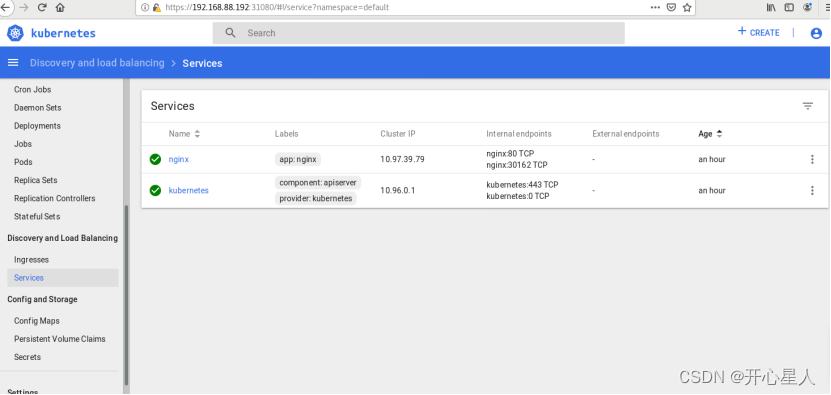
常识推理最近在自然语言处理研究中引起了广泛关注,现有的常识推理方法一般分为两种:一种是在开源数据集上对大型语言模型进行微调 [1],另一种是借助外部知识图谱来训练。然而,构建有标注的常识推理数据集既昂贵,又受限于特定领域,所以尝试无监督常识推理(UCR)至关重要。
本文中,作者专注于无监督多项选择题 QA 任务,也即给定一个问题和一组答案选项,使模型需要预测最可能的选项。作者提出了一种名为 BUCA 的无监督常识 QA 二分类框架,首先使用手动编写的模板将知识图谱三元组转化为文本形式,并生成正面和负面的问题-答案对,然后对预训练好的语言模型进行微调,并在微调过程中加入对比学习来提升模型识别不合理答案的能力,最终选择最高合理性分数的答案作为预测答案。
大量的实验结果表明,BUCA 框架在多个 QA benchmark 上都取得了令人满意的性能,并且相较于现有 UCR 方法,本文的框架对数据的要求更少,展现了 BUCA 框架的有效性。了作者的方法在各种多项选择题回答基准上的有效性。

论文标题:
BUCA: A Binary Classification Approach to Unsupervised Commonsense Question Answering
论文链接:
https://arxiv.org/abs/2305.15932
代码链接:
https://github.com/probe2/BUCA

Method
作者专注于多项选择题 QA 任务:给定一个问题 和一组选项 ,模型应选择最有可能的单个答案 。特别地,本文考虑无监督情境下的 QA 任务,也即默认模型无法访问训练或验证数据。
本文分为如下三个部分介绍 BUCA 框架:三元组转化为二分类问题;训练损失设计以及下游任务推理。
1.1 三元组转化
一般地,一个知识图谱可以表示为三元组 ,其中 是一组实体, 是一组关系类型, 是一个三元组集合 ,其中 分别为头实体和尾实体 , 则是连接 的关系。
受到之前的研究启发 [2],每个知识图谱三元组都可以通过预定义的模板转化为 Q-A 对,这些 Q-A 对可以被用作分类任务的输入,例如:
(PersonX thanks PersonY afterwards, isAfter, PersonX asked PersonY for help on her homework)
可以被转化为:
(After PersonX asked PersonY for help on her homework, PersonX thanks PersonY afterwards)
在附录中,作者展示了转化后的序列对的分布情况。
除此之外,作者为了使模型更好的判别合理与不合理 Q-A 对,还给每一个转化后的 Q-A 对创建了负样本。具体而言,对于训练数据中的一个三元组 ,作者随机从知识图谱中的尾实体抽取一个 来构建负样本 。
1.2 训练损失
在预训练好的语言模型上,作者加入了一个具有两个节点的分类头,分别输出 Q-A 对的合理性分数和不合理分数。对于上一步获得的每一个 Q-A 对及其负样本,作者将其输入模型,获得合理性分数 和不合理分数 。在每次损失计算中,作者同时考虑了正确答案 和错误答案 。
训练损失由三部分组成:
(1)传统二分类损失,其中 分别对应合理性概率和不合理概率

(2)边际排名损失,其中 为边际阈值超参数
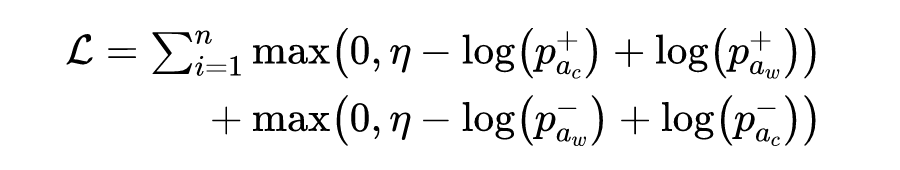
(3)对比学习损失,将同一类别内的所有样例视为给定样例的正例。如下所示,其中 分别为温度参数和特征向量。

1.3 下游任务推理
在最终推理时,只需要根据训练好的分类模型计算每个选项的合理性分数,并选取所有选项中合理性分数最大的一个作为标准答案即可。

Experiments
作者使用了两个常识知识图谱来训练 BUCA 框架:ConceptNet [3] 和ATOMIC [4],并使用五个常识 QA 数据集来评估框架:COPA、Open-BookQA、SIQA、CSQA 和 SCT。

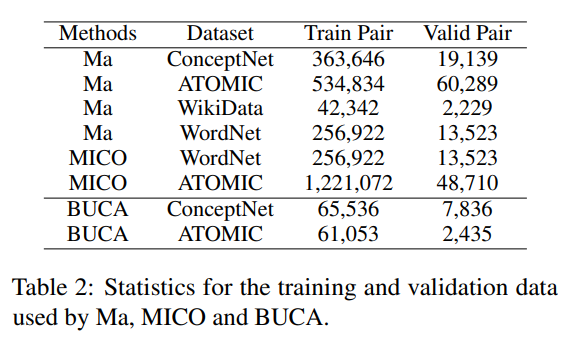
上表展示了主要结果,总体而言,BUCA 在所有数据集上都取得了最佳性能。特别地,Ma [5] 使用多个知识图谱来训练单个模型,对于 CSQA 和 ATOMIC 使用了ConceptNet、WordNet和Wikidata,对于 SIQA 使用了 ConceptNet、WordNet 和 Wikidata,总训练数据量分别为 662,909 和 1,197,742,而 BUCA 仅使用了 65,536 和 61,530,详见下表。考虑到所使用训练数据的差异及结果的相似性,展现出了 BUCA 框架的其高效性。
作者观察到,ConceptNet 对于 CSQA 更有帮助,ATOMIC 对于 SIQA 更有帮助。这可以解释 SIQA 基于 ATOMIC 构建,而 CSQA 基于 ConceptNet 构建的事实。除此之外,作者还发现,在训练过程中,边际排序损失平均比 ConceptNet 上的二分类损失高出 0.8%,在 ATOMIC 上高出 0.1%。这些结果可以解释边际排序损失更能够区分合理答案和不合理答案的得分之间的差异。
为了更深入分析 BUCA 框架各部分效果,作者进行了消融实验。首先,作者对不同的 backbone 模型进行了对比试验,如下表所示,更强的预训练语言模型在下游任务上表现更好,这可以解释为,随着模型容量的增加,模型可以储藏更多的事件类常识知识,从而能够展现出更好的效果。

同样地,作者还探究了对比学习的效果,如下表所示,去掉对比学习时,BUCA框架的整体效果都若于加入了对比学习的版本,不论使用的知识图谱如何。

为了更好地理解为什么常识问答任务中从常识图谱进行迁移学习比从其他数据集(如 MNLI 或 QNLI)更合适,作者对数据进行了多方便比较。
首先,作者比较了 ConceptNet、ATOMIC 和 MNLI(训练数据)与评估 QA 数据集之间的词汇重叠。如下表所示,MNLI 与所有评估数据集的词汇重叠率都比使用的 CKGs 高。然而,词汇重叠并不是性能的关键因素,否则在注入知识之前,使用 NLI 数据集对 NLI-KB 进行微调的模型在下游任务中应该表现更好,这与表 1 的结果有所违背。

之后,作者又分析了句子嵌入的距离。结果表明,MNLI 的条目在 SIQA 问题的常识知识检索中表现不佳,因为它们不是合理的答案。相比之下,从 ATOMIC 和 ConceptNet 生成的句子能够成功地将 SIQA 中的问题与合理的答案配对。这表明,尽管 MNLI 具有更高的词汇覆盖率,但 MNLI 没有适合匹配 SIQA 问题的示例。因此,使用 NLI 数据集进行微调的模型几乎没有从下游常识推理任务中获益。一些实际样例如下图所示:


Conclusion
本文中,作者提出了 BUCA 框架,将知识图谱(KG)转化为正面/负面 Q-A 对,用于训练二元分类模型判断 Q-A 对的合理性。大量实验证明了该框架的有效性,且其能使用更少的数据达到与其他 benchmark 基本相当的结果。在未来的工作中,作者将探索如何更好地选择负样本,并考虑在训练样本中加入更多的候选答案,以进一步提升模型的鲁棒性。

参考文献
[1] Nicholas Lourie, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Unicorn on rainbow: A universal commonsense reasoning model on a new multitask benchmark. Proceedings of the AAAI Conference on Artificial Intelligence, 35(15):13480–13488.
[2] Ying Su, Zihao Wang, Tianqing Fang, Hongming Zhang, Yangqiu Song, and Tong Zhang. 2022. Mico: A multi-alternative contrastive learning framework for commonsense knowledge representation.
[3] Robyn Speer, Joshua Chin, and Catherine Havasi. 2017. Conceptnet 5.5: An open multilingual graph of general knowledge. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, AAAI’17, page 4444–4451. AAAI Press
[4] Maarten Sap, Ronan LeBras, Emily Allaway, Chandra Bhagavatula, Nicholas Lourie, Hannah Rashkin, Brendan Roof, Noah A. Smith, and Yejin Choi. 2018. ATOMIC: An Atlas of Machine Commonsense for If-Then Reasoning
[5] Kaixin Ma, Filip Ilievski, Jonathan Francis, Yonatan Bisk, Eric Nyberg, and Alessandro Oltramari. 2021. Knowledge-driven data construction for zero-shot evaluation in commonsense question answering. Proceedings of the AAAI Conference on Artificial Intelligence, 35(15):13507–13515.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·