Efficient Self-supervised Learning with Contextualized Target Representations for Vision, Speech and Language
(视觉、语音和语言的语境化目标表征的高效自监督学习)

论文:efficient-self-supervised-learning-with-contextualized-target-representations-for-vision-speech-and-language
代码:data2vec
期刊/会议:未发表
摘要
目前的自监督学习算法通常是特定模态的,需要大量的计算资源。为了解决这些问题,我们提高了data2vec的训练效率,这是一个跨越多种模式的学习目标。我们不需要编码masked tokens,使用一个快速的卷积解码器,并分摊构建教师表示的工作量。data2vec 2.0受益于data2vec中引入的丰富的语境化目标表征,这使一个快速的自监督学习者成为可能。在ImageNet-1K图像分类上的实验表明,data2vec 2.0与Masked Autoencoders的准确性相比,在预训练时间上低16.4倍;在Librispeech语音识别上,它的表现与wav2vec 2.0相当;在GLUE自然语言理解上,它与重新训练的RoBERTa模型相比,时间少了一半。在训练了150个epoch的ViT-L模型中,以一些速度换取精度,结果ImageNet1K top-1精度为86.8%。
1、简介
自监督学习一直是一个活跃的研究主题,在计算机视觉,自然语言处理和语音处理等多个领域取得了很大进展。然而,算法通常在设计时只考虑一个模态,这使得不清楚相同的学习机制是否适用于不同的模态。为此,最近的工作引入了统一的模型架构和在不同模式下功能相同的训练目标。
自监督模型受益于模型容量和训练数据集规模的增加以及大量的计算训练工作,这导致了有趣的新特性。虽然得到的模型是优秀的少样本学习者,但之前的自监督学习阶段远远不够有效:对于某些模式,训练具有数千亿个参数的模型,这通常会突破可行的计算边界(超出算力限制)。
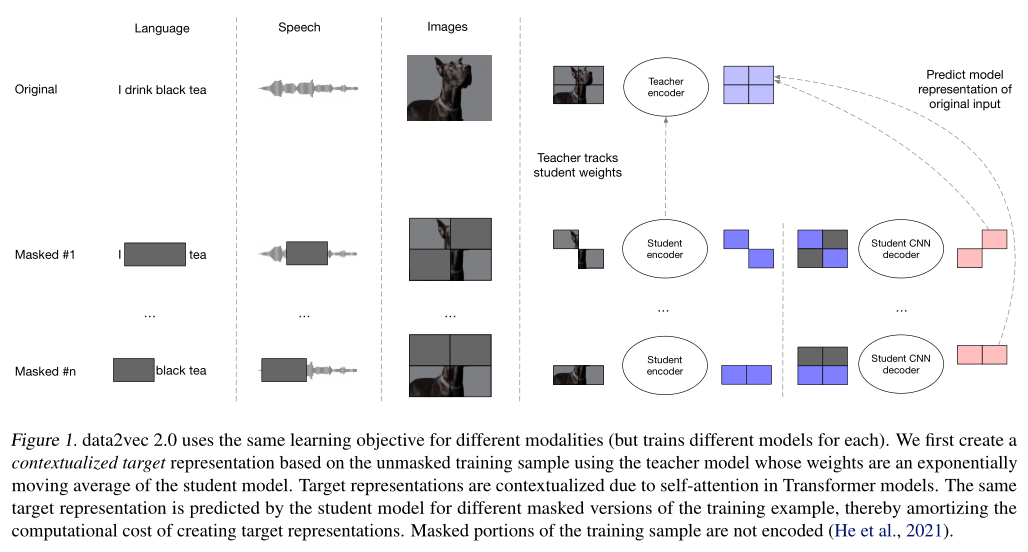
在本文中,我们提出了data2vec 2.0,其通过使用高效的数据编码、快速卷积解码器和重用每个样本的多个mask版本的目标表示。该算法对每个模态使用相同的学习目标,但根据输入模态,使用具有不同特征编码器的Transformer架构为每个模态训练单独的模型。我们遵循Baevski等人的方法,使用基于unmasked训练示例的教师模型创建潜在的语境化目标表征,该模型由学生模型回归,其输入是样本的masked版本(图1),目标情景化可以捕获关于整个样本的信息,例如,对于文本,这些目标可以根据上下文表示单词的不同含义。这对于使用单一特征集来表示单词的不同含义的传统非语境化目标表征来说更加困难。乍一看,使用单独的教师创建情境化目标似乎是减缓模型训练的额外步骤,但我们的效率改进表明,情境化目标会导致更丰富的学习任务和更快的学习。
实验表明,在图像分类、语音识别和自然语言理解方面,效率提高了2-16倍。
2、相关工作
自监督学习在文本、语音和视觉中。对于单一模态(如NLP)的自监督学习已经进行了大量工作,其中模型将文本分割为子词单元,并通过因果模型预测下一个token或通过双向模型预测masked token,来定义基于这些单元的学习任务。
对于语音处理,模型要么重建音频信号,或者以从左到右的方式,基于离散语音信号的短而重叠的窗口来解决学习任务或使用masked预测。
在计算机视觉中,已经向vision transformer架构(ViT)和masked预测方法,通过不编码masked patch可以非常有效。也有基于离散视觉 tokens 的学习方法。其他方法是基于自蒸馏和在线聚类的方法。
与我们的multi-mask训练机制(§3.3)相关的工作包括Caron等人,他们从同一图像创建多个剪裁图像,这与我们为同一训练示例创建多个mask版本的方法形成对比。Jing等人还在卷积神经网络的背景下对一个训练示例应用不同的mask进行试验,但发现裁剪和翻转等数据增强优于这种掩码策略。
广义架构和学习目标。另一个趋势是神经网络架构的统一,可以使用相同的网络处理来自不同模式的数据。这是由统一data2vec中视觉、语音和文本的自监督学习目标的工作补充的。data2vec的一个显著特征是,它是通过预测情景化的目标表示来训练的,这些目标表示包含来自整个输入示例的特征,而不是特定时间步长或patch的有限信息。
联合多模型学习。虽然data2vec和当前工作分别针对每个模态进行训练,但在训练联合模态模型方面已经进行了大量工作,这些模型可以在同一个模型中表示多个模态。这包括在图像和文本上训练的模型,语音和文本,或视频/音频/文本。
有效的自监督学习:自BERT在NLP中取得成功后,后续工作包括更轻量级的训练目标以提高效率,以及通过权重共享来降低模型容量,从而实现更快的训练速度。在计算机视觉中,He等人引入了在编码器网络中not processing masked patch的思想,从而提高了训练速度,Assran等人在联合嵌入架构中使用了这一思想,以实现标签高效的自监督学习。也有关于sparse attention以提高效率的研究。对于语音,更高效的特征编码器模型和时间步压缩有助于提高效率。
3、方法
我们的方法建立在data2vec的基础上,我们首先描述了主要的共享技术,包括预测语境化目标表征表示(§3.1)。类似于Mask Autoencoders(MAE),我们只对样本的non-masked部分进行编码,并使用解码器模型来预测掩码部分的目标表示,但我们没有使用基于transformer的解码器,而是使用更小的卷积解码器,我们发现它更容易、更快地训练(§3.2)。为了分摊创建语境化目标表示的计算开销,我们为训练样本的多个mask版本重用每个目标(§3.3),而不是random masking(随机掩码)或block masking(块掩码),我们的反转块掩码策略确保样本的连续区域被保留,为学生预测提供更多的上下文内容(§3.4)。
3.1 语境化目标表示
我们不是重建原始输入数据的局部窗口,也不是预测其离散表示,而是预测包含整个输入样本信息的教师网络表示。这导致了一个更丰富的训练任务,其中目标是特定于特定的训练样本。语境化目标是通过基于transformer的教师模型的自注意力机制构建的,该模型对未隐藏的训练样本进行编码,训练目标是样本中所有特征的加权和。
目标表征和学习目标:训练目标基于教师的前 K K K个FFN块的平均。在求平均之前,使用实例归一化(layer normalization)对activations进行归一化。训练任务是让学生网络根据样本的掩码版本回归这些目标。
教师权重。教师权重 ∆ ∆ ∆是学生编码器权重 θ θ θ的指数移动平均值: ∆ ← τ ∆ + ( 1 − τ ) θ ∆←τ∆+(1−τ) θ ∆←τ∆+(1−τ)θ,其中 τ τ τ在 τ n τ_n τn次更新期间,从起始值 τ 0 τ_0 τ0到最终值 τ e τ_e τe的线性增长时间表,此后该值保持不变。
学习目标:我们使用基于教师网络 y y y和学生网络预测 f ( x ) f(x) f(x)的目标表示的L2损失。与Baevski等人使用的平滑L1损失相比,这是一种简化,我们发现它在各种模式下都能很好地工作。
3.2 模型架构
类似于data2vec,我们的模型使用特定于模式的特征编码器和Transformer架构,其中后者构成了模型权重的大部分。对于计算机视觉,我们使用16x16像素的patch映射作为特征编码器,对于语音,使用多层卷积网络,遵循van den Oord等人和Baevski等人对于文本,我们使用基于字节对(byte-pair)编码学习的嵌入。
非对称编码器/解码器架构。在第一步中,我们使用教师网络对unmasked训练样本的所有部分进行编码,以创建训练目标(§3.1)。接下来,我们mask部分样本(§3.4)并将其嵌入到学生编码器中。为了提高效率,我们只编码训练示例的unmasked patch或时间步长,会大大加快速度,这与编码样本的所有部分相比,这取决于掩码的数量。然后,学生编码器的输出与被masked部分的固定表示合并,并馈送到解码器网络。为了表示masked tokens,我们发现与学习表示相比,使用随机高斯噪声就足够了。解码器网络然后重建教师网络的背景化目标表示,用于学生输入中隐藏的时间步长。
卷积解码器网络:我们使用由 D D D卷积组成的轻量级解码器,每个卷积后面都有层归一化、GELU激活函数和残差连接。对于语音和文本等顺序数据,我们使用1-D卷积,而对于图像,我们使用2-D卷积,每个卷积都由组参数化以提高效率。我们调整了每个模态的层数和内核大小。
3.3 多掩码训练
data2vec师生设置的一个缺点是需要对每个样本进行两次处理:一次是使用教师模型获得目标,一次是获得学生的预测。此外,与学生模型相比,教师模型的计算activations效率也较低,因为教师需要处理完整的unmasked输入。为了分摊教师模型计算的成本,我们对训练样本的多个masked版本重用教师表示。具体来说,我们考虑 M M M个不同的masked版本的训练样本,并计算相对于同一目标表示的损失。这是可能的,因为目标表示是基于完整的unmasked版本的示例。随着 M M M的增长,计算目标表示的计算开销变得可以忽略不计。在实践中,与其他自监督的工作相比,这使得训练的批量规模相对较小(§4)。
考虑到训练样本的多个mask版本之前已经在ResNet模型的计算机视觉自监督学习的背景下进行了探索,尽管作者发现它的表现远不如不同的图像增强。Caron等人考虑基于同一图像的多种剪裁,但通过比较离散代码来训练模型,而不是预测原始图像的表示。Girdhar等人用样本的多个mask版本在视频上训练MAE模型,以摊平数据加载和准备的开销。
与data2vec相比,data2vec 2.0的另一个效率改进是在训练示例的不同mask版本之间共享特征编码器输出,以避免冗余计算。这导致密集模式(如语音)的显著加速,其中特征编码器占计算的很大一部分,但对于其他模式(如文本)则较少。
3.4 反转块掩码(Inverse Block Masking)
MAE-style的样本编码提高了效率,但也消除了在masked时间步的activations中存储信息的能力,这使得训练任务更具挑战性。随机掩码对于Masked Autoencoders是成功的,但它可能会干扰构建语义表示的能力,因为所创建的掩码中没有结构。Block masking通过mask整个时间步长块或patch而更加结构化,但不能保证训练样本的大连续部分被揭开。我们的目标是使学生模型能够构建丰富的语义表征超过样本的局部区域。
因此,我们引入了inverse block masking:它不是选择要mask的patch,而是以block的方式选择要保留的patch,其中block的大小与patch的数量或时间步长
B
B
B有关。我们首先对每个block的起始点进行采样,然后对称扩展,直到块的宽度为
B
B
B,对于语音和文本,或
B
\sqrt{B}
B,对于图像。我们在不进行替换的情况下采样以下起始点的数量,并根据模态将它们扩展到宽度为
B
B
B或宽度为
B
\sqrt{B}
B的二次块:
L
×
(
1
−
R
)
+
A
B
L \times \frac{(1-R)+A}{B}
L×B(1−R)+A
其中
L
L
L是训练样本中时间步长/patch的总数,
R
R
R是掩码比,这是一个控制被掩码样本百分比的超参数,
A
A
A是一个调整掩码比的超参数(见下文)。
我们允许块重叠,这导致了过度遮盖和每个样本实际遮盖时间步数的一些差异。由于我们只对未掩码时间步进行编码,我们使用一种简单的策略来同化一批中所有样本的未掩码时间步数:对于每个样本,我们随机选择单个时间步进行掩码或反掩码,直到我们达到所需的未掩码时间步数 L × ( 1 − R ) L×(1−R) L×(1−R)。
4、实验
4.1 有效性
作为第一个实验,我们将data2vec 2.0预训练的效率与现有的计算机视觉、语音处理和NLP算法进行了比较。我们测量了图像分类的准确性(§4.2),语音识别的单词错误率(§4.3),GLUE上的自然语言理解性能(§4.4),以及基于挂钟小时数的预训练速度。
设置:对于计算机视觉,我们使用MAE和data2vec的公共实现和推荐配置进行比较。data2vec 2.0和data2vec都在fairseq中实现,我们以不同的速度和准确性权衡评估了data2vec 2.0配置。所有视觉模型都在32个A100 40GB gpu上进行预训练,data2vec 2.0模型在25k-500k次更新,或10-200个epoch之间进行预训练,所有模型的总批大小为512张图像, R = 0.8 R = 0.8 R=0.8,$ M = 8 ,除了使用 ,除了使用 ,除了使用M = 16$的最长训练运行。MAE使用批处理大小为4096张图像或1,600个epoch预训练500k更新;data2vec被预先训练为500k更新,批处理大小为2048或800个epoch。
语音模型在32个A100 40GB gpu上进行预训练,data2vec 2.0在50k-400k更新之间执行,或13-103个epoch,使用总批量大小为17分钟的语音音频,我们设置 M = 8 M = 8 M=8, R = 0.5 R = 0.5 R=0.5。我们将wav2vec 2.0和data2vec进行比较,它们分别经过400k更新预训练,批处理大小分别为93min和63min,并遵循推荐的配置。所有模型都在fairseq中实现。
NLP模型在16个A100 40GB gpu上进行预训练,data2vec 2.0使用400k-1m更新,总批大小为32(每个样本是512个令牌序列),我们设 M = 8 M = 8 M=8, R = 0.42 R = 0.42 R=0.42。将模型与RoBERTa的重新训练版本进行比较,data2vec在原始BERT设置之后都进行了1m更新的预训练,总批大小为256 (32 epoch)。模型在fairseq中实现。
结果:图2显示,data2vec 2.0在所有三种模式中提供了更好的速度和准确性权衡:ImageNet预训练的data2vec 2.0模型在预训练3小时多一点后达到了83.7%的前1精度,而在预训练50.7小时后达到了83.6%——与流行的MAE算法相比,速度提高了16.4倍,精度略有提高。在语音识别方面,语音data2vec 2.0模型以比wav2vec 2.0低10.6倍的时间实现了相当的单词错误率。对于NLP, data2vec 2.0训练的精度与重新训练的RoBERTa模型相似,速度是前者的两倍。

同样的模型也执行更少的epoch:对于计算机视觉,与MAE精度相似的data2vec 2.0模型执行20个epoch,而不是1,600个epoch。对于语音,data2vec 2.0训练13个epoch而不是522个epoch,对于NLP, data2vec 2.0训练4个epoch而RoBERTa训练32个epoch。与data2vec相比,data2vec 2.0也提供了更好的效率:对于视觉,data2vec 2.0可以在2.9倍的时间内几乎达到data2vec的精度,对于语音有3.8倍的加速,对于NLP有2.5倍的加速。
请注意,data2vec已经比MAE更快:最具可比较性的data2vec模型的训练速度是MAE的2.8倍(17.8小时对50.7小时),准确率更高(84.0%对83.6%)。因此,与MAE相比,data2vec 2.0的速度要比NLP快得多,在NLP中,原始的data2vec并不比RoBERTa更有效。data2vec 2.0可以很好地训练相对较小的批次大小,只有512张图像,相比之下,MAE的情况下有4096张图像,data2vec和大多数其他计算机视觉自监督算法有2048张图像(§4.5更详细地分析了多掩蔽)。由于multimask可以从每个训练样本中提取更多的学习信号,因此可以用更少的周期数和批大小进行训练。此外,情境化的目标使训练任务更加丰富。
4.2 计算机视觉
接下来,我们将每种模式的data2vec 2.0与现有工作进行更广泛的比较。对于计算机视觉,我们使用标准的vision Transformer架构,但采用了层归一化,类似于原始的Transformer架构。这将导致所有模式都具有相同的Transformer体系结构。我们还应用随机裁剪和水平翻转的输入图像,其结果和我们喂入相同的数据增强版本给学生和教师。我们使用与MAE相同的超参数。仅对于视觉,我们发现添加全局CLS损失是有用的。详细的超参数见附录A表8;对于微调,我们使用与He等人相同的设置。我们在未标记版本的ImageNet-1K上进行预训练。

表1显示了data2vec 2.0在训练周期更少的情况下,对ViT-B和ViT-L都使用不使用外部数据的先前单一模型进行了改进:与MAE相比,data2vec 2.0在预训练时间更短的情况下将准确度提高了0.9% (ViT-B: 32小时vs. 50.7小时,ViT-L: 63.3小时vs. 93.3小时)。与data2vec 相比,在更少的时间点上实现了略高的精度。
data2vec 2.0还改进了使用多种模型和/或外部数据的几种方法,如TEC、PeCo和BEiT。BEiT-2性能更好,因为它有效地从CLIP 中提取表示,CLIP在比ImageNet-1K大得多的数据集上训练。
表2显示了ViT-H模型的速度/精度权衡:data2vec 2.0在训练时间减少40%和训练周期数的1/16的情况下,比MAE高出0.5%。

4.3 语音处理
为了评估语音上的data2vec 2.0,我们在Librispeech或更大的Lib-light数据集上对其进行预训练,并在Lib-light的标记数据分割上对生成的语音识别模型进行微调,以测试不同资源设置的模型质量。详细超参数请参见附录A中的表9。我们遵循wav2vec 2.0的微调制度,其超参数取决于标记的数据设置。
Alibi特征编码器。Baevski等人的特征编码器使用相对位置嵌入建模为时间卷积,假设所有时间步长都被编码。我们通过删除与屏蔽时间步相对应的内核部分来适应我们的设置。我们还发现,用与它们的距离成正比的惩罚来偏向查询键注意分数是有帮助的。偏差遵循Press等人的初始化,但我们在训练期间保持它们冻结,并为每个初始化为1.0的头部学习一个标量。这只增加了很少的新参数(Large Model为16个),但导致了精度的显著提高,这在§4.5中被削弱。
结果(表3)表明,data2vec 2.0在大多数情况下优于现有技术,训练时间更短。与wav2vec 2.0相比,data2vec 2.0使基本模型的相对错误率降低了26%,大型模型的相对错误率降低了18%。对于基本模型,我们使用图2a中最精确的模型,它在更快的训练时间内获得了比其他模型更高的精度(在16 A100 40GB gpu上需要43.3小时,而wav2vec 2.0在相同硬件上需要57.3小时)。对于大型模型,我们在64 A100 40GB gpu上训练data2vec 2.0 76.7小时,而其他模型在相同硬件上训练108小时(data2vec)或150小时(wav2vec 2.0)。

4.4 自然语言处理
对于NLP,我们采用与BERT相同的训练设置,通过使用50k字节对编码在图书语料库和英语维基百科上进行预训练。作为基线,我们使用原始的BERT设置重新训练RoBERTa使用默认BERT mask策略(mask 15%的token),但没有下句预测任务,我们也与data2vec进行比较。RoBERTa和data2vec都经过了1m更新的预训练,批处理大小为256。data2vec 2.0的超参数在附录A表10中。
模型在一般语言理解评估(GLUE)基准上进行评估(Wang等人,2018年),包括自然语言推理(MNLI, QNLI, RTE)、句子相似性(MRPC, QQP和STS-B)、语法性(CoLA)和情感分析(SST-2)的任务。预训练的模型根据每个任务提供的标记数据进行微调,我们通过执行9个不同的微调运行来报告开发集的平均准确性,并报告平均性能,而没有两个最佳和两个最差的运行,以降低对异常值的敏感性。
结果(表4)显示data2vec 2.0实现了与我们重新训练的RoBERTa基线相当的平均GLUE性能,速度是前者的1.8倍,epoch减少了7.8。与data2vec相比,它的速度提高了2.5倍。请注意,data2vec 2.0使用了更高的mask rate 42%,而BERT/RoBERTa的mask rate 为15%,我们认为这是可能的,因为使用了丰富的上下文化目标。

4.5 消融实验
多任务训练:接下来,我们分析了多重mask对不同批次大小的影响。我们使用了一种简化的计算机视觉设置,其中我们为给定的批量大小(bsz)预训练100,000次更新。图3显示,每个训练样本考虑多个掩码可以极大地提高准确率,例如,对于bsz=64,考虑M = 32而不是M = 2,在保持其他条件相同的情况下,准确率提高了5.2%。这种效应随着批量规模的增大而减小,但表明了预训练高质量模型的可能性,批量规模大大低于今天常见的批量规模。

训练损失:在下一个实验中,我们将更详细地研究我们的损失。表5显示CLS损失组件(§4.2)导致计算机视觉精度的小幅提高。由CLS损失所做的全局表示的预测是对局部补丁信息的补充。我们还比较了情境化目标预测与回归训练样本的局部16x16 patch的原始像素。添加MAE像素回归损失(像素regr)并不会比单独的背景化目标预测有所改善,仅使用像素回归损失(仅像素regr)进行训练会导致准确度大幅下降。

掩码策略:接下来,我们通过将其与block mask和random mask进行比较来消融我们的mask策略。表6显示块掩码(block mask)的性能不如反转块掩码(inverse block mask)(我们的标准设置是B = 3);B = 1对应随机掩蔽,效果也较差。
语音Abili嵌入。最后,我们研究了相对位置嵌入在语音识别中的有效性。表7显示,单独的卷积嵌入(基线-abili)表现不如abili嵌入,并且我们对随机嵌入的学习标量的设计选择是有效的。
5、总结和未来工作
我们提出了一种高效的通用预训练技术,它依赖于不同模式下相同的学习目标。data2vec 2.0表明,自监督学习的训练速度可以在不损失下游任务精度的情况下大幅提高。我们的方法的核心在于使用情境化的目标表示,从而产生更有效的自监督学习者。实验表明,data2vec 2.0可以在2-16倍的训练速度下达到与许多流行的现有算法相同的精度。未来的工作包括将data2vec 2.0应用于视觉、语音和文本以外的其他形式。