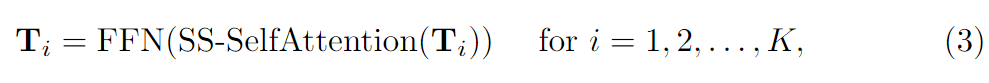读取大文件
python读取文件一般情况是利用open()函数以及read()函数来完成:
f = open(filename,'r')
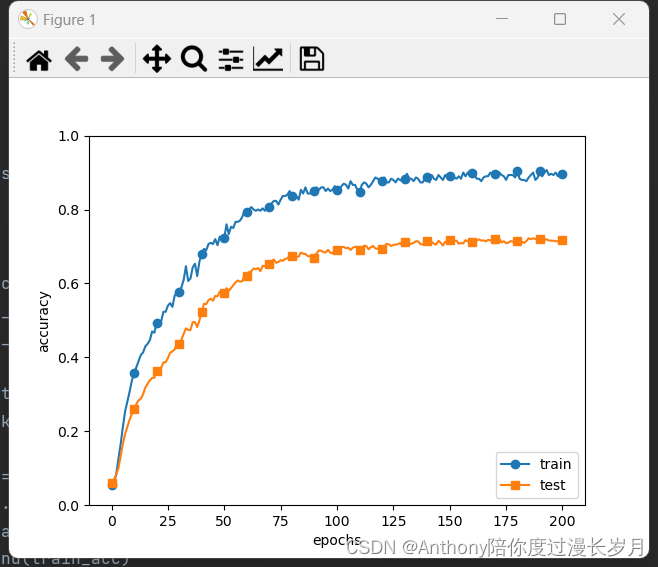
f.read()这种方法读取小文件,即读取大小远远小于内存的文件显然没有什么问题。但是如果是将一个10G大小的日志文件读取,即文件大小大于内存,这么处理就有问题了,会造成MemoryError … 也就是发生内存溢出。
这里发现跟read()类似的还有其他的方法:read(参数)、readline(参数)、readlines(参数)
read(参数):
read() 方法用于从文件读取指定的字符数(文本模式 t)或字节数(二进制模式 b),如果未给定参数 size 或 size 为负数则读取文件所有内容
while True:
block = f.read(1024)
if not block:
breakreadline(参数):
readline() 方法用于从文件读取整行,包括 "\n" 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 "\n" 字符。
while True:
line = f.readline()
if not line:
breakreadlines(参数):
readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表,该列表可以由 Python 的 for... in ... 结构进行处理。 如果碰到结束符 EOF 则返回空字符串。
读取全部的行,构成一个list,通过list来对文件进行处理,但是这种方式依然会造成MemoyError
for line in f.readlines():
....分块读取:
处理大文件是很容易想到的就是将大文件分割成若干小文件处理,处理完每个小文件后释放该部分内存。这里用了iter 和 yield:
def read_in_chunks(filePath, chunk_size=1024*1024):
"""
Lazy function (generator) to read a file piece by piece.
Default chunk size: 1M
You can set your own chunk size
"""
file_object = open(filePath)
while True:
chunk_data = file_object.read(chunk_size)
if not chunk_data:
break
yield chunk_data
if __name__ == "__main__":
filePath = './path/filename'
for chunk in read_in_chunks(filePath):
process(chunk) # <do something with chunk>使用With open():
with语句打开和关闭文件,包括抛出一个内部块异常。for line in f文件对象f视为一个迭代器,会自动的采用缓冲IO和内存管理,所以你不必担心大文件
# If the file is line based
with open(...) as f:
for line in f:
process(line) # <do something with line>关于with open()的优化:
面对百万行的大型数据使用with open 是没有问题的,但是这里面参数的不同也会导致不同的效率。经过测试发先参数为”rb”时的效率是”r”的6倍。由此可知二进制读取依然是最快的模式。
with open(filename,"rb") as f:
for fLine in f:
pass 测试结果:rb方式最快,100w行全遍历2.9秒。基本能满足中大型文件处理效率需求。如果从rb(二级制读取)读取改为r(读取模式),慢5-6倍。
内存检测工具介绍
memory_profiler
首先先用pip安装memory-profiler
pip install memory-profilermemory-profiler是利用python的装饰器工作的,所以我们需要在进行测试的函数上添加装饰器。
from hashlib import sha1
import sys
@profile
def my_func():
sha1Obj = sha1()
with open(sys.argv[1], 'rb') as f:
while True:
buf = f.read(1024 * 1024)
if buf:
sha1Obj.update(buf)
else:
break
print(sha1Obj.hexdigest())
if __name__ == '__main__':
my_func()之后在运行代码时加上-m memory_profiler
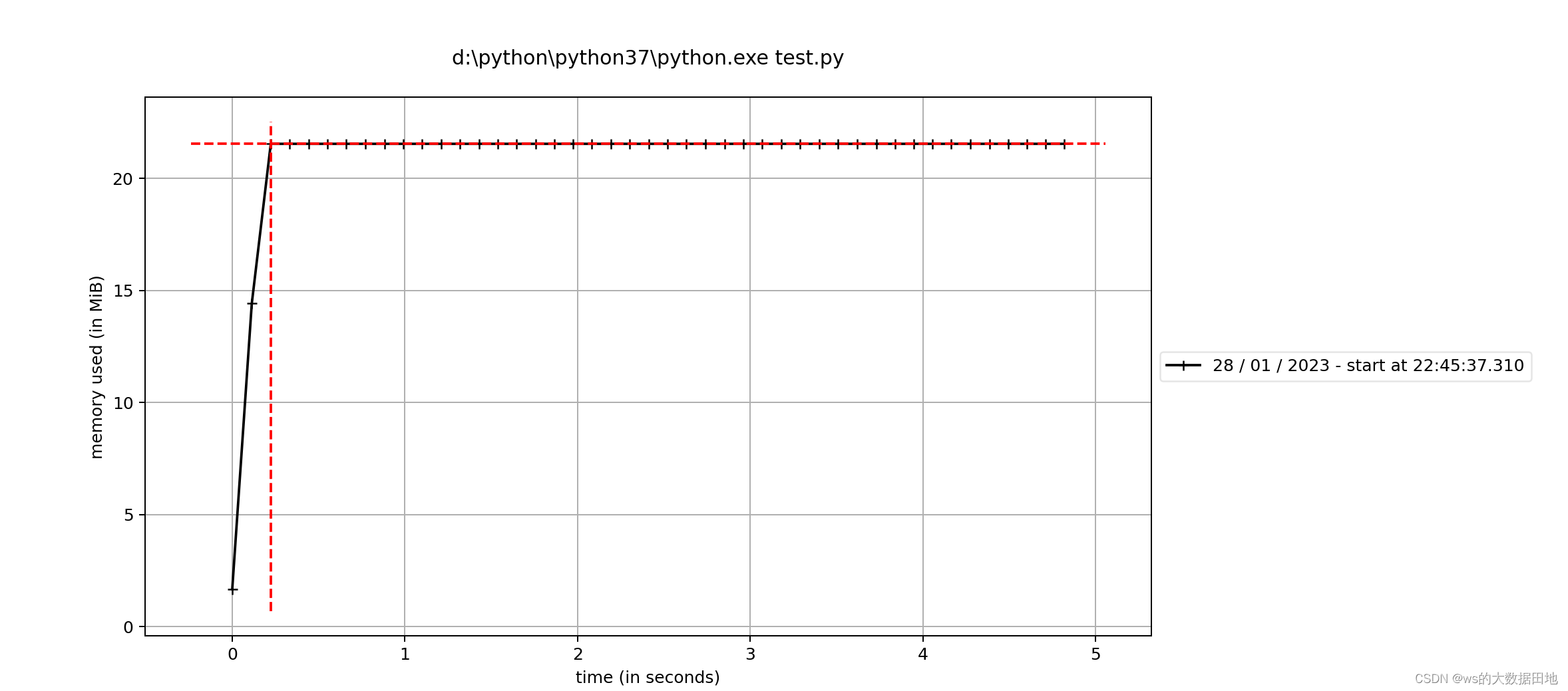
就可以了解函数每一步代码的内存占用了。例如下图:
guppy
首先,通过pip先安装guppy3
pip install guppy3之后可以在代码之中利用guppy直接打印出对应各种python类型(list、tuple、dict等)分别创建了多少对象,占用了多少内存。
from guppy import hpy
import sys
def my_func():
mem = hpy()
with open(sys.argv[1], 'rb') as f:
while True:
buf = f.read(10 * 1024 * 1024)
if buf:
print(mem.heap())
else:
break
通过上述两种工具guppy与memory-profiler可以很好地来监控python代码运行时的内存占用问题。
也可以使用mem_top或者pyrasite。有兴趣的可以看一下