最近一直有社区的小伙伴问,我们很感兴趣CnosDB,但从何开始阅读CnosDB的代码呢,其实这个问题在之前的CnosDB HiTea直播时就有聊到,今天我们就再来回顾一下。
CnosDB的源代码主要分为Query Engine和Storage Engine。Query Engine在query_sever下,里面是query相关的代码。Storage Engine在tskv目录下,主要是时序存储相关的代码。
Query Engine的源码阅读

CnosDB查询步骤大致如下:
1.解析SQL语句成Statement
2.根据Statement生成逻辑计划
3.基于规则优化查询逻辑计划
4.根据逻辑计划生成物理计划
5.基于代价优化物理计划
6.执行计划
其中DDL语句没有3、4、5步骤
CnosDB查询请求的入口代码在 main/src/http/http_service.rs 中的query函数下。一次http的query请求中,参数携带用户和DB名, 根据此进行用户认证,并生成执行SQL的上下文。在 query_server/query/src/dispatcher/manager.r 的execute_query函数下开始处理SQL。
1.解析SQL。解析成ExtStatement这个结构体,该结构体代表SQL的语法树。ExtStatement 结构体可以在query_server/spi/src/query/ast.rs 看到。大致分为两类,一类是DQL和DML,其中包括SELECT、 INSERT语句,另一类是DDL,包括CREATE、 DROP语句。
2.生成逻辑计划。是根据Statement生成逻辑计划,转换的这部分代码在 query_server/query/src/sql/planner.rs。在生成逻辑计划时,会对元数据进行访问,来判断Statement的语义是否正确。
3.优化逻辑计划。这部分的入口代码在 query_server/query/src/execution/query.rs 和 query_server/query/src/sql/optimizer.rs中。逻辑计划的优化是基于规则的,包括谓词下推、简化表达式等规则。其中DDL语句,不需要优化逻辑计划,跳过3、4、5步。
4.逻辑计划转物理计划。比如连接就有排序连接,哈希连接等不同实现
5.优化物理计划。物理计划的优化是基于代价的,比如根据表的数据量优化连接的主表,这步的入口代码在 query_server/query/src/sql/optimizer.rs 处。
6.执行计划。DDL的执行大多是访问元数据并修改,这部分代码在 query_server/query/src/execution/ddl 中。而DQL往往是扫描表,并用谓词过滤,中间可能有连接操作,投影操作,聚合操作。其中最基础的步骤就是扫描表(TableScan),TableScan会生成一个表数据的迭代器,迭代器的操作元素是RecordBatch(是一种DataFrame结构)。之后在迭代器返回的RecordBatch上执行操作。这些操作包括过滤,连接,聚合,并且往往是向量化执行的。
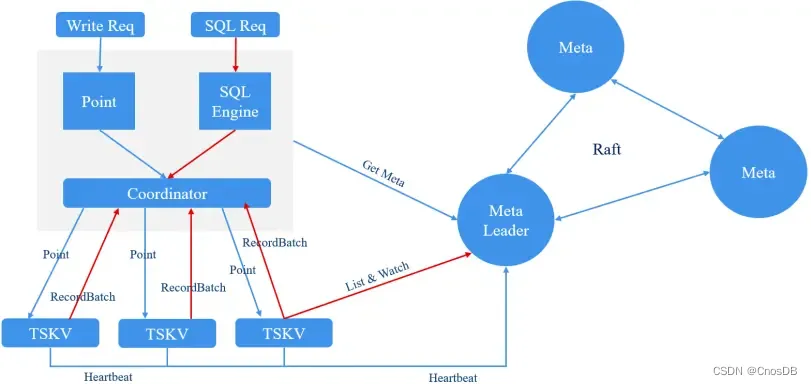
数据流程图
Storage Engine的源码阅读

关于TSKV提供的接口,可以查看 tskv/src/engine.rs 。我们可以从Storage Engine的写入接口开始了解TSKV的工作原理,接口的实现在 tskv/src/kvcore.rs。写入接口接受一个write_batch作为写入的数据,write_batch为flatbuffers生成的代码,原始的fbs文件以及一些grpc定义可以在 common/protos/proto 中找到。从write_batch中可以获取db、table以及真正写入的数据。在写入之前,会根据write_batch生成write_group,具体的实现可以看 tskv/src/database.rs,在写入内存之前,会先写WAL,保证数据恢复,WAL会写入经过压缩后的point以及生成seq,代码实现在 tskv/src/wal.rs。
写完WAL后,开始写入内存,首先会根据write接口传入的参数获取具体的tsfamily,tsfamily为真正的存储单元,具体实现的逻辑位于 tskv/src/tseries_family.rs。数据写入内存后会根据配置项检查是否应该开始进行flush,将数据写入磁盘,满足flush条件的话会开始进行flush,flush代码的实现可以看 tskv/src/compaction/flush.rs。flush过后,首先会发送summmary edit请求,summmary edit主要用来标记哪些数据以及被flush,恢复重启时可以不用写入这些数据,summary有关的逻辑可以查看 tskv/src/summary.rs。compaction会对磁盘中的数据文件进行合并,具体的compaction逻辑可以在 tskv/src/compaction/compact.rs 中看到。
关于分布式
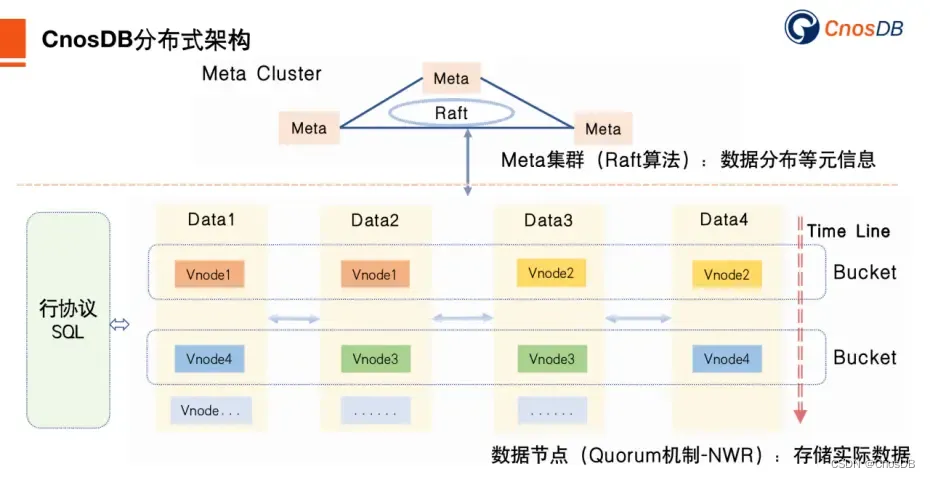
我们还想讲一讲CnosDB的分布式功能。CnosDB分布式由两类节点组成:Meta节点与Data节点。Meta节点用于存储集群相关的元信息,像数据位置分布、Data节点信息、用户权限、DB、Table等相关信息;Meta是基于Raft实现的一套CP存储系统,保证元信息存储高可用强一致性。Data节点用于数据的存储与查询,当前存储与查询相关功能都在Data节点实现;后期可能会做计算、存储分离,存储功能单独一个进程,无状态的计算节点单独进程。
CnosDB的数据分片规则是根据时序数据特有的特点采取基于time-range方式分片。每隔一段时间创建一个bucket(是一个虚拟的逻辑单元),每个Bucket又根据Data节点个数以及副本数创建多个Vnode,每个Vnode是一个单独的LSM Tree ,对应 TSFamily 结构体,是一个独立的运行单元,分布到Data节点上存储数据。为了确保数据容灾的有效性,Meta节点在创建Bucket分配Vnode的时候,可能需要根据机架、电源、控制器和物理位置等信息进行权衡。

CnosDB的数据读写流程是数据写入时根据数据的时间戳确定写入哪个Bucket,然后再根据Hash算法确定写入哪个Vnode以及对应的副本当中。数据读取时,查询引擎解析完SQL后根据过滤条件确定读取的Vnode进行读取,然后汇总结果返回。
CnosDB支持 Hinted Handoff。当跨节点的数据副本写入失败时,会写本地磁盘文件,待网络恢复后再写入目的节点。Hinted Handoff提高写的高可用性。在公有云环境下,网络抖动和Region之间的网络不稳定的情况,具有较大的收益。
小结
本篇文章主要介绍了CnosDB 中 查询、存储和分布式三大 模块的代码结构。更多的代码阅读内容会在后面的章节中逐步展开,敬请期待。
CnosDB简介
CnosDB是一款高性能、高易用性的开源分布式时序数据库,现已正式发布及全部开源。
欢迎关注我们的社区网站:https://www.cnosdb.com