一、什么是异常
异常就是程序运行时发生错误的信号,在程序由于某些原因出现错误的时候,若程序没有处理它,则会抛出异常,程序也的运行也会随之终止;
- 程序异常带来的问题:
1.程序终止,无法运行下去; 2…如果程序是面向客户,那么会使客户的体验感很差,进而影响业务;
- 什么时候容易出现异常:
当处理不确定因素时,比如有用户参与,有外界数据传入时,都容易出现异常;
- 产生异常事件大致分两种:
1.由于语法错误导致程序出现异常,这种错误,根本过不了Python解释器的语法检查,必须在程序执行前就改正;
#语法错误示范一:
if
#语法错误示范二:
def func:
#语法错误示范三:
class foo
pass
#语法错误示范四:
print(hello word
2.就是由于代码的逻辑问题使程序产生了异常;
#错误示例:
for n in 3:
pass
#错误示例:
[][1]
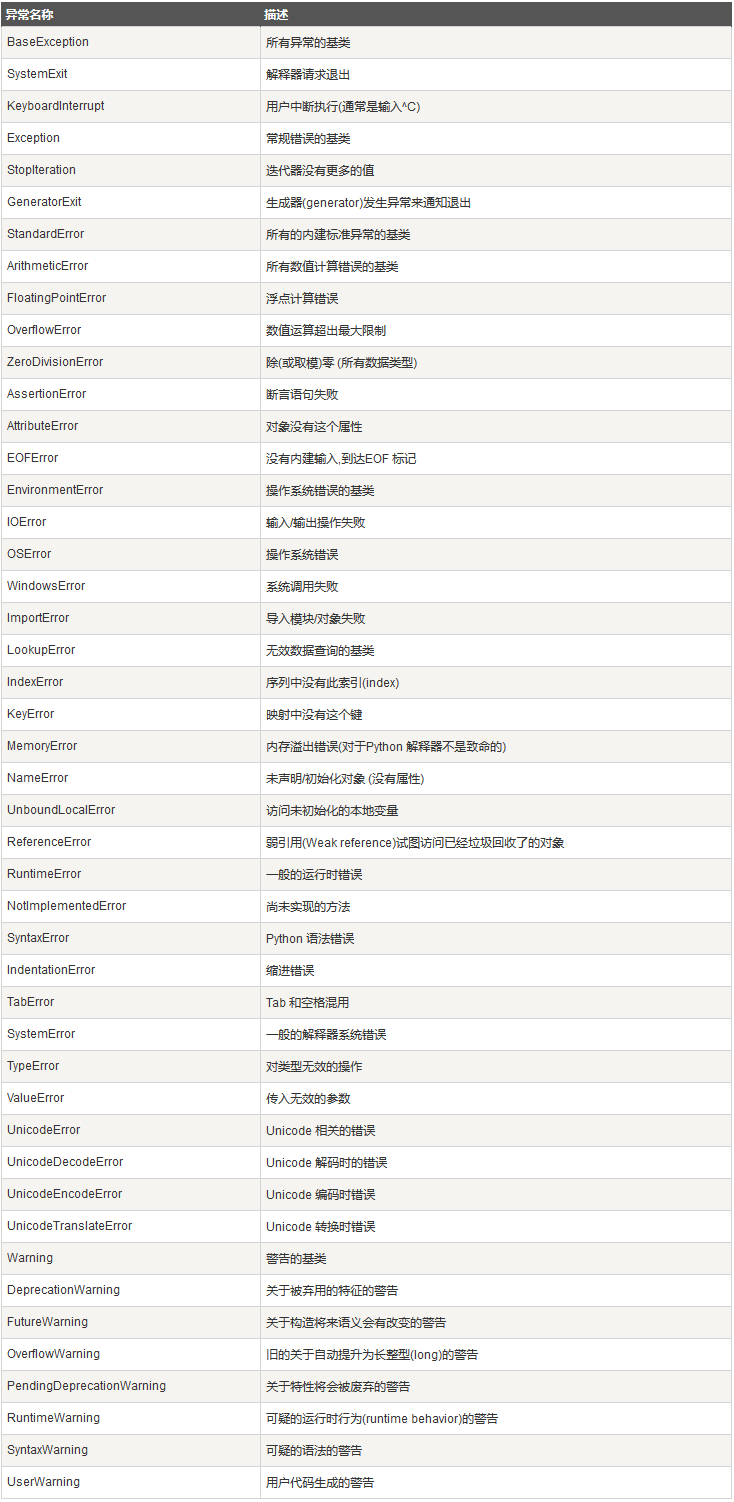
二、异常的类型
异常也是有分类的,不同的异常用不同的类型去标识,不同的类对象标识不同的异常,一个异常标识一种错误;
常用的异常种类:
'''
AttributeError #试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x
IOError # 输入/输出异常;基本上是无法打开文件
ImportError #无法引入模块或包;基本上是路径问题或名称错误
IndentationError #语法错误(的子类) ;代码没有正确对齐
IndexError #下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5]
KeyError #试图访问字典里不存在的键
KeyboardInterrupt #Ctrl+C被按下
NameError #使用一个还未被赋予对象的变量
SyntaxError #Python代码非法,代码不能编译,其实是语法错误;
TypeError #传入对象类型与要求的不符合
UnboundLocalError #试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,导致你以为正在访问它
ValueError #传入一个调用者不期望的值,即使值的类型是正确的
'''
三、异常处理机制
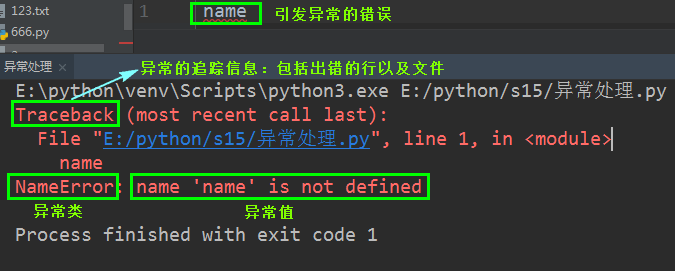
先来看看程序异常后,怎么报的错,我们从报错中能够分析出什么。
什么是异常处理?
python解释器检测到错误,触发异常(也允许程序员自己触发异常),程序员编写特定的代码,专门用来捕获这个异常(这段特点代码与逻辑程序无关和异常处理有关);如果捕获成功则进入另一个处理分支,执行为其定制的逻辑,使程序不会崩溃,这就是异常处理。
为什么要进行异常处理?
python解释器去执行程序,检测到一个错误时,触发异常,异常触发后且没有被处理的情况下,程序就在当前异常处停止运行,后面的代码不会执行,那么没有人会去使用一个运行着突然就崩溃的软件的;所以我们有必要提供一种异常处理机制来增强程序的健壮性和容错性。
如何进行异常处理?
首先须知,异常是由程序的错误引起的,语法上的错误跟异常处理无关,必须在程序运行前就修正;
1.使用if判断式
num1=input('>>: ') #输入一个字符串试试
int(num1)
使用if判断进行异常处理
num1=input('>>: ') #输入一个字符串试试
if num1.isdigit():
int(num1) #我们的正统程序放到了这里,其余的都属于异常处理范畴
elif num1.isspace():
print('输入的是空格,就执行我这里的逻辑')
elif len(num1) == 0:
print('输入的是空,就执行我这里的逻辑')
else:
print('其他情情况,执行我这里的逻辑')
问题一:
使用if的方式我们只为第一段代码加上了异常处理,但这些if,跟你的代码逻辑并无关系,这样你的代码会因为可读性差而不容易被看懂
问题二:
这只是我们代码中的一个小逻辑,如果类似的逻辑多,那么每一次都需要判断这些内容,就会倒置我们的代码特别冗长。
小结:
1.if判断式的异常处理只能针对某一段代码,对于不同的代码段的相同类型的错误你需要写重复的if来进行处理;
2.在你的程序中频繁的写与程序本身无关,与异常处理有关的if,会使得你的代码可读性极其的差;
3.if是可以解决异常的,只是存在1,2的问题,所以,千万不要妄下定论if不能用来异常处理;
之前用来判断异常的方法,比如不能输入数字或字母等等
def test():
print('test running')
choice_dic={
'1':test
}
while True:
choice=input('>>: ').strip()
if not choice or choice not in choice_dic:continue #这便是一种异常处理机制啊
choice_dic[choice]()
2.python为每一种异常定制了一个类型,然后提供了一种特定的语法结构来进行异常处理;
首先重要的几种搭配格式列出来:
try ... except
try ... except ... else
try ... finally
try ... except ... finally
try ... except ... else ... finally
1)基本语法
异常处理的基本语法
try:
被检测的代码块
except 异常类型:
try中一旦检测到异常,就执行这个位置的逻辑
异常处理例子
try:
a = "A"
b
except NameError:
print("b没有赋值会引发程序异常,异常类型时NameError,我们通过"
"捕获这个异常,使其不会崩溃,继而执行此分支,也就是当前"
"打印的这段话")
--------------------- 运行后的效果 ----------------------------------------------
b没有赋值会引发程序异常,异常类型时NameError,我们通过捕获这个异常,使其不会崩溃,继而执行此分支,也就是当前打印的这段话
2)异常类只能用来处理指定的异常情况,如果非指定异常则无法处理;
try:
a = "A"
b
except IndexError:
print("b没有赋值会引发程序异常,异常类型时NameError,我们通过"
"捕获这个异常,使其不会崩溃,继而执行此分支,也就是当前"
"打印的这段话")
-------------------- 运行后的效果 -----------------------------------------------
Traceback (most recent call last):
File "E:/python/s15/异常处理.py", line 3, in <module>
b
NameError: name 'b' is not defined
因为我们设置的捕获异常类和其发生异常的类不是一个类,所以捕获不到;
3)多分支
说明:从上向下报错的代码只要找到一个和报错类型相符的分支就执行这个分支中的代码,然后直接退出分支;如果找不到能处理和报错类型相同的分支,会一直往下走,最后还是没有找到就会报错。
多分支异常处理
s1 = 'hello'
try:
int(s1)
except IndexError as e:
print(e)
except KeyError as e:
print(e)
except ValueError as e:
print(e)
这里我们需要知道的是as的已是就是将捕获到的异常的内容赋值给变量e,变量e是不固定的,也可以使用其他字母来代替,这样的话,既方便我们对异常的内容进行分析,也不影响程序的执行。
4)多分支合并
说明:如果说我们有多个异常在处理时需要共同处理,比如说,只要发生IndexError和NameError异常了,我们就执行或打印一段代码时,就可以使用多分支合并的方式了;
多分支合并例子
l = ['login','register']
for num,i in enumerate(l,1):
print(num,i)
try:
num = int(input('num >>>'))
print(l[num - 1])
except (ValueError,IndexError) :
print('您输入的内容不合法')
5)万能异常;
说明:在python的异常中,有一个万能异常:Exception,它可以捕获任意异常;
s1 = 'hello'
try:
int(s1)
except Exception as e:
print(e)
注意:万能异常应该分两种情况去看;
-
如果想要的效果是,无论出现什么异常,我们统一丢弃,或者使用同一段代码逻辑去处理他们,那么只有一个Exception就足够了。
-
如果你想要的效果是,对于不同的异常我们需要定制不同的处理逻辑,那就需要用到多分支了
多分支+Exception
s1 = 'hello'
try:
int(s1)
except IndexError as e:
print(e)
except KeyError as e:
print(e)
except ValueError as e:
print(e)
except Exception as e:
print(e)
6)as用法:
说明:能够将具体错误信息打印出来,赋值给变量;
7)异常的其他机构,else,finally;
else 说明:当try内的代码块没有报错时并且还要继续运行程序的话就用else;
finally 说明:无论try内的代码块是否异常,都执行该区域内的代码,通过用来进行清理工作;尤其注意如果在函数中有finally,即使return也会先执行fianlly中的代码。
else 以及 finally
s1 = 'hello'
try:
int(s1)
except IndexError as e:
print(e)
except KeyError as e:
print(e)
except ValueError as e:
print(e)
#except Exception as e:
# print(e)
else: #Python小白交流学习群:711312441
print('try内代码块没有异常则执行我')
finally:
print('无论异常与否,都会执行该模块,通常是进行清理工作')
8)主动触发异常 raise;
说明:这是给开发者用的,比如我们现在用的python,作者就会在python中加入主动触发异常,就是用来给开发者的,当遇到异常时会报错,提示开发者;
>>> try:
... raise TypeError('类型错误')
... except Exception as e:
... print(e)
...
类型错误
9)断言 语法
说明:assert断言语句用来声明某个条件是真的,其作用是测试一个条件(condition)是否成立,如果不成立,则抛出异常。
语法:assert condition
如果condition为false,就raise一个AssertionError出来。逻辑上等同于:
if not condition:
raise AssertionError()
assert condition,expression
如果condition为false,就raise一个描述为 expression 的AssertionError出来。逻辑上等同于:
if not condition:
raise AssertionError(expression)
使用例子:
assert 断言例子
>>> assert 1 == 1
>>> assert 1 == 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AssertionError
>>> assert 1 == 2,"这是什么鬼"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AssertionError: 这是什么鬼
10)自定义异常
在我们自定义返回异常时,最好使用异常code + 异常data的方式;看一个例子:
#去path路径的文件中,找到前缀为prev的一行数据,获取数据并返回给调用者。
#code值+data
#1000,成功
#1001,文件不存在
#1002,关键字为空
#1003,未知错误
#方法一:
import os
def func(path,prev):
"""
去path路径的文件中,找到前缀为prev的一行数据,获取数据并返回给调用者。
1000,成功
1001,文件不存在
1002,关键字为空
1003,未知错误
...
:return:
"""
response = {'code':1000,'data':None}
try:
if not os.path.exists(path):
response['code'] = 1001
response['data'] = '文件不存在'
return response
if not prev:
response['code'] = 1002
response['data'] = '关键字为空'
return response
pass #业务代码区
except Exception as e:
response['code'] = 1003
response['data'] = '未知错误'
return response
#方法二:
import os
class ExistsError(Exception):
pass
class KeyInvalidError(Exception):
pass
def new_func(path,prev):
"""
去path路径的文件中,找到前缀为prev的一行数据,获取数据并返回给调用者。
1000,成功
1001,文件不存在
1002,关键字为空
1003,未知错误
...
:return:
"""
response = {'code':1000,'data':None}
try:
if not os.path.exists(path):
raise ExistsError()
if not prev:
raise KeyInvalidError()
pass
except ExistsError as e:
response['code'] = 1001
response['data'] = '文件不存在'
except KeyInvalidError as e:
response['code'] = 1002
response['data'] = '关键字为空'
except Exception as e:
response['code'] = 1003
response['data'] = '未知错误'
return response
##方法三:
class MyException(Exception):
def __init__(self,code,msg):
self.code = code
self.msg = msg
try: #Python小白交流学习群:711312441
raise MyException(1000,'操作异常')
pass
except KeyError as obj:
print(obj,1111)
except MyException as obj:
print(obj,2222)
except Exception as obj:
print(obj,3333)
----------------------- 打印结果 -------------------------------------------
(1000, '操作异常') 2222
try方式比较if的方式的好处:
try…except这种异常处理机制就是取代if那种方式,让你的程序在不牺牲可读性的前提下增强健壮性和容错性,异常处理中为每一个异常定制了异常类型(python中统一了类与类型,类型即类),对于同一种异常,一个except就可以捕捉到,可以同时处理多段代码的异常(无需‘写多个if判断式’)减少了代码,增强了可读性 ;
使用try…except的方式:
-
把错误处理和真正的工作分开来
-
代码更易组织,更清晰,复杂的工作任务更容易实现
-
毫无疑问,更安全了,不至于由于一些小的疏忽而使程序意外崩溃了
什么时候用异常处理?
try…except应该尽量少用,因为它本身就是你附加给你的程序的一种异常处理的逻辑,与你的主要的工作是没有关系的
这种东西加的多了,会导致你的代码可读性变差,只有在有些异常无法预知的情况下,才应该加上try…except,其他的逻辑错误应该尽量修正