Navicat快捷键
刷新:Fn+F5
表内容页面打开表设计页面:Ctrl+D
打开 MYSQL 命令行窗口:Fn+F6
MYSQL 增减查改
create table student(
stuid int not null auto_increment primary key,
stuname varchar(200),
stustatus varchar(100)
);
create table grade(
gradeid int not null auto_increment primary key,
stuid int not null,
gradecourse varchar(100),
gradescore varchar(100)
);
#增加
insert into student(stuname,stustatus)values('Han Li','Normal');
insert into student(stuname,stustatus)values('Gura kench','Normal'),('yiying Zhang','Normal'),('Saburner Wang','Normal');
insert into grade(stuid,gradecourse,gradescore)values(2,'Econ 101','A');
#删除
delete from student where stuid=1;
delete from student;
#修改
update student set stuname='Dae Hung',stustatus ='Dropped' where stuid=5;
#查询
#从student中查询所有的列和行
select * from student;
#查询某一个ID
select * from student where stuid=5;
#查询某一个字段
select stuname,stustatus from student where stuid=5;
#查询学生个数
select count(*)from student;
#从两个表中查
select stuname,student.stuid,gradecourse,gradescore from student,grade where student.stuid=5;
#去除表格列中的重复元素的查询
select distinct grade from student;
#清空表内的数据,并且重置自增列
truncate table student;
#清楚表内的数据,不会重置自增列
delete from student;
#直接把表删除,连带里面的数据
drop table student;
JDBC基础
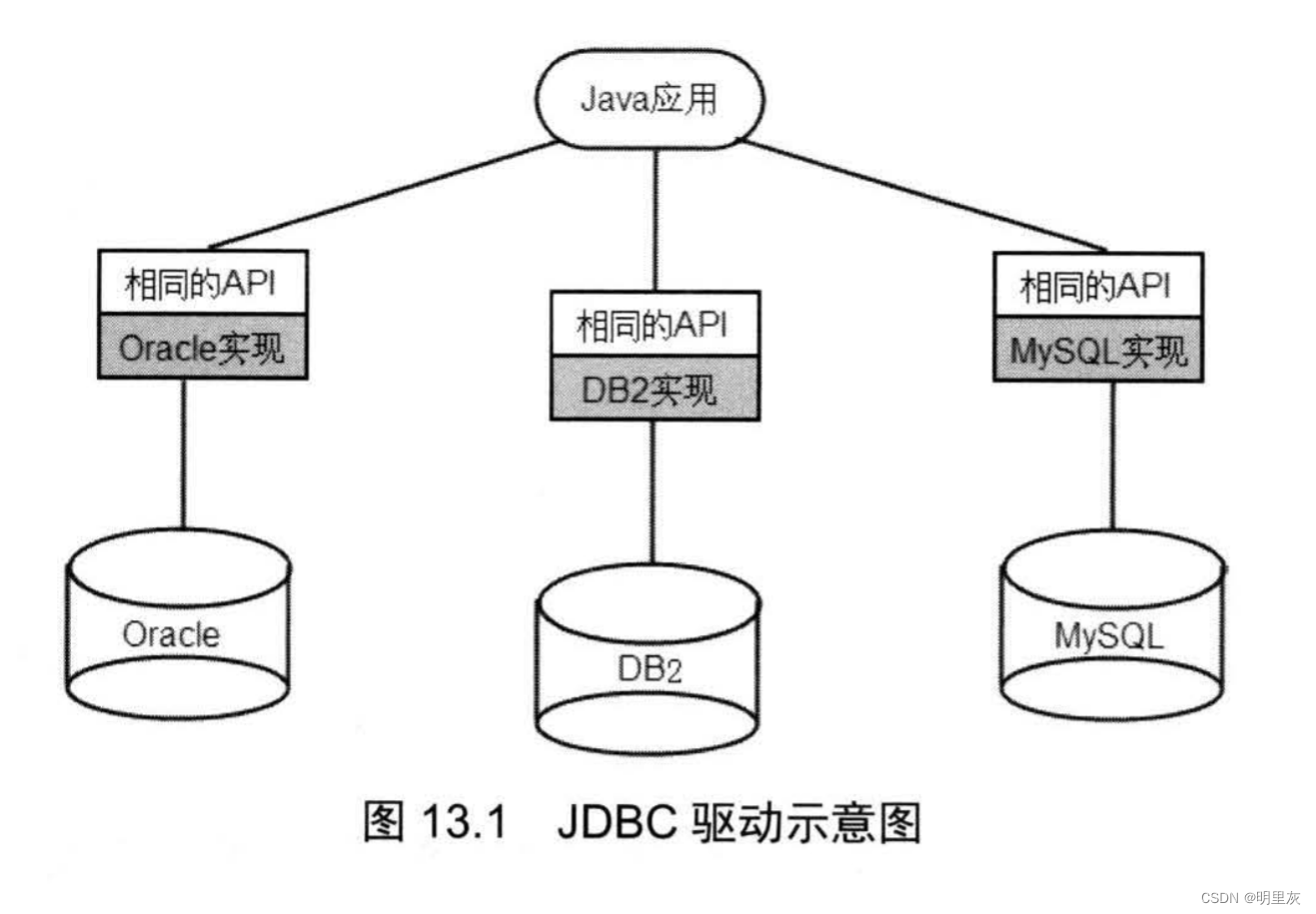
全称是 Java Database Connectivity,即 Java 数据库连接,是一种可以执行 SQL 语句(SQL 是数据库标准查询语言)的 Java API。程序通过 JDBC API 连接到关系数据库,并使用结构化查询语言来完成结构化查询语言。
通过使用 JDBC,就可以使用同一种 API 访问不同的数据库系统。
标准的 API 它们只是接口,没有提供实现类(驱动程序)。
程序员使用 JDBC 是只要面向标准的 JDBC API 编程即可,当需要再数据库之间切换时,只需要更换不同的实现类。
JDBC 比 ODBC 安全性更高,更容易部署。
JDBC 可以完成以下的三个操作:
- 建立与数据库的连接
- 执行 SQL 语句
- 获得 SQL 语句的执行结果

SQL语法
SQL 语句是对所有关系库都通用的命令语句,而 JDBC API 是执行 SQL 语句的工具,JDBC 允许对不同的平台、不同的数据库采用相同的编程接口来执行 SQL 语句。
除标准的 SQL 语句之外,所有数据库都会在标准 SQL 语句基础上进行扩展,增加一些额外的功能,这些额外的功能属于特定的数据库系统,不能在所有的数据库系统上通用。
关系数据库的基本概念和 MYSQL 基本命令
常把数据库和数据管理系统(DBMS)统称为数据库,它既包括存储用户数据的部分,也包括管理数据库的管理系统。
DBMS 是所有数据的知识库,负责管理数据的存储、安全、一致性、并发、恢复和访问等操作。它有一个数据字典(系统表)用于存储它拥有的每个事务的相关信息,例如名字、结构、位置和类型,这种关于数据的数据被称为元数据。
- 网状型数据库
- 层次型数据库
- 关系数据库
- 面向对象数据库
用的最广泛的是关系数据库,关系数据库最基本存储单元室数据表,可以把数据库想象成大量数据表的集合(当时没有这么简单)。
数据表是存储数据的逻辑单元,可以把数据表想象成由行和列组成的表格,每一行被称为一条记录,每一列被称为一个字段。
数据库建表时,需要指定该表包含多少列,每列的数据类型信息,无须指定多少行(每行用于保存一个用户的数据)。
还应该为每个数据表指定一个特殊列,,可以唯一地标识此行的记录,该特殊列被称为主键列。
MYSQL 数据库的一个实例可以同时包含多个数据库,可以用这个命令来查看当前实例下包含多少个数据库:
show databasses;
如果用户创建新的数据库,可以用:
create database [ IF NOT EXISTS ] 数据库名;
如果用户需要删除指定数据库,可以用:
drop database 数据库名;
建立数据库后,要操作该数据库(例如为该数据库建表,在该数据库中执行查询等操作),进入指定数据库可以用:
use 数据库名;
进入指定数据库后,要查询该数据库下包含多少个数据表,可以用:
show tables;
如果要查看指定数据表的表结构(有多少列,每列的数据类型等信息),可以用:
desc 表名;
注意:MYSQL 默认以分号作为每条命令的结束符,每条 MYSQL 命令结束后都应该输一个分号。
执行上面的命令可以连接远程主机的 MYSQL 服务,可以先省略 -p后面的密码,后面会提示要输出密码。
通常无须指定数据表的存储机制,因为系统默认使用 InnoDB 存储机制。如果需要在建表时显式指定存储机制,可以在标准建表语法后添加下面的语句:
- ENGINE=MYISAM——强制使用 MYISAM 存储机制
- ENGINE=InnoDB——强制使用 InnoDB 存储机制
SQL 语句基础
标准的 SQL 语句可以操作任何关系的数据库,如下:
- 在数据库中检索信息
- 对数据库的信息进行更新
- 改变数据库的结构
- 更改系统的安全设置
- 增加或回收用户对数据库、表的许可权限
- 查询语句:主要由 select 关键字完成
- DML 语句:主要由 insert、update 和 delete 三个关键字完成
- DDL 语句:主要由 create、alter、drop 和 truncate 四个关键字完成
- DCL 语句:主要由 grant 和 revoke 两个关键字完成
- 事务控制语句:主要由 commit、rollback 和 savepoint 三个关键词完成
SQL 语句不区分大小写。
可能用到标识符:定义表名、列名,也可以用于定义变量等。
标识符的命名规则:
- 通常必须以字母开头
- 包括字母、数字和桑特殊字符(#_$)
- 不要使用当前数据库系统中的关键字、保留字,通常使用多个单词连缀而成,单词之间以_分隔
- 同一个外模式下的对象不应该同名
DDL 语句
DDL 语句是操作数据库对象的语句,包括创建(create)、删除(drop)和修改(alter)数据库对象。

因为存在上面几种数据库对象,所以 create 之后可以紧跟不同的关键字。
例如:建表应使用 create table,建索引应使用 create index,建视图应使用 create view……drop 和 alter 后也需要添加类似的关键字来表示删除、修改那种数据库对象。
创建表的语法
create table [ 模式名. ] 表名
{
#可以定义多个列定义
colunmName1 datatype [default expr ],
...
}
花括号{}里可以包含多个列定义,每个列定义之间用英文逗号隔开,最后一个列定义以括号结束。
列定义由列名、列类型和可选默认值组成。将列名放在前面,列类型放在后面。如果要指定列的默认值,要使用 default 关键字,而不是用等号(=)。
create table test
{
#整型常用 int
test_id int,
#小数点数
test_price decimal,
#普通长度文本,使用 default 指定默认值
test_name varchar(255) default 'xxx',
#大文本类型
test_desc text,
#test_desc text,
#图片
test_img blob,
test_data datetime
} ;


上面的建表语句只是创建一个空表,没有任何数据,如果使用子查询建表语句,则可以在建表的同时插入数据。
子查询建表语句的语法:
create table [模式名.] 表名 [column[,column...]]
as subquery;
MYSQL 的一个 modify 命令不支持一次修改多个列定义。但是可以用圆括号把多个列定义括起来,可以在 alter table 后使用多个 modify 命令。
- 从数据表中删除列的语法:(需要比较长的时间,因为删除后还需要回收空间)
#删除 hehe 表中的 aaa字段
alter table hehe
drop aaa;
删除列,在 drop 后面紧跟需要删除的列名:
#删除 hehe 表中的 aaa 字段
alter table hehe
drop aaa;
重命名数据表的语法格式:
alter table 表名
rename to wawa;
改变列名:
alter table 表名
修改列名使用 change 选项:
# 将wawa 数据表中的 bbb 字段重命名为 ddd
alter table wawa
change bbb ddd int;
删除表:
drop table 表名;
删除已有的 wawa 数据表删除:
drop table 表名;
- 表结构被删除,表对象也不存在
- 表里的所有数据被删除
- 该表所有的相关引用、约束也被删除
用 truncate 表删除表的记录,但保留表结构:
truncate 表名
数据库约束
- 建表的同时为相应的数据列指定约束
- 建表后创建,以修改表的方式来增加约束
所有数据类型的值都可以是 null,包括 int、float、boolean 等数据类型
空字符串不为 null,0也不等于 null
- NOT NULL 约束
确保指定列不为空。
- UNIQUE 约束
用于保证指定列或指定组合不允许出现重复值,但是可以出现多个 null 值(可以放在 create table 语句中与列定义并列,也可以房子 alter table 语句中使用 add 关键字来添加约束定义)
create table unique_test
{
#建立了非空约束,test_id不可以为 null
test_id int not null,
#unique就是唯一约束,使用劣迹约束语法建立唯一约束
test_name varchar(255) unique;
};[constraint 约束名] 约束定义
为多行组合建立唯一约束,或者想自行指定约束名,就要用表级约束语法:(为 test_name 和 test_pass 分别建立唯一约束,这两列都不能出现重复值)
#建表时创建唯一约束,使用表级约束语法建立约束
create table unique_teat2
{
#建立了非空约束
test_id int not null,
test_name varchar(255),
teat_pass varchar(255),
#使用表级约束语法建立唯一约束
unique (test_name),
#使用表级约束语法建立唯一约束,而且指定约束名
constraint test2_uk unique(test_pass)
};这两列的组合不能重复:
#建表时创建唯一约束,使用标记约束语法建立越是
create table unique_teat3
{
#建立了非空约束
test_id int not null,
test_name varchar(255),
test_pass varchar(255),
#使用表级约束语法建立唯一约束,指定两列组合不能重复
constraint test3_uk unique(test_name,test_pass)
};
也可以在修改表是使用 add 关键字增加唯一约束:
#alter table unique_test3
add unique(test_name,test_pass);
在修改表是使用 modify 关键字,为单列采用列级约束语法增加唯一约束:
#unique test3表的 test_name列添加唯一约束
atler table unique_test3
modify test_test_name varchar(255) unique;
drop index test_uk;
删除约束是在 alter table 语句后使用 “drop constraint 约束名”语法来完成,但 MYSQL 不使用这种方式:用 “drop index 约束名”的方式来删除约束
#删除 unique_test3表上的 test3_uk唯一约束
alter table unique_test3
drop index test3_uk;
- PRIMARY KEY 约束
每一个表中最多运行有一个主键,这个主键约束可以有多个数据列组合,主键值表中能唯一确定一行记录的字段或字段组合。
同一个表中最多只能有一个主键约束。
- FOREIGN KEY 约束
外键约束只要用于保证一个或两个数据表之间的参照晚自习,外键列的值必须在主键参照列的值的范围之内,或者为空。
当主表中的记录被从表参照时,主表记录不允许被删除,不行包从表参照该表的所有记录全部删除后才可以删除主表的该记录。
- CHECK 约束
要求 emp_salary 大于0,但是这个要求实际上不会起作用。
索引
索引是存放模式中的一个数据库对象,总是从属于数据表,但是他也和数据表一样属于数据库对象,它的作用是加速对表的查询,减少了磁盘的I/O。
在数据字典中独立存放,但不能独立存在,必须属于某个表。
视图
- 可以限制对视图的访问
- 使复杂的查询变简单
- 提供数据独立性
- 提供对相同数据的不同显示
视图的本质是被命名的SQL查询语句。
创建视图:
create or replace view 视图名
as
subquery
删除视图:
drop view 视图名
DML语句语法
DML 可以完成如下三个任务:
- 插入新数据
- 修改已有数据
- 删除不需要的数据
- insert into 语句
用于向指定数据表中插入值的列名,value 后用括号列出对应要插入的值.
insert into table_name[(column[,colmn...])]
values(value [,value...]);
- updata 语句
用于修改数据表的记录,每次可以修改多条记录,通过使用 where 自居限定修改哪些记录。
where 子句是一个条件表达式,相当与 if,只有符合条件才会被修改。
没有 where 子句意味着 where 表达式的值总是 true,该表所有记录都会被修改。
updata table_name
set column=value1[,column2=value2]...
[WHERE condition];
- delete from 语句
用于删除指定数据表的记录,不需要指定列名,是整行删除。
只删除满足 where 条件的记录,没有 where 子句限定会将表里的全部记录删除
delete from table_name
[WHRER condition];
单表查询
select 语句是查询数据,可以执行单表和多表查询,还可以执行子查询。
它用于从一个或多个数据表选出特定行、特定列的交集。
select column1,column2...
from 数据库
[where condiion]
使用 distinct 取出重复行时,distinct 紧跟 select 关键字,它的作用是取出后面字段组合的重复值,而不管对应记录在数据库里是否重复。
SQL 中判断两个值相等的标记运算符是单等号,判断不相等的运算符是<>,赋值运算符不是等号,是冒号等号(:=)。
多表查询
可能会出现两个或者多个数据具有相同的列名,所以在这些同名的列名之前使用表面前缀作为限制。
JDBC
常用接口
DriveManager:用于管理JDBC驱动的服务类
Connection:代表数据库连接对象
ResultSet:结果集对象
编程步骤
- 加载数据库驱动
- 获取数据库连接
- 通过Connection对象创建Statement对象
- 使用Statement执行SQL语句
- 操作结果集
- 回收数据库资源
管理结果集
JDBC使用ResultSet来封装查询到的结果,然后移动ResultSet的记录来取出结果集的内容。
可更新的结果集要满足:
- 所有数据都来自于一个表
- 选出的数据集不行包含主键列
使用连接池管理连接
一个数据库连接对象对应一个物理数据库连接,每次操作到打开一个物理连接,使用后立即关闭连接,频繁地打开关闭将造成系统性能地下。
一个数据库连接池的解决方案是:当程序启动时,系统主动建立足够的数据库连接,并将这些连接组成一个连接池。每次应用程序请求数据库连接时,不用重新打开连接,直接从连接池中取出已有的连接使用,使用完也不用关闭数据库连接,而是直接归还给连接池。
数据库连接池常用参数:
- 数据库初始连接数
- 连接池最大连接数
- 连接池最小连接数
- 连接池每次增加的容量