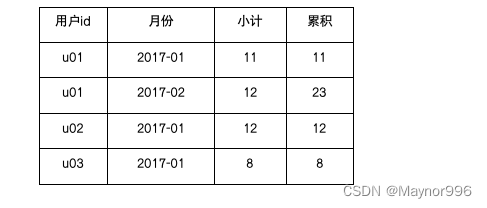
BN层
批归一化层(Batch Normallization)是一种在卷积神经网络模型中大量使用,为了加速模型收敛的技术。为什么CNN 中引入 BN 层可以加速网络的收敛呢?因为将输入的样本数据或特征图,归一化后,改善了输入数据的分布,或者说减少了内部相关变量分布的偏移,模型在统一的分布中更能获取数据的特征。所以这里的归一化,其实是标准化(Standardization),即
x
n
e
w
=
x
−
μ
σ
x_{new} = \frac{x - \mu}{\sigma}
xnew=σx−μ
一张图可以解释,改善输入数据的分布,可以更容易找到模型参数w和b,从而加速模型收敛

此外,BN 还充当正则器的作用,减少了 dropout 的需要。原文摘要如下
Batch Normalization allows us to use much higher learning rates and be less careful about initialization. It also acts as a regularizer, in some cases eliminating the need for Dropout.
算子融合
在训练时,卷积层和 BN 是两个模块,但是为什么训练时不能融合,而训练完成后,仅执行前向推理却可以融合?因为训练时是按批次输入数据的,BN 就是为了解决小批次输入数据的分布偏移而提出的,因此训练时需要BN层。而训练后的推理,是单样本输入,训练时 BN 的参数已经确定,这些参数相当于对前一层的特征图数据做一次线性变换,而卷积层也可以转化为对特征图的线性变换。因此这两个相邻的算子可以融合。
模型训练时通过移动平均的方法近似获得整个样本集的均值和方差
μ
=
μ
n
=
α
μ
n
−
1
+
(
1
−
α
)
⋅
1
N
∑
i
n
x
i
,
n
\mu = \mu_n = \alpha\mu_{n-1} + (1-\alpha)\cdot\frac{1}{N}\sum_{i}^nx_{i,n}
μ=μn=αμn−1+(1−α)⋅N1i∑nxi,n
对于特征图 Fc,i,j 中第 c 个通道的 ( i , j ) 的值,写程向量和矩阵形式为
(
F
~
1
,
i
,
j
F
~
2
,
i
,
j
⋮
F
~
C
,
i
,
j
)
=
(
1
σ
1
2
+
ε
0
0
0
0
1
σ
2
2
+
ε
0
0
0
⋱
0
0
0
0
0
1
σ
n
2
+
ε
)
(
F
1
,
i
,
j
F
2
,
i
,
j
⋮
F
C
,
i
,
j
)
+
(
−
μ
1
σ
1
2
+
ε
−
μ
2
σ
2
2
+
ε
⋮
−
μ
n
σ
n
2
+
ε
)
\left(\begin{array}{l} \tilde{F}_{1, i, j} \\ \tilde{F}_{2, i, j} \\ \vdots \\ \tilde{F}_{C, i, j} \end{array}\right)=\left(\begin{array}{cccc} \frac{1}{\sqrt{\sigma_{1}^{2}+\varepsilon}} & 0 & 0 & 0 \\ 0 & \frac{1}{\sqrt{\sigma_{2}^{2}+\varepsilon}} & 0 & 0 \\ 0 & \ddots & 0 & 0\\ 0 & 0 & 0 & \frac{1}{\sqrt{\sigma_{n}^{2}+\varepsilon}} \end{array}\right)\left(\begin{array}{l} F_{1, i, j} \\ F_{2, i, j} \\ \vdots \\ F_{C, i, j} \end{array}\right)+\left(\begin{array}{c} -\frac{\mu_{1}}{\sqrt{\sigma_{1}^{2}+\varepsilon}} \\ -\frac{\mu_{2}}{\sqrt{\sigma_{2}^{2}+\varepsilon}} \\ \vdots \\ -\frac{\mu_{n}}{\sqrt{\sigma_{n}^{2}+\varepsilon}} \end{array}\right)
F~1,i,jF~2,i,j⋮F~C,i,j
=
σ12+ε10000σ22+ε1⋱00000000σn2+ε1
F1,i,jF2,i,j⋮FC,i,j
+
−σ12+εμ1−σ22+εμ2⋮−σn2+εμn
即 F = W * x + b,因此可将两者合并
F
~
i
,
j
=
W
b
n
(
W
c
o
n
v
F
i
,
j
+
b
c
o
n
v
)
+
b
b
n
\tilde{F}_{i, j} = W_{bn}(W_{conv}F_{i,j} + b_{conv}) + b_{bn}
F~i,j=Wbn(WconvFi,j+bconv)+bbn
从而新的卷积层的 W 为 Wbn* Wconv ,新的 b 为 Wbn * Wconv + Wbn
具体实现可参考PyTorch的相关源码。
参考文档
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
ML 入门:归一化、标准化和正则化
BN与Conv层的合并
模型推理加速技巧:融合BN和Conv层