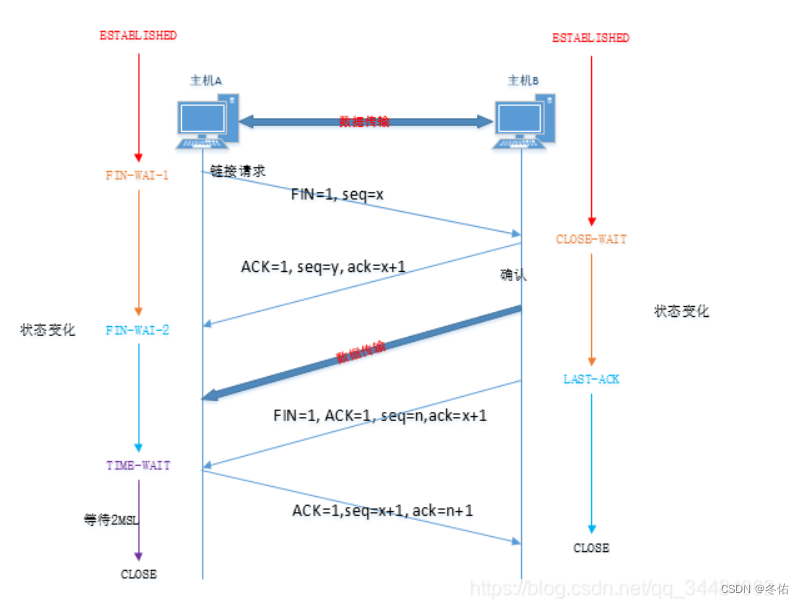
MMDetection 是一个基于 PyTorch 的目标检测开源工具箱,它是 OpenMMLab 项目的一部分。包含以下主要特性:
- 支持三个任务
- 目标检测(Object Detection)是指分类并定位图片中物体的任务
- 实例分割(Instance Segmentation)是指分类,分割图片物体的任务
- 全景分割(Panoptic Segmentation)是统一了语义分割(对图像的每个像素进行分类)和实例分割(检测出对象实例并进行分割)的检测任务
- 模块化设计以灵活支持 6 个数据集,57 种不同算法和丰富的数据增强,提供 450+ 个预训练模型
- 支持数十个算法模型的部署
安装(目标检测)
使用下面的命令快速生成虚拟环境:
$ python -m venv venv
# Windows 下进入虚拟环境
$ venv/Scripts/activate
提前看下 MMDetection 和 MMCV 版本兼容性 里 PyTorch + MMDetection + MMCV 的匹配版本号,比如我当下看到的版本要求是:
- PyTorch: 1.3+
- MMDetection: 2.28.1
- MMCV: >=1.3.17, <1.8.0
MMDetection 是基于 PyTorch 的检测框架,首先安装 torch 库:
$ pip install torch
$ pip install opencv-python
$ pip install torchvision
MMDetection 包括 MMDetection 和 MMCV,两者是一体的,需要安装 MMCV,按 安装 MMCV - 使用 mim 安装 的说明使用 mim(OpenMMLab项目的包管理工具)安装:
$ pip install openmim
$ mim install mmcv-full==1.7.1
然后再安装 MMDetection,(重要的事说两遍)提前看下 MMDetection 和 MMCV 版本兼容性 里 PyTorch + MMDetection + MMCV 的匹配版本号,选择合适的版本安装,建议直接用 mim 快速安装:
$ mim install mmdet==2.28.1
在 Windows 系统下,如果安装过程中遇到下面的异常:
$ error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
$ [end of output]
$
$ note: This error originates from a subprocess, and is likely not a problem with pip.
$ ERROR: Failed building wheel for pycocotools
$ Failed to build pycocotools
$ ERROR: Could not build wheels for pycocotools, which is required to install pyproject.toml-based projects
可以按照 《Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools"的解决办法》 提供的方法解决。
安装完成后,执行下面的 Python 代码(demo.py)验证是否正确安装了 MMDetection 和所需的环境:
import mmcv
from mmdet.apis import init_detector, inference_detector
# 一、指定模型的配置文件和 checkpoint 文件路径
# 下载 https://github.com/open-mmlab/mmdetection 项目并解压
# 把 mmdetection-master/configs/_base_ 文件夹复制到当前项目 configs/ 目录下
# 把 mmdetection-master/configs/faster_rcnn 文件夹复制到当前项目 configs/ 目录下
config_file = 'configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
# 从 model zoo 下载 checkpoint 并放在 `checkpoints/faster_rcnn/` 文件下
# 网址为: http://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
checkpoint_file = 'checkpoints/faster_rcnn/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
# 二、根据配置文件和 checkpoint 文件构建模型
# 有 GPU 时使用 device = 'cuda:0'
device = 'cpu'
# 初始化检测器
model = init_detector(config_file, checkpoint_file, device=device)
# 三、测试单张图片并展示结果
# 图像地址: https://github.com/open-mmlab/mmdetection/blob/master/demo/demo.jpg
img = mmcv.imread('demo/demo.jpg')
# 推理演示图像, 结果是一个 `numpy.ndarray` 列表
result = inference_detector(model, img)
# 将结果可视化
model.show_result(img, result)
# 将可视化结果保存为图片
model.show_result(img, result, out_file='demo/demo_result.jpg')
这个时候的项目目录结构如下:

如果成功安装 MMDetection,则上面的代码可以完整地运行,并顺利生成下面的 demo/demo_result.jpg 文件:

实例分割
实例分割(Instance Segmentation)是指分类,分割图片物体的任务。打开 MMDetection - 模型库/MMDetection 并选择 Instance Segmentation 任务类型:

挑选一个 AP(平均精确度)值 较高,而且年份比较新的算法,比如当下看到的算法名是 SCNet(算法 RF-Next 需要 GPU 才能跑起来),就在前面下载好的 mmdetection-master/configs/ 目录下找到对应的 scnet 文件夹及其依赖的 htc 文件夹,并将它们复制到当前项目 configs/ 目录下。点击 算法名 进入算法详情页面:

同样的,挑选一个 AP(平均精确度)值 较高的模型,这里先复制 模型名称 的文本,然后在 configs/scnet/metafile.yml 文件中搜索这个文本:

搜索完成可以获得两个配置及参数:
- Config: 模型的配置文件路径(
config_file = 'xxx.py') - Weights: 模型的下载网址,通过这个地址下载模型文件(
checkpoint_file = 'xxx.pth')
完成上面的准备工作后,执行下面的 Python 代码(demo.py)验证是否可以对图像进行分类、分割物体目标的任务:
import mmcv
from mmdet.apis import init_detector, inference_detector
print('指定模型的配置文件和checkpoint文件路径')
config_file = 'configs/scnet/scnet_r50_fpn_1x_coco.py'
checkpoint_file = 'checkpoints/scnet/scnet_r50_fpn_1x_coco-c3f09857.pth'
print('根据配置文件和checkpoint文件构建模型')
device = 'cpu'
model = init_detector(config_file, checkpoint_file, device=device)
print('测试单张图片并展示结果')
img = mmcv.imread('demo/demo.jpg')
result = inference_detector(model, img)
model.show_result(img, result)
model.show_result(img, result, out_file='demo/demo_result.jpg')
这个时候的项目目录结构如下:

如果上面代码中 MMDetection 的实例分割任务可以完整地运行,就会顺利生成下面的 demo/demo_result.jpg 文件:

全景分割
全景分割(Panoptic Segmentation)是统一了语义分割(对图像的每个像素进行分类)和实例分割(检测出对象实例并进行分割)的检测任务。同前面一样,打开 MMDetection - 模型库/MMDetection 并选择 Panoptic Segmentation 任务类型:

这里的算法目前就只有一个,只能选择 PanopticFPN 算法,还是在前面下载好的 mmdetection-master/configs/ 目录下找到对应的 panoptic_fpn 文件夹,并将其复制到当前项目 configs/ 目录下。点击 算法名 进入算法详情页面:

再从中选一个模型,复制 模型名称 的文本,到 configs/panoptic_fpn/metafile.yml 文件中搜索:

搜索完成可以获得 Config(config_file = 'xxx.py')和 Weights 下载后文件路径(checkpoint_file = 'xxx.pth')配置参数。然后执行下面的 Python 代码(demo.py)验证是否可以对图像进行对每个像素进行分类同时检测出对象实例并进行分割的任务:
import mmcv
from mmdet.apis import init_detector, inference_detector
# 上面代码没有变,就下面两个变量的值改一下
config_file = 'configs/panoptic_fpn/panoptic_fpn_r50_fpn_1x_coco.py'
checkpoint_file = 'checkpoints/panoptic_fpn/panoptic_fpn_r50_fpn_1x_coco_20210821_101153-9668fd13.pth'
# 下面代码也没有变
device = 'cpu'
model = init_detector(config_file, checkpoint_file, device=device)
img = mmcv.imread('demo/demo.jpg')
result = inference_detector(model, img)
model.show_result(img, result)
model.show_result(img, result, out_file='demo/demo_result.jpg')
这时项目的目录结构如下:

如果上面代码里的全景分割任务可以顺利运行,就会生成下面的 demo/demo_result.jpg 文件:

实践完成到这里,就会发现,其实调用代码是一样的,就是改一下配置文件和模型文件,就可以实现不同的功能!