查询优化是在合理利用系统资源和性能指标的基础上,定义最有效、最优化的方式和技术,以提高查询性能的过程。查询调整的目的是找到一种方法来减少查询的响应时间,防止资源的过度消耗,并识别不良的查询性能。
在查询优化的背景下,查询处理通过分析查询的执行步骤、优化技术和其他关于查询的信息,确定如何更快地从SQL Server中检索数据。
12个查询优化技巧以提高性能
监测指标可用于评估查询运行时间,检测性能隐患,并显示如何改进。例如,它们包括
- 执行计划。一个SQL Server查询优化器一步一步地执行查询,扫描索引以检索数据,并在查询执行过程中提供详细的指标概览。
- 输入/输出统计。用于确定查询执行过程中的逻辑和物理读取操作的数量,帮助用户检测缓存/内存容量问题。
- 缓冲区缓存。用于减少服务器上的内存使用。
- 延迟。用于分析查询或操作的持续时间。
- 索引。用来加速在SQL服务器上的阅读操作。
- 内存优化的表。用于在内存中存储表数据,使读写操作运行得更快。
方法1:用select字段,不要用select all
SELECT语句是用来从数据库中检索数据的。在大型数据库的情况下,不建议检索所有的数据,因为这将在查询巨大的数据量时占用更多资源,并且我们在业务中能够使用到的所有字段的情况是极其小的。
方法2:避免使用SELECT DISTINCT
SQL DISTINCT操作符用于只选择列的唯一值,从而消除重复的值。它的语法如下。
SELECT DISTINCT column_name FROM table_name;
然而,这可能需要工具处理大量的数据,结果是使查询运行缓慢。例如,你可以通过启用性能指标(如SET STATISTICS语句)并再次用SELECT DISTINCT执行查询来检查。你会发现,这并没有带来一点区别。
相反,为了使查询在SQL Server上运行得更快,你应该避免使用SELECT DISTINCT,只需执行SELECT语句,但要指定列。
方法3: 用INNER JOIN(不是WHERE)创建连接
INNER JOIN语句从连接的表中返回所有匹配的记录,而WHERE子句则根据指定的条件过滤结果的记录。
让我们看看如何用INNER JOIN优化一个特定例子的SQL查询。我们将从HumanResources.Department和HumanResources.EmployeeDepartmentHistory这两个表中检索数据,其中DepartmentIDs是相同的。首先,用INNER JOIN类型执行SELECT语句。
SELECT d.DepartmentID ,d.Name ,d.GroupName FROM HumanResources.Department d INNER JOIN HumanResources.EmployeeDepartmentHistory edh ON d.DepartmentID = edh.DepartmentID
然后,使用WHERE子句而不是INNER JOIN来连接SELECT语句中的表。
SELECT
d.Name
,d.GroupName
,d.DepartmentID
FROM HumanResources.Department d
,HumanResources.EmployeeDepartmentHistory edh
WHERE d.DepartmentID = edh.DepartmentID
虽然结果一致,但是带有WHERE子句的查询将不得不浪费更多的资源。因为,首先,它生成所有可能的组合,然后根据条件过滤它们,最后输出结果。
方法4:避免在JOIN谓词中使用多个OR
当你需要从几个表中检索多个列时,建议取消使用OR操作,或将查询分成小的子查询。相反,它评估了OR操作的每个组件,而这又可能导致性能不佳。
方法5: 使用WHERE而不是HAVING来定义过滤器
WHERE子句用于在从表中检索数据时或通过与多个表连接时对所选列定义过滤条件。
HAVING子句用于指定对GROUP BY子句创建的组的过滤条件。此外,HAVING在所有行被选中后对行进行过滤,并在WHERE子句之后执行。
让我们仔细看看下面这个查询。
SELECT p.BusinessEntityID ,p.FirstName ,p.LastName FROM Person.Person p INNER JOIN Person.EmailAddress ea ON p.BusinessEntityID = ea.BusinessEntityID GROUP BY p.BusinessEntityID ,p.FirstName ,p.LastName ,ea.EmailAddressID HAVING ea.EmailAddressID BETWEEN 100 AND 200
首先,该查询从Person.EmailAddress表中扫描数据,然后根据指定范围过滤数据,最后输出结果行。
如果我们用WHERE子句而不是HAVING子句来执行相同的查询,结果集将检索仅限于指定条件的数据,因此,避免了任何额外的扫描和步骤。
SELECT p.BusinessEntityID ,p.FirstName ,p.LastName FROM Person.Person p INNER JOIN Person.EmailAddress ea ON p.BusinessEntityID = ea.BusinessEntityID WHERE ea.EmailAddressID BETWEEN 100 AND 200 GROUP BY p.BusinessEntityID ,p.FirstName ,p.LastName ,ea.EmailAddressID
方法6:合理使用通配符
通配符作为单词和短语的占位符,可以加在它们的开头/结尾。为了使数据检索更加有效和快速,你可以在SELECT语句中在短语的末尾使用通配符。例如%通配符、_占位符等。
SELECT p.BusinessEntityID ,p.FirstName ,p.LastName ,p.Title FROM Person.Person p WHERE p.FirstName LIKE 'And%';
在特定业务中,可以避免全文通配的情况,这样也能提升查询性能。
方法7:使用TOP对查询结果进行采样
SELECT TOP命令是用来设置从数据库中返回的记录数的限制。为了确保你的查询能够输出所需的结果,你可以使用这个命令来获取几条记录作为样本。例如,以上一节的查询为例,在结果集中定义了5条记录的限制,SSMS默认返回1000条数据,其实这是没有必要的。
SELECT TOP 5 p.BusinessEntityID ,p.FirstName ,p.LastName ,p.Title FROM Person.Person p WHERE p.FirstName LIKE 'And%';
方法8:在非高峰期运行查询大型运算
比如我们ERP或者其他业务系统中的日报流水、月报流水汇总等,常常设计到数百万条数据的查询、计算、合并等,这类运算回占据大量内存和运行时间,此类运算最好放到系统资源最宽裕的时候。
方法9:添加索引
在SQL Server中,当你执行一个查询时,优化器可以生成一个执行计划。如果它检测到可能被创建的缺失索引以优化性能,执行计划会在警告部分提出这个建议。有了这个建议,它就会告知你当前的SQL应该为哪些列建立索引,以及完成后的性能可以提高多少。
让我们运行 dbForge Studio for SQL Server 中的查询分析器,看看它是如何工作的:
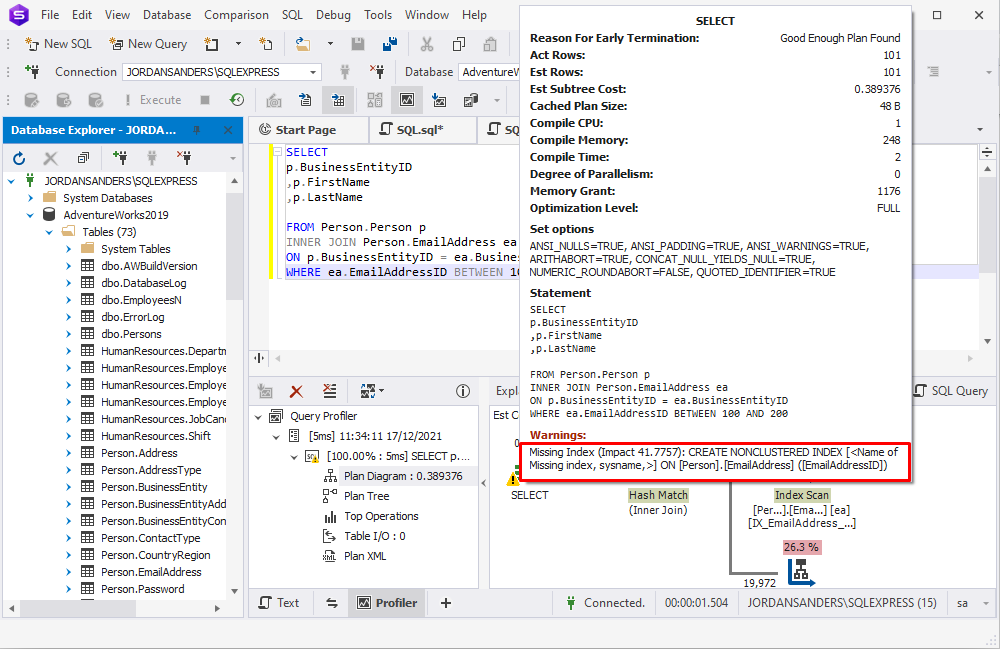
缺失的索引并不能保证一定会提升更好的性能,它只能提供一个概率。在SQL Server中,你可以使用以下动态管理视图,这些视图可能会帮助你深入了解基于查询执行历史的索引的使用情况:
- sys.dm_db_missing_index_details。提供有关建议的缺失索引的信息,空间索引除外。
- sys.dm_db_missing_index_columns: 返回有关不包含索引的表列的信息。
- sys.dm_db_missing_index_group_stats。返回有关缺失索引组的摘要信息,如查询成本、avg_user_impact(告知你通过增加缺失索引可以提高多少性能),以及其他一些衡量有效性的指标。
- sys.dm_db_missing_index_groups: 提供包括在一个特定的索引组中的缺失索引的信息。
方法10:尽量减少对任何查询提示的使用
当你面临性能问题时,你可以使用查询提示来优化查询。它们在T-SQL语句中被指定,并使优化器根据该提示选择执行计划。通常,查询提示包括NOLOCK、Optimize For和Recompile Merge/Hash/Loop。然而,你应该仔细考虑它们的用法,因为有时它们可能会引起更多意想不到的副作用、不良影响,甚至在试图解决这个问题时破坏业务逻辑。例如,你为提示写了额外的代码,这些代码在一段时间后可能不适用或过时。这意味着你应该始终监控、管理、检查并保持提示的更新。
方法11:尽量减少大量的写操作
写入、修改、删除或导入大量数据可能会影响查询性能,甚至在需要更新和操作数据、为查询添加索引或检查约束、处理触发器等时,会阻塞表。此外,写入大量的数据会增加日志文件的大小。因此,大量的写操作可能不是一个巨大的性能问题,但你应该意识到它们的后果,并在出现意外行为时做好准备。
方法12:多表查询
当你向一个查询添加多个表时,你可能会超载。此外,大量的表可能会导致执行计划的效率低下。在生成计划时,SQL查询优化器需要确定这些表是如何连接的,以何种顺序,如何以及何时应用过滤器和聚合。
对于SQL查询的优化,你可以把一个查询分成几个独立的查询,这些查询以后可以被连接起来,删除不必要的连接、子查询、表等。
dbForge Studio for SQL Server是SSMS以外的更好的数据库管理工具,除了更好的开发体验以外,还能更简洁的分析SQL开发中的性能问题,欢迎咨询