基本思想:需要一个快的实例分割模型,由于需要配置oak使用,所以就记录和实现一下微软社区提供的思路,去部署PaddleSeg的轻量级(实际是语义)分割模型
所有的实验模型,花了两天。。。mmp 自己训练模型,开始整自己的业务需求了
链接: https://pan.baidu.com/s/1DrUaSU3u42hRbF8zWR8m2Q?pwd=c7id 提取码: c7id
一、需要本机配置好 openvion和cuda cudnn tensorRT环境,参考附录
ubuntu@ubuntu:~$ python -m pip install paddlepaddle-gpu==2.3.2.post111 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
ubuntu@ubuntu:~$ git clone https://github.com/PaddlePaddle/PaddleSeg.git
Cloning into 'PaddleSeg'...
remote: Enumerating objects: 21959, done.
remote: Counting objects: 100% (13/13), done.
remote: Compressing objects: 100% (12/12), done.
Receiving objects: 22% (4856/21959), 45.23 MiB | 757.00 KiB/s
Receiving objects: 61% (13554/21959), 245.85 MiB | 299.00 KiB/s
Receiving objects: 61% (13554/21959), 246.70 MiB | 432.00 KiB/s
remote: Total 21959 (delta 0), reused 6 (delta 0), pack-reused 21946
Receiving objects: 100% (21959/21959), 346.46 MiB | 341.00 KiB/s, done.
Resolving deltas: 100% (14409/14409), done.配置环境自己搞一下,测试图片
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/configs/pp_liteseg
ubuntu@ubuntu:~/PaddleSeg$ wget https://paddleseg.bj.bcebos.com/dygraph/camvid/pp_liteseg_stdc1_camvid_960x720_10k/model.pdparams
ubuntu@ubuntu:~$ axel -n 100 https://paddleseg.bj.bcebos.com/dataset/camvid.tar
ubuntu@ubuntu:~/PaddleSeg$ python3 predict.py --config /home/ubuntu/PaddleSeg/configs/pp_liteseg/pp_liteseg_stdc1_camvid_960x720_10k.yml --model_path /home/ubuntu/PaddleSeg/model.pdparams --image_path /home/ubuntu/camvid/images/0001TP_007980.png --device 0 --save_dir output --custom_color 0 0 0 255 255 255
测试结果


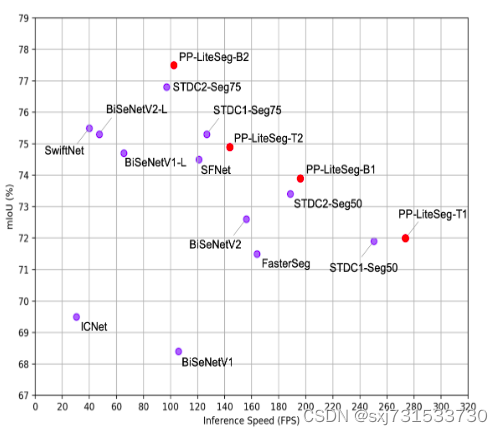
挑选这个模型的主要原因是官方提示最快的模型
二、1)转onnx模型,第一次用百度的东西,还是蛮贴心的
将代码中的
model = SavedSegmentationNet(model) # add argmax to the last layer
执行转换,对比paddle.shape有问题不用在意,因为打开了argmax
ubuntu@ubuntu:~/PaddleSeg$ python3 deploy/python/infer_onnx_trt.py --config /home/ubuntu/PaddleSeg/configs/pp_liteseg/pp_liteseg_stdc1_camvid_960x720_10k.yml --model_path /home/ubuntu/PaddleSeg/model.pdparams --save_dir ./saved --width 960 --height 720
/home/ubuntu/.local/lib/python3.8/site-packages/scipy/fft/__init__.py:97: DeprecationWarning: The module numpy.dual is deprecated. Instead of using dual, use the functions directly from numpy or scipy.
from numpy.dual import register_func
/home/ubuntu/.local/lib/python3.8/site-packages/scipy/sparse/sputils.py:17: DeprecationWarning: `np.typeDict` is a deprecated alias for `np.sctypeDict`.
supported_dtypes = [np.typeDict[x] for x in supported_dtypes]
/home/ubuntu/.local/lib/python3.8/site-packages/scipy/special/orthogonal.py:81: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
from numpy import (exp, inf, pi, sqrt, floor, sin, cos, around, int,
2022-11-22 14:00:41 [INFO] Loading pretrained model from https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet1.tar.gz
2022-11-22 14:00:41 [INFO] There are 145/145 variables loaded into STDCNet.
2022-11-22 14:00:41 [INFO] Loading pretrained model from /home/ubuntu/PaddleSeg/model.pdparams
2022-11-22 14:00:41 [INFO] There are 247/247 variables loaded into PPLiteSeg.
2022-11-22 14:00:41 [INFO] Loaded trained params of model successfully
==input shape: 720 960
out shape: (1, 1, 720, 960)
The paddle model has been predicted by PaddlePaddle.
2022-11-22 14:00:42 [INFO] Static PaddlePaddle model saved in ./saved/paddle_model_static_onnx_temp_dir.
[Paddle2ONNX] Start to parse PaddlePaddle model...
[Paddle2ONNX] Model file path: ./saved/paddle_model_static_onnx_temp_dir/model.pdmodel
[Paddle2ONNX] Paramters file path: ./saved/paddle_model_static_onnx_temp_dir/model.pdiparams
[Paddle2ONNX] Start to parsing Paddle model...
[Paddle2ONNX] Use opset_version = 11 for ONNX export.
[Paddle2ONNX] PaddlePaddle model is exported as ONNX format now.
2022-11-22 14:00:43 [INFO] ONNX model saved in ./saved/pp_liteseg_stdc1_camvid_960x720_10k_model.onnx.
Completed export onnx model.
The onnx model has been checked.
The onnx model has been predicted by ONNXRuntime.
(1, 720, 960)
/usr/lib/python3/dist-packages/apport/report.py:13: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import fnmatch, glob, traceback, errno, sys, atexit, locale, imp, stat
Traceback (most recent call last):
File "deploy/python/infer_onnx_trt.py", line 491, in <module>
export_load_infer(args)
File "deploy/python/infer_onnx_trt.py", line 439, in export_load_infer
assert onnx_out.shape == paddle_out.shape
AssertionError
2)基于onnx转mnn模型,在这转ncnn模型存在很多不支持的算子,以后有机会在搞,客户要求2天交工,先完成业务
ubuntu@ubuntu:~/MNN/build$ ./MNNConvert -f ONNX --modelFile /home/ubuntu/PaddleSeg/saved/pp_liteseg_stdc1_camvid_960x720_10k_model.onnx --MNNModel /home/ubuntu/PaddleSeg/saved/pp_liteseg_stdc1_camvid_960x720_10k_model.mnn --bizCode MNN
Start to Convert Other Model Format To MNN Model...
[14:00:51] /home/ubuntu/MNN/tools/converter/source/onnx/onnxConverter.cpp:40: ONNX Model ir version: 8
Start to Optimize the MNN Net...
inputTensors : [ x, ]
outputTensors: [ argmax_0.tmp_0, ]
Converted Success!
3)部署mnn框架上
cmakelists.txt
cmake_minimum_required(VERSION 3.16)
project(SegClion)
set(CMAKE_CXX_FLAGS "-std=c++11")
set(CMAKE_CXX_STANDARD 11)
include_directories(${CMAKE_SOURCE_DIR})
include_directories(${CMAKE_SOURCE_DIR}/include)
include_directories(${CMAKE_SOURCE_DIR}/include/MNN)
find_package(OpenCV REQUIRED)
#message(STATUS ${OpenCV_INCLUDE_DIRS})
#添加头文件
include_directories(${OpenCV_INCLUDE_DIRS})
#链接Opencv库
add_library(libmnn SHARED IMPORTED)
set_target_properties(libmnn PROPERTIES IMPORTED_LOCATION ${CMAKE_SOURCE_DIR}/lib/libMNN.so)
add_executable(SegClion main.cpp )
target_link_libraries(SegClion ${OpenCV_LIBS} libmnn )main.cpp
#include <iostream>
#include <algorithm>
#include <vector>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/opencv.hpp>
#include<MNN/Interpreter.hpp>
#include<MNN/ImageProcess.hpp>
using namespace std;
using namespace cv;
int main(int argc, char **argv) {
cv::Mat bgr = cv::imread("/home/ubuntu/VOCdevkit/0001TP_007980.png");;
int orignal_width=bgr.cols;
int orignal_height=bgr.rows;
int target_width=960;
int target_height=720;
cv::Mat resize_img;
cv::resize(bgr, resize_img, cv::Size(target_width, target_height));
auto start = chrono::high_resolution_clock::now(); //开始时间
// MNN inference
auto mnnNet = std::shared_ptr<MNN::Interpreter>(
MNN::Interpreter::createFromFile(
"/home/ubuntu/PaddleSeg/saved/pp_liteseg_stdc1_camvid_960x720_10k_model.mnn"));
auto t1 = std::chrono::steady_clock::now();
MNN::ScheduleConfig netConfig;
netConfig.type = MNN_FORWARD_CPU;
netConfig.numThread = 4;
auto session = mnnNet->createSession(netConfig);
auto input = mnnNet->getSessionInput(session, nullptr);
mnnNet->resizeTensor(input, {1, 3, target_height, target_width});
mnnNet->resizeSession(session);
MNN::CV::ImageProcess::Config config;
const float mean_vals[3] = {255 * 0.5f, 255 * 0.5f, 255 * 0.5f};
const float norm_255[3] = {1.f / (255 * 0.5), 1.f / (255 * 0.5), 1.f / (255 * 0.5)};
std::shared_ptr<MNN::CV::ImageProcess> pretreat(
MNN::CV::ImageProcess::create(MNN::CV::BGR, MNN::CV::RGB, mean_vals, 3,
norm_255, 3));
pretreat->convert(resize_img.data, target_width, target_height, resize_img.step[0], input);
mnnNet->runSession(session);
auto Sessionscores = mnnNet->getSessionOutput(session, "argmax_0.tmp_0");
MNN::Tensor scoresHost(Sessionscores, Sessionscores->getDimensionType());
Sessionscores->copyToHostTensor(&scoresHost);
int w = scoresHost.width();
int h = scoresHost.height();
int c = scoresHost.channel();
int b = scoresHost.batch();
//printf(" w=%d h=%d c=%d b=%d\n", w, h, c, b);
std::vector<int> vec_host_scores;
///
w=c;
h=h;
c=1;
//printf("new_w=%d new_h=%d new_c=%d new_b=%d\n", w, h, c, b);
for (int i = 0; i < scoresHost.elementSize(); i++) {
vec_host_scores.emplace_back(scoresHost.host<int>()[i]);
}
auto end = chrono::high_resolution_clock::now(); //结束时间
auto duration = (end - start).count();
cout << "程序运行时间:" << setprecision(10) << duration / 1000000000.0 << "s"
<< "; " << duration / 1000000.0 << "ms"
<< "; " << duration / 1000.0 << "us"
<< endl;
int num_class = 256;
vector<int> color_map(num_class * 3);
for (int i = 0; i < num_class; i++) {
int j = 0;
int lab = i;
while (lab) {
color_map[i * 3] |= ((lab >> 0 & 1) << (7 - j));
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j));
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j));
j += 1;
lab >>= 3;
}
}
cv::Mat pseudo_img(w, h, CV_8UC3, cv::Scalar(0, 0, 0));
for (int r = 0; r < w; r++) {
for (int c = 0; c < h; c++) {
int idx = vec_host_scores[r*h + c];
pseudo_img.at<Vec3b>(r, c)[0] = color_map[idx * 3];
pseudo_img.at<Vec3b>(r, c)[1] = color_map[idx * 3 + 1];
pseudo_img.at<Vec3b>(r, c)[2] = color_map[idx * 3 + 2];
}
}
cv::Mat result;
cv::addWeighted(resize_img, 0.4, pseudo_img, 0.6, 0, result, 0);
cv::imshow("pseudo_img", pseudo_img);
cv::imwrite("pseudo_img.jpg", pseudo_img);
cv::imshow("bgr", resize_img);
cv::imwrite("resize_img.jpg", resize_img);
cv::imshow("result", result);
cv::imwrite("result.jpg", result);
cv::resize(result,result,cv::Size(orignal_width,orignal_height));
cv::waitKey(0);
mnnNet->releaseModel();
mnnNet->releaseSession(session);
return 0;
}测试时间
/home/ubuntu/untitled12/cmake-build-debug/SparseInstClion
程序运行时间:0.26398354s; 263.98354ms; 263983.54us
Process finished with exit code 0测试结果


三、1)转openvion模型、oak模型、部署
ubuntu@ubuntu:~$ ubuntu@ubuntu:~$ python /opt/intel/openvino_2021/deployment_tools/model_optimizer/mo.py --input_model /home/ubuntu/PaddleSeg/saved/pp_liteseg_stdc1_camvid_960x720_10k_model.onnx --output_dir /home/ubuntu/PaddleSeg/saved/FP16 --input_shape [1,3,720,960] --data_type FP16 --scale_values [127.5,127.5,127.5] --mean_values [127.5,127.5,127.5]
[ SUCCESS ] Generated IR version 10 model.
[ SUCCESS ] XML file: /home/ubuntu/PaddleSeg/saved/FP16/pp_liteseg_stdc1_camvid_960x720_10k_model.xml
[ SUCCESS ] BIN file: /home/ubuntu/PaddleSeg/saved/FP16/pp_liteseg_stdc1_camvid_960x720_10k_model.bin
[ SUCCESS ] Total execution time: 8.82 seconds.
[ SUCCESS ] Memory consumed: 243 MB.
It's been a while, check for a new version of Intel(R) Distribution of OpenVINO(TM) toolkit here https://software.intel.com/content/www/us/en/develop/tools/openvino-toolkit/download.html?cid=other&source=prod&campid=ww_2021_bu_IOTG_OpenVINO-2021-4-LTS&content=upg_all&medium=organic or on the GitHub*cmakelists.txt
cmake_minimum_required(VERSION 3.4.1)
set(CMAKE_CXX_STANDARD 14)
project(nanodet_demo)
find_package(OpenCV REQUIRED)
find_package(ngraph REQUIRED)
find_package(InferenceEngine REQUIRED)
include_directories(
${OpenCV_INCLUDE_DIRS}
${CMAKE_CURRENT_SOURCE_DIR}
${CMAKE_CURRENT_BINARY_DIR}
)
add_executable(nanodet_demo main.cpp )
target_link_libraries(
nanodet_demo
${InferenceEngine_LIBRARIES}
${NGRAPH_LIBRARIES}
${OpenCV_LIBS}
)main.cpp
#include <inference_engine.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <iostream>
#include <vector>
#include <chrono>
#include <iomanip> // Header file needed to use setprecision
using namespace std;
using namespace cv;
void preprocess(cv::Mat image, InferenceEngine::Blob::Ptr &blob) {
int img_w = image.cols;
int img_h = image.rows;
int channels = 3;
InferenceEngine::MemoryBlob::Ptr mblob = InferenceEngine::as<InferenceEngine::MemoryBlob>(blob);
if (!mblob) {
THROW_IE_EXCEPTION << "We expect blob to be inherited from MemoryBlob in matU8ToBlob, "
<< "but by fact we were not able to cast inputBlob to MemoryBlob";
}
// locked memory holder should be alive all time while access to its buffer happens
auto mblobHolder = mblob->wmap();
float *blob_data = mblobHolder.as<float *>();
for (size_t c = 0; c < channels; c++) {
for (size_t h = 0; h < img_h; h++) {
for (size_t w = 0; w < img_w; w++) {
blob_data[c * img_w * img_h + h * img_w + w] =
(float) image.at<cv::Vec3b>(h, w)[c];
}
}
}
}
int main(int argc, char **argv) {
cv::Mat bgr = cv::imread("/home/ubuntu/VOCdevkit/0001TP_007980.png");
int orignal_width = bgr.cols;
int orignal_height = bgr.rows;
int target_width = 960;
int target_height = 720;
cv::Mat rgb;
cv::cvtColor(bgr, rgb, cv::COLOR_BGR2RGB);
cv::Mat resize_img;
cv::resize(rgb, resize_img, cv::Size(target_width, target_height));
// resize_img.convertTo(resize_img, CV_32FC1, 1.0 / 255, 0);
//resize_img = (resize_img - 0.5) / 0.5;
auto start = chrono::high_resolution_clock::now(); //开始时间
std::string input_name_ = "x";
std::string output_name_ = "argmax_0.tmp_0";
std::string model_path = "/home/ubuntu/PaddleSeg/saved/FP16/pp_liteseg_stdc1_camvid_960x720_10k_model.xml";
InferenceEngine::Core ie;
InferenceEngine::CNNNetwork model = ie.ReadNetwork(model_path);
// prepare input settings
InferenceEngine::InputsDataMap inputs_map(model.getInputsInfo());
input_name_ = inputs_map.begin()->first;
InferenceEngine::InputInfo::Ptr input_info = inputs_map.begin()->second;
//input_info->setPrecision(InferenceEngine::Precision::FP32);
//input_info->setLayout(InferenceEngine::Layout::NCHW);
//prepare output settings
InferenceEngine::OutputsDataMap outputs_map(model.getOutputsInfo());
for (auto &output_info : outputs_map) {
std::cout << "Output:" << output_info.first << std::endl;
output_info.second->setPrecision(InferenceEngine::Precision::FP32);
}
//get network
InferenceEngine::ExecutableNetwork network_ = ie.LoadNetwork(model, "CPU");
InferenceEngine::InferRequest infer_request_ = network_.CreateInferRequest();
InferenceEngine::Blob::Ptr input_blob = infer_request_.GetBlob(input_name_);
preprocess(resize_img, input_blob);
// do inference
infer_request_.Infer();
const InferenceEngine::Blob::Ptr pred_blob = infer_request_.GetBlob(output_name_);
auto m_pred = InferenceEngine::as<InferenceEngine::MemoryBlob>(pred_blob);
auto m_pred_holder = m_pred->rmap();
const float *pred = m_pred_holder.as<const float *>();
auto end = chrono::high_resolution_clock::now(); //结束时间
auto duration = (end - start).count();
cout << "程序运行时间:" << std::setprecision(10) << duration / 1000000000.0 << "s"
<< "; " << duration / 1000000.0 << "ms"
<< "; " << duration / 1000.0 << "us"
<< endl;
int w = target_height;
int h = target_width;
std::vector<int> vec_host_scores;
for (int i = 0; i < w * h; i++) {
vec_host_scores.emplace_back(pred[i]);
}
int num_class = 256;
vector<int> color_map(num_class * 3);
for (int i = 0; i < num_class; i++) {
int j = 0;
int lab = i;
while (lab) {
color_map[i * 3] |= ((lab >> 0 & 1) << (7 - j));
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j));
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j));
j += 1;
lab >>= 3;
}
}
cv::Mat pseudo_img(w, h, CV_8UC3, cv::Scalar(0, 0, 0));
for (int r = 0; r < w; r++) {
for (int c = 0; c < h; c++) {
int idx = vec_host_scores[r * h + c];
pseudo_img.at<Vec3b>(r, c)[0] = color_map[idx * 3];
pseudo_img.at<Vec3b>(r, c)[1] = color_map[idx * 3 + 1];
pseudo_img.at<Vec3b>(r, c)[2] = color_map[idx * 3 + 2];
}
}
cv::Mat result;
cv::addWeighted(resize_img, 0.4, pseudo_img, 0.6, 0, result, 0);
cv::imshow("pseudo_img", pseudo_img);
cv::imwrite("pseudo_img.jpg", pseudo_img);
cv::imshow("bgr", bgr);
cv::imwrite("resize_img.jpg", resize_img);
cv::imshow("result", result);
cv::imwrite("result.jpg", result);
cv::resize(result, result, cv::Size(w, h));
cv::waitKey(0);
return 0;
}
测试结果
/home/ubuntu/nanodet/demo_openvino/cmake-build-debug/nanodet_demo
Output:argmax_0.tmp_0
程序运行时间:0.274273849s; 274.273849ms; 274273.849us
图片


2)转oak模型和部署
ubuntu@ubuntu:/opt/intel/openvino_2021/deployment_tools/tools/compile_tool$ ./compile_tool -m /home/ubuntu/PaddleSeg/saved/FP16/pp_liteseg_stdc1_camvid_960x720_10k_model.xml -ip U8 -d MYRIAD -VPU_NUMBER_OF_SHAVES 4 -VPU_NUMBER_OF_CMX_SLICES 4
Inference Engine:
IE version ......... 2021.4.1
Build ........... 2021.4.1-3926-14e67d86634-releases/2021/4
Network inputs:
x : U8 / NCHW
Network outputs:
argmax_0.tmp_0 : I32 / CHW
[Warning][VPU][Config] Deprecated option was used : VPU_MYRIAD_PLATFORM
Done. LoadNetwork time elapsed: 6655 ms
ubuntu@ubuntu:/opt/intel/openvino_2021/deployment_tools/tools/compile_tool$ cp pp_liteseg_stdc1_camvid_960x720_10k_model.blob /home/ubuntu/PaddleSeg/saved/FP16
python代码
#!/usr/bin/env python3
import cv2
import depthai as dai
import numpy as np
import argparse
import time
import os
def get_color_map_list(num_classes, custom_color=None):
"""
Returns the color map for visualizing the segmentation mask,
which can support arbitrary number of classes.
Args:
num_classes (int): Number of classes.
custom_color (list, optional): Save images with a custom color map. Default: None, use paddleseg's default color map.
Returns:
(list). The color map.
"""
num_classes += 1
color_map = num_classes * [0, 0, 0]
for i in range(0, num_classes):
j = 0
lab = i
while lab:
color_map[i * 3] |= (((lab >> 0) & 1) << (7 - j))
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j))
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j))
j += 1
lab >>= 3
color_map = color_map[3:]
if custom_color:
color_map[:len(custom_color)] = custom_color
return color_map
def visualize(image, result, color_map, save_dir=None, weight=0.6):
"""
Convert predict result to color image, and save added image.
Args:
image (str): The path of origin image.
result (np.ndarray): The predict result of image.
color_map (list): The color used to save the prediction results.
save_dir (str): The directory for saving visual image. Default: None.
weight (float): The image weight of visual image, and the result weight is (1 - weight). Default: 0.6
Returns:
vis_result (np.ndarray): If `save_dir` is None, return the visualized result.
"""
color_map = [color_map[i:i + 3] for i in range(0, len(color_map), 3)]
color_map = np.array(color_map).astype("uint8")
# Use OpenCV LUT for color mapping
c1 = cv2.LUT(result, color_map[:, 0])
c2 = cv2.LUT(result, color_map[:, 1])
c3 = cv2.LUT(result, color_map[:, 2])
pseudo_img = np.dstack((c3, c2, c1))
im = image
vis_result = cv2.addWeighted(im, weight, pseudo_img, 1 - weight, 0)
if save_dir is not None:
if not os.path.exists(save_dir):
os.makedirs(save_dir)
image_name = os.path.split(image)[-1]
out_path = os.path.join(save_dir, image_name)
cv2.imwrite(out_path, vis_result)
else:
return vis_result
nn_shape = [960,720] #width height
class_num=256
color_map=get_color_map_list(class_num)
# Start defining a pipeline
pipeline = dai.Pipeline()
pipeline.setOpenVINOVersion(version = dai.OpenVINO.VERSION_2021_4)
# Define a neural network that will make predictions based on the source frames
detection_nn = pipeline.create(dai.node.NeuralNetwork)
detection_nn.setBlobPath("/home/ubuntu/PaddleSeg/saved/FP16/pp_liteseg_stdc1_camvid_960x720_10k_model.blob")
detection_nn.setNumPoolFrames(4)
detection_nn.input.setBlocking(False)
detection_nn.setNumInferenceThreads(2)
# Define a source - color camera
cam = pipeline.create(dai.node.ColorCamera)
cam.setPreviewSize(nn_shape[1],nn_shape[0])
cam.setInterleaved(False)
cam.preview.link(detection_nn.input)
cam.setFps(40)
# Create outputs
xout_rgb = pipeline.create(dai.node.XLinkOut)
xout_rgb.setStreamName("nn_input")
xout_rgb.input.setBlocking(False)
detection_nn.passthrough.link(xout_rgb.input)
xout_nn = pipeline.create(dai.node.XLinkOut)
xout_nn.setStreamName("nn")
xout_nn.input.setBlocking(False)
detection_nn.out.link(xout_nn.input)
# Pipeline defined, now the device is assigned and pipeline is started
with dai.Device() as device:
cams = device.getConnectedCameras()
device.startPipeline(pipeline)
# Output queues will be used to get the rgb frames and nn data from the outputs defined above
q_nn_input = device.getOutputQueue(name="nn_input", maxSize=4, blocking=False)
q_nn = device.getOutputQueue(name="nn", maxSize=4, blocking=False)
start_time = time.time()
counter = 0
fps = 0
layer_info_printed = True
while True:
# instead of get (blocking) used tryGet (nonblocking) which will return the available data or None otherwise
in_nn_input = q_nn_input.get()
in_nn = q_nn.get()
frame = in_nn_input.getCvFrame()
layers = in_nn.getAllLayers()
if layer_info_printed:
for item in layers:
print(item.name)
layer_info_printed=False
# get layer1 data
pred = in_nn.getFirstLayerInt32()
pred = np.array(pred).astype('uint8').reshape(nn_shape[0],nn_shape[1])
frame = visualize(frame, pred, color_map, None, weight=0.6)
cv2.imwrite("oak.jpg",frame)
cv2.putText(frame, "NN fps: {:.2f}".format(fps), (2, frame.shape[0] - 4), cv2.FONT_HERSHEY_TRIPLEX, 0.4, (255, 0, 0))
cv2.imshow("nn_input", frame)
counter+=1
if (time.time() - start_time) > 1 :
fps = counter / (time.time() - start_time)
counter = 0
start_time = time.time()
if cv2.waitKey(1) == ord('q'):
break测试结果,测试摄像头的

c++代码
cmakelist.txt
cmake_minimum_required(VERSION 3.16)
project(untitled15)
set(CMAKE_CXX_STANDARD 11)
find_package(OpenCV REQUIRED)
#message(STATUS ${OpenCV_INCLUDE_DIRS})
#添加头文件
include_directories(${OpenCV_INCLUDE_DIRS})
include_directories(${CMAKE_SOURCE_DIR}/include)
include_directories(${CMAKE_SOURCE_DIR}/include/utility)
#链接Opencv库
find_package(depthai CONFIG REQUIRED)
add_executable(untitled15 main.cpp include/utility/utility.cpp)
target_link_libraries(untitled15 ${OpenCV_LIBS} depthai::opencv )main.cpp
#include <stdio.h>
#include <string>
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include "utility.hpp"
#include <vector>
#include "depthai/depthai.hpp"
using namespace std;
using namespace std::chrono;
using namespace cv;
int post_process(std::vector<int> vec_host_scores,cv::Mat resize_img,cv::Mat &result, vector<int> color_map,int w,int h){
cv::Mat pseudo_img(w, h, CV_8UC3, cv::Scalar(0, 0, 0));
for (int r = 0; r < w; r++) {
for (int c = 0; c < h; c++) {
int idx = vec_host_scores[r*h + c];
pseudo_img.at<Vec3b>(r, c)[0] = color_map[idx * 3];
pseudo_img.at<Vec3b>(r, c)[1] = color_map[idx * 3 + 1];
pseudo_img.at<Vec3b>(r, c)[2] = color_map[idx * 3 + 2];
}
}
cv::addWeighted(resize_img, 0.4, pseudo_img, 0.6, 0, result, 0);
//cv::imshow("pseudo_img", pseudo_img);
cv::imwrite(".pseudo_img.jpg", pseudo_img);
// cv::imshow("bgr", resize_img);
cv::imwrite("resize_img.jpg", resize_img);
//cv::imshow("result", result);
cv::imwrite("result.jpg", result);
//cv::waitKey(0);
return 0;
}
int main(int argc, char **argv) {
int num_class = 256;
vector<int> color_map(num_class * 3);
for (int i = 0; i < num_class; i++) {
int j = 0;
int lab = i;
while (lab) {
color_map[i * 3] |= ((lab >> 0 & 1) << (7 - j));
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j));
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j));
j += 1;
lab >>= 3;
}
}
int target_width=960;
int target_height=720;
dai::Pipeline pipeline;
//定义
auto cam = pipeline.create<dai::node::ColorCamera>();
cam->setBoardSocket(dai::CameraBoardSocket::RGB);
cam->setResolution(dai::ColorCameraProperties::SensorResolution::THE_1080_P);
cam->setPreviewSize(target_height, target_width); // NN input
cam->setInterleaved(false);
auto net = pipeline.create<dai::node::NeuralNetwork>();
dai::OpenVINO::Blob blob("/home/ubuntu/PaddleSeg/saved/FP16/pp_liteseg_stdc1_camvid_960x720_10k_model.blob");
net->setBlob(blob);
net->input.setBlocking(false);
//基本熟练明白oak的函数使用了
cam->preview.link(net->input);
//定义输出
auto xlinkParserOut = pipeline.create<dai::node::XLinkOut>();
xlinkParserOut->setStreamName("parseOut");
auto xlinkoutOut = pipeline.create<dai::node::XLinkOut>();
xlinkoutOut->setStreamName("out");
auto xlinkoutpassthroughOut = pipeline.create<dai::node::XLinkOut>();
xlinkoutpassthroughOut->setStreamName("passthrough");
net->out.link(xlinkParserOut->input);
net->passthrough.link(xlinkoutpassthroughOut->input);
//结构推送相机
dai::Device device(pipeline);
//取帧显示
auto outqueue = device.getOutputQueue("passthrough", 8, false);//maxsize 代表缓冲数据
auto detqueue = device.getOutputQueue("parseOut", 8, false);//maxsize 代表缓冲数据
bool printOutputLayersOnce=true;
while (true) {
auto ImgFrame = outqueue->get<dai::ImgFrame>();
auto frame = ImgFrame->getCvFrame();
auto inNN = detqueue->get<dai::NNData>();
if( printOutputLayersOnce&&inNN) {
std::cout << "Output layer names: ";
for(const auto& ten : inNN->getAllLayerNames()) {
std::cout << ten << ", ";
}
std::cout << std::endl;
printOutputLayersOnce = false;
}
cv::Mat result;
auto pred=inNN->getLayerInt32(inNN->getAllLayerNames()[0]);
post_process(pred,frame,result,color_map,target_width,target_height);
cv::imshow("demo", frame);
cv::imshow("result", result);
cv::imwrite("result.jpg",result);
cv::waitKey(1);
}
return 0;
}测试结果 感觉有问题,我先用图片测测

2),我的搞个读图片的比较好
#include <stdio.h>
#include <string>
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include "utility.hpp"
#include <vector>
#include "depthai/depthai.hpp"
using namespace std;
using namespace std::chrono;
using namespace cv;
int post_process(std::vector<int> vec_host_scores,cv::Mat resize_img,cv::Mat &result, vector<int> color_map,int w,int h){
cv::Mat pseudo_img(w, h, CV_8UC3, cv::Scalar(0, 0, 0));
for (int r = 0; r < w; r++) {
for (int c = 0; c < h; c++) {
int idx = vec_host_scores[r*h + c];
pseudo_img.at<Vec3b>(r, c)[0] = color_map[idx * 3];
pseudo_img.at<Vec3b>(r, c)[1] = color_map[idx * 3 + 1];
pseudo_img.at<Vec3b>(r, c)[2] = color_map[idx * 3 + 2];
}
}
cv::addWeighted(resize_img, 0.4, pseudo_img, 0.6, 0, result, 0);
//cv::imshow("pseudo_img", pseudo_img);
cv::imwrite(".pseudo_img.jpg", pseudo_img);
// cv::imshow("bgr", resize_img);
cv::imwrite("resize_img.jpg", resize_img);
//cv::imshow("result", result);
cv::imwrite("result.jpg", result);
//cv::waitKey(0);
return 0;
}
int main(int argc, char **argv) {
int num_class = 256;
vector<int> color_map(num_class * 3);
for (int i = 0; i < num_class; i++) {
int j = 0;
int lab = i;
while (lab) {
color_map[i * 3] |= ((lab >> 0 & 1) << (7 - j));
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j));
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j));
j += 1;
lab >>= 3;
}
}
int target_width=960;
int target_height=720;
dai::Pipeline pipeline;
//定义
auto cam = pipeline.create<dai::node::XLinkIn>();
cam->setStreamName("inFrame");
auto net = pipeline.create<dai::node::NeuralNetwork>();
dai::OpenVINO::Blob blob("/home/ubuntu/PaddleSeg/saved/FP16/pp_liteseg_stdc1_camvid_960x720_10k_model.blob");
net->setBlob(blob);
net->input.setBlocking(false);
//基本熟练明白oak的函数使用了
cam->out.link(net->input);
//定义输出
auto xlinkParserOut = pipeline.create<dai::node::XLinkOut>();
xlinkParserOut->setStreamName("parseOut");
auto xlinkoutOut = pipeline.create<dai::node::XLinkOut>();
xlinkoutOut->setStreamName("out");
auto xlinkoutpassthroughOut = pipeline.create<dai::node::XLinkOut>();
xlinkoutpassthroughOut->setStreamName("passthrough");
net->out.link(xlinkParserOut->input);
net->passthrough.link(xlinkoutpassthroughOut->input);
//结构推送相机
dai::Device device(pipeline);
//取帧显示
auto inqueue = device.getInputQueue("inFrame");//maxsize 代表缓冲数据
auto detqueue = device.getOutputQueue("parseOut", 8, false);//maxsize 代表缓冲数据
bool printOutputLayersOnce=true;
cv::Mat frame=cv::imread("/home/ubuntu/VOCdevkit/0001TP_007980.png");
while(true) {
if(frame.empty()) break;
auto img = std::make_shared<dai::ImgFrame>();
frame = resizeKeepAspectRatio(frame, cv::Size(target_height, target_width), cv::Scalar(0));
toPlanar(frame, img->getData());
img->setTimestamp(steady_clock::now());
img->setWidth(target_height);
img->setHeight(target_width);
inqueue->send(img);
auto inNN = detqueue->get<dai::NNData>();
if( printOutputLayersOnce&&inNN) {
std::cout << "Output layer names: ";
for(const auto& ten : inNN->getAllLayerNames()) {
std::cout << ten << ", ";
}
std::cout << std::endl;
printOutputLayersOnce = false;
}
cv::Mat result;
auto pred=inNN->getLayerInt32(inNN->getAllLayerNames()[0]);
post_process(pred,frame,result,color_map,target_width,target_height);
cv::imshow("demo", frame);
cv::imshow("result", result);
cv::imwrite("result.jpg",result);
int key = cv::waitKey(1);
if(key == 'q' || key == 'Q') return 0;
}
// while (true) {
//
//
// auto ImgFrame = outqueue->get<dai::ImgFrame>();
// auto frame = ImgFrame->getCvFrame();
//
// auto inNN = detqueue->get<dai::NNData>();
// if( printOutputLayersOnce&&inNN) {
// std::cout << "Output layer names: ";
// for(const auto& ten : inNN->getAllLayerNames()) {
// std::cout << ten << ", ";
// }
// std::cout << std::endl;
// printOutputLayersOnce = false;
// }
// cv::Mat result;
// auto pred=inNN->getLayerInt32(inNN->getAllLayerNames()[0]);
//
// post_process(pred,frame,result,color_map,target_width,target_height);
// cv::imshow("demo", frame);
// cv::imshow("result", result);
// cv::imwrite("result.jpg",result);
// cv::waitKey(1);
//
//
// }
return 0;
}测试图片没有太大问题

还是训练等宽高的吧,,,
四、转rknn部署rk3399 pro上
dataset.txt
0001TP_007980.png
转换代码
from rknn.api import RKNN
ONNX_MODEL = '/home/ubuntu/PaddleSeg/saved/pp_liteseg_stdc1_camvid_960x720_10k_model.onnx'
RKNN_MODEL = '/home/ubuntu/PaddleSeg/saved/pp_liteseg_stdc1_camvid_960x720_10k_model.rknn'
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
# pre-process config
print('--> config model')
rknn.config(mean_values=[[127.5, 127.5, 127.5]], std_values=[[127.5, 127.5, 127.5]], reorder_channel='0 1 2',
target_platform='rk3399pro',
quantized_dtype='asymmetric_affine-u8', optimization_level=3, output_optimize=1)
print('done')
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset='dataset.txt') # ,pre_compile=True
if ret != 0:
print('Build pp_liteseg_stdc1_camvid_960x720_10k_model failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export RKNN model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export pp_liteseg_stdc1_camvid_960x720_10k_model.rknn failed!')
exit(ret)
print('done')
rknn.release()转换成功
D Packing Conv_p2o.Conv.8_47 ...
D Quantize @Conv_p2o.Conv.8_47:bias to asymmetric_affine.
D Quantize @Conv_p2o.Conv.8_47:weight to asymmetric_affine.
D Packing Conv_p2o.Conv.9_48 ...
D Quantize @Conv_p2o.Conv.9_48:bias to asymmetric_affine.
D Quantize @Conv_p2o.Conv.9_48:weight to asymmetric_affine.
D Packing Mul_p2o.Mul.1_109_Add_p2o.Add.6_99 ...
D Packing Mul_p2o.Mul.5_54_Add_p2o.Add.9_45 ...
D Packing Mul_p2o.Mul.9_20_Add_p2o.Add.12_16 ...
D Disable rknn op statistic.
D output tensor id = 0, name = ArgMax_p2o.ArgMax.0/out0_0
D input tensor id = 1, name = x_195
I Build config finished.
done
--> Export RKNN model
done
py仿真测试
import os
import urllib
import traceback
import time
import sys
import warnings
import numpy as np
import cv2
from rknn.api import RKNN
RKNN_MODEL = "/home/ubuntu/PaddleSeg/saved/pp_liteseg_stdc1_camvid_960x720_10k_model.rknn"
IMG_PATH = "/home/ubuntu/PycharmProjects/untitled3/0001TP_007980.png"
QUANTIZE_ON = True
def visualize(image, result, color_map, save_dir=None, weight=0.6):
"""
Convert predict result to color image, and save added image.
Args:
image (str): The path of origin image.
result (np.ndarray): The predict result of image.
color_map (list): The color used to save the prediction results.
save_dir (str): The directory for saving visual image. Default: None.
weight (float): The image weight of visual image, and the result weight is (1 - weight). Default: 0.6
Returns:
vis_result (np.ndarray): If `save_dir` is None, return the visualized result.
"""
color_map = [color_map[i:i + 3] for i in range(0, len(color_map), 3)]
color_map = np.array(color_map).astype("uint8")
# Use OpenCV LUT for color mapping
c1 = cv2.LUT(result, color_map[:, 0])
c2 = cv2.LUT(result, color_map[:, 1])
c3 = cv2.LUT(result, color_map[:, 2])
pseudo_img = np.dstack((c3, c2, c1))
im = image
vis_result = cv2.addWeighted(im, weight, pseudo_img, 1 - weight, 0)
if save_dir is not None:
if not os.path.exists(save_dir):
os.makedirs(save_dir)
image_name = os.path.split(image)[-1]
out_path = os.path.join(save_dir, image_name)
cv2.imwrite(out_path, vis_result)
else:
return vis_result
def get_color_map_list(num_classes, custom_color=None):
"""
Returns the color map for visualizing the segmentation mask,
which can support arbitrary number of classes.
Args:
num_classes (int): Number of classes.
custom_color (list, optional): Save images with a custom color map. Default: None, use paddleseg's default color map.
Returns:
(list). The color map.
"""
num_classes += 1
color_map = num_classes * [0, 0, 0]
for i in range(0, num_classes):
j = 0
lab = i
while lab:
color_map[i * 3] |= (((lab >> 0) & 1) << (7 - j))
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j))
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j))
j += 1
lab >>= 3
color_map = color_map[3:]
if custom_color:
color_map[:len(custom_color)] = custom_color
return color_map
if __name__ == "__main__":
class_num=256
color_map=get_color_map_list(class_num)
# Create RKNN object
rknn = RKNN()
if not os.path.exists(RKNN_MODEL):
print("model not exist")
exit(-1)
# Load ONNX model
print("--> Loading model")
ret = rknn.load_rknn(RKNN_MODEL)
if ret != 0:
print("Load rknn model failed!")
exit(ret)
print("done")
# init runtime environment
print("--> Init runtime environment")
ret = rknn.init_runtime()
if ret != 0:
print("Init runtime environment failed")
exit(ret)
print("done")
image_size = (960, 720)
src_img = cv2.imread(IMG_PATH)
resize_img=cv2.resize(src_img,image_size)
color_img = cv2.cvtColor(resize_img, cv2.COLOR_BGR2RGB) # hwc rgb
print("--> Running model")
start = time.clock()
pred = rknn.inference(inputs=[color_img])
# 获取结束时间
end = time.clock()
# 计算运行时间
runTime = end - start
runTime_ms = runTime * 1000
# 输出运行时间
print("运行时间:", runTime_ms, "毫秒")
pred = np.squeeze(pred).astype('uint8')
print(pred)
added_image =visualize(resize_img, pred, color_map, None,weight=0.6)
cv2.imshow("added",added_image)
cv2.imwrite("add.jpg",added_image)
cv2.waitKey(0)
rknn.release()测试结果

c++ rk3399 pro测试
cmakelists.txt
cmake_minimum_required(VERSION 3.16)
project(untitled10)
set(CMAKE_CXX_FLAGS "-std=c++11")
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fopenmp ")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fopenmp")
include_directories(${CMAKE_SOURCE_DIR})
include_directories(${CMAKE_SOURCE_DIR}/include)
find_package(OpenCV REQUIRED)
#message(STATUS ${OpenCV_INCLUDE_DIRS})
#添加头文件
include_directories(${OpenCV_INCLUDE_DIRS})
#链接Opencv库
add_library(librknn_api SHARED IMPORTED)
set_target_properties(librknn_api PROPERTIES IMPORTED_LOCATION ${CMAKE_SOURCE_DIR}/lib64/librknn_api.so)
add_executable(untitled10 main.cpp)
target_link_libraries(untitled10 ${OpenCV_LIBS} librknn_api )main.cpp
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <queue>
#include "rknn_api.h"
#include "opencv2/core/core.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"
#include <chrono>
using namespace cv;
using namespace std;
void printRKNNTensor(rknn_tensor_attr *attr) {
printf("index=%d name=%s n_dims=%d dims=[%d %d %d %d] n_elems=%d size=%d "
"fmt=%d type=%d qnt_type=%d fl=%d zp=%d scale=%f\n",
attr->index, attr->name, attr->n_dims, attr->dims[3], attr->dims[2],
attr->dims[1], attr->dims[0], attr->n_elems, attr->size, 0, attr->type,
attr->qnt_type, attr->fl, attr->zp, attr->scale);
}
int post_process_u8(float *input0,cv::Mat resize_img,int w,int h){
std::vector<int> vec_host_scores;
for(int i=0;i<w*h;i++){
vec_host_scores.emplace_back(input0[i]);
}
int num_class = 256;//提取到外面 只执行一次即可,自己改吧
vector<int> color_map(num_class * 3);
for (int i = 0; i < num_class; i++) {
int j = 0;
int lab = i;
while (lab) {
color_map[i * 3] |= ((lab >> 0 & 1) << (7 - j));
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j));
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j));
j += 1;
lab >>= 3;
}
}
cv::Mat pseudo_img(w, h, CV_8UC3, cv::Scalar(0, 0, 0));
for (int r = 0; r < w; r++) {
for (int c = 0; c < h; c++) {
int idx = vec_host_scores[r*h + c];
pseudo_img.at<Vec3b>(r, c)[0] = color_map[idx * 3];
pseudo_img.at<Vec3b>(r, c)[1] = color_map[idx * 3 + 1];
pseudo_img.at<Vec3b>(r, c)[2] = color_map[idx * 3 + 2];
}
}
cv::Mat result;
cv::addWeighted(resize_img, 0.4, pseudo_img, 0.6, 0, result, 0);
//cv::imshow("pseudo_img", pseudo_img);
cv::imwrite(".pseudo_img.jpg", pseudo_img);
// cv::imshow("bgr", resize_img);
cv::imwrite("resize_img.jpg", resize_img);
//cv::imshow("result", result);
cv::imwrite("result.jpg", result);
//cv::waitKey(0);
return 0;
}
int main(int argc, char **argv) {
const char *img_path = "../0001TP_007980.png";
const char *model_path = "../pp_liteseg_stdc1_camvid_960x720_10k_model.rknn";
const char *post_process_type = "fp";//fp
const int target_width = 960;
const int target_height = 720;
// Load image
cv::Mat bgr = cv::imread(img_path);
if (!bgr.data) {
printf("cv::imread %s fail!\n", img_path);
return -1;
}
cv::Mat rgb;
//BGR->RGB
cv::cvtColor(bgr, rgb, cv::COLOR_BGR2RGB);
cv::Mat img_resize;
cv::resize(rgb,img_resize,cv::Size(target_width,target_height));
int width=bgr.cols;
int height=bgr.rows;
// Load model
FILE *fp = fopen(model_path, "rb");
if (fp == NULL) {
printf("fopen %s fail!\n", model_path);
return -1;
}
fseek(fp, 0, SEEK_END);
int model_len = ftell(fp);
void *model = malloc(model_len);
fseek(fp, 0, SEEK_SET);
if (model_len != fread(model, 1, model_len, fp)) {
printf("fread %s fail!\n", model_path);
free(model);
return -1;
}
rknn_context ctx = 0;
int ret = rknn_init(&ctx, model, model_len, 0);
if (ret < 0) {
printf("rknn_init fail! ret=%d\n", ret);
return -1;
}
/* Query sdk version */
rknn_sdk_version version;
ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &version,
sizeof(rknn_sdk_version));
if (ret < 0) {
printf("rknn_init error ret=%d\n", ret);
return -1;
}
printf("sdk version: %s driver version: %s\n", version.api_version,
version.drv_version);
/* Get input,output attr */
rknn_input_output_num io_num;
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
if (ret < 0) {
printf("rknn_init error ret=%d\n", ret);
return -1;
}
printf("model input num: %d, output num: %d\n", io_num.n_input,
io_num.n_output);
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++) {
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]),
sizeof(rknn_tensor_attr));
if (ret < 0) {
printf("rknn_init error ret=%d\n", ret);
return -1;
}
printRKNNTensor(&(input_attrs[i]));
}
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]),
sizeof(rknn_tensor_attr));
printRKNNTensor(&(output_attrs[i]));
}
int input_channel = 3;
int input_width = 0;
int input_height = 0;
if (input_attrs[0].fmt == RKNN_TENSOR_NCHW) {
printf("model is NCHW input fmt\n");
input_width = input_attrs[0].dims[0];
input_height = input_attrs[0].dims[1];
printf("input_width=%d input_height=%d\n", input_width, input_height);
} else {
printf("model is NHWC input fmt\n");
input_width = input_attrs[0].dims[1];
input_height = input_attrs[0].dims[2];
printf("input_width=%d input_height=%d\n", input_width, input_height);
}
printf("model input height=%d, width=%d, channel=%d\n", input_height, input_width,
input_channel);
/* Init input tensor */
rknn_input inputs[1];
memset(inputs, 0, sizeof(inputs));
inputs[0].index = 0;
inputs[0].buf = img_resize.data;
inputs[0].type = RKNN_TENSOR_UINT8;
inputs[0].size = input_width * input_height * input_channel;
inputs[0].fmt = RKNN_TENSOR_NHWC;
inputs[0].pass_through = 0;
/* Init output tensor */
rknn_output outputs[io_num.n_output];
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < io_num.n_output; i++) {
outputs[i].want_float = 1;
}
printf("img.cols: %d, img.rows: %d\n", img_resize.cols, img_resize.rows);
auto t1=std::chrono::steady_clock::now();
rknn_inputs_set(ctx, io_num.n_input, inputs);
ret = rknn_run(ctx, NULL);
if (ret < 0) {
printf("ctx error ret=%d\n", ret);
return -1;
}
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
if (ret < 0) {
printf("outputs error ret=%d\n", ret);
return -1;
}
/* Post process */
std::vector<float> out_scales;
std::vector<uint8_t> out_zps;
for (int i = 0; i < io_num.n_output; ++i) {
out_scales.push_back(output_attrs[i].scale);
out_zps.push_back(output_attrs[i].zp);
}
if (strcmp(post_process_type, "fp") == 0) {
post_process_u8((float *) outputs[0].buf,img_resize,
target_height, target_width);
}
//毫秒级
auto t2=std::chrono::steady_clock::now();
double dr_ms=std::chrono::duration<double,std::milli>(t2-t1).count();
printf("%lf ms\n",dr_ms);
ret = rknn_outputs_release(ctx, io_num.n_output, outputs);
if (ret < 0) {
printf("rknn_query fail! ret=%d\n", ret);
goto Error;
}
Error:
if (ctx > 0)
rknn_destroy(ctx);
if (model)
free(model);
if (fp)
fclose(fp);
return 0;
}测试结果
ubuntu@ubuntu:~$ ssh firefly@10.10.71.229
firefly@10.10.71.229's password:
_____ _ __ _
| ___(_)_ __ ___ / _| |_ _
| |_ | | '__/ _ \ |_| | | | |
| _| | | | | __/ _| | |_| |
|_| |_|_| \___|_| |_|\__, |
|___/
Welcome to Ubuntu 20.04.3 LTS (GNU/Linux 4.4.194 aarch64)
* Documentation: http://wiki.t-firefly.com
* Management: http://www.t-firefly.com
System information as of Wed Nov 23 02:49:58 UTC 2022
System load: 0.00 0.07 0.07 Up time: 11 min Local users: 2
Memory usage: 10 % of 3777MB IP: 10.10.71.229
Usage of /: 64% of 12G
Last login: Wed Nov 23 02:45:04 2022 from 10.10.113.206
firefly@firefly:~$ cd sxj731533730/build/
firefly@firefly:~/sxj731533730/build$ make
-- Configuring done
-- Generating done
-- Build files have been written to: /home/firefly/sxj731533730/build
[100%] Built target untitled10
firefly@firefly:~/sxj731533730/build$ ./untitled10
D RKNNAPI: ==============================================
D RKNNAPI: RKNN VERSION:
D RKNNAPI: API: 1.6.1 ( build: 2021-03-15 16:31:37)
D RKNNAPI: DRV: 1.7.1 ( build: 2021-12-10 09:43:11)
D RKNNAPI: ==============================================
sdk version: 1.6.1 (00c4d8b build: 2021-03-15 19:31:37) driver version: 1.7.1 ( build: 2021-12-10 09:43:11)
model input num: 1, output num: 1
index=0 name=x_195 n_dims=4 dims=[1 3 720 960] n_elems=2073600 size=2073600 fmt=0 type=3 qnt_type=2 fl=0 zp=127 scale=0.007843
index=0 name=ArgMax_p2o.ArgMax.0/out0_0 n_dims=3 dims=[0 1 720 960] n_elems=691200 size=1382400 fmt=0 type=4 qnt_type=0 fl=0 zp=0 scale=1.000000
model is NCHW input fmt
input_width=960 input_height=720
model input height=720, width=960, channel=3
img.cols: 960, img.rows: 720
D RKNNAPI: __can_use_fixed_point: use_fixed_point = 1.
468.068165 ms
测试结果

参考
50、ubuntu18.04&20.04+CUDA11.1+cudnn11.3+TensorRT7.2+Deepsteam5.1+vulkan环境搭建和YOLO5部署_sxj731533730的博客-CSDN博客
30、OAK摄像头使用官方的yolox进行初训练和测试_sxj731533730的博客-CSDN博客
OAKChina – Opencv AI Kit 人工智能套件-南京派驰电子
PaddleSeg/configs/pp_liteseg at release/2.6 · PaddlePaddle/PaddleSeg · GitHub
Ubuntu20.04环境下使用OpenVINO部署BiSeNetV2模型_英特尔边缘计算社区的博客-CSDN博客
![[附源码]java毕业设计药品销售管理系统](https://img-blog.csdnimg.cn/a41a0458678c4a2eb858470138c2c58a.png)