文章目录
- 一. 前言
- yolov4的创新点
- 2.1 输入端的创新
- 2.1.1数据增强
- 2.1.2自对抗训练(SAT)
- 2.2BackBone创新
- Dropblock
- 标签平滑
- 损失函数
- IOU Loss
- GIOU Loss
- DIOU Loss
- CIOU Loss
一. 前言
作者AlexeyAB大神! YOLOv4 拥有43.5%mAP+65FPS ,达到了精度速度最优平衡,
作者团队:Alexey Bochkovskiy&中国台湾中央研究院
论文链接:
https://arxiv.org/pdf/2004.10934.pdf
代码链接:
GitHub - AlexeyAB/darknet: YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet )
————————————————
在讲YOLOv4之前,先介绍一下两个包:Bag of Freebies(免费包)和Bag-of-Specials(特赠包)
Bag of Freebies:指的是那些不增加模型复杂度,也不增加推理的计算量的训练方法技巧,来提高模型的准确度
Bag-of-Specials:指的是那些增加少许模型复杂度或计算量的训练技巧,但可以显著提高模型的准确度
YOLOv4主要的贡献:
①构建了一个简单且高效的目标检测模型,该算法降低了训练门槛,这使得普通人员都可以使用 1080Ti 或 2080 Ti GPU 来训练一个超快,准确的(super fast and accurate)目标检测器。
②验证了最先进的 Bag-of-Freebies 和 Bag-of-Specials 方法在训练期间的影响
BoF指的是
1)数据增强:图像几何变换(随机缩放,裁剪,旋转),Cutmix,Mosaic等
2)网络正则化:Dropout,Dropblock等
3) 损失函数的设计:边界框回归的损失函数的改进 CIOU
BoS指的是
1)增大模型感受野:SPP、ASPP等
2)引入注意力机制:SE、SAM
3)特征集成:PAN,BiFPN
4)激活函数改进:Swish、Mish
5)后处理方法改进:soft NMS、DIoU NMS
③修改了最先进的方法,并且使其更为有效,适合单GPU训练。包括 CBN,PAN, SAM等,从而使得 YOLO-v4 能够在一块 GPU 上就可以训练起来。
yolov4的创新点
输入端的创新点:训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练
BackBone主干网络:各种方法技巧结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock
Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构
Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的回归框位置损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
2.1 输入端的创新
Yolov4对训练时的输入端进行改进,使得训练时在单张GPU上跑的结果也蛮好的。比如数据增强Mosaic、cmBN、SAT自对抗训练。
2.1.1数据增强
Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。

为什么要进行Mosaic数据增强呢?
在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。Coco数据集中小目标占比达到41.4%,数量比中目标和大目标都要多。但在所有的训练集图片中,只有52.3% 的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。
针对这种状况,Yolov4的作者采用了Mosaic数据增强的方式。
主要有2个优点:
1.丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
2.batch不需要很大:Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
2.1.2自对抗训练(SAT)
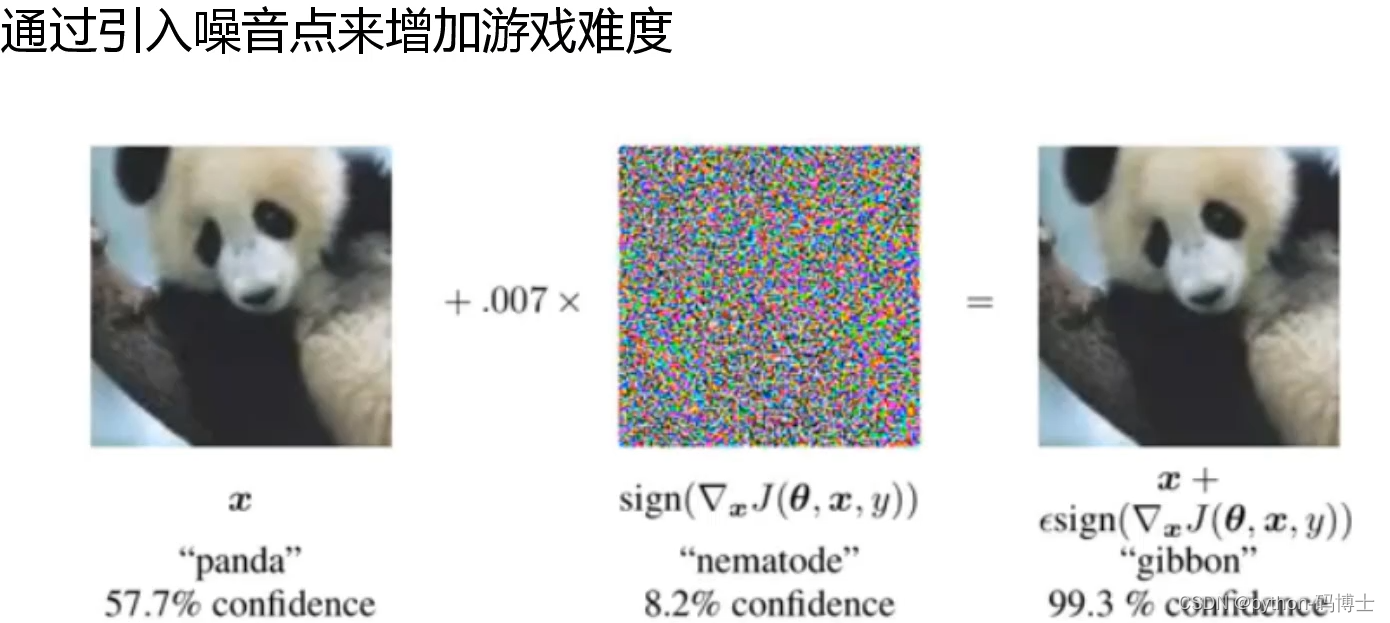
SAT全称:Self-adversarial-training。可以自己增加或者让网络增加噪音点来增加训练难度
2.2BackBone创新
Dropblock
Yolov4中使用的Dropblock,其实和常见网络中的Dropout功能类似,也是缓解过拟合的一种正则化方式。
Dropblock在2018年提出,论文地址:https://arxiv.org/pdf/1810.12890.pdf
传统的Dropout很简单,一句话就可以说的清:随机删除减少神经元的数量,使网络变得更简单。
dropout主要作用在全连接层,而dropblock可以作用在任何卷积层之上
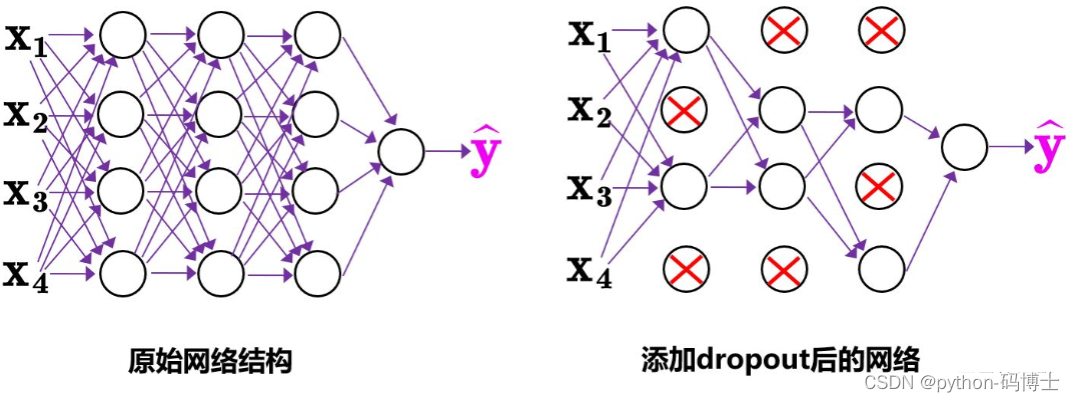
而Dropblock和Dropout相似,比如下图:
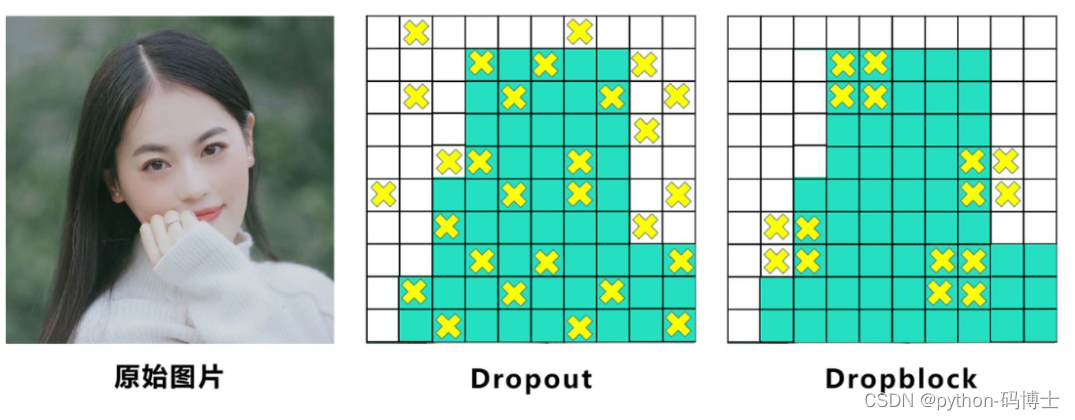
中间Dropout的方式会随机的删减丢弃一些信息,但Dropblock的研究者认为,卷积层对于这种随机丢弃并不敏感,因为卷积层通常是三层连用:卷积+激活+池化层,池化层本身就是对相邻单元起作用。而且即使随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。
因此,在全连接层上效果很好的Dropout在卷积层上效果并不好。
所以右图Dropblock的研究者则干脆整个局部区域进行删减丢弃。
这种方式其实是借鉴2017年的cutout数据增强的方式,cutout是将输入图像的部分区域清零,而Dropblock则是将Cutout应用到每一个特征图。而且并不是用固定的归零比率,而是在训练时以一个小的比率开始,随着训练过程线性的增加这个比率。
在特征图上一块一块的进行归0操作,去促使网络去学习更加鲁棒的特征
为了保证Dropblock后的特征图与原先特征图大小一致,需要和dropout一样,进行rescale操作
Dropblock的研究者与Cutout进行对比验证时,发现有几个特点:
优点一:Dropblock的效果优于Cutout
优点二:Cutout只能作用于输入层,而Dropblock则是将Cutout应用到网络中的每一个特征图上
优点三:Dropblock可以定制各种组合,在训练的不同阶段可以修改删减的概率,从空间层面和时间层面,和Cutout相比都有更精细的改进。
Yolov4中直接采用了更优的Dropblock,对网络的正则化过程进行了全面的升级改进。
标签平滑
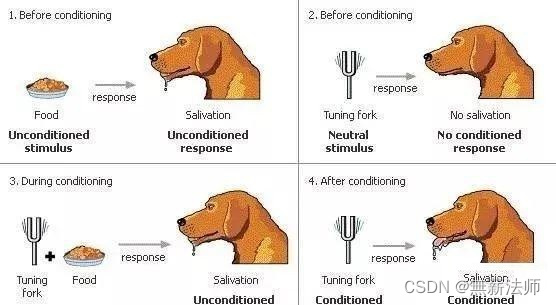
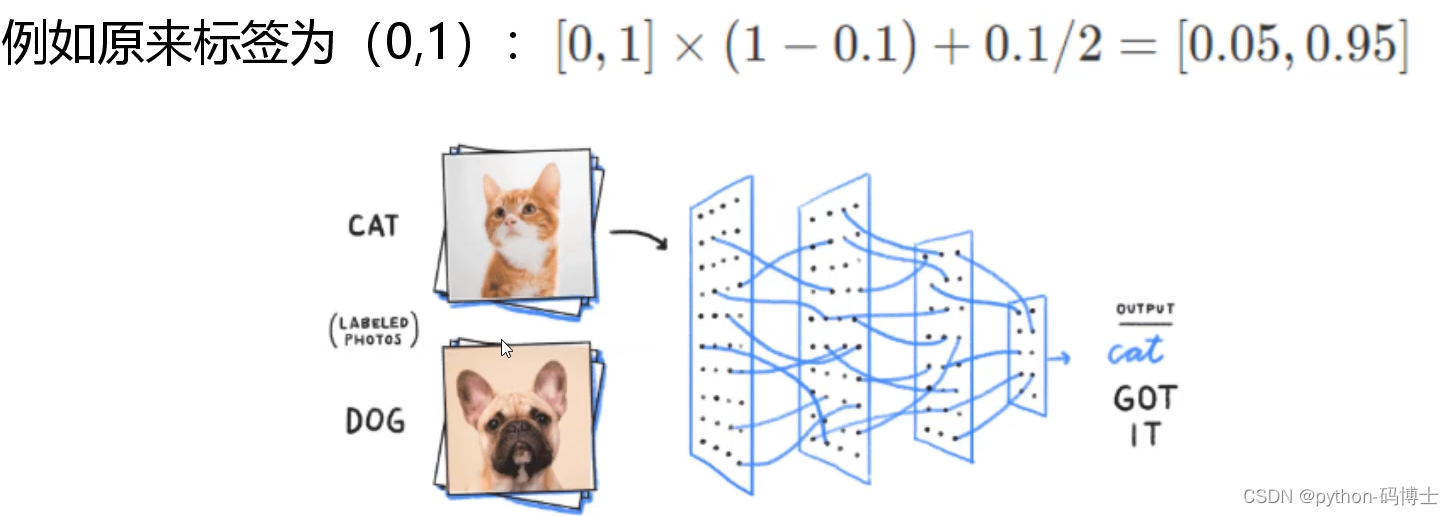
神经网络最大的缺点就是太自信(过拟合),毕竟每个东西都是由原子组成,多多少少有一些相似,所以不要让模型太过绝对,拿下面图片距举例,虽然我们预测的是猫,但是让狗的概率不至于为0,留一丝喘息的余地,日后好相见,当然大概率还是猫。
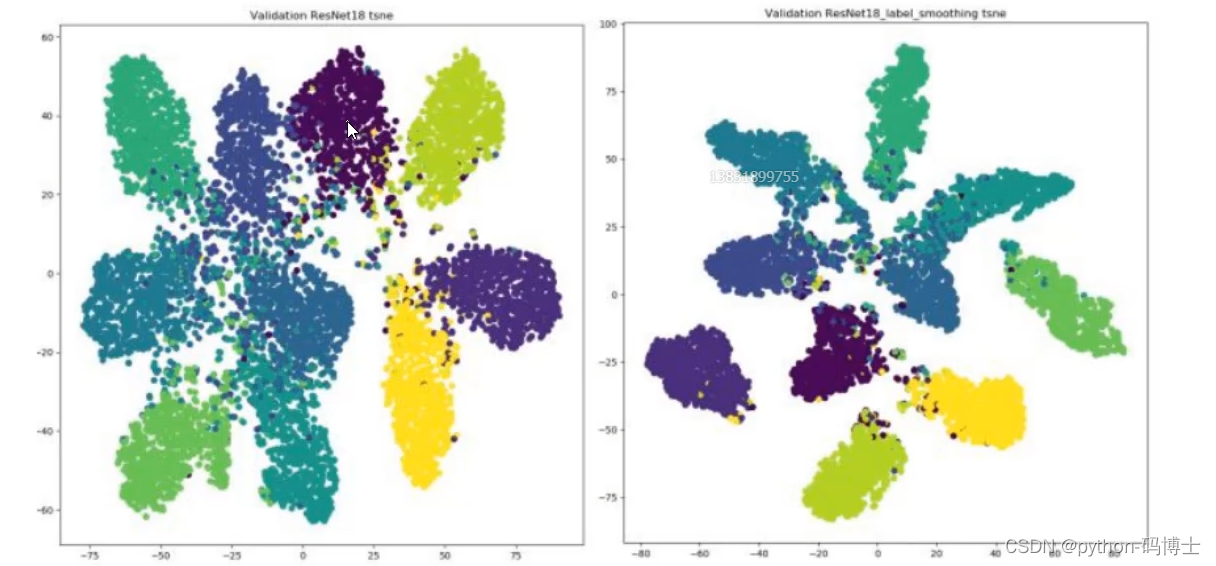
使用之前(左)和使用之后的区别(右),明显右边的聚类更好一些。
损失函数
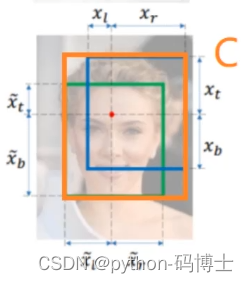
CIOU_loss-目标检测任务的损失函数一般由分类损失函数和回归损失函数两部分构成,回归损失函数的发展过程主要包括:最原始的Smooth L1 Loss函数、2016年提出的IoU Loss、2019年提出的GIoU Loss、2020年提出的DIoU Loss和最新的CIoU Loss函数。
IOU Loss
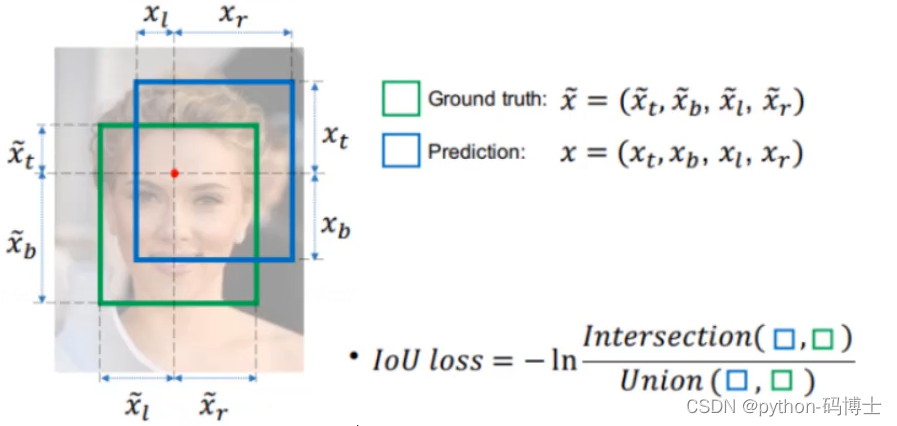
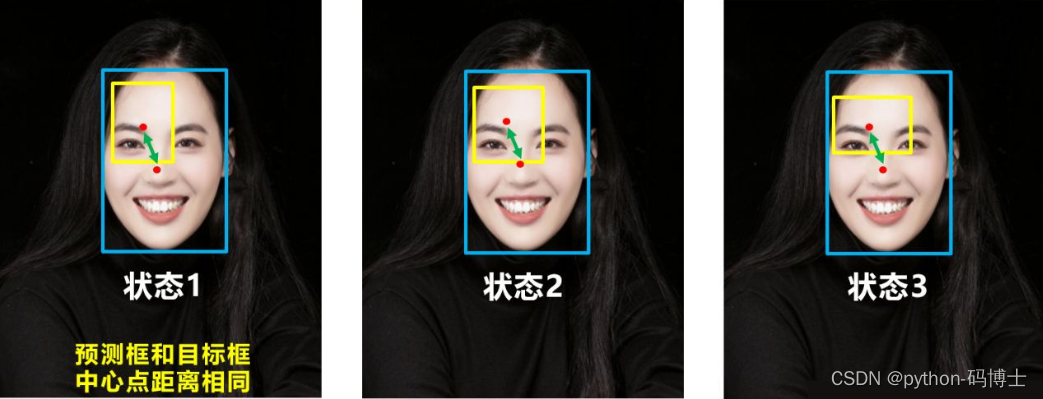
IoU Loss-所谓的IoU Loss,即预测框与GT框之间的交集/预测框与GT框之间的并集。这种损失会存在一些问题,具体的问题如下图所示,(1)如状态1所示,当预测框和GT框不相交时,即IOU=0,此时无法反映两个框之间的距离,此时该 损失函数不可导,即IOU_Loss无法优化两个框不相交的情况。(2)如状态2与状态3所示,当两个预测框大小相同时,那么这两个IOU也相同,IOU_Loss无法区分两者相交这种情况。

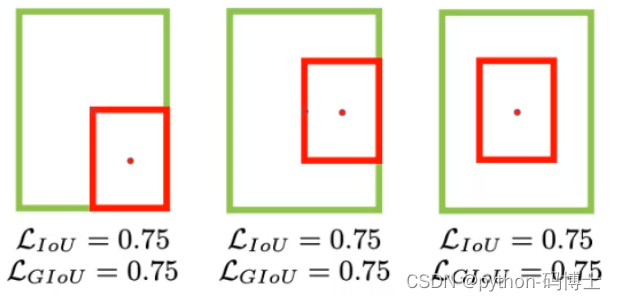
GIOU Loss
GIOU_Loss-为了解决以上的问题,GIOU损失应运而生。GIOU_Loss中增加了相交尺度的衡量方式,缓解了单纯IOU_Loss时存在的一些问题。
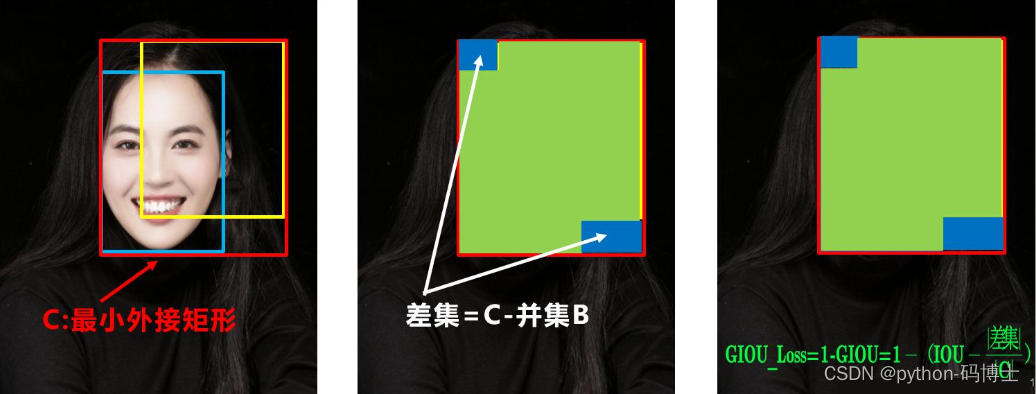
GIOU引入了最小封闭形状C(C是把A和B包含在内的最小矩形),在不重叠的情况下能让预测框尽可能的朝着真实框前进。
我们再看这个公式的最后一部分,意思是C减去A和B的并集再除以C,当然分子的值越小越好,最好为0。
L
G
I
o
U
=
1
−
I
o
U
+
∣
C
−
B
∪
B
g
t
∣
∣
C
∣
L_{GIoU} = 1-IoU + \frac{|C-B \cup B^{gt}|}{|C|}
LGIoU=1−IoU+∣C∣∣C−B∪Bgt∣
但是GIOU Loss也有一定的缺陷,就是当遇到预测框完全在真实框里面的时GIOU就和IOU一样了,不能确定哪个框更好了。
DIOU Loss
L
D
I
o
U
=
1
−
I
o
U
+
ρ
2
(
b
,
b
g
t
)
c
2
L_{DIoU} = 1-IoU + \frac{\rho^2(b,b^{gt})}{c^2}
LDIoU=1−IoU+c2ρ2(b,bgt)
b: 预测框
b{gt}: 真实框
ρ
\rho
ρ :欧式距离
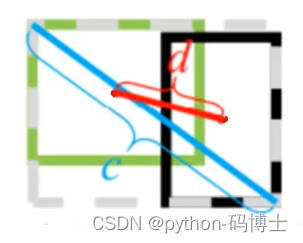
公式最后一部分的分子表示真实框和预测框中心点的欧式距离,图中d。
分母是能覆盖预测框与真实框的最小BOX的对角线长度,图中c
两个框越重合的时候,d值越小,当两个框重合时,d值为0。
DIOU直接优化距离,网络收敛速度更快,并且解决了GIOU的问题。也是用的比较多的方法。下面两张图片是为了好理解: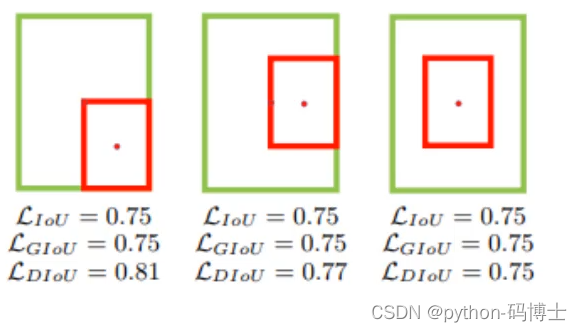

如下图所示,当真实框包裹预测框时,此时预测框的中心点的位置都是一样的,因此按照DIOU_Loss的计算公式,三者的值都是相同的。为了解决这个问题,CIOU_Loss应运而生。
CIOU Loss
L
C
I
o
U
=
1
−
I
o
U
+
ρ
2
(
b
,
b
g
t
)
c
2
+
α
ν
L_{CIoU} = 1-IoU + \frac{\rho^2(b,b^{gt})}{c^2}+\alpha\nu
LCIoU=1−IoU+c2ρ2(b,bgt)+αν
ν
=
4
π
2
(
arctan
ω
g
t
h
g
t
−
arctan
ω
h
)
2
\nu=\frac{4}{\pi^2}(\arctan\frac{\omega^{gt}}{h^{gt}}-\arctan\frac{\omega}{h})^2
ν=π24(arctanhgtωgt−arctanhω)2
α
=
ν
(
1
−
I
o
U
)
+
ν
\alpha=\frac{\nu}{(1-IoU)+\nu}
α=(1−IoU)+νν
一个好的损失函数要考虑3方面因素:重叠面积,中心点距离,长宽比
在DIOU的时候已经把重叠面积和中心点距离考虑进去了,现在还差一个长宽比
ν
\nu
ν。当真实框长宽比
ω
g
t
h
g
t
\frac{\omega^{gt}}{h^{gt}}
hgtωgt与预测框长宽比
ω
h
\frac{\omega}{h}
hω一直时最后一项为0,其中
α
\alpha
α可以看做权重参数。