Iceberg 数据湖是什么?数据湖能解决什么问题?独立于计算层和存储层之间的表格层?
- 0. 导读
- 1. Hive数仓遇到的问题
- 2. 一种开放的表格式
- 3. 自下而上的元数据
- 4. 高性能的查询
- 4.1 分区剪裁
- 4.2 文件过滤
- 4.3 RowGroup过滤
参考:https://iceberg.apache.org/blogs/
0. 导读
来聊下数据湖三剑客中的iceberg,因为项目准备上这个了。
Iceberg项目2017年由 Netflix 发起, 它是在2018年被 Netflix 捐赠给 Apache 基金会的项目。在2021年 Iceberg 的作者Ryan Blue创建 Tabular 公司,发起以 Apache Iceberg 为核心构建一种新型数据平台。
Ryan Blue 认为我们不是齿轮——我们是工匠。Iceberg 的哲学的核心是让人们快乐:数据基础设施应该在没有令人不快的意外的情况下工作。
虽然 Iceberg 最初的功能相比 Delta 或 Hudi 少一些,但是得益于底层架构接口设计的优雅通用,因此其较早的实现了 Flink 的读写,在国内也获得了不少的关注。下面聊一下 Iceberg 的优势与原理。
1. Hive数仓遇到的问题
首先我们回到Ryan Blue创建Iceberg的原因。起初是认识到数据的组织方式(表格式)是许多数据基础设施面临挫折和问题的共同原因——这些问题因 Netflix 运行在 S3上的云原生数据平台而被更多的暴露。
例如如果没有原子提交,对 Hive 表的每次更改都会冒着其他地方出现错误的风险。因此自动化的修复出现的问题也就是白日梦,这也就给数据工程师造就了更多维护工作,让人很不快乐。
所以说在Iceberg创建初期,它最核心希望解决的是Hive数仓遇到的问题。

具体来说,主要包括下面这些问题:
-
没有
acid保证,无法读写分离 -
只能支持
partition粒度的谓词下推 -
确定需要扫描哪些文件时使用文件系统的
list操作 -
partition字段必须显式出现在query里面
1、没有acid保证
由于Hive数仓只是文件系统上一系列文件的集合(单纯的采用目录方式进行管理),而数据读写只是对文件的直接操作,没有关系型数据库常有的事务概念和acid保证,所以会存在脏读等问题。
2、partition粒度的谓词下推
Hive的文件结构只能通过partition和bucket对需要扫描哪些文件进行过滤,无法精确到文件粒度。
所以尽管parquet文件里保存了max和min值可以用于进一步的过滤(即谓词下推),但是Hive却无法使用。
3、文件系统的list操作
Hive在确定了需要扫描的partition和bucket之后,对于bucket下有哪些文件需要使用文件系统的list操作,而这个操作是 O ( n ) O(n) O(n)级别的,会随着文件数量的增加而变慢。
特别是对于像 s3 这样的对象存储来说,一次list操作需要几百毫秒,每次只能取1000条记录,对性能的影响无法忽略。
4、query需要显式地指定partition
在 Hive 中,分区需要显示指定为表中的一个字段,并且要求在写入和读取时需要明确的指定写入和读取的分区。Iceberg将完全自行处理,并跳过不需要的分区和数据。在建表时用户可以指定分区,无需为快速查询添加额外的过滤,表布局可以随着数据或查询的变化而更新。

在上述例子中,Hive 表并不知道event_date和event_time的对应关系,需要用户来跟踪。
而在 Iceberg 中将分区进行隐藏,由 Iceberg 来跟踪分区与列的对应关系。
在建表时用户可以指定
date(event_time)作为分区, Iceberg 会保证正确的数据总是写入正确的分区,而且在查询时不需要手动指定分区列,Iceberg 会自动根据查询条件来进行分区裁剪。
2. 一种开放的表格式
上面讲了创建 Iceberg 最初想要解决的问题,下面我们说下 Iceberg 在大数据中的定位是什么,以及它在数据湖架构中的位置。
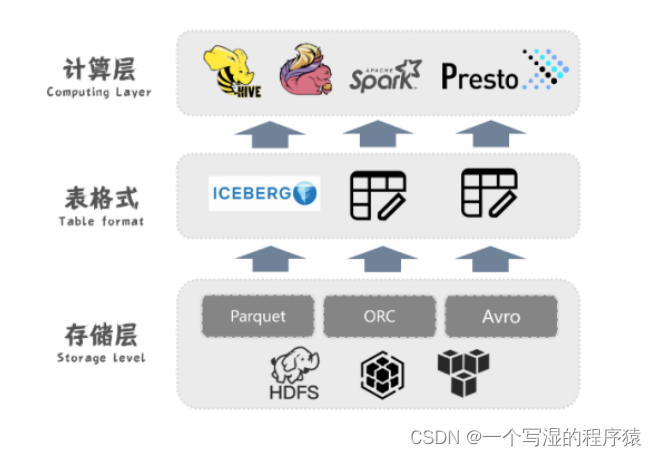
Iceberg 的核心开发者Ryan Blue,将Iceberg定义为一种开放式的表格式为大数据分析,它的定位是在计算引擎之下,又在存储之上,将其称之为table format。
在大数据时代数据的存储格式早已经发生了翻天覆地的变化,从最初的txt file, 到后来的Sequence file, rcfile以及目前的parquet、orc 和 avro 等数据存储文件。
数据的存储有了更好的性能、更高的压缩比,但是对于数据的组织方式依然没有太大的变化。目前Hive对于数据组织的方式任然是采用文件目录的方式进行组织方式,这种组织方式面临上一节中遇到的问题。
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Presto and Spark that use a high-performance format that works just like a SQL table.

从上图可以看出,Iceberg是在HDFS或S3存储引擎上的又一层,用于管理在存储引擎中的Parquet、ORC和avro等压缩的大数据文件,使这些文件更便于管理维护,同时为其构造出相应的元数据文件。
其上层是对接用于计算的Spark、Presto和Flink等计算引擎,并为其提供灵活的可插拔性。Iceberg并不依赖于Spark, 它定义了自己的catalog,schema和数据类型体系,保证了其独立性。
3. 自下而上的元数据
那么 Iceberg 是如何组织数据与元数据的呢?

在数据存储层面上,Iceberg 是规定只能将数据存储在Parquet、ORC和Avro文件中的。像 Parquet 这样的文件格式已经可以读取每个数据文件中的列子集并跳过行。
因此,如果可以跟踪表中的每个数据文件,分区和列级指标的主要信息,那么就可以根据数据文件的统计信息来更有效的进行Data skip。
在Iceberg中对于每个数据文件,都会存在一个manifest清单文件来追踪这个数据文件的位置,分区信息和列的最大最小,以及是否存在 null 或 NaN 值等统计信息。每个清单都会跟踪表中的文件子集,以减少写入放大并允许并行元数据操作。
每个清单文件追踪的不只是一个文件,在清单文件中会为每个数据文件创建一个统计信息的json存储。这样可以使用这些统计信息检查每个文件是否与给定的查询过滤器匹配,如果当前查询的信息并不在当前数据的范围内,还可以实现File skip, 避免读取不必要的文件。
如下图所示,每个清单文件可追踪多个数据文件,这样的优点是减少了元数据小文件的生成,同时可以允许跳过整个清单文件以及其关联的数据文件。

在元数据层面上,Iceberg 将某个版本或快照的清单文件存贮在清单文件列表中,即manifest-list中。其实manifest-list并不是单独的文件,而是snapshot快照文件中的一个list结构体。
从manifest-list清单文件列表中读取清单时,Iceberg 会将查询的分区谓词与每个分区字段的值范围进行比较,然后跳过那些没有任何范围重叠的清单文件。
元数据中的min-max索引对查找查询文件所需的工作量产生了巨大影响。当表增长到数十或数百 PB 时,可能会有数 GB 的元数据,如果对元数据进行暴力扫描将需要长时间的等待作业——相反,使用min-max索引构建的元数据存储使得 Iceberg 会跳过大部分。

回过头来,我们在来看下 Iceberg 在其中是如何维护分区信息的。
Iceberg 和 Hive 不同的是,Iceberg 不是通过list出目录来跟踪分区和定位文件的。
从上面的元数据文件可以看出,Iceberg 的清单文件中会记录每个数据文件所属的分区值信息,同时在清单列表中会记录每个清单文件的分区信息。除此以外在Iceberg的数据文件中也会存储分区列的值,以进行自动分区转换的实现。
总而言之,Iceberg采用的是直接存储分区值而不是作为字符串键,这样无需像 Hive 中那样解析键或 URL 编码值,同时利用元数据索引来过滤分区选择数据文件。
综上,每次进行数据的增删改都会创建一系列的 Data file 或 Delete file 数据文件,同时会生成多个追踪和记录每个数据文件的manifest file清单文件,每个清单文件中可能会记录多个数据文件的统计信息;这些清单文件会被汇总记录到snapshot文件中的manifest list清单文件列表中,同时在快照文件中记录了每个清单文件的统计信息,方便跳过整个清单文件。而每次操作都会重新复制一份metadata.json 的元数据文件,文件汇总了所有快照文件的信息,同时在文件中追加写入最新生成的快照文件。
4. 高性能的查询
Iceberg 表格式的最主打的卖点正是其更快的查询速度。
在 Iceberg 中自上而下实现了三层的数据过滤策略,分别是分区裁剪、文件过滤、RowGroup过滤。
4.1 分区剪裁
对于分区表来说,优化器可以自动从where条件中根据分区键直接提取出需要访问的分区,从而避免扫描所有的分区,降低了IO请求。Iceberg支持分区表和隐式分区技术,所以很自然地支持分区裁剪优化。
如上一节所示,Iceberg实现分区剪枝并不依赖文件所在的目录,而是利用了Iceberg特有的清单文件实现了一套更为复杂的分区系统及分区剪枝算法,名为Hidden Partition。
首先每个 snapshot 中都存储所有 manifest 清单文件的包含分区列信息,每个清单文件每个数据文件中存储分区列值信息。这些元数据信息可以帮助确定每个分区中包含哪些文件。
这样实现的好处是:
-
无需调用文件系统的list操作,可以直接定位到属于分区的数据文件。
-
partition的存储方式是透明的,用户在查询时无需指定分区,Iceberg可以自己实现分区的转换。
-
即使用户修改分区信息后,用户无需重写之前的数据。
4.2 文件过滤
Iceberg 提供了文件级别的统计信息,例如Min/Max等。可以用where语句中的过滤条件去判断目标数据是否存在于文件中。
Iceberg 利用元数据中的统计信息,通过Predicate PushDown(谓词下推)实现数据的过滤。
在讲 Iceberg 前我们先来说下 Spark 是如何实现谓词下推的:
在SparkSQL优化中,会把查询的过滤条件,下推到靠近存储层,这样可以减少从存储层读取的数据量。
其次在真正读取过滤数据时,Spark并不自己实现谓词下推,而是交给文件格式的reader来解决。
例如对于parquet文件,Spark使用PartquetRecordReader类来读取parquet文件,分别对于非向量化读和向量化的读取。在构造reader类时需要提供filter的参数,即过滤的条件。过滤逻辑稍后由RowGroupFilter调用,根据文件中块的统计信息或存储列的元数据验证是否应该删除读取块(Spark在3.1 支持avro, json, csv的谓词下推)。
相比于Spark,Iceberg会在snapshot层面基于元数据信息过滤掉不满足条件的data file。
4.3 RowGroup过滤
对于Parquet这类列式存储文件格式,它也会有文件级别的统计信息,例如Min/Max/BloomFiter等等,利用这些信息可以快速跳过无关的RowGroup,减少文件内的数据扫描。
Iceberg在data file层面过滤掉不满足条件的RowGroup。这一点和Spark实际是类似的,但是作为存储引擎的Iceberg,他使用了parquet更偏底层的ParquetFileReader接口,自己实现了过滤逻辑。
Iceberg通过调用更底层的API, 可以直接跳过整个RowGroup, 更进一步的减少了IO量。