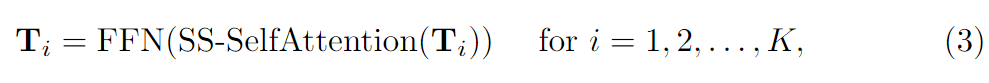1.背景&现状
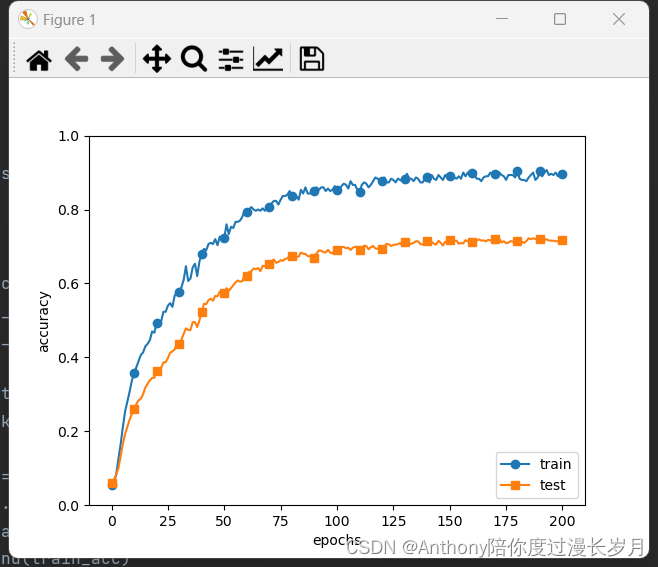
在大数据领域也已经工作了多年,无论所待过的大公司还是小公司,统计出来的数据经常需要查询展示,比如说:用做大屏或者报表或者给一些线上服务提供数据源,经常会要用代码写一套接口服务,需要进行开发-测试-上线等一套流程,开发效率非常低下,导致开发一个服务需要接近0.5天或者1天的时间。
不少大厂其实对于这个平台也有建设,甚至拿出来单独售卖((比如阿里datawork里面的数据服务、网易猛犸EasyDS)),但是收费确实不低,因此想着根据自己的工作经验,开发出这样一套产品,由于之前开源的数据对比平台命名为dataCompare,因此这个平台命名为dataService,即:数据服务
主要解决如下几个问题:
(1)开发一个api接口服务需要进行开发-测试-上线等一套流程,通常至少需要0.5天到1天
(2)为了满足不同的数据量要求,选择不同的数据存储,因此导致数据存储多样性(比如:Mysql、Oracle、Hbase、Doris等等),所以针对不同的存储开发代码不一致
(3)接口服务不规范,不同的开发人员,对于接口开发不一致
(4)数据和接口没办法复用,不同的业务选择相同的数据表,建立各自的接口服务,但是存在接口和数据冗余问题
(5)不清楚哪些数据被哪些应用访问,导致停掉数据加工任务并不清楚会影响哪些业务
2.目标
为了解决上述问题因此开发了开源大数据服务平台——dataService
(1)采用写sql低代码或者界面交互、勾选的方式即可api服务的开发、测试和上线,同时避免了针对不同的数据存储进行代码适配开发,开发效率至少提升50%
(2)接口规范化:通过数据服务平台实现接口规范化,避免不同的开发人员开发习惯不一致导致标准不一致
(3)构建api集市实现接口的可复用,避免数据和接口冗余问题
(4)通过数据血缘和接口血缘,打通数据加工和服务的全链路
3.系统核心功能介绍
目前dataService已经完成如下功能:
(1)通过简单配置或者写sql等低代码的方式即可实现api服务的开发和测试
(2)目前已经支持Mysql、Doris、Hive 等数据源
整体流程如下:
(1)流程一:新建数据源——新建API服务
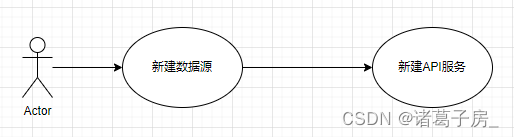
流程一
(2)流程二:根据数据源类型创建数据源连接

流程二
(3)流程三:新建API服务——配置sql——测试API服务——上线
SELECT
name,
addr as address,
sum(num) as total_num
FROM
table_name
WHERE
user_id = ${uid};
(1) SELECT查询的字段即为API返回参数
(2) 如果定义了字段别名,则返回参数名称为字段别名
(3) 支持SQL函数
(4) WHERE条件中的参数为API请求参数,参数格式为${参数名}
(4)流程四:发布API服务到API集市供业务方调用
4.系统架构设计

数据服务平台能够解决数据服务统一化,便于数据服务的治理、指标口径的统一。能够提升业务的开发效率,更快的面对业务的变化。数据服务平台主要分如下三层:
(1)数据应用接入层:主要是针对外部应用接入,包含:HTTP服务、RPC服务、Client 服务
(2)数据服务解析层:主要通过SQL方式访问各种数据存储,然后生成对应数据服务。核心功能:SQL解析、SQL校验、SQL路由、数据查询
(3)数据存储层:主要包含数据的存储管理,MySQL、Redis、Doris、Hive等等。都能很好的支持,提供API服务
5.系统功能演示
主页

添加数据源

数据源管理

新建api服务

api服务测试

6.后续规划
(1)上线api服务 pull方式的数据自动推送获取
(2)api服务限流和监控
(3)服务血缘探测、服务编排
7.核心代码开源
https://github.com/zhugezifang/dataService
https://gitee.com/ZhuGeZiFang/dataService