写在前面:在上次我们学习了指针的相关类型的知识,对指针家族的成员基本有了了解,这次让我们跟着一些题目来练习和补充一些知识,这有助于我们强化理解这些知识。
话不多说,我们马上开始:
1.指针和数组的笔试题解析
1.1一维数组
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a));
printf("%d\n",sizeof(a+0));
printf("%d\n",sizeof(*a));
printf("%d\n",sizeof(a+1));
printf("%d\n",sizeof(a[1]));
printf("%d\n",sizeof(&a));
printf("%d\n",sizeof(*&a));
printf("%d\n",sizeof(&a+1));
printf("%d\n",sizeof(&a[0]));
printf("%d\n",sizeof(&a[0]+1));先来给出输出结果:
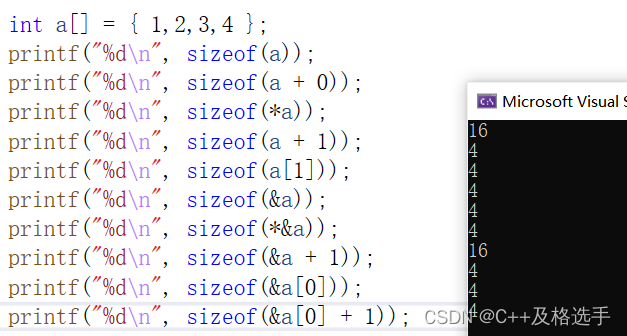
这里我们来挑些易错的进行分析和讲解:
1.sizeof(a):这个不用多说,我们都知道一维数组的数组名表示首地址,但是前面我们了解到了有两个特殊的情况,一种是sizeof(数组名)的时候表示的是整个数组中的所有元素所占的总字节数,还有一种就是&(数组名)的时候,取出的是整个数组的地址,虽然和数组首元素地址相同,但是它加1跳过的是一整个数组的长度,而普通的数组名加1只是跳到数组的下一个元素而已;
2.sizeof(a+0):这个和sizeof(a)不是一样的......吗?稍等,你要是这么认为你就错了,让我们来慢慢分析,首先,我们应该知道sizeof这个函数的一些原理,sizeof计算的是括号内所占的内存的空间的大小,单位是字节,不关注内存中到底存放的是什么,sizeof是操作符,并不是函数,
我们说,sizeof内部只有单独放一个数组名的时候才表示数组首元素的地址,但是它现在加了0,所以就变成了数组首元素的地址加了0,其结果导致其变成了地址的运算,也就间接导致了sizeof认为现在在他要算的其实就是一个指针变量而已,并不是一个数组,所以,sizeof会返回数字4(x86,32位环境下)或者是(x64,64位环境下);
3.sizeof(*a): 首先我们来看,该括号里面既不是只有数组名,也不是取地址数组名,所以,括号里的a就表示数组首元素的地址,对其解引用,就得到a[0]的值,也就是四个字节的int型 ;
4.sizeof(a+1):同上原理,现在a表示的是数组首元素的地址,所以我们的加1操作就是得到了第二个元素的地址,所以返回值为指针大小(4或8);
5.szieof(&a):现在有了取地址数组名,所以我们现在&a表示的是整个数组的地址,但是sizeof计算的仍然是指针大小,即4或8;
6.sizeof(*&a):我们规定,解引用操作与取地址操作可以相互抵消,所以返回的相当于sizeof(a);
7.sizeof(&a+1):整个数组的地址加1,将会跳过一个数组的字节数的步长,现在的指针指向的是a数组的最后一个元素的末尾,但是其本身还是地址,所以其返回值仍然为指针的大小;
1.2 字符数组
什么?你说上面的题没难住你?那接下来就会更难些了,准备好我们就出发吧......
温馨提示:这边由于c和c++存在不兼容问题,导致strlen函数在cpp文件运行时会出现问题,我这边用.c文件进行编译运行
//1.
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr + 0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr + 1));
printf("%d\n", sizeof(&arr[0] + 1));
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));
//2.
char arr[] = "abcdef";
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr + 0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr + 1));
printf("%d\n", sizeof(&arr[0] + 1));
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));
//3.
char* p = "abcdef";
printf("%d\n", sizeof(p));
printf("%d\n", sizeof(p + 1));
printf("%d\n", sizeof(*p));
printf("%d\n", sizeof(p[0]));
printf("%d\n", sizeof(&p));
printf("%d\n", sizeof(&p + 1));
printf("%d\n", sizeof(&p[0] + 1));
printf("%d\n", strlen(p));
printf("%d\n", strlen(p + 1));
printf("%d\n", strlen(*p));
printf("%d\n", strlen(p[0]));
printf("%d\n", strlen(&p));
printf("%d\n", strlen(&p + 1));
printf("%d\n", strlen(&p[0] + 1));首先,我们来看一下sizeof和strlen有什么不同
1.sizeof计算占用内存空间的大小,单位是字节,不关注内存中到底放的是什么,也不会对内存中的表达式进行求值;
2.sizeof是操作符,strlen是函数;
3.strlen是针对字符串的,本质上是求出在'\0'之前出现的字符的个数。
1.2.1 第一部分
运行结果:

我们来分析一下:
首先,字符数组和字符串的区别:有无’\0',这个比较重要,对于sizeof来说,不管有无'\0'它都会正确的计算字节数并返回,对于strlen来说,没有'\0',相当于字符串没有终止标志,得到的可能就是一个随机值。
1.sizeof(arr + 0):我们说sizeof括号内部只有单独放着数组名或者&(数组名)的时候不一样,那么现在加了0,会不会相当于没加呢?不如这样,我们来调试一个就知道了,

上面的调试显示出了arr和arr+0明显是两个不同的变量,arr+0表示的是第一个元素的地址,arr则表示的是整个数组,所以sizeof(arr)就是返回int*的大小,4或8;
2.sizeof(*arr):此时arr表示的由整个数组的范围缩减到了数组首元素的地址,*a=*(&a[0])=a[0],所以返回char类型的大小1;
3.sizeof(&arr),相当于整个数组的地址,但是其本质上还是指针,所以大小固定为4或8个字节;
4.sizeof(&arr+1):这个&arr+1其实是指向了非法内存arr末尾元素的下一个地址,但是sizeof不会管那么多
5.sizeof(&arr[0]+1):这个无可厚非,表示的是第二个元素的地址,4或8个字节
6.strlen(arr):此处arr为字符数组,意味不知道终止符'\0'的位置,所以该返回值为随机值
7.strlen(arr+0):此处相当于将arr[0]传入strlen,返回值和strlen(arr)一样为随机值
8.strlen(*arr):*arr=*(&arr[0])=a[0]='a'=97,strlen会将97作为地址进行寻找,形成非法访问操作,
9.strlen(&arr):也为随机值,&arr拿到的就是整个数组的地址,也是从arr[0]开始数,所以拿到的随机值应和6,7保持一致
10.strlen(&arr+1):随机值,与前面的随机数长度差6(一个字符数组的长度)
11.strlen(&arr[0]+1):随机值,与6,7,9中的随机值相差1,

1.2.2 第二部分
运行结果:

几点需要注意:
1.sizeof(arr)会计算'\0'字符;
2.sizeof(arr+0)表示的是&arr[0];
3.sizeof(*arr)表示的是sizeof(arr[0]);
4.&arr,&arr+1,&arr[0]+1分别为整个字符串的地址,监视窗口如下:
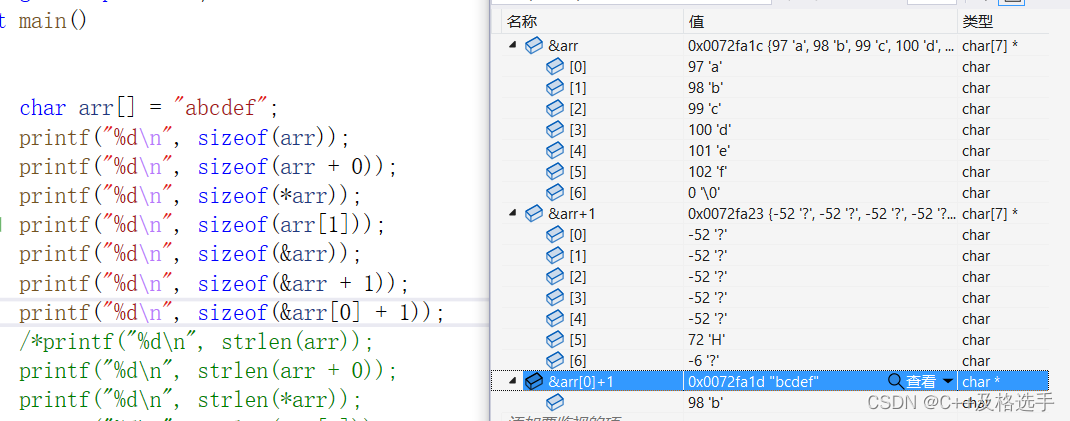
注意此时&arr+1是跳过了'\0',直接取到了'\0'的后面的位置(可以由两处起始地址的差值来求)
5.strlen不和sizeof一样,没有arr和arr+0的区分,对于strlen都一样
6.strlen(&arr)=strlen(arr),不建议使用
7.strlen(&arr+1):指向了字符串的'\0'的后面,返回随机值;
8.strlen(&arr[0]+1)=strlen(&arr[1])=6-1=5;
1.2.3 第三部分
输出结果:

1.p中存储的是字符串首元素的地址,p=&'a';
2.p+1为字符'b'的地址
3.&p,&p+1均与原字符串无关
4.&p[0]+1=&'a'+1=&'b';
1.3 二维数组
关于指针的问题,最抽象和难理解的也就是二维数组的相关操作了吧,不要着急,我们来边看题目边分析,
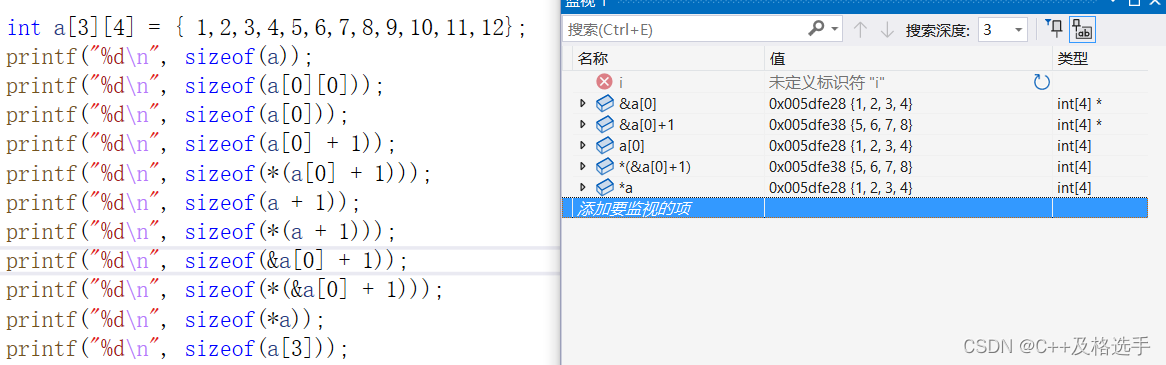
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(a[0][0]));
printf("%d\n", sizeof(a[0]));
printf("%d\n", sizeof(a[0] + 1));
printf("%d\n", sizeof(*(a[0] + 1)));
printf("%d\n", sizeof(a + 1));
printf("%d\n", sizeof(*(a + 1)));
printf("%d\n", sizeof(&a[0] + 1));
printf("%d\n", sizeof(*(&a[0] + 1)));
printf("%d\n", sizeof(*a));
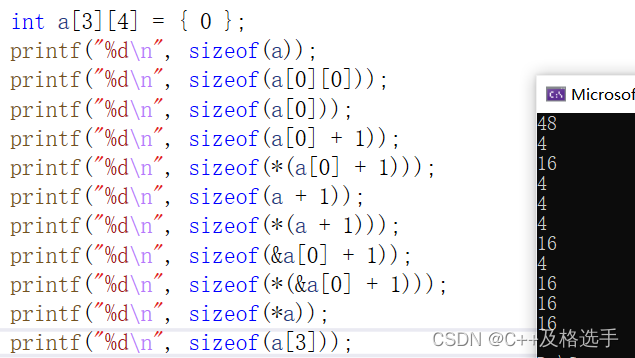
printf("%d\n", sizeof(a[3]));首先是输出结果:
首先对于以上的二维数组,我们平时做题通常认为它是这样的:
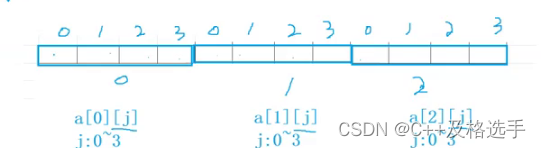
而实际上,它真正在内存中的存储是这样的:
这一点还希望大家知晓,接着我们来看题目:
1.sizeof(a[0]):由于是二维数组组,所以说a[0]表示的是第一行的一维数组,问题也就转化为了第一行的数组的数组名,也就是求第一行数组所占的字节数(4*4=16);
2.sizeof(a[0] + 1):有的读者是不是认为a[0]+1相当于a[1]啊?敲黑板了,重点来了,我告诉你并不是,由于我们的a[0]不是单独放在sizeof内部,还加上了1,导致其所代表的的指针的地址范围“缩小”或者“降级”(该名词仅为笔者叙述词,不具有实际意义,不要深挖),也就是说,原来a[0]代表的是第一行的地址,而现在a[0]就变成了普通的第一行的首元素的地址,即&a[0][0],再加上1,就变成了&a[0][1],其大小为4或8个字节。
3.sizeof(*(a[0] + 1)):同2,a[0]此处代表a[0][0],加1位&a[0][1],再解引用,所以括号内表示a[0][1],也就是4个字节;
4.sizeof(a + 1):a并未单独放在sizeof内部,所以a表示二维数组首元素的地址(&a[0]),所以a+1=&a[1],注意二维数组的首元素是第一行的整行,并不是a[0][0]这一个元素,这里的a就是第一行的地址,其类型是int (*)[4](数组指针),是一行为整形的4个数据组成的数组的指针,a+1就相当于跳过了第一行,所以其结果仍然为一个指针的大小4或8;
5.sizeof(*(a + 1)):a没有单独存在,所以a会“降一级”变为数组首元素的地址&a[0],再加1,则表示&a[1],再解引用,就得到第二行数组,返回的就是第二行数组的字节数16;第二种就是*(a+1)可直接表示为a[1],也正确;
6.sizeof(&a[0] + 1):由上面的分析得出其表示第二行的地址,返回值为一个指针大小;
7.sizeof(*(&a[0] + 1)):&a[0]+1=&a[1],*&a[1]=a[1],所以返回值为16;
8.sizeof(*a):此时数组名变成首元素的地址,二维数组首元素的地址为第一行一维数组的地址,也即*a=*(&a[0])=a[0],返回的就是第一行的所有元素的字节数16;
9.sizeof(a[3]):“xd,你题目写错了吧,a[3][4]的二维数组,行数只能为0-2,你这写个3,这不明摆的坑我们吗?”,稍等,不放你可以先去上面看看运行结果,显示是能运行的,这就奇怪了,sizeof这个操作符吧,他比较懒,不会跟你计较越不越界,sizeof在程序编译期间就会处理,其返回值至于内部数据的类型有关,并不会参与内部的运算,这样就不会需要内部运算了,sizeof就会根据原来的数组结构进行推断(哎~原来的数组一行有四个int,那我的第四行应该也是四个int吧?哎,不管了,就当四个int返回吧,我累了~~~)也就检测不出越界访问了,我们来看个例子
从上面看出b并没有返回我们认为的int型,而是继续保持原来的数据,同样间接证明了a+2没有进行。
下面是二维数组的运行时相关数组内容监视窗口(增添数据以观测不同点):
2.指针的笔试题
下面就是一些精华的应用场景了,准备好了我们就发车吧~~~
2.1
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
//程序的结果是什么?
你做对了没?
解析:&a+1表示整个元素的地址,再向后移动一位处的地址,将其减去一正好是数组的最后一个元素,而*(a+1)表示a[1];
2.2
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
//假设p 的值为0x100000。 如下表表达式的值分别为多少?
//已知,结构体Test类型的变量大小是20个字节
int main()
{
p=(struct Test*)0x100000;
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;输出结果如下:
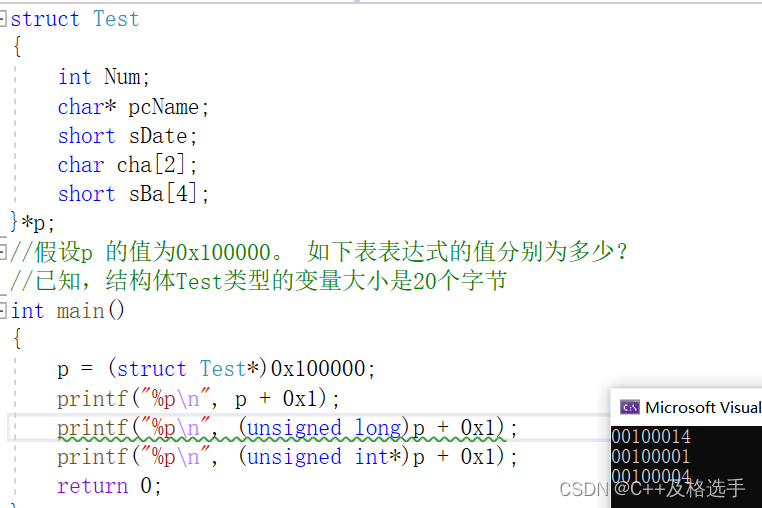
其中的0x1其实就是十六进制数字的1,相当于p+1的作用,那么p+1要加上二十个字节的长度,也就是p+1=0x100014,第二个将p强制类型转换为了一个unsigned long型的整形数据,所以加1就变成了真正意义要上的加1,也就是相当于0x100001,再看最后一个,将本来大小为20个字节的指针强制类型转换成了4个字节大小的指针,所以加1就会跳过四个字节,即0x100004;
2.3
int main()
{
int a[4] = { 1, 2, 3, 4 };
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf( "%x,%x", ptr1[-1], *ptr2);
return 0;
}输出结果:(基于小端的x86环境下)
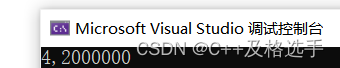
此处的ptr[-1]可以看成是*(ptr-1),就相当于ptr的地址减1,也就是指向了4这个元素,第二个是比较难理解的,我们不妨先来看一看他们代表的内存都是啥吧

从上面我们可以得出,ptr的地址只是比a[0]的地址多了1, 这就涉及到了字节偏移的问题,我们的ptr2比a[0]多1的话,相当于它指向a[0]的末尾,又由于小端存储,所以低地址上方低位字节,又因为ptr2为int*,会自动向后寻找四个字节:
2.4
#include <stdio.h>
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf( "%d", p[0]);
return 0;
}其输出结果为1,
首先,关于逗号表达式,其最终返回值就是最后的那条语句,数组里面真正存储的是1,3,5三个数字,剩下的就都默认初始化为0了;
2.5
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
注意,还是要用.c文件编译,c++规定比c多
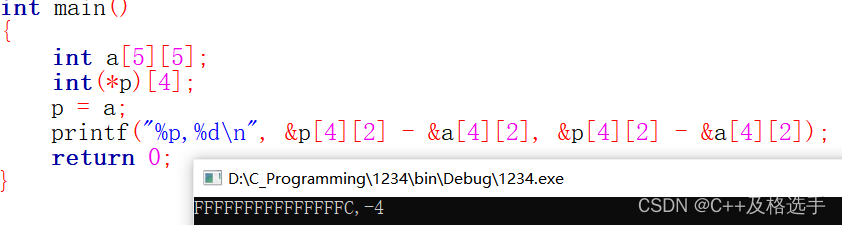
上来我们就注意到两个数组大小不同,其实如果非要这样运行的话,我们可以这样想:
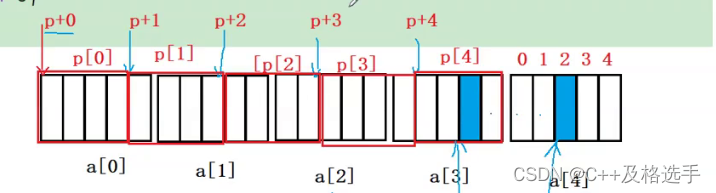
可见,要求的结果地址相差4个字节,结果为-4,但是作为地址不会管你整数还是负数,它会直接把-4转换为地址来打印。
2.6
#include <stdio.h>
int main()
{
char *a[] = {"work","at","alibaba"};
char**pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}
输出结果:
at
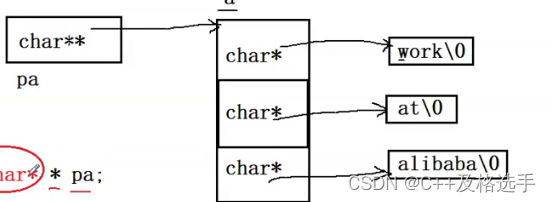
解析:a的每个数组元素是char*,也就是a的每个数组元素表示的是字符串的地址,而pa的类型为char**,也就是说pa指向的是a数组,如下图
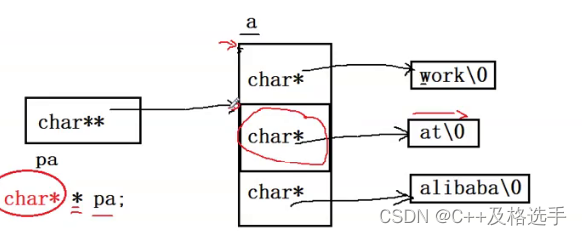
而我们又知道,当有int *p时,p+1表示的是p的地址向后移动4个字节,所以char**pa的时候,pa++就相当于pa向后移动了char*个字节,如下图
2.7
int main()
{
char *c[] = {"ENTER","NEW","POINT","FIRST"};
char**cp[] = {c+3,c+2,c+1,c};
char***cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *--*++cpp+3);
printf("%s\n", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
}
输出结果:还是.c文件吧,你懂得
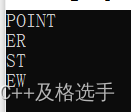
解析:这后面的提酒相对较难一些了,需要仔细分析,还会有很多的坑,话不多说,先画个图
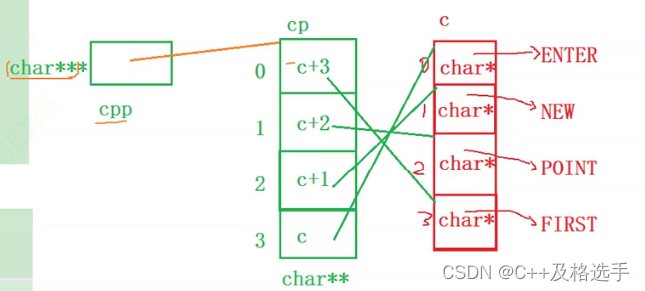
一目了然~~~呃~~~我们再看看吧
这样只能解决第一个问题,从第二个问题开始,我们就要考虑符号优先级问题了,我们有前后置++大与+,解引用*也大于+,所以对与第二个式子我们的运算顺序为:(*--(*++cpp))+3,最后我们计算可得出,结果为第一个字符串的第四个字符往后(注意此时的cpp在第一步中已经指向了c+2;同理第三个也可以变成*(*(cpp-1)-1)+1,也可得出结果,重点是要熟悉数组和指针的相互转换关系。
一件不幸的事,我的笔记本要没电了,所以就先到这吧,需要更新我会尽快补上的~~~