本文摘自《Keras深度学习:入门、实战与进阶》。
https://item.jd.com/10038325202263.html

这个数据集由Alex Krizhevsky、Vinod Nair和Geoffrey Hinton收集整理,共包含了60000张32×32的彩色图像,50000张用于训练模型、10000张用于评估模型。可以从其主页(http://www.cs.toronto.edu/~kriz/cifar.html)下载。共有10个类别,它们是:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车。每个分类有6000个图像。

1、加载CIFAR-10数据
Keras提供了dataset_cifar10()函数用于下载或读取CIFAR-10数据。第一次运行dataset_cifar10()时,程序会检查是否有cifar-10-batches-py.tar.gz文件,如果还没有,就会下载文件,并且解压下载的文件。第一次运行因为需要下载文件,所以运行时间可能会比较长,之后就可以直接从本地加载数据,用于神经网络模型的训练。
如果是Windows环境,文件将存放在C:\Users\用户名\Documents.keras\datasets中。我们来查看解压后的cifar-10-batches-py目录下的内容。
# 查看cifar-10目录下的文件
> file <- 'C:/Users/Daniel/Documents/.keras/datasets/cifar-10-batches-py'
> list.files(file) # 查看目录下文件
[1] "batches.meta" "data_batch_1" "data_batch_2" "data_batch_3" "data_batch_4"
[6] "data_batch_5" "readme.html" "test_batch"
CIFAR-10数据集分为训练集和测试集两部分。训练集构成了5个训练批次(data_batch_1、data_batch_2、data_batch_3、data_batch_4、data_batch_5),每一批次10000张图。另外用于测试的10000张图单独构成一批(test_batch)。注意一个训练批次中的各类图像数量并不一定相同,总的训练样本包含来自每一类的5000张图。数据导入时,会直接被分割成训练集和测试集两部分,训练和测试数据又由图像数据和标签所组成。
> library(keras)
> c(c(x_train,y_train),c(x_test,y_test)) %<-% dataset_cifar10()
> # 查看数据维度
> dim(x_train);dim(x_test)
[1] 50000 32 32 3
[1] 10000 32 32 3
> dim(y_train);dim(y_test)
[1] 50000 1
[1] 10000 1
train训练数据集有50000项,test测试数据集10000项。x_train和x_test是四维数组,第一维是样本数,第二、三维是指图像大小为32×32,第四维是RGB三原色,所以是3。y_train和y_test是矩阵(二维数组),第一维是样本数,第二维是图像数据的实际真实值。每一个数字代表一种图像类别的名称:0:飞机(airplane)airplane、1:汽车(automobile)automobile、2:鸟(bird)bird、3:猫(cat)、43:鹿(deer)deer、4:dog、5:狗(dog)、6:青蛙(frog)frog、7:马(horse)horse、8:船(ship)ship、9:卡车(truck)truck。
运行以下程序代码,绘制train数据集中前10张图像
> # 绘制前10张图像
> label_dict <- data.frame('label' = 0:9,
+ 'name' = c("airplane","automobile","bird","cat","deer",
+ "dog","frog","horse","ship","truck"))
>
> par(mfrow=c(2,5))
> for(i in 1:10){
+ plot(as.raster(x_train[i,,,],max=255))
+ title(main = paste0(i-1,",",
+ label_dict[label_dict$label==y_train[i],2]))
+ }
> par(mfrow=c(1,1))

2、CIFAR-10数据预处理
为了将数据送入卷积神经网络模型进行训练与预测,必须进行数据的预处理。前面的维度分析可知,x_train和x_test的图像数据已经是四维数组,符合卷积神经网络模型的维度要求。
> x_train <- x_train / 255
> x_test <- x_test / 255
> min(x_train);max(x_train)
[1] 0
[1] 1
> min(x_test);max(x_test)
[1] 0
[1] 1
对于CIFAR-10数据集,我们希望预测图像的类型,例如“船”图像的label是8,经过独热编码(One-Hot Encoding)转换为0000000010,10个数字正好对应输出层10个神经元。可以利用to_categorical()函数进行转换。
> y_train_onehot <- to_categorical(y_train,num_classes = 10)
> y_test_onehot <- to_categorical(y_test, num_classes = 10)
> dim(y_train_onehot)
[1] 50000 10
> dim(y_test_onehot)
[1] 10000 10
3、构建简单卷积神经网络识别CIFAR-10图像
首先构建一个简单的卷积神经网络,来验证卷积神经网络在这个数据集上的性能,并以此为基础对网络进行优化,逐步提高模型的准确度。
这个简单的卷积神经网络具有两个卷积层、一个最大值池化层、一个Flatten层和一个全连接层,网络拓扑结构如下:
卷积层,具有32个特征图,卷积核大小为3×3,激活函数为Relu。
Dropout概率为20%的Dropout层。
卷积层,具有32个特征图,卷积核大小为3×3,激活函数为Relu。
Dropout概率为20%的Dropout层。
采样因子(pool_size)为2×2的最大值池化层。
Flatten层。
具有512个神经元和ReLU激活函数的全连接层。
Dropout概率为50%的Dropout层。
具有10个神经元的输出层,激活函数为softmax。
编译模型时,采用RMSProp优化器,categorical_crossentropy作为损失函数,同时采用准确率(accuracy)来评估模型的性能。
构建模型build_simple_cnn ()程序代码如下。
> build_simple_cnn <- function(X=trainx) {
+ model <- keras_model_sequential() %>%
+ layer_conv_2d(filters = 32,
+ kernel_size = c(3,3),
+ activation = 'relu',
+ input_shape = dim(X)[-1]) %>%
+ layer_dropout(rate = 0.2) %>%
+ layer_conv_2d(filters = 32,
+ kernel_size = c(3,3),
+ activation = 'relu') %>%
+ layer_dropout(rate = 0.2) %>%
+ layer_max_pooling_2d(pool_size = c(2,2)) %>%
+ layer_flatten() %>%
+ layer_dense(units = 512, activation = 'relu') %>%
+ layer_dropout(rate = 0.5) %>%
+ layer_dense(units = 10, activation = 'softmax')
+ # Compile
+ model %>% compile(
+ loss = 'categorical_crossentropy',
+ optimizer = optimizer_rmsprop(),
+ metrics = 'accuracy')
+ model
+ }
模型构建后,使用fit()函数进行模型训练。将训练周期参数epochs设置为25,batch_size参数为256,validation_split参数为0.2,说明从训练样本中抽取20%作为验证集。`
> simple_cnn_model <- build_simple_cnn(x_train)
> history <- simple_cnn_model %>%
+ fit(x_train,
+ y_train_onehot,
+ epochs = 25,
+ batch_size = 256,
+ validation_split = 0.2)
> plot(history)
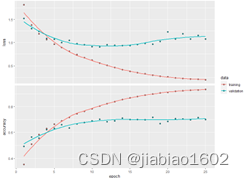
经过30个训练周期后,训练集的准确率为93%,验证集的准确率为70%,出现过拟合现象。可使用当监测值不再改善时将终止训练的callback_early_stopping()回调函数来监控模型,防止出现过拟合现象。
利用训练好的简单卷积神经网络模型对测试进行预测,并查看混淆矩阵。
> pred <- simple_cnn_model %>% predict_classes(x_test)
> t <- table(Actual = y_test,Predicted = pred)
> t
Predicted
Actual 0 1 2 3 4 5 6 7 8 9
0 788 24 28 18 27 1 12 10 55 37
1 23 817 5 13 3 2 8 4 27 98
2 100 11 470 85 117 68 61 47 22 19
3 37 18 46 525 102 137 42 38 22 33
4 34 4 33 63 691 33 47 69 13 13
5 23 9 38 226 63 535 18 57 14 17
6 14 12 28 73 57 25 755 8 11 17
7 27 4 25 43 78 40 4 739 8 32
8 77 46 7 19 5 2 4 6 795 39
9 44 98 7 14 4 1 6 13 24 789
模型对汽车(1:automobile)的预测能力最好,有817个样本被正确预测,准确率超过81%;其次是船(8:ship),有795个样本被正确预测。
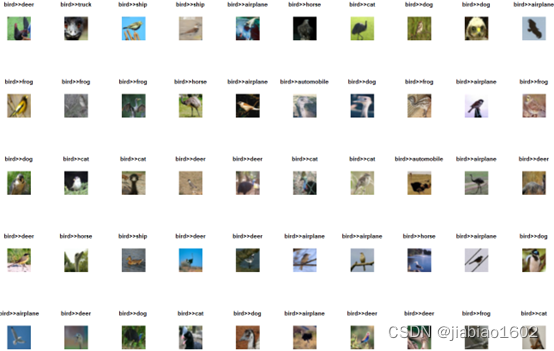
最后,让我们绘制实际是鸟,但预测错误的50张图像
> ind <- which(as.vector(y_test)==2 & pred != 2) # 提取实际为2,但预测不为2的下标集
> # 绘制预测错误的图像
> par(mfrow=c(5,10))
> for(i in 1:50){
+ plot(as.raster(x_test[ind[i],,,]))
+ title(main = paste0(label_dict[label_dict$label==y_test[ind[i]],2],">>",
+ label_dict[label_dict$label==pred[ind[i]],2]))
+
+ }
> par(mfrow=c(1,1))