ZFNet
CNN卷积网络的发展史
1. LetNet5(1998)
2. AlexNet(2012)
3. ZFNet(2013)
4. VGGNet(2014)
5. GoogLeNet(2014)
6. ResNet(2015)
7. DenseNet(2017)
8. EfficientNet(2019)
9. Vision Transformers(2020)
10. 自适应卷积网络(2021)
上面列出了发展到现在CNN的一些经典的网络模型,我将持续不断更新学习上述神经网络的笔记。共勉!
ZFnet是2013年ImageNet挑战赛冠军的模型,该模型由微软研究院的Alex Krizhevsky和Ilya Sutskever设计。
原论文地址Visualizing and Understanding Convolutional Networks
Abstract(概念)
大型卷积网络模型最近展示了令人印象深刻的经典在ImageNet实验台上的操作性能(Krizhevsky et al., 2012)。然而卷积神经网路在当时就像一个黑箱子,我们并不知道它为什么能够工作以及它为什么能表现的那么好。在本文中,我们解决了这两个问题:
- 我们介绍了一种新颖的可视化技术这让我们能够可视化模型的中间特征层以及分类器的操作。这种可视化技术可以用来解释为什么Krizhevsky等人在ImageNet上分类的模型为什么效果那么好。
- 我们还会通过对比来探究模型敏感度,相关性。我们展示我们的ImageNet模型很好地推广到其他数据集:当对Softmax分类器进行了再训练,结果令人信服比目前最先进的结果要好Caltech-101和Caltech-256数据集。
本篇文章有点长,但是会对我们理解卷积神经网络有很大的帮助。并且为我们改进网络提供了很好的思路。 相关视频推荐ZFNet深度学习图像分类算法(反卷积可视化可解释性分析)
1. Introduction(介绍)
这部分介绍了以下3个因素会减小模型损失:
- 大规模结构化数据
- 更强的GPU,TPU等
- 更好的模型正则化策略,dropout(每个batch随机掐死一部分神经元,阻止它的前向和反向传播,这样可以放置过拟合。破除了神经网路中的联合适应性,模型集成,数据增强的效果)
尽管当时的模型已经这么强了,但是我们对它的内部操作以及内部行为都一无所知,我们也不知道从什么角度提示它的性能,这对于一个科学家来讲是远远不够的。 如果我们对它的内部没有清晰的了解,对它的操作没有认识,我们对它的所有改进都变成了试错碰运气。 那么我们怎么才能创造出一个好的网络模型呢?
这篇论文中我们介绍了一种可视化技术,它能够揭示每一个神经网路中的feature map(特征图)对哪些特征感兴趣。并且展示了在训练中不同层的特征演化过程把它作为一个诊断模型潜在问题的方法。使用的可视化方法叫做deconvnet(反卷积)。并且进行了局部遮挡敏感性分析,局部遮挡相关性分析用于探究分类器是对图像中哪部分是重点关注的。
ZFNet是通过对ALexNet进行改进而得到的,并且我们发现在IamgeNet上进行训练的模型能够泛化迁移到其他数据集上只需重新训练最后的softmax分类器就可以。
1.1 Related Work(相关工作)
可视化卷积神经网路可以让我们对网路的性能有直观的认识,但是当时大多数只停留在第一层,因为第一层卷积核比较好可视化,低层的feature map可解释性强,高层的feature map可解释性弱完全看不出来是什么,为此Erhan等人在2009提出了梯度上升用于可视化,但是此方法需要谨慎的初始化,并且对每一层的不变性没有任何帮助。(不变性:网络能从不同的图中提取到相同的特征和信息)。为此Le等人延申了(Berkes&Wiskott)的思想提出用海森矩阵数值解来获取最优的响应,就可以来研究神经网路的不变性了。但是对于神经网路高层很难用一个二阶近似值表明的。Donahue等人在2013年提出了一个方法,它是从原图中找到一些小图可以使其在高层神经网路中有一个强的激活但是我们的方法(deconvnet)是不一样的,我们的方法提供了一个无参数并且能够探究网络不变性的方法,能够表明每一个中间层的feature map对哪种特征模式感兴趣,是从高层向底层投影揭示特定的feature map关注的是哪些信息,哪些模式。
2. Approach(方法)
该方法是在AlexNet上进行修改得到的。在下面我们会具体介绍那些地方改动了。

神经网路前向传播:输入图像-卷积-Relu激活-池化-归一化-全连接-Softmax。
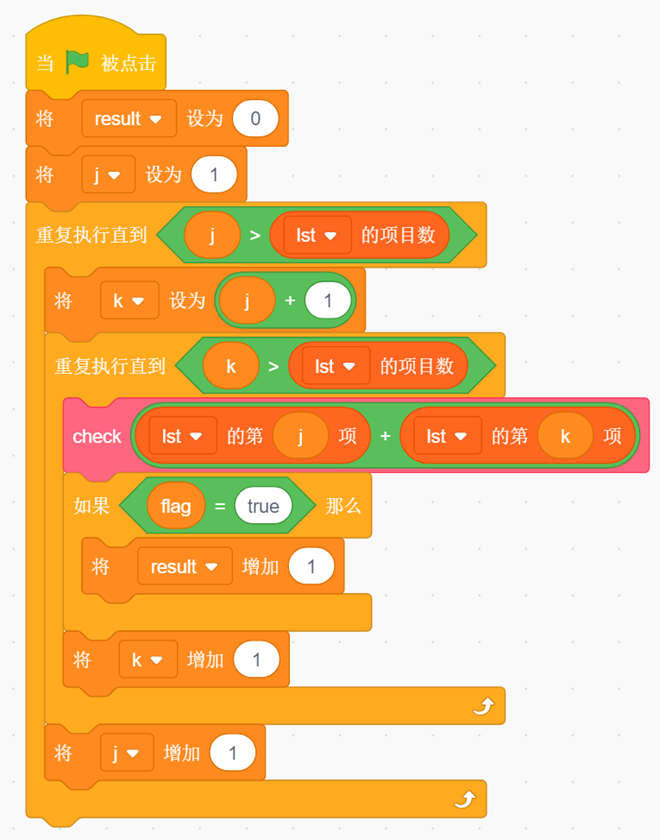
deconvnet: 反池化-Relu激活-反卷积。
下面我们将介绍这三个概念:
2.1 Unpooling(反池化)
我们都知道最大池化进行的是下采样操作,将大图变为小图但是这样子做不可避免的会丢失相关区域的信息。这里我们引入switch操作用于记住最大值的位置,在我们进行反池化的时候只需将值回溯到原位置就能完成反池化操作,这样子我们就能保留主要的特征,如下图所示。
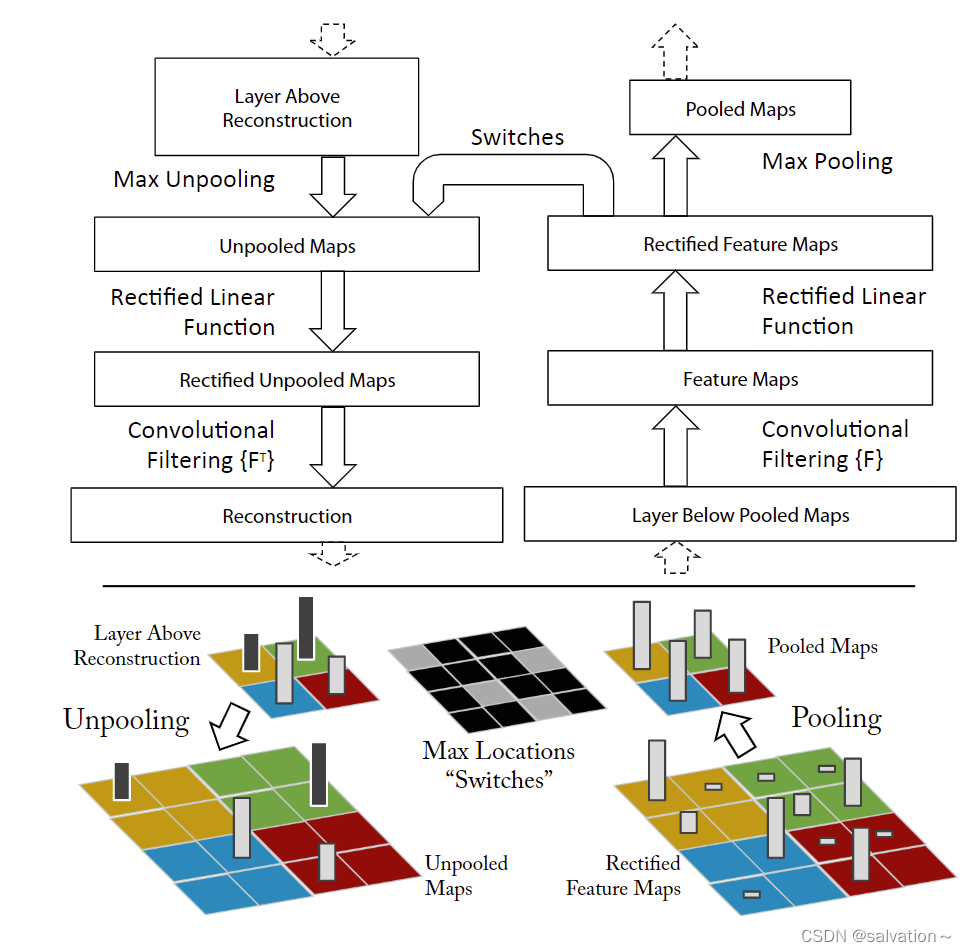
反池化将小图转为大图,从图中我们可以看到很多信息已经丢失了,但是它任然能够保留提取特征的主要矛盾。
2.2 反激活
使用Relu
目的:保证所有中间的激活为正数。
2.3 反卷积
使用原始正向卷积核的转置
注意:虽然池化时会丢失一部分信息,但重构得到的图和原图还是有一定相似性的。 亮暗轮廓体现出特定feature map反映的特征。
3. Training Deatils
这里我们就不介绍了,这部分论文中就是介绍了训练的细节。
4. Convnet Visualization(可视化)

如上图所示,左上图是第一层卷积核的feature map下方的这些是能使上面9个卷积核激活最大的数据集中原图中9张小图。第一层并不需要deconvnet,只需要将feature map和卷积核可视化出来就行。上图左边的第一个是一个右向下的斜杠,刚好在下图中第一个也是。左上图中第3行第2列的提取的是绿色的特征,刚好原图中也是绿色能够使其激活最大。根据可视化结果我们可以发现第一层网络提取的是边缘,颜色等特征。

接下来的就可以使用deconvnet进行可视化了。如上图所示左图是第二层的feature map通过deconvnet重构回原始像素空间再经过可视化得到的图像。右图是原图中能使卷积核激活最大的9张小图。通过结果我们可以发现第二层提取到了图片的形状。例如右下角卷积核提到的是直角特征,也有黄色特征(4行3列)出现了更高级的特征。接下里我们看一下第三层卷积核提取的特征。
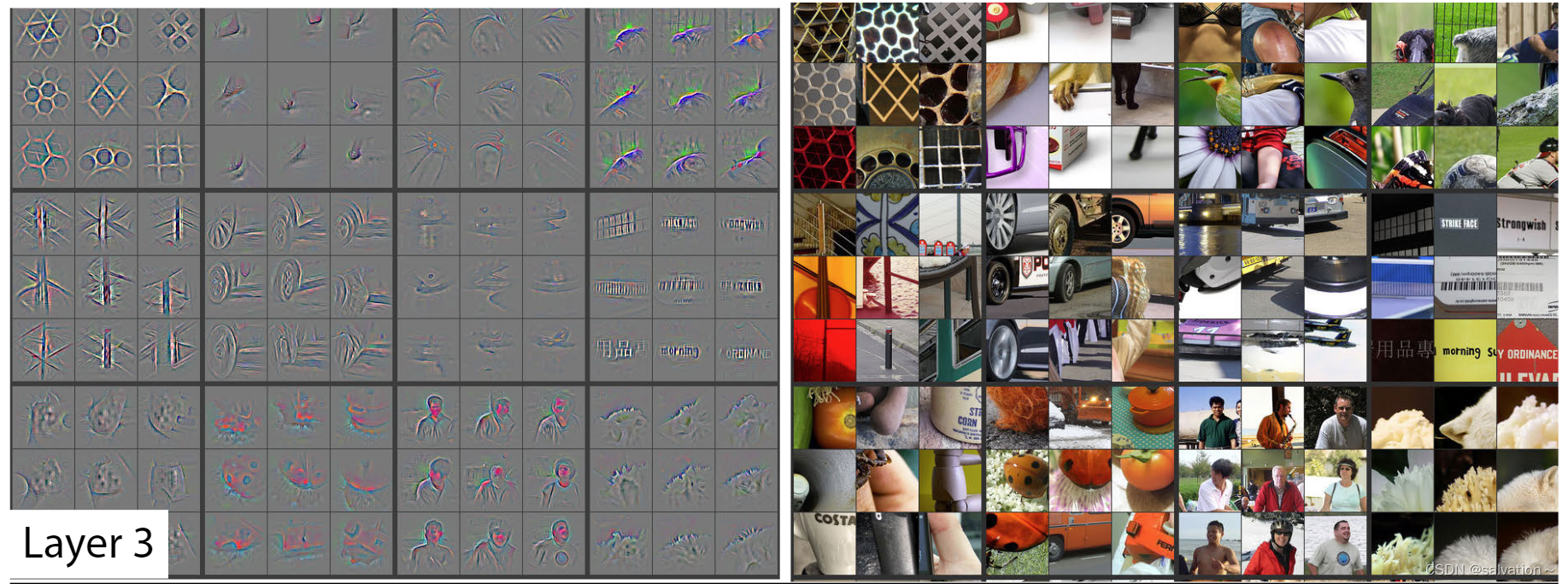
通过左边灰色图是第三层卷积核的feature map通过deconvnet后可视化的图像,右图是原图中能使该层卷积核激活最大的图像。通过结果我们发现提取的特征已经有人脸,毛绒,轮胎,语言等语义特征了。并且原图不再是长得一样的图片,而是不同的(例如人脸3行3列,是原图中9张不同的人脸),这说明高层网络提取到的特征具有不变性!

通过结果我们可以发现第4层,第5层卷积核提取到的特征是狗脸,鸟脚,鸟眼睛,自行车轮胎,绿色背景(第5层中第1行2列)等特征。
总结: 从上述结果我们可以发现:
- 低层网络提取到边框,颜色等空间特征(spatial)而高层网络则提取到人脸,眼睛,绿色背景等语义(semantic)特征
- 越高层的网络提取到的特征越具有不变性(不同图像中提取到相同部分)

低层网络收敛越快,高层网络收敛越慢。每一行表示一个feature map,每一列表示训练过程中不同的轮次。从原图中找到能使第2层卷积核激活最大的一张图,将它喂入网络中得到feature map再经过deconvnet重构回原始像素空间再经过可视化就得到这个灰图。 如果图片中出现突变(例如Layer3中的脸从4行5列到4行6脸,脸不一样了),原始的图像发生了改变。Layer2中我们发现很早的轮次就出现了特征(收敛),高层中只有到后面的几个轮次才出现特征(收敛)。
接下来我们探究原图进行平移,旋转,缩放等操作对网络的底层和高层造成的影响,小的改变对底层网络有巨大的影响,对高层影响较小是准线性的。最后的结果对平移,缩放并不敏感,但是当旋转到一定角度时,网络会很敏感。

从上图中我们可以发现,第一层只要平移,缩放,旋转一点点就会有很大的改变而第7层平移,缩放变化不大,但是场景这一特征在旋转到一定角度时会规律性出现峰值。由此我们可以得出结论:卷积神经网路具有良好的平移和缩放不变性并不具有良好的旋转不变性
4.1 Architecture Selection(模型改进)
通过可视化我们可以对AlexNet网络进行改进,通过可视化第一层和第二层我们发现第一层中有一些卷积核是特别高或特别低的高频或低频信息,这些卷积核称为无效卷积核。第二层因为步长特别大,会出现一些混淆的人工特征(网格)这些也是无效的。为了纠正这些我们将1111改为了77并且将步长由4改为了2.新体系保持了良好的特性,卷积核都变的有效同样feature map也是有效的。并且分类的性能也优于AlexNet。

从上图中我们可以发现对训练中第一层卷积核进行可视化,卷积核过大会出现高亮信息,并且存在很多失效的filter和混乱网络。但是通过
(1) 减小卷积核,可以使失效的卷积核减少,
(2) 减小步长:可以减掉混乱网络。
4.2 Occlusion Sensitivity(局部遮挡敏感性分析)
在图像分类中我们会有一个问题,模型到底是对图像的局部区域呢还是对图像整体进行识别呢?下面的图就展示了这个问题,我们用一个灰色挡板对图像不同补位进行遮挡,观察中间层和结果。我们发现网络是对图像某些关键区域感兴趣,遮挡住这些部位正确结果就会显著的降低。

(b)图:灰色滑块在不同位置遮挡,把每一个位置的第5层的激活最大的feature map值叠加求和在一起。这个feature map提取的是毛茸茸这个特征,如果我们把毛茸茸相关区域特征遮挡,结果就会降低。第二个feature map提取的是文字,如果我们将文字信息遮挡,结果也会降低。
©图:黑框中是原图输入网络Layer5激活最大的feature map经过反卷积后可视化的图像。其他3张是数据集中能使该卷积核激活最大的图对应的feature map反卷积后的图像。
(d)图:遮挡不同部位网络识别出正确类别的概率。
(e)图:遮挡不同部位网络识别出的类别。例如在第一幅图中遮挡住狗脸,网络会识别它为网球(Tennis ball)。
4.3 Correspondence Analysis(局部相关性分析)
深度学习模型没有显式定义图像中各部分的相关性。而是隐式的定义。(比如检测人脸,人脸里面的眼睛特征,嘴巴特征和不同人的眼睛特征之间是否有关系呢?实际上是相关的,但是深度学习并没有显式的定义而是隐式的定义。)为了验证这个观点我们进行了局部相关性分析,如下图所示:

为了验证神经网路存在隐式相关,我们将采用5张不同狗的图片,进行右眼遮挡,左眼遮挡,鼻子遮挡以及随机遮挡操作,用
ϵ
i
l
=
x
i
l
−
x
~
i
l
\epsilon^{l}_{i} = x^{l}_i - \tilde{x}^{l}_{i}
ϵil=xil−x~il 来表示某一张图片遮挡一个部位后在某一层网络上特征向量(feature vector)与原图之间特征向量的差值。 $ \epsilon^{l}_{i}$ 体现了遮挡一个部位后对该层网络feature vector的影响(遮挡右眼对第5层网络feature vector的影响)。然后将5张图片遮挡右眼后的
ϵ
i
l
\epsilon^{l}_{i}
ϵil,两两之间经过符号函数处理后求出海明距离然后相加就得到
Δ
l
=
∑
i
,
j
=
1
,
i
≠
j
5
H
(
s
i
g
n
(
ϵ
i
l
)
,
s
i
g
n
(
ϵ
i
l
)
)
\Delta_l = \sum^{5}_{i,j=1,i \neq j}\Eta(sign(\epsilon^{l}_{i}),sign(\epsilon^{l}_{i}))
Δl=∑i,j=1,i=j5H(sign(ϵil),sign(ϵil)).
Δ
l
\Delta_l
Δl 越小证明不同图之间
ϵ
i
l
\epsilon^{l}_{i}
ϵil是越小的,说明遮右眼对不同图片造成的影响是一样的。说明了哪怕是5张不同的狗狗但是遮右眼对它们造成的影响是一样的,说明遮右眼是隐式定义在网络中的。
通过表格我们可以知道,遮右眼第5层的
Δ
l
\Delta_l
Δl是很小的,只要是遮同一个部位
Δ
l
\Delta_l
Δl都是比较小的,随即遮
Δ
l
\Delta_l
Δl较大,但是随着网络深度的增加随即遮
Δ
l
\Delta_l
Δl会减小。这说明随着网络深度的增加,网络会越加关注图片的语义信息(sematical),狗这个类别而不是空间信息(spatial)狗眼睛,鼻子等。
5. Experiments(实验)
5.1 ImageNet 2012

我们采用ImageNet数据集用于训练,上图是我们的模型结果与AlexNet模型结果的比较,将第一层的卷积核由1111改为77 步长改为2,增加3,4,5层卷积核的个数为512,1024,512,然后将(a)(b)进行集成得到最终的模型。我们发现结果会特别好!
接下里我们分析去掉网络中不同层对模型产生的影响:
只去掉全连接层只会对模型产生一点点的影响,这就很惊讶了因为全连接层包含了所有的参数但是这也说明了全连接层的臃肿复杂。
去掉两个中间的卷积层对网络影响也不大。但是两个都去掉,那么结果就变得非常的差了。这表明网络的整体深度对网络是比较重要的。我们也可以改变全连接层神经元个数,但是效果不大,改变卷积核个数,增加卷积核个数和全连接神经元个数容易造成过拟合

下面是结果:
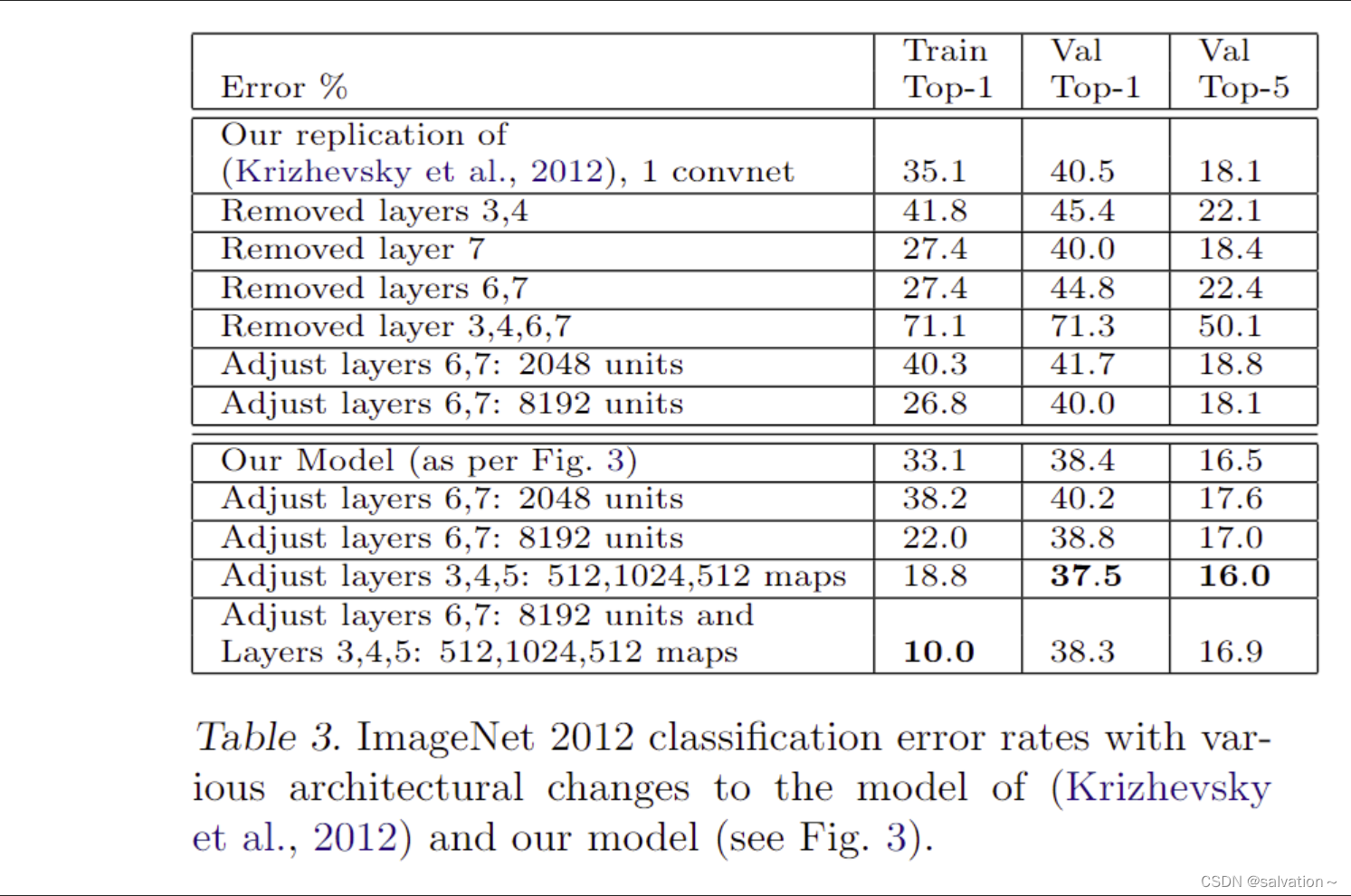
通过分析结果我们可以知道,增加6,7层的神经元个数为8192,第3,4,5层卷积核个数为512,1024,512在训练集上表现出最好的效果,这明显是出现了过拟合,而最优的网络结构是增加3,4,5层的卷积核个数为512,1024,512。这样的网络模型在验证集和测试集上都取得了最好的结果。
5.2 Feature Generalization(特征泛化)
上述的实验表明了卷积神经网络在ImageNet数据集上的表现是非常不错的,有着非常先进的水平。各种复杂的不变性是能够被神经网络学习到的。现在我们来探索一下在ImageNet数据集上学习到的特征能否泛化迁移到其他数据集上Caltech-101,Caltech-256,PASCAL。怎么做呢?我们只需要保留网络的1-7层(预训练好的特征提取器),然后修改softmax的输出层,将输出层由1000改为101,256等只训练softmax层,这样我们只需要用很少的样本就能完成训练并达到良好的分类效果。使用softmax分类和SVM的计算复杂度其实是一样的。
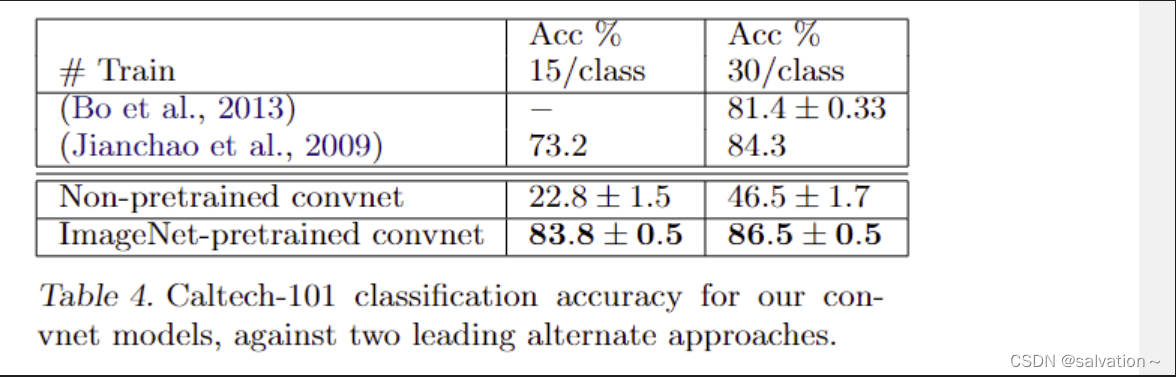
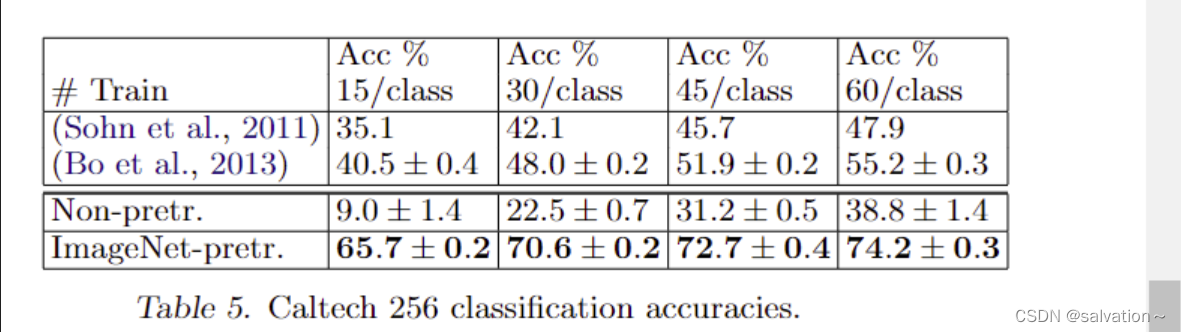
从结果发现预训练模型的准确率打败了之前最佳的模型,但是如果只保留模型结果,随机初始化模型权重结果是非常不好的。这证明迁移学习的有效性
在ImageNet上提取到的特征,用于其他新的数据集上进行训练模型。
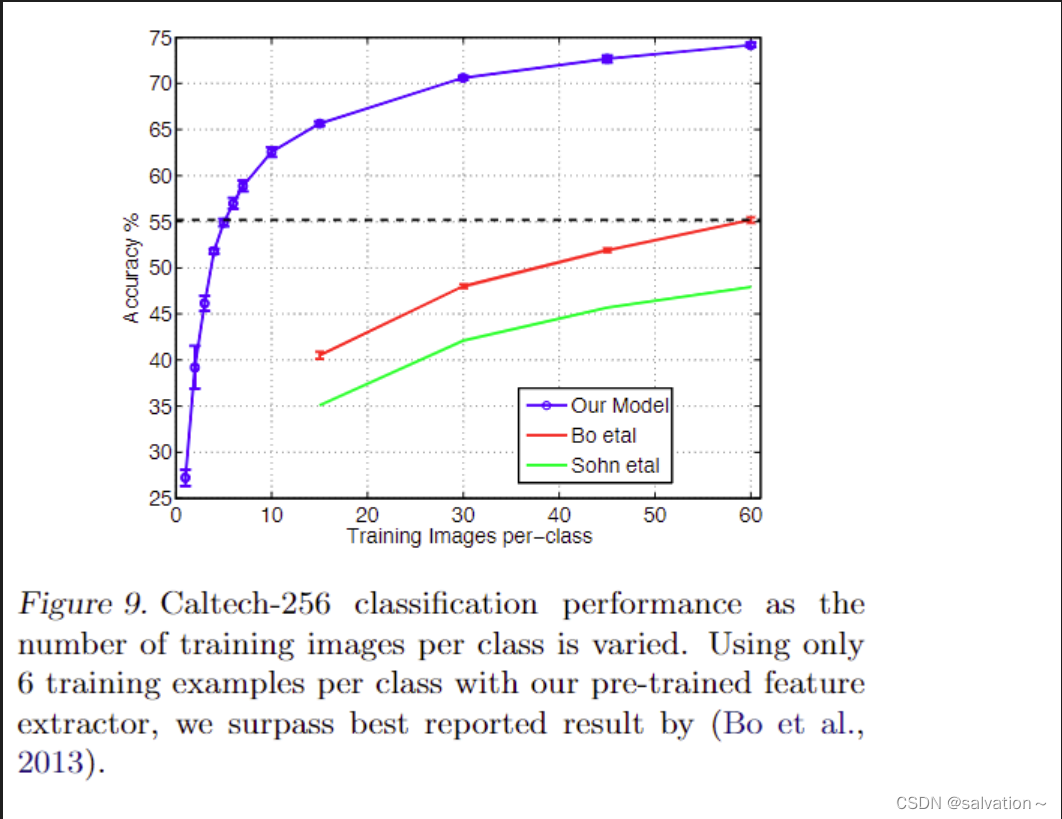
每个类别用多少张图片进行训练能得到非常好的分类效果,这个领域叫做one-short learning。我们发现当我们使用迁移学习的时候,每个新的类别只需要几张图片就能达到非常好的效果。如上图所示:当使用迁移学习的时候只要6张图片就能达到之前模型最好的效果而使用和之前一样多的照片是能达到更好的效果!

但是我们将模型泛化迁移到PASCAL VOC数据集上的时候,模型在一些类别上的准确率并没有超过(B)模型,因为PASCAL VOC数据集的图片中物体很多并不是ImageNet中单一的图片更为复杂,所以我们发现迁移学习可以将在复杂数据集上提取到的特征迁移到比他简单的数据集上时可以达到非常好的分类效果!
5.3 Feature Analysis(特征分析)
不同层特征对分类的有效性分析

从上表中我们可以发现随着网络深度的增加提取到的特征越有用!高层网络更关注图片的语义信息(人脸,鸟脚等)而底层网络只关注到空间信息(边缘,颜色)。
6. Disscussion(讨论)
我们探索了用于图像分类大型卷积网络模型,提出了deconvnet(反卷积)可视化中间层的特征以此来表明这些特征远不是随机的、不可解释的模式。相反,它们显示出许多直观的理想属性,如组合性、增加的不变性和随着我们逐层上升的不变性。如何用可视化方法改进模型,进行了局部遮挡敏感性分析,局部遮挡相关性分析,特征泛化分析,特征分析。在局部遮挡敏感性分析中模型对图片区域感兴趣而不是一整个图片。在Caltech数据集上泛化很好,但是在PASCAL VOC数据集集上不是特别好,但是仅差一点我们可以通过采用多物体损失函数用来改进模型!