前言
这段时间在自己的Win11系统上部署了chatGLM以及Qwen模型,进行对话、推理以及工具调用都没有问题,但是在尝试进行微调的时候发现好像并不能成功,因此花费了很大的力气,又分别在ubuntu桌面版、windows子系统WSL2 Ubuntu上部署了Qwen模型,并尝试进行LoRA的微调实践。
由于过程比较多,步骤较为繁琐,我可能会分几个部分进行叙述。首先介绍一下我的两个环境(平民玩家,勿喷):
一台笔记本安装的Ubuntu22.04桌面版:

显卡是1070M 8G
一台台式电脑,安装的Win11系统、WSL2(Ubuntu22.04分发版)

显卡是4060Ti 16G
下边开始安装配置,对于windows系统来说是WSL2上的Ubuntu,下边我简称WSL2。
开始配置环境
第一步:安装python环境
在大模型的开发中,首选conda环境,因为conda提供了对于科学计算以及常用的所有的包,免去了我们安装大量的第三方库的问题。
首先到到anaconda的官方地址:
https://repo.anaconda.com/archive/
选择一个需要安装的conda包,对于大模型开发,首选python3.11版本的conda,如下所示:

在Ubuntu22.04桌面版上不用说,下载后,直接在downloads文件夹下打开终端:
sh 下载的包名(在Linux系统上输入前几个字母,例如An按tab键就可以补全了)

WSL2环境,可以先通过windows系统下载好文件,再移动到Linux环境中(可以在资源管理器中找到),例如这样:

采用windows终端打开Ubuntu:

或者直接点击也行:

再切换到你放置conda包的地方,同样使用:
sh 下载的包名
就可以开始安装。
安装过程就是一直按enter:
最后一步要输入yes

再输入yes,不能按得太快,默认不接收协议就退出安装了。

安装完成:
在Ubuntu桌面版可以直接输入:python -V查看python版本

这就是默认将conda环境作为系统的默认python解释器了。
WSL2,我直接输入python,发现系统并不能识别python命令,通过查询,需要激活conda环境:
source /home/<用户名>/anaconda3/bin/activate请<用户名>为自己的。
输入之后就发现光标前面多了一个base,证明conda已经启用:

第二步:安装CUDA
CUDA是英伟达专为深度学习设计的加速库,广泛应用与当前的大模型开发中,因此必须要安装CUDA。这个也说明,要进行大模型的研究,只能选用N卡,A卡是不能够进行训练或者推理的。
我们直接输入:
nvcc --version看看机器是否已经安装了CUDA,如果下图所示:
![]()
这就是没有安装,这里Ubuntu提示使用sudo apt install nvidia-cuda-toolkit 去安装该库。这个我已经替大家试过了,采用这个命令,它默认安装的是CUDA11.5:

而不管你是什么显卡,CUDA11.5对于后续的开发是不够的,因此不能采用这种方法。
正确的安装方法如下:
需要到网址:
CUDA Toolkit 12.4 Update 1 Downloads | NVIDIA Developer
按照自己的需要选择CUDA版本。
先查看自己的显卡支持的最高cuda:
nvidia-smi
右侧出现CUDA Version就是当前环境能够支持的最高CUDA版本。
1070M显卡在Ubuntu22.04上居然支持CUDA12.2,也是相当可以(我记得之前安装Ubuntu18.04的时候最高只能支持11.几):

4060Ti能够支持最新版本12.4


安装网页的指示一步一步的执行:

安装完成之后需要手动修改环境变量!!
vi ~/.bashrc
按i键开始插入内容 按↓键滑到文末,复制以下内容:
export PATH=$PATH:/usr/local/cuda/bin然后重启WSL2:
wsl --shutdown
wsl -d Ubuntu再输入nvcc -V就可以看到已经安装成功了:

如果安装错了CUDA版本,例如之前使用sudo apt install nvidia-cuda-toolkit 安装的,可以通过以下命令卸载以安装的,再进行重装即可:
(我之前就采用默认命令安装,导致后续的问题,因此需要重装,开始竟然一时找不到卸载CUDA的方法,这个是在官方文档中找到的,采用以下三个步骤: )
sudo apt-get --purge remove "*cuda*" "*cublas*" "*cufft*" "*cufile*" "*curand*" \
"*cusolver*" "*cusparse*" "*gds-tools*" "*npp*" "*nvjpeg*" "nsight*" "*nvvm*"
sudo apt-get --purge remove "*nvidia*" "libxnvctrl*"
sudo apt-get autoremove(对于WSL2执行这些命令后,这里有个提示,如果是WSL2采用了以上卸载命令,发现虽然CUDA已经卸载完了,但是我们电脑的C盘空间还是没有变多。这是由于WSL2采用的虚拟盘只能扩大,不能自动缩容,需要手动进行压缩,大家可以自行百度解决。)
由于我的笔记本只能支持12.2所以转到历史版本:

我这里选择12.2.0:

按照给出的命令依次执行:

wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda-repo-ubuntu2204-12-2-local_12.2.0-535.54.03-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-2-local_12.2.0-535.54.03-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-2-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda执行完之后也需要修改环境变量:
vi ~/.bashrc
环境变量修改完之后,载入配置文件:
source ~/.bashrc再输入nvcc -V,安装成功:

第三步:安装CUDNN(这个可以不安装)
网址:
cuDNN Archive | NVIDIA Developer
选择一个版本:

解压
xz -d cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz
tar -xvf cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar将解压后的文件夹重命名
mv cudnn-linux-x86_64-8.9.7.29_cuda12-archive cuda移动文件:
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp -P cuda/lib/libcudnn* /usr/local/cuda/lib64 添加权限:
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*ok,到这里CUDNN就安装完成了,至于怎么验证是否安装成功吧,咳咳,我也不知道...反正下边的命令对我来说没用:
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2开发环境配置
桌面版可以安装pycharm,我们这里介绍jupyter-lab配置
jupyter-lab配置
这块主要是为了在windows上去方便的修改WSL2上面的文件,如果是在Ubuntu桌面版上可以直接安装pycharm,但是jupyterlab在某些方面是非常的方便,还是很推荐的,当然你也可以在pycharm中建立jupyternotebook也是一样的。
直接输入命令进行安装:
pip install jupyterlab如果是桌面版再输入:jupyter-lab即可启动,也不需要过多的配置:

如果是WSL2,在Ubuntu上安装的jupyter-lab需要在windows上访问需要以下的配置:
我们启动后,在本地访问后看到,需要提供密码:

我们需要做一些额外的配置。
远程加密设置jupyterlab访问密码的方法
from jupyter_server.auth import passwd
passwd()
记录生成的密文
生成配置文件:
jupyter lab --generate-config![]()
使用Vim编辑器打开该文件
vim /home/renjintao/.jupyter/jupyter_lab_config.py/password =进行查找
按enter键定位到
按i进行插入修改,填入之前生成的密文密码:

你也可以采用同样的方式设置其他的配置:

ServerApp.allow_origin = '*'
ServerApp.allow_remote_access = True
ServerApp.ip = '0.0.0.0'
ServerApp.open_browser = False
ServerApp.password = '加密后的密码'
ServerApp.port = 8002 *# 如果这里的端口没有修改,它还是默认的8888*修改完成后输入:wq保存退出。
启动命令:
jupyter-lab或者,采用后台启动的命令:
nohup jupyter lab --allow-root > jupyterlab.log 2>&1 &本地打开浏览器
127.0.0.1:8888
输入自己设置的密码即可访问:

设置jupyter-lab的默认启动位置:
创建配置文件
jupyter notebook --generate-config用vim编辑器打开该文件:
vim /home/<用户名>/.jupyter/jupyter_notebook_config.py先按下/
输入:c.NotebookApp.notebook_dir
按enter
按i
修改如下:

保存退出
:wq重启jupyter Lab的命令(针对后台启动的方式,如果直接采用jupyter-lab的方式启动的,按Ctrl+C停止进程,再次输入jupyter-lab即可)
先查看进程:
ps aux | grep jupyter杀死进程:
kill -9 进程号再次启动:
nohup jupyter lab --allow-root > jupyterlab.log 2>&1 &可以按到jupyter Lab已经默认启动到需要的路径下了:
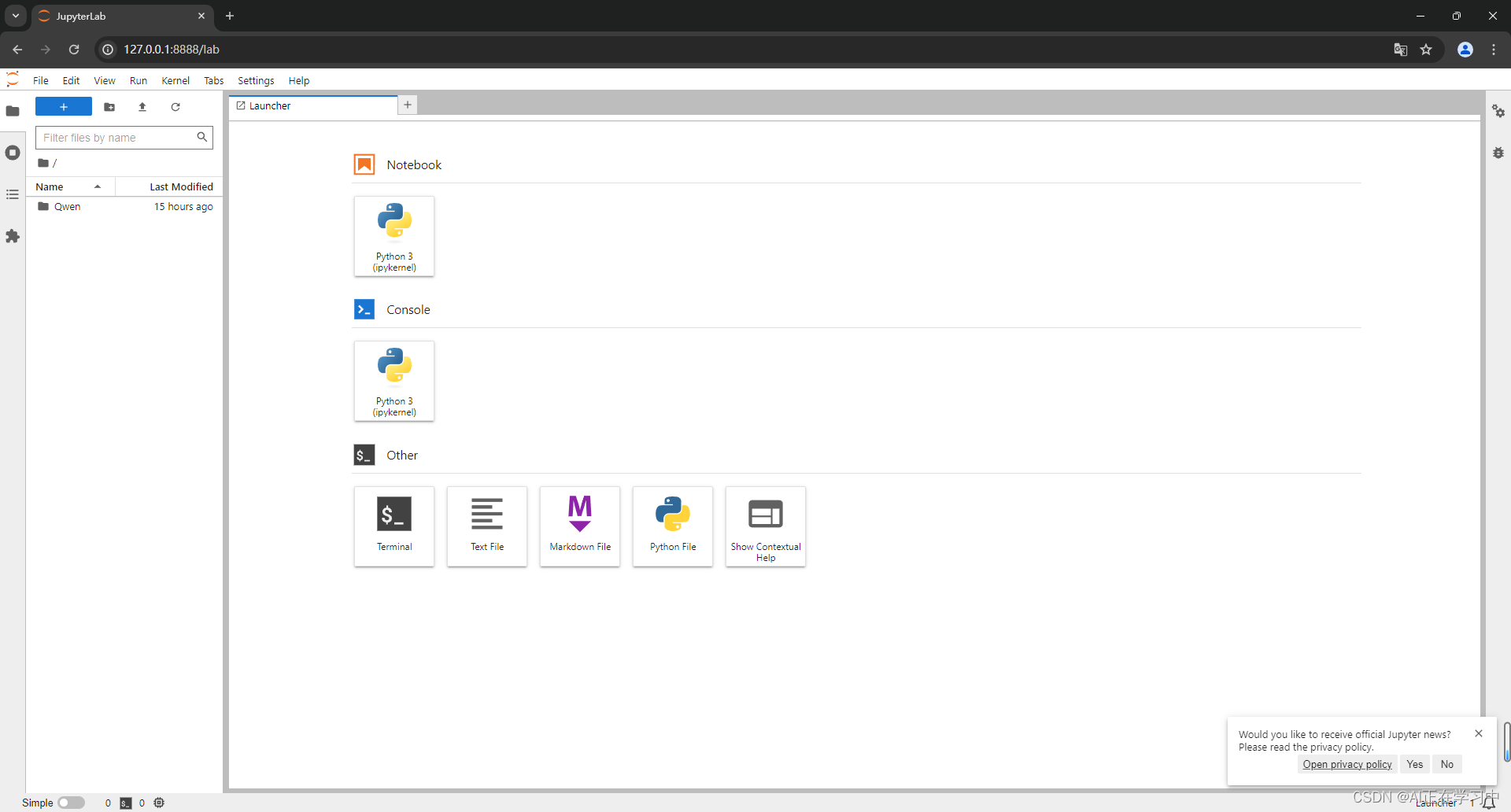
到目前为止机器的运行环境,以及我们要用到的编程环境都差不多了,下一部分将开始建立具体大模型的运行环境。
开始部署
建立虚拟环境
建立Qwen的虚拟环境
conda create -n qwen python=3.11切换到虚拟环境
conda activate qwen克隆项目文件
git clone https://github.com/QwenLM/Qwen安装依赖文件
cd Qwen
pip install -r requirements.txt安装GPU版本pytorch
到网址:
Start Locally | PyTorch
找到匹配cuda版本的pytorch版本安装命令:

12.x版本
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu12111.x版本
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118非常快速的安装完成:

验证pytorch是否安装成功
输入python进入到解释器环境:
import torch
print(torch.__version__)
print(torch.cuda.is_available())如果输出是True,则安装成功
配置jupyterlab
为虚拟环境建立kernel
conda install -n qwen ipykernel
将虚拟环境的kernel写入jupyterlab
python -m ipykernel install --user --name qwen --display-name qwen
再重启一下jupyterlab
下载模型
通过魔搭社区下载模型文件,执行下载命令前先安装:
pip install modelscope
方法1:Ubuntu桌面版采用:用pycharm打开项目,设置环境变量:
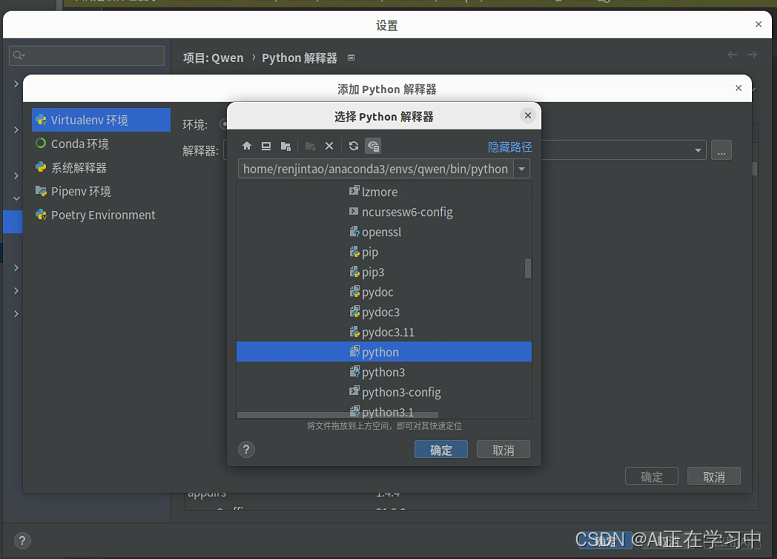
新建一个py文件:
写入以下代码:
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen-1_8B-Chat', cache_dir='./model', revision='master')
右键运行,开始下载:

下载完成

下载到本文件夹下的路径:

方法2:采用jupyterlab
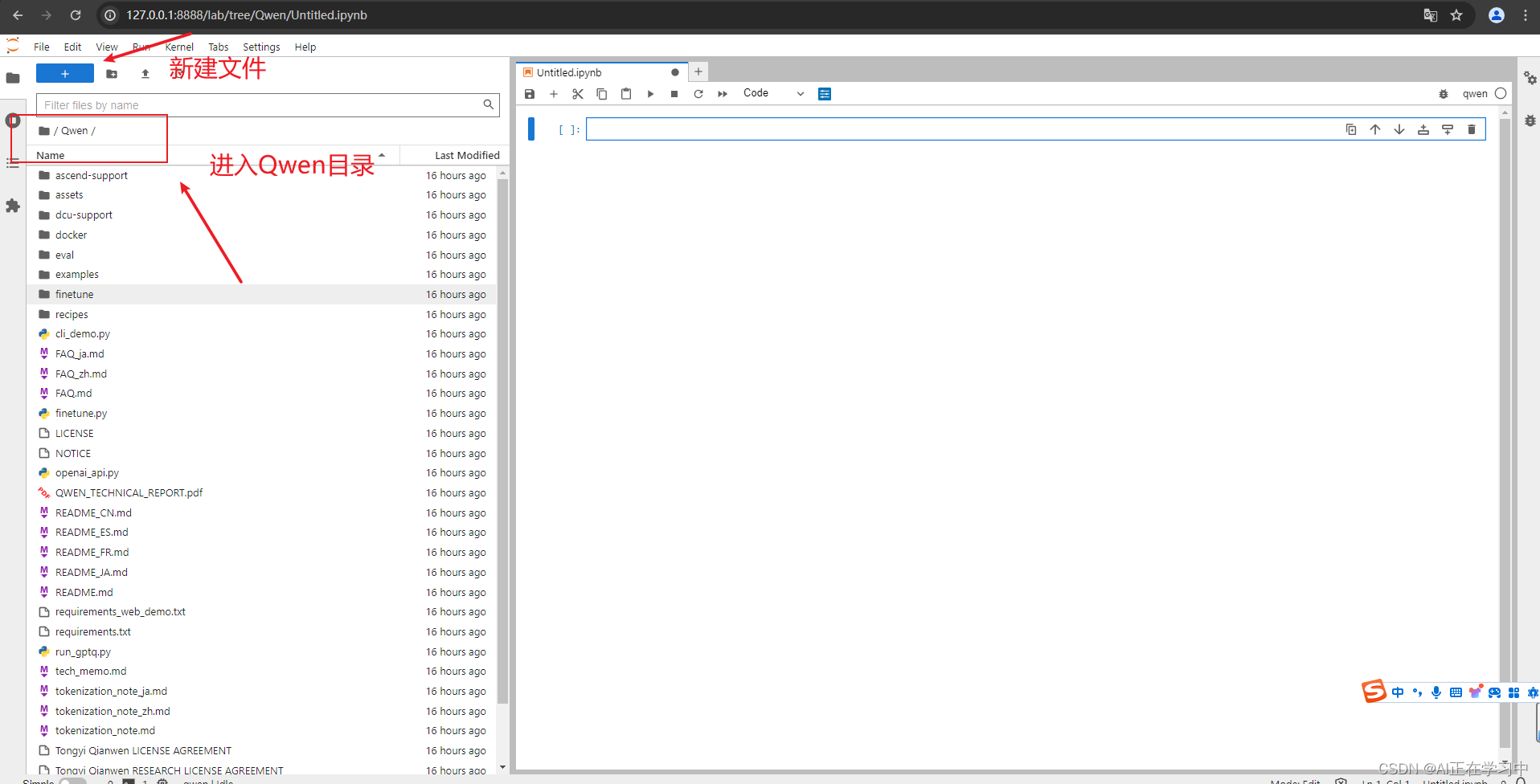
在右侧notebook中输入
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen-1_8B-Chat', cache_dir='./model', revision='master')点击运行

下载完成,可以看到本地路径下出现:

我们WSL2这边顺带再下载一个7B模型
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen-7B-Chat', cache_dir='./model', revision='master')运行

下载成功。
启动大模型测试
命令行脚本
修改cli_demo.py脚本中的本地模型路径:
DEFAULT_CKPT_PATH = './model/qwen/Qwen-1_8B-Chat'
DEFAULT_CKPT_PATH = './model/qwen/Qwen-7B-Chat'
jupyterlab修改

启动模型试试:

成功启动模型,再对话试试:

或者在终端输入:
python cli_demo.py启动成功:

WSL2(16G显存)上测试一下7B模型:

再次运行:
python cli_demo.py加载就慢很多了:

对话的反应也很慢:

测试网页demo
需要安装相应的依赖:
pip install -r requirements_web_demo.txt
再启动web-demo试试:
pycharm:

jupyterlab

注意我这里是7B模型
启动网页脚本:
python web_demo.py启动成功。
打开浏览器,输入127.0.0.1:8000访问

显卡监控命令
nvidia-smi或者每秒查看一次进行监控:
watch -n 1 nvidia-smi1.8模型下的显卡占用:

7B模型下的显卡占用:

flash-attention安装
注意到之前在启动模型时,提示:

这就是没有安装flash-attention,flash-attention是一种推理加速框架。
flash-attention主要进行计算层的并行优化。
!! 在多次尝试后发现我的4060Ti根本用不了flash-attention2,非常的郁闷,等到后期用到GTX 3090、4090以及更高规格的显卡,再进一步尝试吧!!
安装方法如下:
先安装依赖包
pip install packaging
pip install ninjaReleases · Dao-AILab/flash-attention (github.com)
下载flash-attention库的预编译包
按照自己的pytorch版本、cuda以及python版本下载版本
例如pytorch2.3,CUDA 11.X,python3.11版本:

pytorch2.3,CUDA 12.X,python3.11版本

如果不知道自己的torch版本
在jupyterlab中输入:
pip list

可以用wget命令

下载好了安装包,放到一个文件中:
我的WSL2,也可以直接windows上下载好了,直接放到Ubuntu文件中去:

再切换到目录:
安装预编译文件:
pip install 该安装包名
pip install flash_attn-2.5.7+cu122torch2.3cxx11abiTRUE-cp311-cp311-linux_x86_64.whl成功安装:

再回到之前的qwen文件夹:

克隆flash-attention项目文件
git clone https://github.com/Dao-AILab/flash-attention
网络不好的时候可能需要多尝试几次:

cd到该文件夹:
cd flash-attention/csrc/layer_norm将需要的另外的组件,预编制到当前机器上:
MAX_JOBS=4 python setup.py install
如果之前安装默认的CUDA 这里会提示:
CUDA 11.6以下的版本不支持flash-attention!!!
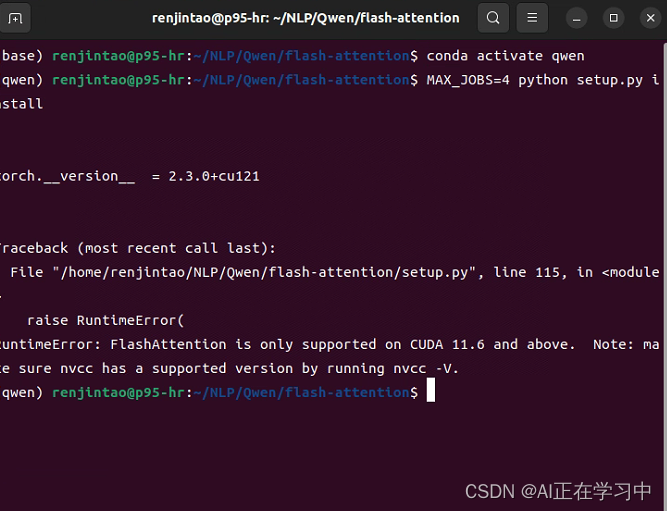
正确安装的界面如下: