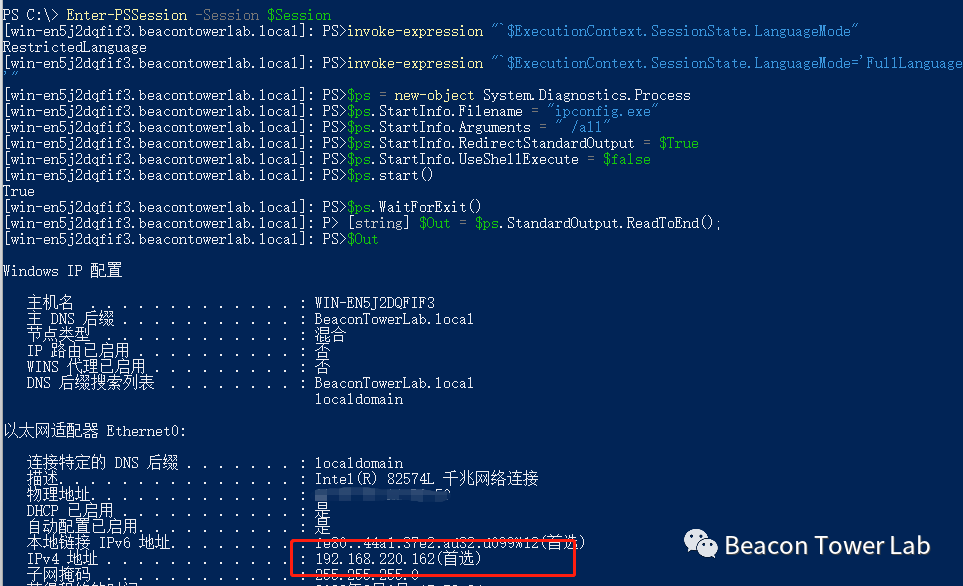
1.depthwise卷积&&Pointwise卷积
depthwise与pointwise卷积又被称为Depthwise Separable Convolution,与常规卷积不同的是此卷积极大地减少了参数数量,同时保持了模型地精度,depthwise操作是先进行二维平面上地操作,然后利用pointwise进行维度上的更新。
2. 1*1的卷积核有什么作用
实现不同通道数据之间的计算,降维、升维、跨通道交互、增加非线性,大大减少了参数量,其次,增加的1X1卷积后面也会跟着有非线性激励,这样同时也能够提升网络的表达能力
意义:实现了不同通道同一位置的信息融合,可以实现通道数的降维或升维
3. 反卷积相比其他上采样层的缺点,棋盘格现象怎么产生的
上采样可以扩大输入图像的尺寸,将一个小分辨率的图像扩展成一个高分辨率的图像。在YOLOv4模型中,上采样被加入卷积网络中,作为中间层使用,扩展特征图尺寸,便于张量拼接,上采样常用的方法有双线性插值法,反卷积(也称转置卷积)法和上池化法。
正向卷积:
反向卷积

在上采样使用反卷积的时候,卷积核的大小不能被步长整除导致的。处理方法:多层反卷积;反卷积后面接个步长为1的卷积;调整kernel权重分布;采取可以被stride整除的kernel size;调整图像大小(使用最近邻插值或双线性插值),然后执行卷积操作。
4.3D卷积和2D卷积的区别,主要存在问题,如何加速运算,视频理解的sota方法,还有什么方向可以改进
2D卷积可以分为单通道卷积和多通道卷积
3D卷积由于Convolution Filter只能在高度和宽度方向上移动,因此仍被称为2D卷积,一个Filter和一张图像卷积只能生成一个通道的输出数据。
3D卷积使用的数据和2D卷积最大的不同就在于数据的时序性。3D卷积中的数据通常是视频的多个帧或者是一张医学图像的多个分割图像堆叠在一起,这样每帧图像之间就有时间或者空间上的联系
5.卷积核大小如何选取
6.卷积层减少参数的方法,使用13,31代替3*3的原理是什么
非对称卷积通常用于逼近现有的正方形卷积以进行模型压缩和加速,可以将标准的dd卷积分解1d为和d*1卷积,以减少参数量。其背后的理论相当简单:如果二维卷积核的秩为1,则运算可等价地转换为一系列一维卷积。然而,由于深度网络中下学习到的核具有分布特征值,其内在秩比实际中的高,因此直接将变换应用于核会导致显著的信息损失。
7.设计一个在CNN卷积核上做dropout的方式
8.反卷积转置卷积的实现原理
9.Dropout的原理
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。相同点:都有正则化的效果。二者的机制是有差别的。过拟合的原因,就是使用了对问题而言过于复杂的表述,所以缓解过拟合的基本方法就是降低对问题表述的复杂度。
不同点:BN实现这一点的机制是尽量在一个更平滑的解子空间中寻找问题的解,强调的是处理问题的过程的平滑性,隐含的思路是更平滑的解的泛化能力更好,Dropout是强调的鲁棒性,即要求解对网络配置的扰动不敏感,隐含思路是更鲁棒的解泛化能力更好。从这个机制看,Dropout对过拟合的控制机制实际上更直接更表面化更简单粗暴,而BN则要间接一点,但是更底层更本质。但是二者的机制有差别又有重叠,平滑和鲁棒二者常常是一致的,但又不完全一致,不能简单说哪个效果更好,但从机制上看,BN的思想在统计上似乎应该更好一点,但是由于BN用于约束平滑性的手段本身并不完备,只是选用了一种控制模式,所以并不能完全体现其控制平滑性的思想,所以BN对泛化性能的实际影响也不是非常大。
10.直接转置卷积和先上采样再卷积的区别
- 上采样过程(使用插值的方法)。如果后面拼接一个卷积,其感受野大小基本保持不变。如果是多个卷积其感受野还是会增大。 2. 上采样过程中复制的点,也具有和原始特征点相同的感受野。也就是本层中的两个完全相同的特征点的感受野等价于上一层的一个特征点的感受野。直接转置卷积的感受野相同。
- 反卷积: 一维-> 多维立方 ->重叠融合;上采样+卷积: 一维变 多维 变一维。
11.maxpooling怎么传递导数
12.CNN里面池化的作用
平均池化:倾向于保留突出背景特征;
最大池化:倾向于保留突出纹理特征;
卷积的作用就是为了提取某些指定的特征,而池化就是为了进一步抽取更高阶的特征。通过池化操作忽略一些细节信息,强行让CNN学到的更多我们想要的高阶信息。
13.反向传播的时候怎么传递pooling的导数
max pooling: 下一层的梯度会原封不动地传到上一层最大值所在位置的神经元,其他位置的梯度为0;
average pooling: 下一层的梯度会平均地分配到上一层的对应相连区块的所有神经元。
14.卷积神经网络在maxpooling处怎么反向传播误差
15. shufflenet的结构
第一代模型主要核心为分组卷积和通道打乱,第二代模型主要核心为通道分割和通道打乱。
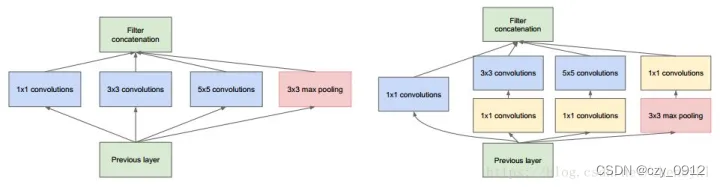
第二代模型是在四条提速规则下对第一代模型进行调整的结果,论文说在同等复杂度下,shufflenet v2比shufflenet和mobilenetv2更准确。这四条准则如下:(G1)同等通道大小最小化内存访问量 对于轻量级CNN网络,常采用深度可分割卷积(depthwise separable convolutions),其中点卷积( pointwise convolution)即1x1卷积复杂度最大。这里假定输入和输出特征的通道数分别为C1和C2,经证明仅当C1=C2时,内存使用量(MAC)取最小值,这个理论分析也通过实验得到证实。(G2)过量使用组卷积会增加MAC 组卷积(group convolution)是常用的设计组件,因为它可以减少复杂度却不损失模型容量。但是这里发现,分组过多会增加MAC。(G3)网络碎片化会降低并行度 一些网络如Inception,以及Auto ML自动产生的网络NASNET-A,它们倾向于采用“多路”结构,即存在一个lock中很多不同的小卷积或者pooling,这很容易造成网络碎片化,减低模型的并行度,相应速度会慢,这也可以通过实验得到证明。(G4)不能忽略元素级操作 对于元素级(element-wise operators)比如ReLU和Add,虽然它们的FLOPs较小,但是却需要较大的MAC。这里实验发现如果将ResNet中残差单元中的ReLU和shortcut移除的话,速度有20%的提升。
16. 深度网络attention怎么加
17.resnet的结构特点以及解决地问题是什么
复杂问题,越深的网络往往有更好的性能,然而随着网络的加深,训练集的准确率反而下降;可以确定这不是由于Overfit过拟合造成的(过拟合的情况训练集应该准确率很高);所以作者针对这个问题提出了一种全新的网络,叫深度残差网络,它允许网络尽可能的加深。 理论上,对于“随着网络加深,准确率下降”的问题,Resnet提供了两种选择方式,也就是identity mapping和residual mapping,如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
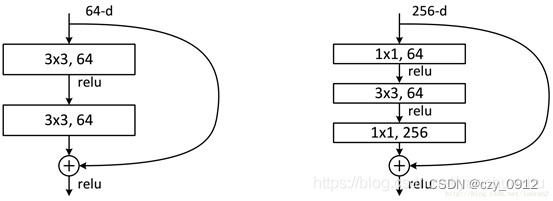
这两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),一般称整个结构为一个”building block“。其中右图又称为”bottleneck design”,目的一目了然,就是为了降低参数的数目。看右图,输入是一个3×3×256的特征,第一个步骤用64个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复到256个channel,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话参考左图,输入假设是3x3x256,第一步经过256个卷积核3×3×256,第二部再经过256个卷积核3×3×256。所以参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
18. 图神经网络的理解
19.unet结构,为什么要下采样,上采样
下采样:
1.降低显存和计算量,图小了占内存也就小了,运算量也少了。2.增大感受野,使同样3*3的卷积能在更大的图像范围上进行特征提取。大感受野对分割任务很重要,小感受野是做不了多类分割的,而且分割出来的掩膜边界很粗糙!3.多出几条不同程度下采样的分支,可以很方便进行多尺度特征的融合。多级语义融合会让分类很准。
上采样:
20.resnet v1到v2有什么改进,下采样过程是什么样的,跳跃链接怎么实现,shape如何保持
21.fpn的结构
FPN 的结构较为简单,可以概括为:特征提取,上采样,特征融合,多尺度特征输出。FPN 的输入为任意大小的图片,输出为各尺度的 feature map。与 U-net 类似, FPN 的整个网络结构分为自底向上 (Bottom-Up) 和自顶向下 (Top-Down) 两个部分,Bottom-Up 是特征提取过程,对应 Unet 中的 Encoder 部分,文中以 Resnet 作为 backbone,Top-Down 将最深层的特征通过层层的上采样,采样至与 Bottom-Up 输出对应的分辨率大小,与之融合后输出 feature map,融合方式为对应位置相加,而 Unet 采用的融合方式为对应位置拼接,关于两者的差异我之前在 Unet 这篇文章中提过,这里就不再赘述。在下图中放大的部分中,包含了 3 个步骤:1. 对上层输出进行 2 倍的上采样,2. 对 Bottom-Up 中与之对应的 feature map 的进行 1x1 卷积,以保证特征 channels 相同,3. 将上面两步的结果相加。
22.roi pooling和roi align的区别
23.resnet的理解和全连接相比有什么区别
24.简述alexnet,vgg,resnet,densenet,googlenet
alexnet:
vgg:
resnet:
densenet:
googlenet:
25.mobileNet v1,v2,shuffleNet v2,xception,denseNet
26.感受野的计算,增加
感受野是卷积神经网络(CNN)每一层输出的特征图(feature map)上的像素点在原始输入图像上映射的区域大小。感受野的计算从最深层开始向浅层计算,逐步计算到第一层(即上图的蓝色层开始向红色层传递计算),所以计算前要知道网络的整体结构和参数。
增加方法:1.增加pooling层,但是会降低准确性(pooling过程中造成了信息损失)2.增大卷积核的kernel size,但是会增加参数 3.增加卷积层的个数,但是会面临梯度消失的问题
27.为什么卷积神经网络适用于图像和视频,还能用于其他领域吗
卷积网络的特点主要是卷积核参数共享,池化操作。参数共享的话的话是因为像图片等结构化的数据在不同的区域可能会存在相同的特征,那么就可以把卷积核作为detector,每一层detect不同的特征,但是同层的核是在图片的不同地方找相同的特征。然后把底层的特征组合传给后层,再在后层对特征整合(一般深度网络是说不清楚后面的网络层得到了什么特征的)。而池化主要是因为在某些任务中降采样并不会影响结果。所以可以大大减少参数量,另外,池化后在之前同样大小的区域就可以包含更多的信息了。综上,所有有这种特征的数据都可以用卷积网络来处理。
28.CNN反向传播细节,怎么过全连接层池化层卷积层
29.CNN里能自然起到防止过拟合的办法
正则化是指修改学习算法,使其降低泛化误差而非训练误差。常用的正则化方法根据具体的使用策略不同可分为:(1)直接提供正则化约束的参数正则化方法,如L1/L2正则化;(2)通过工程上的技巧来实现更低泛化误差的方法,如提前终止(Early stopping)和Dropout;(3)不直接提供约束的隐式正则化方法,如数据增强等。
30.CNN中感受野权值共享是什么意思
把局部连接(感受野)中的每一个卷积核中对应的权值进行共享,就可以进一步减少网络中参数的个数,即下一层每一个像素点是由上一层对应位置的N×N的局部区域图片(也就是感受野)与同一卷积核N×N的权值做内积,加 偏置后 再 经过非线性映射 而来的,至此,网络训练参数的数量不再受原始输入图片大小的影响(因为卷积核固定了,里边的权值多少也就固定了)。
把局部连接(感受野)中的每一个卷积核中对应的权值进行共享,就可以进一步减少网络中参数的个数,即下一层每一个像素点是由上一层对应位置的N×N的局部区域图片(也就是感受野)与同一卷积核N×N的权值做内积,加 偏置后 再 经过非线性映射 而来的,至此,网络训练参数的数量不再受原始输入图片大小的影响(因为卷积核固定了,里边的权值多少也就固定了)
31.BN层的作用,为什么有这个作用,训练和测试时有什么不同,在测试时怎么使用
BN作用是收敛速率增加,可以达到更好的精度。
BN层是一种数据归一化方法,往往用在深度神经网络中激活层之前。其作用可以加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失。并且起到一定的正则化作用,几乎代替了Dropout。

归一化的目的:将数据规整到统一区间,减少数据的发散程度,降低网络的学习难度。BN的精髓在于归一之后,使用r,b作为还原参数,在一定程度上保留原数据的分布。
神经网络中传递的张量数据,其维度通常记为[N, H, W, C],其中N是batch_size,H、W是行、列,C是通道数。
训练时,均值、方差分别是该批次内数据相应维度的均值与方差;推理时,均值、方差是基于所有批次的期望计算所得。
import tensorflow as tf
from tensorflow.python.training import moving_averages
def batch_normalization(input, is_training, name="BN",
moving_decay=0.999, eps=1e-5):
input_shape = input.get_shape()
params_shape = input_shape[-1]
axis = list(range(len(input_shape) - 1))
with tf.variable_scope(name, reuse=tf.AUTO_REUSE) as scope:
beta = tf.get_variable('beta',
params_shape,
initializer=tf.zeros_initializer)
gamma = tf.get_variable('gamma',
params_shape,
initializer=tf.ones_initializer)
moving_mean = tf.get_variable('moving_mean',
params_shape,
initializer=tf.zeros_initializer,
trainable=False
)
moving_var = tf.get_variable('moving_var',
params_shape,
initializer=tf.ones_initializer,
trainable=False
)
def train():
# These ops will only be preformed when training.
mean, var = tf.nn.moments(input, axis)
update_moving_mean = moving_averages.assign_moving_average(moving_mean,
mean,
moving_decay)
update_moving_var = moving_averages.assign_moving_average(
moving_var, var, moving_decay)
return tf.identity(mean), tf.identity(var)
mean, var = tf.cond(tf.equal(is_training, True), train,
lambda: (moving_mean, moving_var))
return tf.nn.batch_normalization(input, mean, var, beta, gamma, eps)
32.BN层做预测的时候,方差均值怎么算,online learning的时候怎么算
训练时,均值、方差分别是该批次内数据相应维度的均值与方差;推理时,均值、方差是基于所有批次的期望计算所得
33.BN机制,BN怎么训练
BN(Batch Normalization)层的作用(1)加速收敛,防止梯度消失(2)控制过拟合,可以少用或不用Dropout和正则(3)降低网络对初始化权重不敏感(4)允许使用较大的学习率
对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是说收敛地快。方法很简单,道理很深刻。
就是说经过BN后,目前大部分Activation的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
34.发生梯度消失,梯度爆炸的原因,如何解决
梯度消失:产生的原因有:一是在深层网络中,二是采用了不合适的损失函数
梯度爆炸:一般出现在深层网络和权值初始化值太大的情况下。在深层神经网络或循环神经网络中,误差的梯度可在更新中累积相乘。如果网络层之间的梯度值大于 1.0,那么重复相乘会导致梯度呈指数级增长,梯度变的非常大,然后导致网络权重的大幅更新,并因此使网络变得不稳定。梯度爆炸会伴随一些细微的信号,如:①模型不稳定,导致更新过程中的损失出现显著变化;②训练过程中,在极端情况下,权重的值变得非常大,以至于溢出,导致模型损失变成 NaN等等。
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。解决梯度消失、爆炸主要有以下几种方法:(1) pre-training+fine-tunning (2) 梯度剪切:对梯度设定阈值 (3) 权重正则化 (4) 选择relu等梯度大部分落在常数上的激活函数 (5) batch normalization (6) 残差网络的捷径(shortcut) (7)LSTM的“门(gate)”结构
35. CNN网络很大,手机上运行效率不高,如何模型压缩
36 欠拟合、过拟合及如何防止过拟合
对训练数据集有很好的拟合(训练误差),同时也希望它可以对未知数据集(测试集)有很好的拟合结果(泛化能力),所产生的测试误差被称为泛化误差。度量泛化能力的好坏,最直观的表现就是模型的过拟合(overfitting)和欠拟合(underfitting)
欠拟合:通过增加网络复杂度或者在模型中增加特征
过拟合:原因:训练数据集样本单一,样本不足;训练数据中噪声干扰过大;模型过于复杂;1.增加数据 2.采用合适的模型(控制模型的复杂度)3.降低特征的数量 4.L1 / L2 正则化 5.dropout 6.Early stopping(提前终止)
CNN在图像识别的过程中有强大的“不变性”规则,即待辨识的物体在图像中的形状、姿势、位置、图像整体明暗度都不会影响分类结果。我们就可以通过图像平移、翻转、缩放、切割等手段将数据库成倍扩充