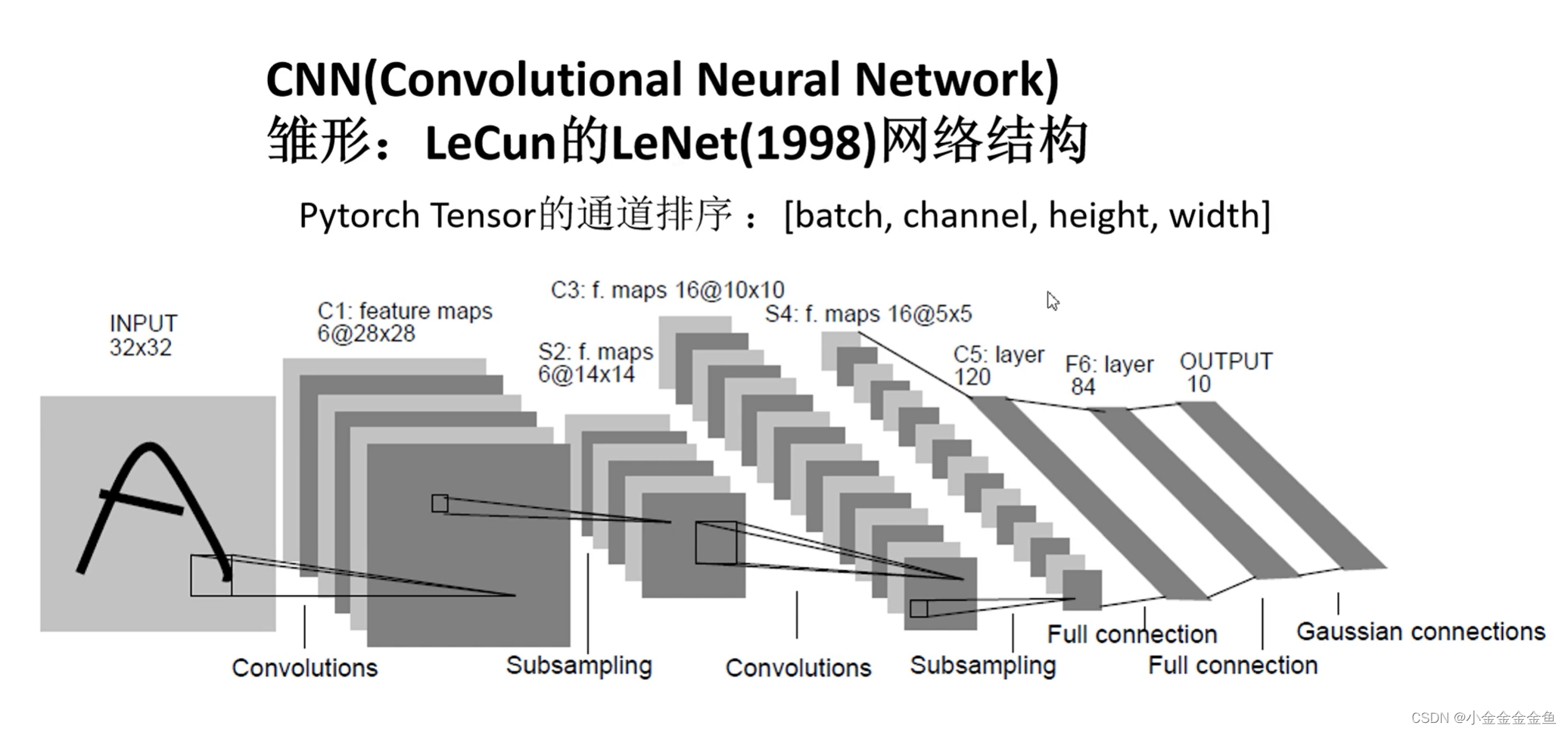
参考:
视频:
https://www.bilibili.com/video/BV187411T7Ye/?spm_id_from=333.999.0.0&vd_source=b425cf6a88c74ab02b3939ca66be1c0d
博客:https://blog.csdn.net/STATEABC/article/details/123661612?utm_medium=distribute.pc_feed_404.none-task-blog-2defaultBlogCommendFromBaiduRate-8-123661612-blog-null.pc_404_mixedpudn&depth_1-utm_source=distribute.pc_feed_404.none-task-blog-2defaultBlogCommendFromBaiduRate-8-123661612-blog-null.pc_404_mixedpud
搭建网络
- 在pytorch中搭建模型:
1、先写一个类,继承nn.Module
2、在类中实现两个方法:
①**init(self) 初始化函数**:
实现在搭建网络过程中需要使用到的一些网络层结构
②forward(self,x):
定义正向传播的过程
实例化这个类之后,将参数传递到实例中,进行正向传播。按照forward里面的这个顺序来运行。
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module): #在Pytorch中搭建模型首先要定义一个类,这个类要继承于nn.Module这个副类
def __init__(self): #在该类中首先要初始化函数,实现在搭建网络过程中需要使用到的网络层结构,#然后在forward中定义正向传播的过程
super(LeNet, self).__init__() #super能够解决在多重继承中调用副类可能出现的问题
self.conv1 = nn.Conv2d(3, 16, 5) #这里输入深度为3,卷积核个数为16,大小为5x5
self.pool1 = nn.MaxPool2d(2, 2) #最大池化核大小为2x2,步长为2
self.conv2 = nn.Conv2d(16, 32, 5) #经过Conv2d的16个卷积核处理后,输入深度变为16
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120) #全连接层的输入是一维的向量,因此将输入的特征矩阵进行展平处理(32x5x5),然后根据网络设置输出
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) #输出有几个类别就设置几
def forward(self, x): #在forward中定义正向传播的过程
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28) 可通过矩阵尺寸大小计算公式得
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
-
init(self)
①super:在定义类的过程中继承了nn.Module类。super:在多层继承中调用父类可能出现的问题。
②第一个卷积层: self.conv1 = nn.Conv2d(3, 16, 5):
通过nn.Conv2d函数(使用2d卷积,对输入的数据进行处理)来构建卷积层。参数:
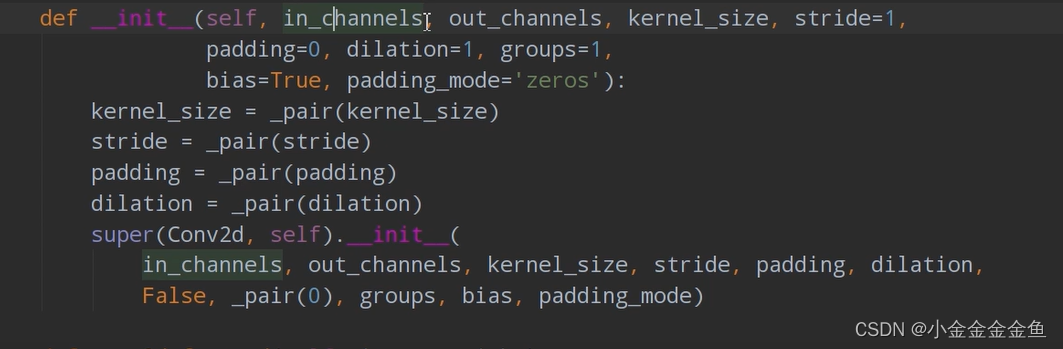
1 in_channels 输入特征矩阵的深度(如:3:R,G,B)
2 out_channels 使用卷积核的个数(使用几个卷积核,就会生成一个深度为多少维的特征矩阵)
3 kernel_size 卷积核大小
4 stride 步长,默认等于1
5 padding 在四周补数时默认等于0
6 dilation groups 比较高阶,暂时用不到
7 bias 偏置,True默认使用
self.conv1 = nn.Conv2d(3, 16, 5)
↓
输入深度为3,卷积核个数为16,大小为5x5
③计算输出图片的大小:
( padding=0 )
(32-5)/1+1 = 28
所以输出的是16x28x28(16个卷积核,所以channel变成16了)
如果写了batch,那就是输出(banchx16x28x28)
④定义下采样层:self.pool1 = nn.MaxPool2d(2, 2) :
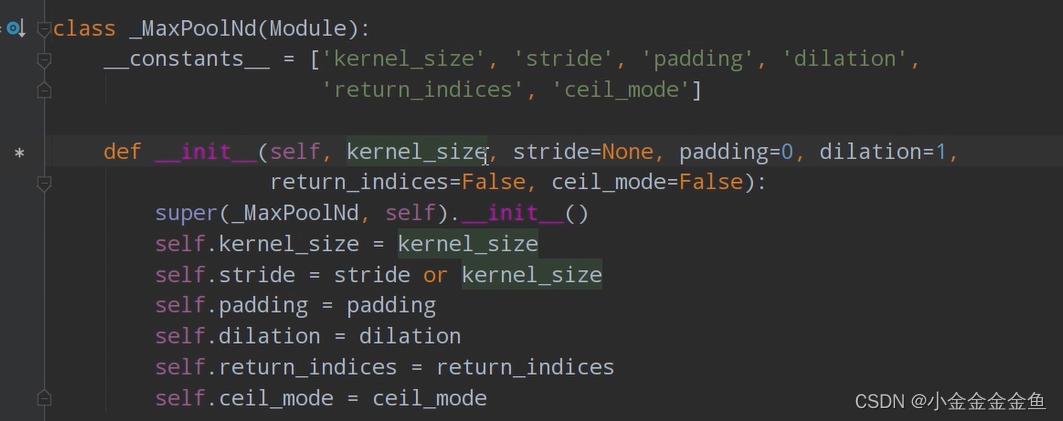
1 kernel_size 池化核大小
2 stride 如果不去指定步长,则采用与池化核大小一样的步距
self.pool1 = nn.MaxPool2d(2, 2)
↓
采用池化核大小2x2,步长为2的最大池化操作
⑤计算池化层输出:(28-2)/2+1=14,即宽度高度缩减为输入的一半
池化层,只改变特征矩阵的高和宽,不影响深度(16)
⑥第二个卷积层:self.conv2 = nn.Conv2d(16, 32, 5)
输入深度16,采用32个卷积核,尺寸5x5
(14-5+0)/1+1 = 10
所以输出为32x10x10
⑦第二个下采样层:nn.MaxPool2d(2, 2)
(10-2)/2+1 = 5
所以输出为(32x5x5)的尺寸
⑧第一个全连接层:self.fc1 = nn.Linear(32x5x5, 120)
全连接层的输入为一维向量,所以要把特征矩阵展平变成一维向量。
↓所以第一个全连接层的输入为32x5x5,有120个参数
⑨第二个全连接层:self.fc2 = nn.Linear(120, 84)
输入为上个全连接层的输出(120个节点)
第二层这里设置84个节点(看顶上的网络结构图,按照这个神经网络的定义来构建这个网络)
⑩self.fc3 = nn.Linear(84, 10)
84就是上一层定义的84个节点。
输出需要根据训练集来弄。这里是10(使用cifar10训练–>具有10个类别的分类任务)。 -
forward(self,x) 定义前向传播
x:输入的数据:按照以下排列顺序的数据↓
①x = F.relu(self.conv1(x))
数据x经过定义的卷积层1
将得到的输出通过relu激活函数
②x = self.pool1(x)
将输出通过下采样1层
③x = F.relu(self.conv2(x))
……
④x = self.pool2(x)
……
到了这里
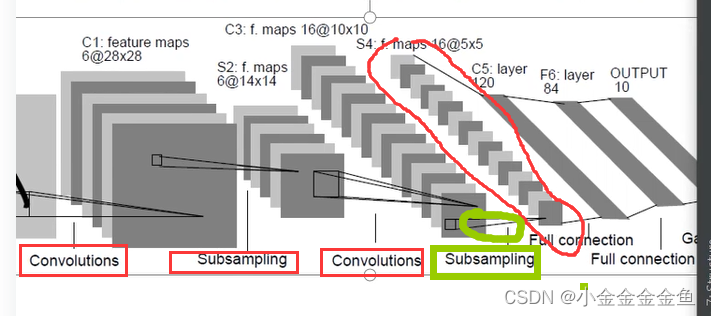
要和全连接层进行拼接,将特征矩阵展平变成一维向量↓
⑤x = x.view(-1, 32x5x5)
将特征矩阵展平变成一维向量
-1 第一个维度,自动推理,为batch
3255展平后节点个数
-1是xpython里view(x,y)函数的一个可选取值,x这一项置为-1,就会自动根据整个向量的维度和后面的y计算x这项
-1表示不确定展开成几行,但是知道要展开成32x5x5列,因为一共就是32x5x5,所以是一行,即一维向量
-1是代表自动推理,函数自己计算那个维度的大小
⑥x = F.relu(self.fc1(x))
将数据通过全连接层1+它的激活函数
⑦x = F.relu(self.fc2(x))
……
⑧x = self.fc3(x)
通过全连接层3得到最终的输出
为什么这里没有用Softmax这个函数?
对于分类问题,一般会在最后接上一个softmax层,让输出转化成为一个概率分布。
但是在训练网络过程中,计算卷积交叉熵的过程中,已经在它的内部(优化器SGD中)实现了softmax方法,所以这里不用再添加了。
测试
# 实例化 ↑ 后进行测试 ↓
import torch
input1 =torch.rand([32,3,32,32]) #定义随机生成数据的shape batch,深度,高度,宽度
model = LeNet() #实例化模型
print(model)
output = model(input1) #将数据输入到网络中进行正向传播
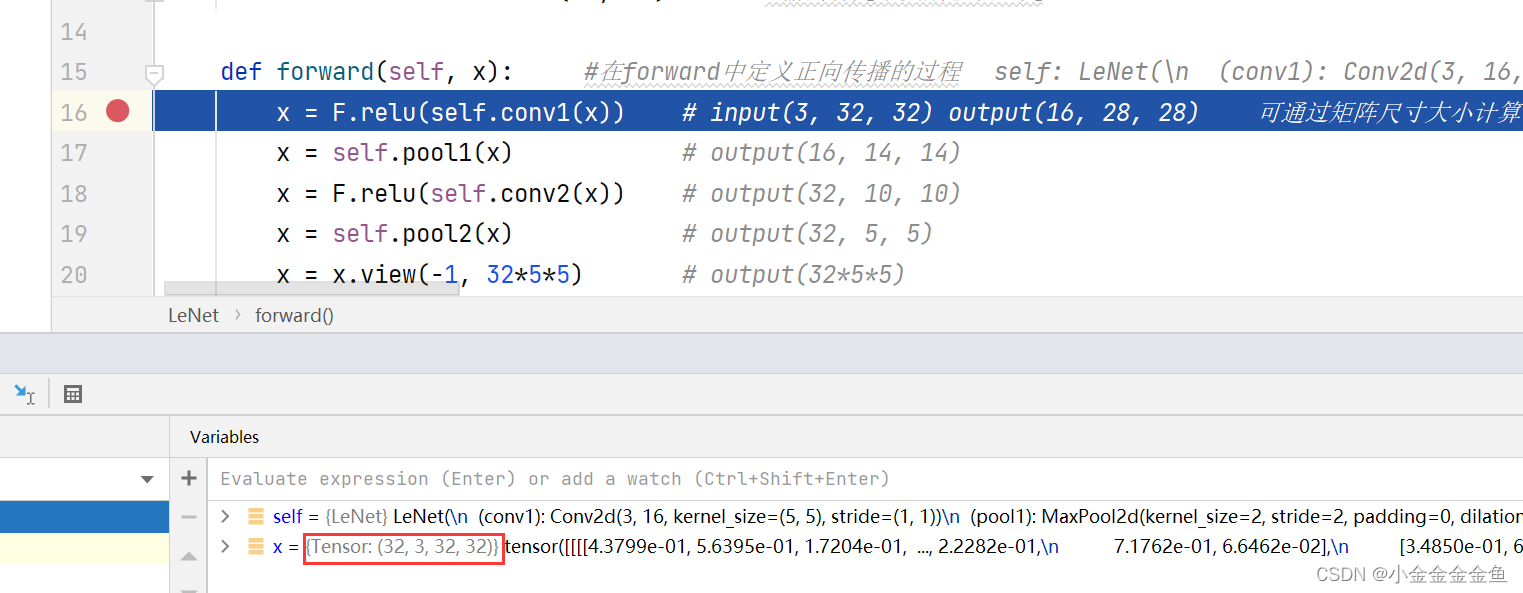

将input变量传输类的实例model,为什么会自动调用forward() ?
在nn.mldule类中,有一个call方法调用了forward函数,所以所有的nn.module子类中默认调用forward函数
【
实例后得到的实例当成一个函数调用的时候(例如:model(),此处model是实例)会调用实例所属类的__call__方法,而_call__方法中调用了forward方法
】
训练:
cifar10数据集
提前下载复制到当前目录的data文件夹里面
transform = transforms.Compose( # 通过transforms.Compose函数将使用的预处理方法打包成一个整体
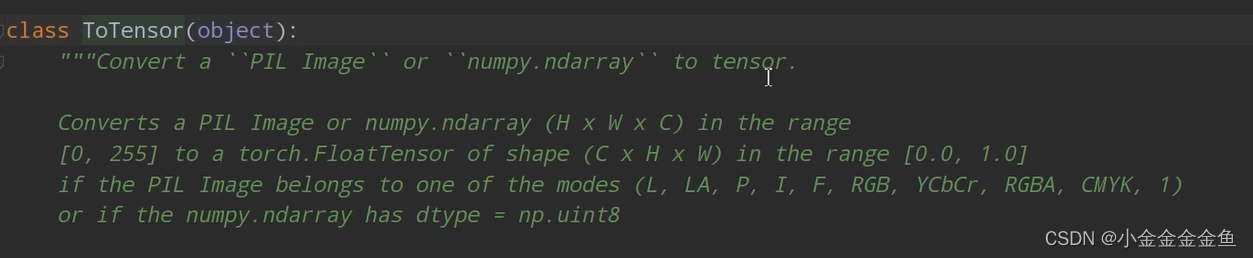
[transforms.ToTensor(),
# 将PIL图像或numpy数据转化成tensor,即将shape (H x W x C) in the range [0, 255]转换成shape (C x H x W) in the range [0.0, 1.0]
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 标准化的过程
transform,对图像进行预处理
Compose函数把用到的一些预处理方法打包成一个整体
- ToTensor
 - Normalize
- Normalize
标准化,使用均值或者标准差来标准化tensor

# 导入50000张训练图片
train_set = torchvision.datasets.CIFAR10(root='./data', # 数据集存放目录,这里是当前目录的data文件夹下
train=True, # 如果是True,就会导入cifar10训练集的样本
download=True, # 第一次运行时为True,下载数据集,下载完成后改为False
transform=transform) # 预处理过程
# 加载训练集,实际过程需要分批次(batch)训练
train_loader = torch.utils.data.DataLoader(train_set, # 导入的训练集
batch_size=50, # 每批训练的样本数
shuffle=False, # 是否打乱训练集
num_workers=0) # 使用线程数,在windows下设置为0
通过CIFAR10函数导入训练集,将训练集的每一个图像通过transform预处理函数进行预处理
# 10000张测试图片
# 第一次使用时要将download设置为True才会自动去下载数据集
test_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=4,
shuffle=False, num_workers=0)
# 获取测试集中的图像和标签,用于accuracy计算
test_data_iter = iter(test_loader)
test_image, val_label = test_data_iter.next()
将test_loader转化为可迭代的迭代器
通过next方法可获取到一批数据,其中包含图像、图像对应的标签值
发现.next()这里报错,改为了:
test_image, test_label = test_data_iter.next()
# 导入标签
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
iindex[0]对应plane
模型
net = LeNet() #实例化模型
loss_function = nn.CrossEntropyLoss()
#定义损失函数,在nn.CrossEntropyLoss中已经包含了Softmax函数
optimizer = optim.Adam(net.parameters(), lr=0.001)
#定义优化器,这里使用Adam优化器,net是定义的LeNet,parameters将LeNet所有可训练的参数都进行训练,lr=learning rate
- nn.CrossEntropyLoss() 损失函数

可以看出已经内置了softmax函数 - optim.Adam(net.parameters(), lr=0.001) 优化器
使用Adam优化器
net.parameters():把net(LeNet)中可训练的参数都进行训练
lr学习率
有GPU时使用GPU,无GPU时使用CPU训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
net = LeNet() #实例化模型
# net.to(device) #将网络分配到指定的device中
loss_function = nn.CrossEntropyLoss() #定义损失函数,在nn.CrossEntropyLoss中已经包含了Softmax函数
optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,这里使用Adam优化器,net是定义的LeNet,parameters将LeNet所有可训练的参数都进行训练,lr=learning rate
# 对应的,需要用to()函数来将Tensor在CPU和GPU之间相互移动,分配到指定的device中计算
for epoch in range(5): # loop over the dataset multiple times #将训练集迭代的次数(5轮)
running_loss = 0.0 #累加训练过程的损失
# time_start = time.perf_counter()
for step, data in enumerate(train_loader, start=0): #遍历训练集样本
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data #将得到的数据分离成输入(图片)和标签
# zero the parameter gradients
optimizer.zero_grad() #将历史损失梯度清零,如果不清除历史梯度,就会对计算的历史梯度进行累加(通过这个特性能够变相实现一个很大的batch)
# forward + backward + optimize
outputs = net(inputs) # 将图片放入网络正向传播,得到输出
# outputs = net(inputs.to(device)) # 将inputs分配到指定的device中
# loss = loss_function(outputs, labels.to(device)) # 将labels分配到指定的device中
loss = loss_function(outputs, labels) #计算损失,outputs为网络预测值,labels为输入图片对应的真实标签
loss.backward() #将loss进行反向传播
optimizer.step() #进行参数更新
# print statistics
running_loss += loss.item() #计算完loss完之后将其累加到running_loss
# 累加损失,因为希望每500次迭代计算一个损失:
if step % 500 == 499: # print every 500 mini-batches #每隔500次打印一次训练的信息
with torch.no_grad():
# with是一个上下文管理器:在接下来的计算中,不要计算每个节点中误差的损失梯度。否则即使在测试阶段中也会计算
# 会自动生成前向的传播图,这会占用大量内存,测试时应该禁用
# outputs = net(val_image.to(device)) # 将test_image分配到指定的device中
outputs = net(test_image) # [batch, 10] [0]为batch
predict_y = torch.max(outputs, dim=1)[1] #寻找输出的最大的index。在维度1上进行最大值的预测,[1]为index索引,[0]为batch
# accuracy = (predict_y == test_label.to(device)).sum().item() / test_label.size(0) # 将test_label分配到指定的device中
accuracy = torch.eq(predict_y, test_label).sum().item() / test_label.size(0) #将预测的标签类别与真实的标签类别进行比较,在相同的地方返回值为1,否则为0,用此计算预测对了多少样本
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
# print('%f s' % (time.perf_counter() - time_start))
running_loss = 0.0
print('Finished Training')
- enumerate就是c++里面的枚举,返回每一批数据的data和这一批data对应的步数index。
start=0说明从0开始
得到数据后,将数据分离成图像和标签:inputs, labels = data - optimizer.zero_grad()
将历史损失梯度清零

如果不清除历史梯度,就会对计算的历史梯度进行累加(通过这个特性能够变相实现一个很大的batch)
一般情况下,batch_size是根据硬件设备来设置的。数值设置的越大,训练效果就越好。但一般由于硬件设备受限,内存不足,所以不可能用很大的batch训练。所以用这种梯度清零的方法来实现很大batch的训练:
一次性计算多个小的batch的损失梯度,变相得到一个很大的batch的图片的损失梯度。再对这个大batch的梯度进行反向传播。 - accuracy = torch.eq(predict_y, test_label).sum().item() / test_label.size(0)
torch.eq(predict_y, test_label) 相同的地方返回True(1),否则返回False(0)。
sum:求和,计算本次测试中预测对了多少个样本 - running_loss = 0.0
清零,进行下一轮
save_path = './Lenet.pth' #保存权重
torch.save(net.state_dict(), save_path) #将网络的所有参数及逆行保存
保存网络所有参数
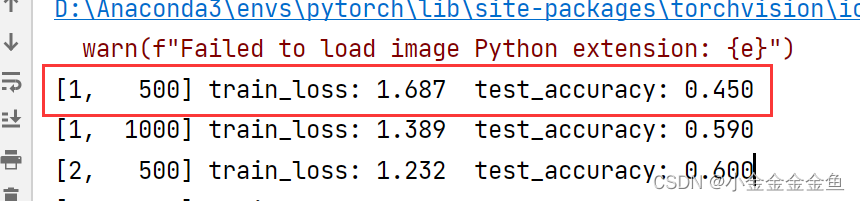
在第一个epoch中的第500步,训练的损失是1.687,测试准确率是0.450
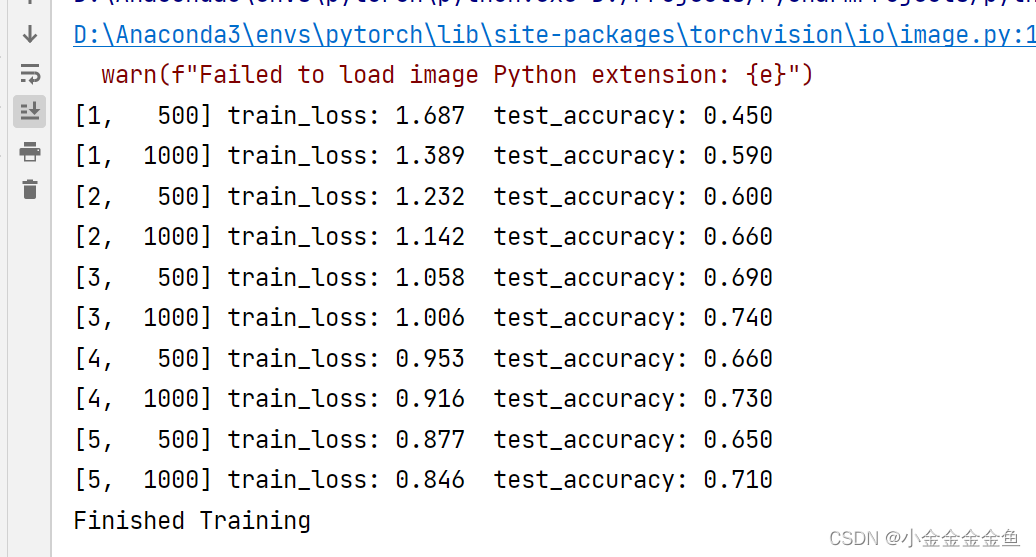
最终准确率0.710
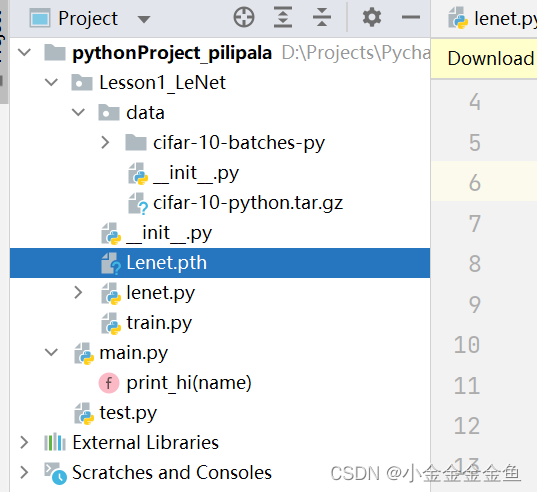
可以看到已经生成了本次训练的模型权重文件
测试:
调用模型权重进行预测
transform = transforms.Compose(
[transforms.Resize((32, 32)), #首先需resize成跟训练集图像一样的大小
transforms.ToTensor(), #转化成tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) #标准化处理
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet() #实例化网络
net.load_state_dict(torch.load('Lenet.pth')) #载入保存的权重文件
im = Image.open('plane.png') #导入要测试的图片
# PIL图像导入的可是一般都是宽度,高度,通道,要正向传播则要转变成pytorch tensor的格式
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W] #对数据增加一个新维度,因为tensor的参数是[batch, channel, height, width]
with torch.no_grad():
outputs = net(im) #把图像传入网络
predict = torch.max(outputs, dim=1)[1].numpy() #寻找输出汇总的最大尺度对应的index(索引),把它传入classes
print(classes[int(predict)])
或者使用softmax得到一个概率分布:
with torch.no_grad():
outputs = net(im) #把图像传入网络
# predict = torch.max(outputs, dim=1)[1].numpy() #寻找输出汇总的最大尺度对应的index(索引),把它传入classes
predict = torch.softmax(outputs, dim=1) #使用softmax函数 因为输出的是[channel,第一个维度],所以dim=1
# print(classes[int(predict)])
print(predict)