0. 简介
对于视觉SLAM而言,除了使用特征点法来完成VIO以外,还可以使用光流法来完成VIO的估计。而传统的光流法受环境,光照变化严重,所以有时候会出现光流偏差等问题。所以现在有越来越多的工作朝着深度学习的方向扩展,比如说这一篇文章《FlowFormer: A Transformer Architecture for Optical Flow》,目前已经被ECCV 2022收录。这里作者也在Github上开源了该项目的代码:https://github.com/drinkingcoder/FlowFormer-Official。FlowFormer的整个流程如下:首先由图像对构建4D cost volume成本编码,将成本编码到一个新的潜在空间中具有交替组转换器(AGT)层的成本内存中,并通过一个带有动态位置成本查询的循环Transform解码器对位置 cost queries进行解码。
ECCV2022 | FlowFormer: 一种基于transformer架构的光流!性能SOTA
1. 文章贡献
作为一种基于Transformer的神经网络架构,主要目的是通过深度学习直接输出光流的图像。文中指出贡献可以概括为四个方面:
-
我们提出了一种新的基于Transform的神经网络结构FlowFormer,用于光流量估计,它实现了最先进的流量估计性能。
-
设计了一种新颖的cost volume编码器,有效地将成本信息聚合为紧凑的潜在cost tokens。
-
我们提出了一种循环成本解码器,该解码器通过动态位置成本查询循环解码成本特征,迭代细化估计光流。
-
据我们所知,我们第一次验证imagenet预先训练的传输
2. 详细内容
下面我们将对原文的第三部分进行解析,并分析这篇文章的重点部分。首先我们需要明白光流的估计任务需要输出每像素位移场
f
:
R
2
→
R
2
\mathbf{f}:\mathbb{R}^2 \rightarrow \mathbb{R}^2
f:R2→R2。这样的目的是为了充分将源图像
x
∈
R
2
x \in \mathbb{R}^2
x∈R2的二维空间中的位置
I
s
\mathbf{I}_s
Is,映射到目标图像的
I
t
\mathbf{I}_t
It位置。具体的转换关系如下
p
=
x
+
f
(
x
)
\mathbf{p}=x+\mathbf{f}(x)
p=x+f(x)。同时为了充分使用现有的视觉Transformer的方法以及之前基于CNN架构的光流估计方法中广泛使用的4D成本量(cost volume)。所以作者团队使用Transformer来对4D成本量进行编码和解码以实现精确的光流估计。下图就是整个FlowFormer的总体架构。它通过两个主要部分处理来自siamese特征的4D成本量。1)成本体积(cost volume)编码器,将4D成本量编码到一个潜在的空间,形成成本记忆(cost memory);2)成本记忆解码器,根据编码的成本记忆和上下文特征预测每像素的位移场。
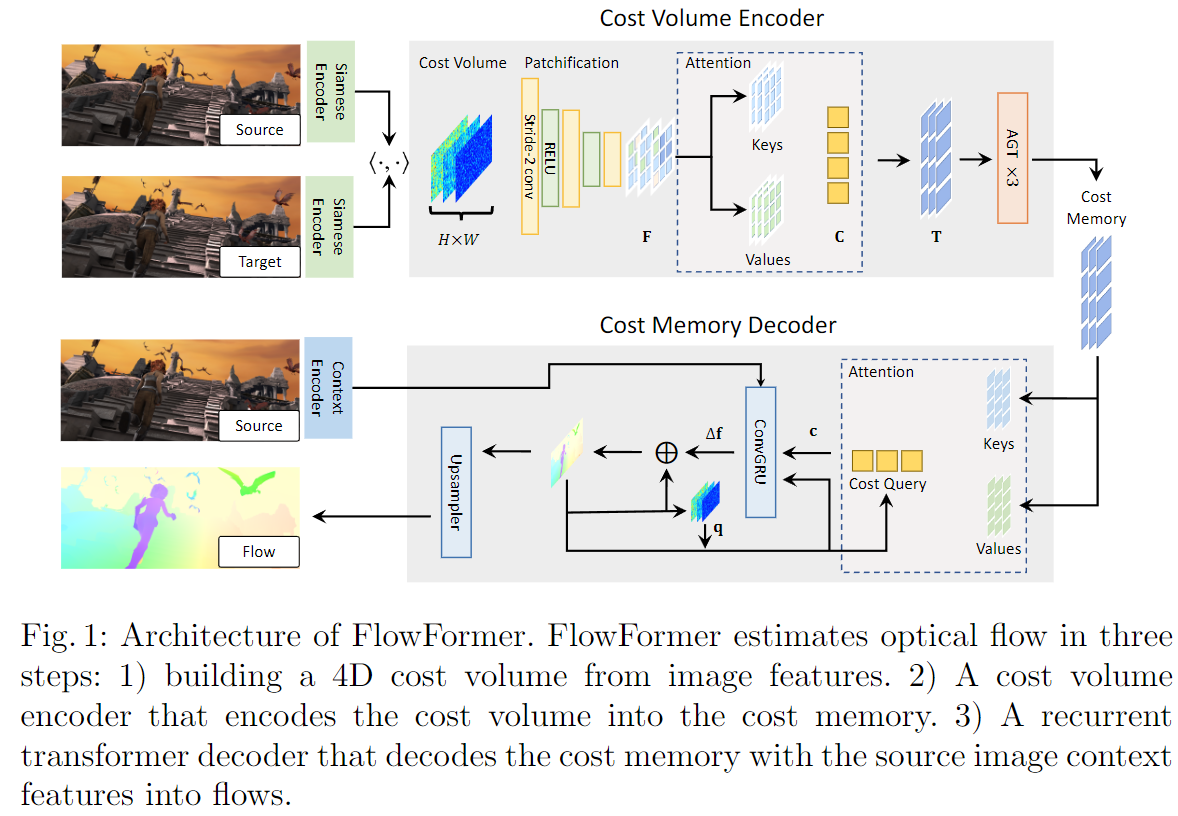
我们下面来详细的看一看这三个部分
2.1 构建4D成本量
骨干网用于从输入 H I × W I × 3 H_I × W_I × 3 HI×WI×3的RGB图像中提取出 H × W × D f H ×W ×D_f H×W×Df特征图,通常我们设置 ( H , W ) = ( H I / 8 , W I / 8 ) (H, W) = (H_I /8, W_I /8) (H,W)=(HI/8,WI/8)。在提取出源图像和目标图像的特征图后,通过计算源图像和目标图像之间所有像素对的点积相似度,构造 H × W × H × W H × W × H × W H×W×H×W的4D成本量。
2.2 4D成本量解码
为了估计光流,文中需要根据4D成本量中编码的源视觉和目标视觉相似性来识别源像素在目标图像中的相应位置。构建的4D成本量可以看作是一系列大小为 H × W H×W H×W的2D成本图,每个成本图测量单个源像素和所有目标像素之间的视觉相似性。我们将源像素x的成本图表示为 M x ∈ R H × W \mathbf{M}_x∈\mathbb{R}^{H×W} Mx∈RH×W。在此类成本图中找到相应位置通常是一项挑战,因为在两幅图像中可能存在重复模式和非区分区域。当仅考虑地图局部窗口的成本时,这项任务变得更具挑战性,就像以前基于CNN的光流估计方法所做的那样。即使在估计单个源像素的精确位移时,考虑其上下文源像素的成本图也是有益的。
为了解决这一难题,我们提出了一种基于Transformer的成本体积编码器,该编码器将整个成本体积编码到成本内存中。我们的成本卷编码器包括三个步骤:1)成本映射补丁化,2)成本补丁嵌入,3)成本内存编码。我们详细阐述这三个步骤如下。
-
成本映射补丁化:根据现有的视觉变换器,我们修补了成本图 M x ∈ R H × W \mathbf{M}_x∈\mathbb{R}^{H×W} Mx∈RH×W对于每个源像素 x x x的跨步卷积,从而获得成本补丁嵌入序列。具体来说,给定一个 H × W H×W H×W成本图,我们首先在其右侧和底部填充零,使其宽度和高度乘数为8。然后,填充的成本图通过三个步长为2卷积的堆栈和ReLU转换为特征映射 F x ∈ R [ H / 8 ] × [ W / 8 ] × D p \mathbf{F}_x∈\mathbb{R}^{[H/8]×[W/8]×D_p} Fx∈R[H/8]×[W/8]×Dp。特征图中的每个特征代表输入成本图中的一个 8 × 8 8×8 8×8的补丁。三种卷积的输出通道均为 D p / 4 , D p / 2 D_p / 4, D_p / 2 Dp/4,Dp/2 以及 D p D_p Dp。
-
基于潜在汇总(latent summarizations)的补丁特征标记:尽管拼接会为每个源像素生成一系列代价高昂的补丁特征向量,但此类补丁特征的数量仍然很大,阻碍了不同源像素之间的信息传播效率。实际上,成本图是高度冗余的,因为只有少数高代价成本才是最有用的。为了获得更紧凑的成本特征,我们通过 K K K个潜在编码(latent codewords query) C ∈ R K × D \mathbf{C}∈\mathbb{R}^{K×D} C∈RK×D,来进一步总结了每个源像素 x x x的补丁特征 F x \mathbf{F}_x Fx。具体来说,通过潜在编码来查询每个源像素的代价补丁特征,并通过点积注意机制将每个代价映射,进一步总结为一个 D D D维度的 K K K个潜在向量。潜在编码 C ∈ R K × D \mathbf{C}∈\mathbb{R}^{K×D} C∈RK×D是随机初始化的,并通过反向传播进行更新,且在所有源像素之间共享。归纳 F x F_x Fx的潜在表征 T x T_x Tx(4D cost volume)得到为:
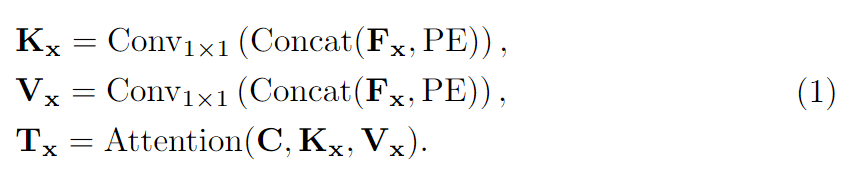
在投影成本-补丁特征 F x F_x Fx以获取密钥 K x K_x Kx和值 V x V_x Vx之前,将补丁特征与位置嵌入序列 P E ∈ R [ H / 8 ] × [ W / 8 ] × D p \mathbf{PE}∈\mathbb{R}^{[H/8]×[W/8]×D_p} PE∈R[H/8]×[W/8]×Dp进行拼接。给定一个2D位置 p \mathbf{p} p,我们将其编码为一个长度为 D p D_p Dp的位置嵌入,并使用COTR方法。最后,通过对查询、键和值进行多头点积注意,可以将源像素 x x x的代价图汇总为 K K K个潜在表示 T x ∈ R K × D \mathbf{T}_x∈\mathbb{R}^{K×D} Tx∈RK×D。一般来说 K × D ≪ H × W K×D≪ H×W K×D≪H×W的大小,并且潜在汇总 T x T_x Tx为每个源像素 x x x提供了比每个 H × W H×W H×W成本图更紧凑的表示。对于图像中的所有源像素,总共有 ( H × W ) 2 D (H×W)2D (H×W)2D成本图。因此,它们的汇总表示可以转换为潜在的4D成本量 T ∈ R H × W × K × D \mathbf{T}∈\mathbb{R}^{H×W×K×D} T∈RH×W×K×D -
关注潜在cost空间:上述两个阶段将原始的4D成本体积转化为潜在的、紧凑的4D成本体积t。但是,直接对4D体积中的所有向量应用自注意仍然过于昂贵,因为计算成本随tokens数量的增加呈二次增长。如图2所示,我们提出了一种交替分组转换层(AGT),该层以两种相互正交的方式对标记进行分组,并在两组中交替应用注意,减少了注意成本,同时仍然能够在所有标记之间传播信息。
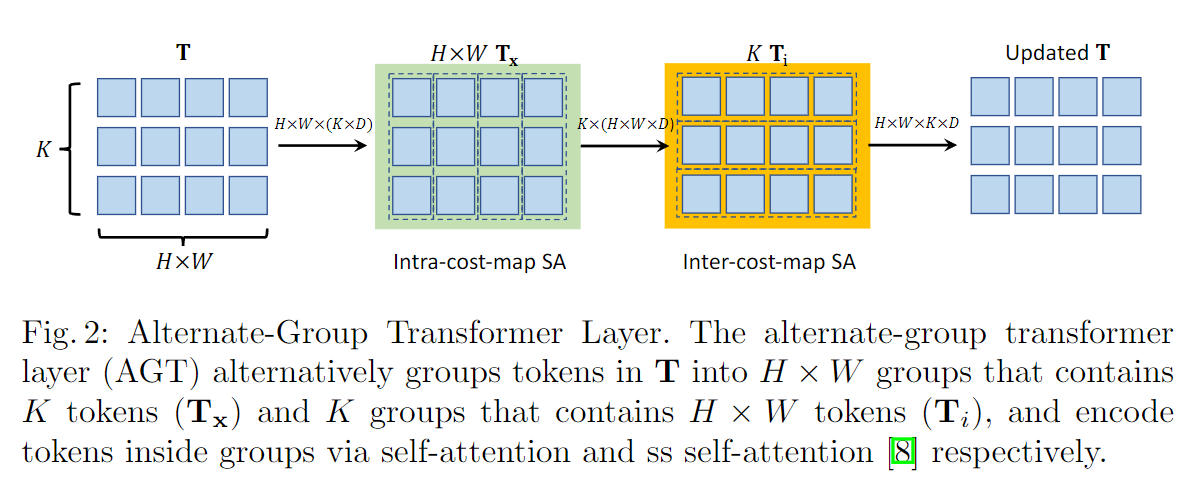
对每个源像素进行第一次分组,即每个 T x ∈ R K × D \mathbf{T}_x∈\mathbb{R}^{K×D} Tx∈RK×D组成一个组,在每个组内进行自我注意力机制
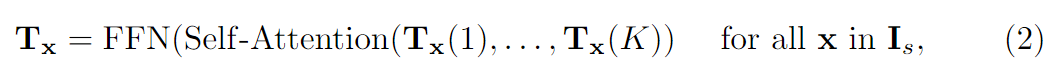
其中, T x ( i ) T_x(i) Tx(i)表示编码源像素 x x x的成本图的第 i i i个潜在表示。在对每个源像素 x x x的所有 K K K个潜在标记进行自我注意力机制后,更新 T x T_x Tx并通过前馈网络(FFN)进一步变换,然后重新组织,形成更新的4D成本量 T T T。自我注意力机制和FFN子层都采用Transformer残差连接和层归一化的共同设计。这种自我注意力机制可以在每个成本图中传播信息,我们将其命名为内部代价图的自我注意力。第二种方法将所有潜在成本标记 T ∈ R H × W × K × D \mathbf{T}∈\mathbb{R}^{H×W×K×D} T∈RH×W×K×D根据 K K K个不同潜在表征分为 K K K组。因此,每组都有 D D D维的 ( H × W ) (H×W) (H×W)标记,用于通过Twins文章中提出的空间可分离的自我注意(SS-SelfAttention)在空间域中传播信息。
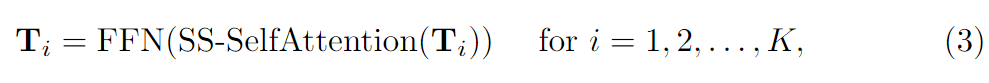
上述自我注意操作的参数在不同组之间共享,并按顺序进行操作,形成提出的交替组注意层。通过多次叠加交替组Transformer层,潜在成本令牌可以有效地跨源像素和跨潜在表示交换信息,以更好地编码4D成本体积。通过这种方式,我们的成本体积编码器将 H × W × H × W H × W × H × W H×W×H×W 4D成本体积转换为 H × W × K H × W × K H×W×K且长度为 D D D的潜在标记。我们将最终的 H × W × K H × W × K H×W×K标记称为成本存储器,用于光流的解码模块。