安装 Ollama
根据官网指导,安装对应版本即可。
下载安装指导文档:
handy-ollama/docs/C1/1. Ollama 介绍.md at main · datawhalechina/handy-ollama
注意:在 Windows 下安装 Ollama 后,强烈建议通过配置环境变量来修改模型存储位置,不然就会默认存储在 C 盘目录下,而大模型文件一般都比较大。
知识库问答助手
架构图
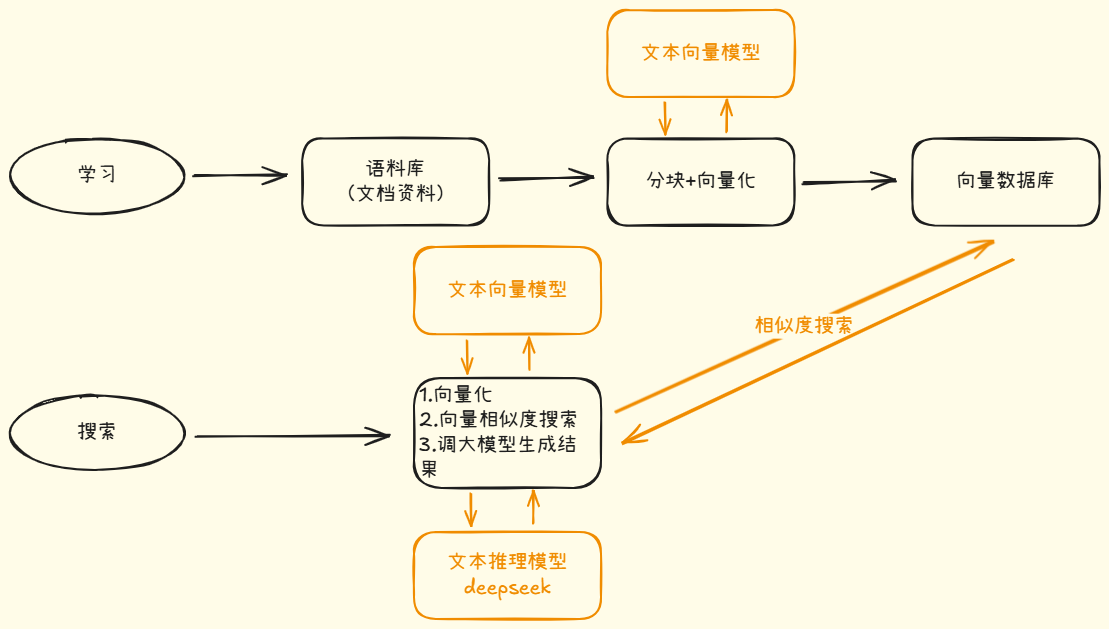
RAG 知识库架构图如下:
知识库

知识库分块
功能:读取知识库文本文件,并将内容分割成多个段落块。
# 1、读取文件内容
with open("knowledge/中医v1.txt", encoding="utf-8", mode="r") as fp:
data = fp.read()
# 2、根据换行分割
chunk_list = data.split("\n\n")
chunk_list = [chunk for chunk in chunk_list if chunk]
print(chunk_list)
文本向量化
功能:将分块后的文本,通过调用文本向量模型,进行向量化。
import requests
text = "感冒发烧"
res = requests.post(
url="http://127.0.0.1:11434/api/embeddings",
json={
"model": "nomic-embed-text",
"prompt": text
},
)
embedding_list = res.json()['embedding']
print(text)
print(len(embedding_list), embedding_list)
向量数据库
功能:将文本向量化后,存储到向量数据库中,这里用 Chroma 向量数据库,支持通过语义相似度进行搜索。
import uuid
import chromadb
import requests
def ollama_embedding_bye_api(text):
res = requests.post(
url="http://127.0.0.1:11434/api/embeddings",
json={
"model": "nomic-embed-text",
"prompt": text
},
)
embedding_list = res.json()['embedding']
return embedding_list
client = chromadb.PersistentClient(path="db/chroma_demo")
collection = client.get_or_create_collection(name="collection_v1")
documents = ["风寒感冒", "寒邪客胃", "心脾两虚"]
ids = [str(uuid.uuid4()) for _ in documents]
embeddings = [ollama_embedding_bye_api(text) for text in documents]
# 插入数据
collection.add(
ids=ids,
documents=documents,
embeddings=embeddings
)
# 关键字搜索
qs = "感冒胃疼"
qs_embedding = ollama_embedding_bye_api(qs)
res = collection.query(query_embeddings=[qs_embedding, ], query_texts=qs, n_results=2)
print(res)
推理模型
功能:调用 AI 大模型,实现文本生成功能
import requests
prompt = "今天天气怎么样"
response = requests.post(
url="http://127.0.0.1:11434/api/generate",
json = {
"model": "deepseek-r1:1.5b",
"prompt": prompt,
"stream": False
}
)
res = response.json()['response']
print(res)
集成
完整代码:
import uuid
import chromadb
import requests
def file_chunk_list():
# 1、读取文件内容
with open("knowledge/中医v1.txt", encoding="utf-8", mode="r") as fp:
data = fp.read()
# 2、根据换行分割
chunk_list = data.split("\n\n")
chunk_list = [chunk for chunk in chunk_list if chunk]
return chunk_list
def ollama_embedding_bye_api(text):
res = requests.post(
url="http://127.0.0.1:11434/api/embeddings",
json={
"model": "nomic-embed-text",
"prompt": text
},
)
embedding_list = res.json()['embedding']
return embedding_list
def ollama_generate_by_api(prompt):
response = requests.post(
url="http://127.0.0.1:11434/api/generate",
json={
"model": "deepseek-r1:1.5b",
"prompt": prompt,
"stream": False
}
)
res = response.json()['response']
return res
def initial():
client = chromadb.PersistentClient(path="db/chroma_demo")
# 创建集合
# client.delete_collection("collection_v2")
collection = client.get_or_create_collection(name="collection_v2")
# 构造数据
documents = file_chunk_list()
ids = [str(uuid.uuid4()) for _ in range(len(documents))]
embeddings = [ollama_embedding_bye_api(text) for text in documents]
# 插入数据
collection.add(
ids=ids,
documents=documents,
embeddings=embeddings,
)
def run():
# 关键字搜索
qs = "风寒感冒"
qs_embedding = ollama_embedding_bye_api(qs)
client = chromadb.PersistentClient(path="db/chroma_demo")
collection = client.get_collection(name="collection_v2")
res = collection.query(query_embeddings=[qs_embedding, ], query_texts=qs, n_results=2)
result = res["documents"][0]
context = "\n".join(result)
print(context)
prompt = f"""你是一个中医问答机器人,任务是根据参考信息回答用户问题,如果参考信息不足以回答用户问题,请回复不知道,不要去杜撰任何信息
参考信息:{context},来回答问题:{qs},
"""
result = ollama_generate_by_api(prompt)
print(result)
if __name__ == "__main__":
initial()
run()
项目参考:
【大模型RAG完整教程】手把手带你结合项目实战,完成一套完整的RAG项目!增加检索/文本向量/知识库搭建_哔哩哔哩_bilibili