Python爬虫——使用socket模块进行图片下载
- 什么是socket
- 爬虫的工作流程
- socket爬取图片
- 为什么能用socket能下载图片
- socket下载图片和request下载图片的区别
- 使用socket下载一张图片
- 使用socket下载多张图片
- 方法1
- 方法2
什么是socket
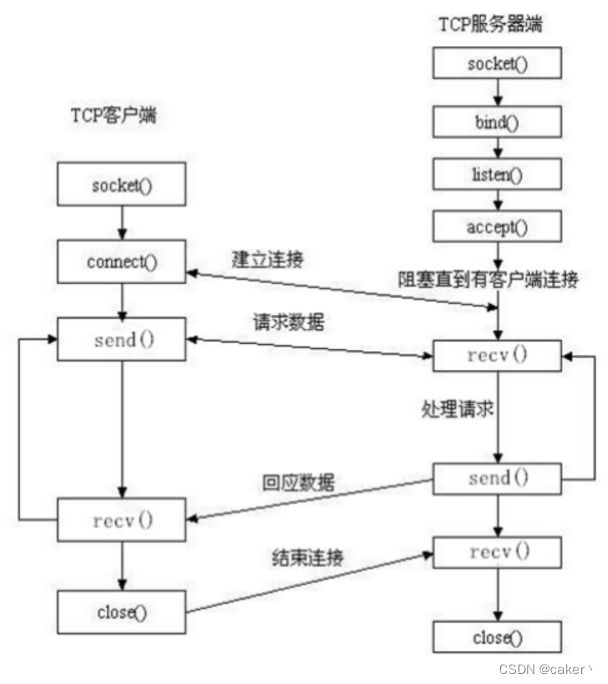
Socket 是一种通信机制,用于实现网络上的进程间通信。它是一种应用层协议,通常基于 TCP/IP 协议栈,可以在不同的计算机之间进行通信。Socket 本质上是一个文件描述符,它提供了一组用于网络通信的 API 接口,可以进行数据传输、建立连接、监听端口等操作。
使用 Socket 可以实现不同计算机之间的进程间通信,例如客户端和服务器之间的通信,也可以实现同一计算机内不同进程之间的通信。Socket 可以支持不同的传输协议,例如 TCP 和 UDP,可以根据需要选择不同的协议来进行通信。
在 Python 中,使用 socket 模块可以实现 Socket 编程,可以创建客户端和服务器端程序,进行网络通信。Socket 编程可以用于开发网络应用程序,例如网络爬虫、聊天室、文件传输等。
| 方法 | 描述 |
|---|---|
| connect( (host,port) ) | host代表服务器主机名或IP,port代表服务器进程所绑定的端口号。 |
| send | 发送请求信息 |
| recv | 接收数据 |
爬虫的工作流程
爬虫的工作流程
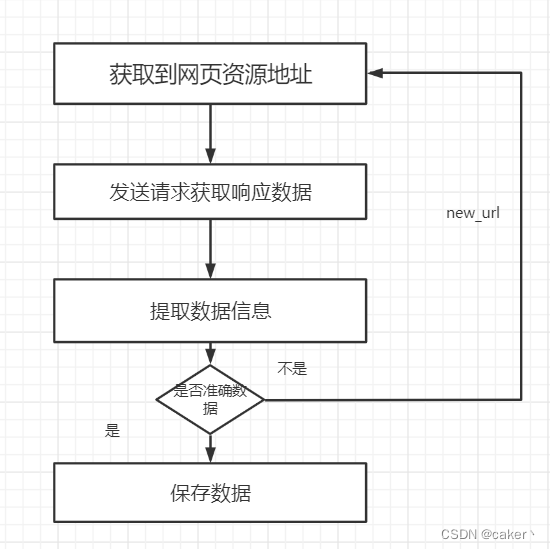
- 获取到资源地址:
爬虫首先要做的工作就是获取数据的资源地址,有了准确的地址之后我们才能数据去进行发送请求
- 发送请求获取数据
第二步要做的工作就是获取网页,这里就是获取网页的源代码。源代码里包含了网页的部分有用信息,所以 只要把源代码获取下来,就可以从中提取想要的信息了。
- 反爬虫处理:
有些网站会采取反爬虫措施,例如设置访问频率限制、验证码等,需要针对这些措施进行处理,以保证爬虫程序的正常运行。可以使用 Python 的验证码识别等技术来处理反爬虫措施。
- 提取信息:
获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据。首先,最通用的方法便是采用正则表达式提取,这是一个万能的方法,但是在构造正则表达式时比较复杂且容易出错。 另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、CSS选择器或 XPath来提取网页信息的库,如Beautiful Soup、pyquery、lxml 等。使用这些库,我们可以高效快速地从中提取网页信 息,如节点的属性、文本值等。 提取信息是爬虫非常重要的部分,它可以使杂乱的数据变得条理清晰,以便我们后续处理和分析数据。
- 保存数据:
提取信息后,我们一般会将提取到的数据保存到某处以便后续使用。这里保存形式有多种多样,如可以简单保 存为 TXT 文本或 JSON 文本,也可以保存到数据库,如 MySQL 和 MongoDB 等,也可保存至远程服务 器,如借助 SFTP 进行操作等。
- 爬虫控制:
爬虫程序需要控制爬取的网页数量和频率,以避免对目标网站造成过大的负荷。可以使用 Python 的多线程或者多进程来实现并发爬取,也可以使用时间控制来控制爬取频率。
- 数据分析:
获取到数据后,可以进行数据分析和处理,例如数据可视化、机器学习、自然语言处理等,以得到更有价值的信息。
socket爬取图片
为什么能用socket能下载图片
使用 Socket 可以下载图片的原因是因为 HTTP 协议是基于 Socket 的应用层协议,它使用 TCP/IP 协议族来传输数据。在 HTTP 协议中,客户端通过 Socket 建立连接到服务器,发送请求,服务器接收请求并返回响应,客户端接收响应并处理响应数据。
由于 HTTP 协议是基于 Socket 的,所以使用 Socket 可以直接发送 HTTP 请求和接收 HTTP 响应,实现数据的传输和下载。使用 Socket 下载图片需要手动构造 HTTP 请求和解析 HTTP 响应,需要编写更多的代码来处理数据传输和错误处理,但是相对于其他下载方式,使用 Socket 可以更加灵活和自定义,可以实现更多的功能和应用场景。
socket下载图片和request下载图片的区别
Socket 和 Request 都可以用于下载图片,但是它们的实现方式和用途略有不同。
Socket 是一种底层的网络通信协议,它可以在应用层和传输层之间建立连接,进行数据传输。使用 Socket 下载图片需要手动构建 HTTP 请求和解析 HTTP 响应,需要编写更多的代码来处理数据传输和错误处理。Socket 更适合于底层网络通信的应用,如实现自定义协议、网络游戏等。
Request 是一个 Python 库,它封装了 HTTP 请求和响应的处理,可以方便地进行网络请求。使用 Request 下载图片只需要简单的代码就可以完成,而且可以方便地设置请求头、请求参数等信息。Request 更适合于开发网络爬虫、数据采集等应用。
总的来说,使用 Socket 下载图片更加底层、灵活,但需要编写更多的代码;使用 Request 下载图片更加高层、方便,但可能会有一些限制。选择使用哪种方式,取决于具体的需求和应用场景。
用代码举例说明:
使用 Socket下载图片:
import socket
# 构造 HTTP 请求
request = b"GET /images/test.jpg HTTP/1.1\r\nHost: example.com\r\n\r\n"
# 建立连接并发送请求
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("example.com", 80))
s.send(request)
# 接收响应并保存图片
response = s.recv(4096)
while response:
if b"Content-Type: image/jpeg" in response:
with open("test.jpg", "wb") as f:
f.write(response)
break
response = s.recv(4096)
# 关闭连接
s.close()
使用 Request 下载图片:
import requests
# 发送请求并保存图片
response = requests.get("http://example.com/images/test.jpg")
with open("test.jpg", "wb") as f:
f.write(response.content)
可以看到,使用 Request 下载图片更加简单和方便,而使用 Socket 则需要手动构建 HTTP 请求和解析 HTTP 响应,需要更多的代码和处理过程。
使用socket下载一张图片
以图片http://image11.m1905.cn/uploadfile/2021/0922/thumb_0_647_500_20210922030733993182.jpg为例。
想要使用socket下载这张图片,具体步骤如下:
-
获取到资源地址 url。
-
创建 Socket 客户端对象 client,并连接到服务器 image11.m1905.cn 的端口 80。
-
构造 HTTP 请求,包括请求方法、请求地址、请求协议版本、请求头等信息,并发送请求。
-
循环接收服务器响应,并将响应数据添加到二进制对象 result 中。
-
使用正则表达式提取响应数据中的图片数据,即去掉响应头部分。
-
将图片数据存储到本地文件中,即下载图片到本地。
代码如下:
import socket
import re
import time
# 获取到资源地址
url = 'http://image11.m1905.cn/uploadfile/2021/0922/thumb_0_647_500_20210922030733993182.jpg'
start = time.time()
# 创建套接字对象
client = socket.socket()
# 创建连接
client.connect(('image11.m1905.cn', 80))
# 构造http请求
http_res = 'GET ' + url + ' HTTP/1.0\r\nHost: image11.m1905.cn\r\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36\r\n\r\n'
# print(http_res)
# 发送请求
client.send(http_res.encode())
# 建立一个二进制对象用来存储我们得到的数据
result = b''
data = client.recv(1024)
# 循环接收响应数据 添加到bytes类型
while data:
result += data
data = client.recv(1024)
# print(result)
# 提取数据
# re.S使 . 匹配包括换行在内的所有字符去掉响应头
images = re.findall(b'\r\n\r\n(.*)', result, re.S)
# print(images[0])
# 打开一个文件,将我们读取到的数据存入进去,即下载到本地我们获取到的图片
with open('小姐姐.png', 'wb')as f:
f.write(images[0])
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start # 计算代码执行时间
print(f'All images downloaded successfully in {elapsed_time:.2f} seconds')
使用socket下载多张图片
假设我们想使用socket下载多张图片,我这里给出两种实现方法。
方法1
将需要下载的url做成一个列表,再使用split函数将url中的/进行分割,然后通过切片方法得到url中的相对路径和host值,最后通过循环遍历url列表,达到下载多张图片的效果。代码如下
import socket
import re
import time
start = time.time()
# 获取到的资源地址
urls = [
'https://pic.netbian.com/uploads/allimg/220211/004115-1644511275bc26.jpg',
'https://pic.netbian.com/uploads/allimg/220215/233510-16449393101c46.jpg',
'https://pic.netbian.com/uploads/allimg/211120/005250-1637340770807b.jpg'
]
# 创建连接
for url in urls:
# 解析URL
parts = url.split('/') # ['https:', '', 'pic.netbian.com', 'uploads', 'allimg', '220211', '004115-1644511275bc26.jpg']
host = parts[2] # pic.netbian.com
path = '/' + '/'.join(parts[3:]) # /uploads/allimg/220211/004115-1644511275bc26.jpg
# print(parts)
# print(host)
# print(path)
# 创建套接字对象连接到主机
client = socket.socket()
client.connect((host, 80))
# 构造HTTP请求
http_req = f'GET {path} HTTP/1.1\r\nHost: {host}\r\nuser-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' \
f'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36\r\nConnection: close\r\n\r\n '
# print(http_req)
# 发送请求
client.sendall(http_req.encode())
# 接受响应数据
result = b''
data = client.recv(1024)
while data:
result += data
data = client.recv(1024)
# 提取图像数据
images = re.findall(b'\r\n\r\n(.*)', result, re.S)
# print(images[0])
# 写入文件
if images:
with open(f'{parts[-1]}', 'wb') as f:
f.write(images[0])
else:
print(f'No image data received for {url}')
# 关闭连接
client.close()
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start # 计算代码执行时间
print(f'All images downloaded successfully in {elapsed_time:.2f} seconds')
方法2
通过创建线程池,使用多线程的方式同时下载所有图片。
代码如下:
import socket
import re
import multiprocessing
import time
def download_image(url):
# 解析URL
parts = url.split('/')
host = parts[2]
path = '/' + '/'.join(parts[3:])
# 创建套接字对象连接到主机
client = socket.socket()
client.connect((host, 80))
# 构造HTTP请求
http_req = f'GET {path} HTTP/1.1\r\nHost: {host}\r\nuser-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' \
f'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36\r\nConnection: close\r\n\r\n '
# 发送请求
client.sendall(http_req.encode())
# 接受响应数据
result = b''
data = client.recv(1024)
while data:
result += data
data = client.recv(1024)
# 提取图像数据
images = re.findall(b'\r\n\r\n(.*)', result, re.S)
# 写入文件
if images:
with open(f'{parts[-1]}', 'wb') as f:
f.write(images[0])
else:
print(f'No image data received for {url}')
# 关闭连接
client.close()
if __name__ == '__main__':
start = time.time()
urls = [
'https://pic.netbian.com/uploads/allimg/220211/004115-1644511275bc26.jpg',
'https://pic.netbian.com/uploads/allimg/220215/233510-16449393101c46.jpg',
'https://pic.netbian.com/uploads/allimg/211120/005250-1637340770807b.jpg'
]
# 创建进程池
pool = multiprocessing.Pool(processes=3)
# 同时下载所有图片
pool.map(download_image, urls)
# 关闭进程池
pool.close()
pool.join()
end = time.time()
elapsed_time = end - start # 计算代码执行时间
print(f'All images downloaded successfully in {elapsed_time:.2f} seconds')