关联容器和顺序容器有着根本的不同:关联容器中的元素是按关键字来保存和访问的,而顺序容器中的元素是按它们在容器中的位置来顺序保存和访问的。关联容器因此相比与顺序容器支持高效的关键字查找和访问。
其底层数据结构:顺序关联容器 ->红黑树,插入和查找的时间复杂度为 O(log n)
无序关联容器 ->哈希表,插入查找的时间复杂度为O(1)
1. 关联容器介绍:
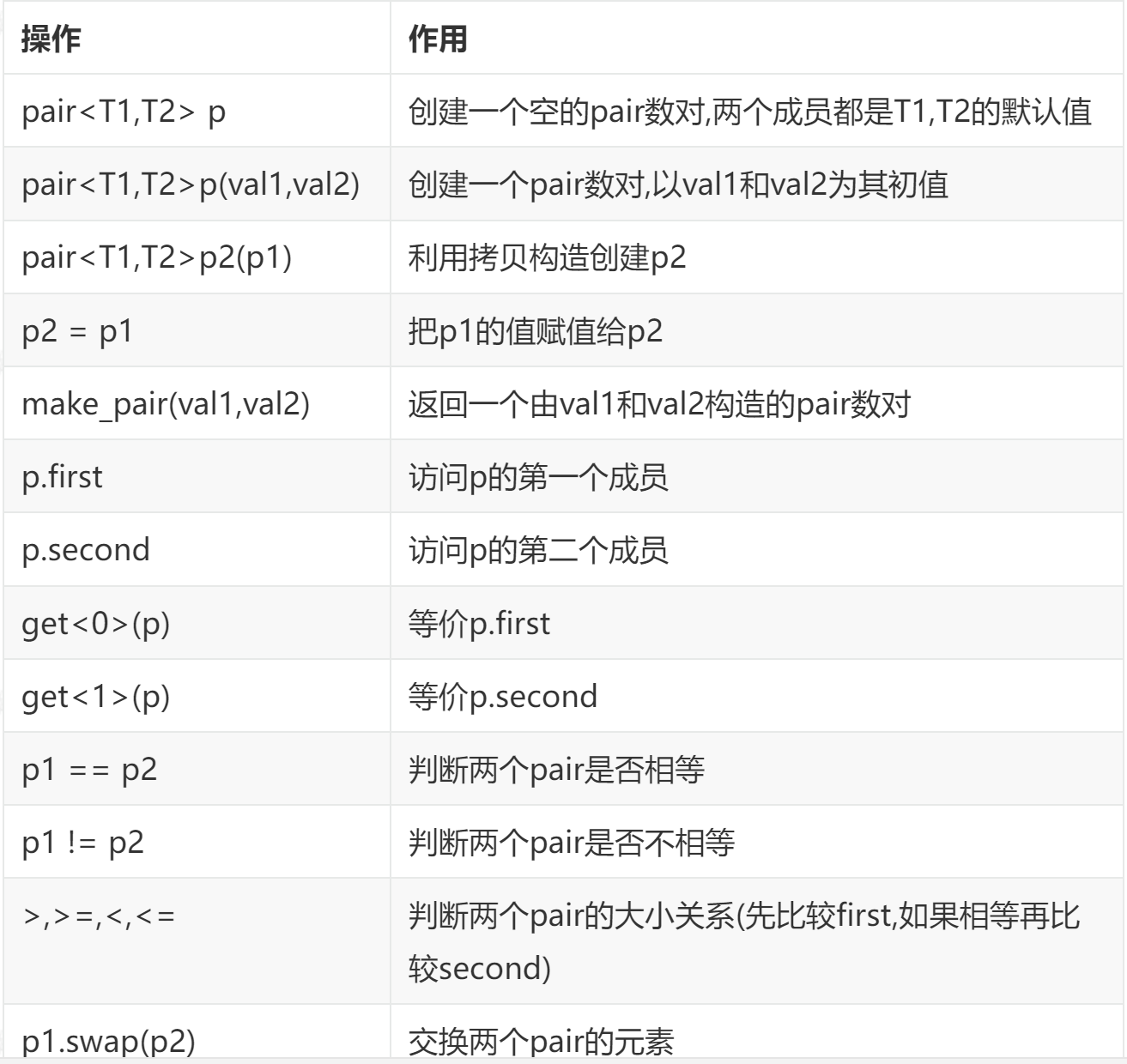
1.1. pair 数对:
pair是一个模板类,使用时需要引用<utility>文件
#include <utility>//通用工具pair可将两个value处理为一个元素。C++标准库内多处用到了这个结构。尤其容器 map、unordered_map和unordered_multimap就是使用pair来管理其内部元素(key_value),任何函数如果需返回两个 value,也需要用到pair,例如minmax()最大最小值
1.1.1. 基础操作:
1.2. 有序关联容器:
1.2.1. set 和multiset:
使用set或multiset,必须先包含头文件<set>:
#include <set>上述两个类型都被定义为命名空间std内的class template:
namespace std {
template <typename T,
typename Compare = less<T>,
typename Allocator = allocator<T> >
class set;
template <typename T,
typename Compare = less<T>,
typename Allocator = allocator<T> >
class multiset;
}其中T是能进行排序的数据类型。第二个参数是进行排序的规则,默认为升序(小于,<)。第三个是内存分配器,不用管。
set 和multiset通常用平衡二叉树(balanced binary tree,确切说是红黑树)实现。这样在插入数据时能自动排序,使得查找元素时有良好性能。其查找函数具有对数O(logn)时间复杂度。
但是,自动排序也造成set和multiset的一个重要限制:你不能直接改变元素值,因为这样会打乱原本正确的顺序。
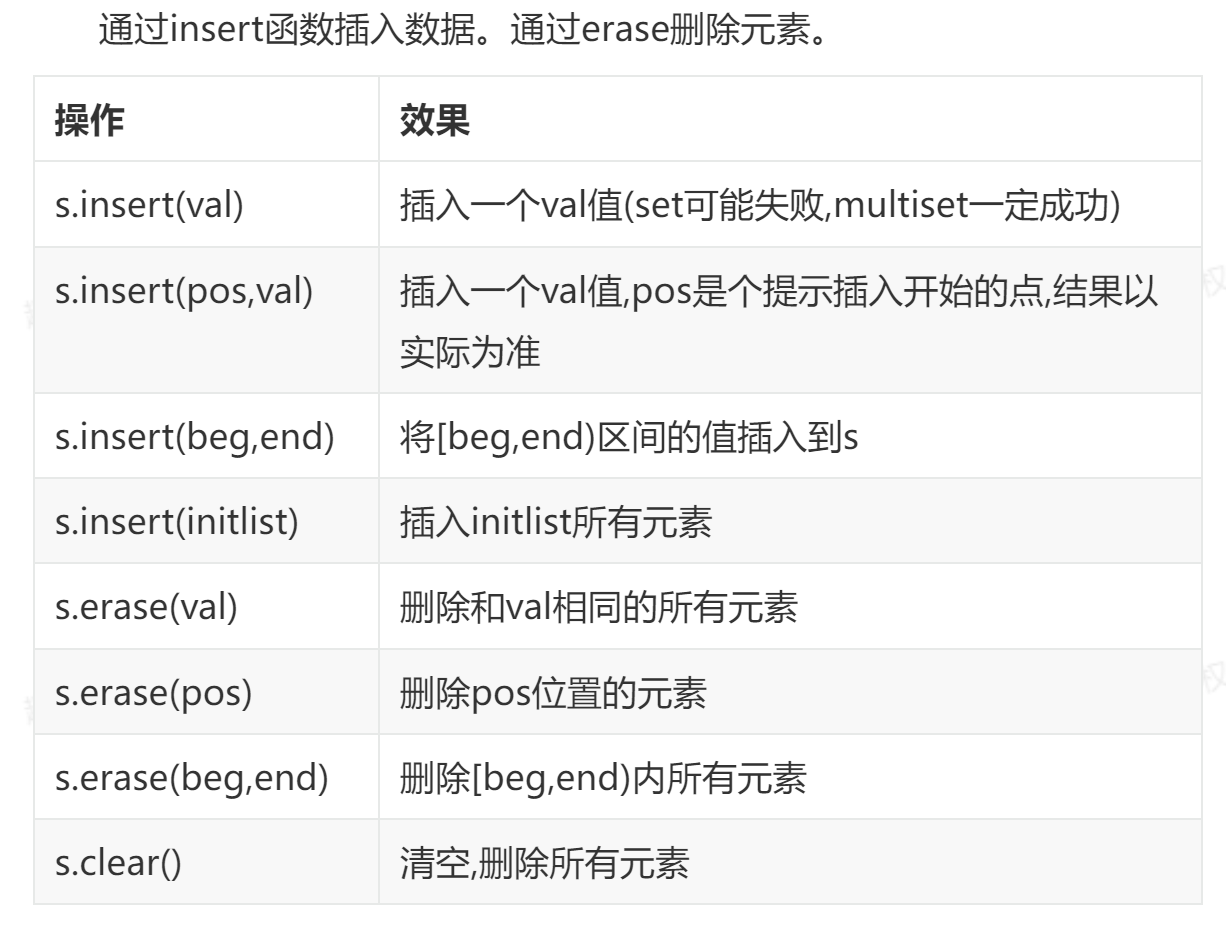
1.2.1.1. 基础操作:
set和multiset支持双向迭代器,不支持随机迭代器
可以往前和往后,但不能+1,-1(这是随机迭代器)等。

1.2.1.2. 常用函数:
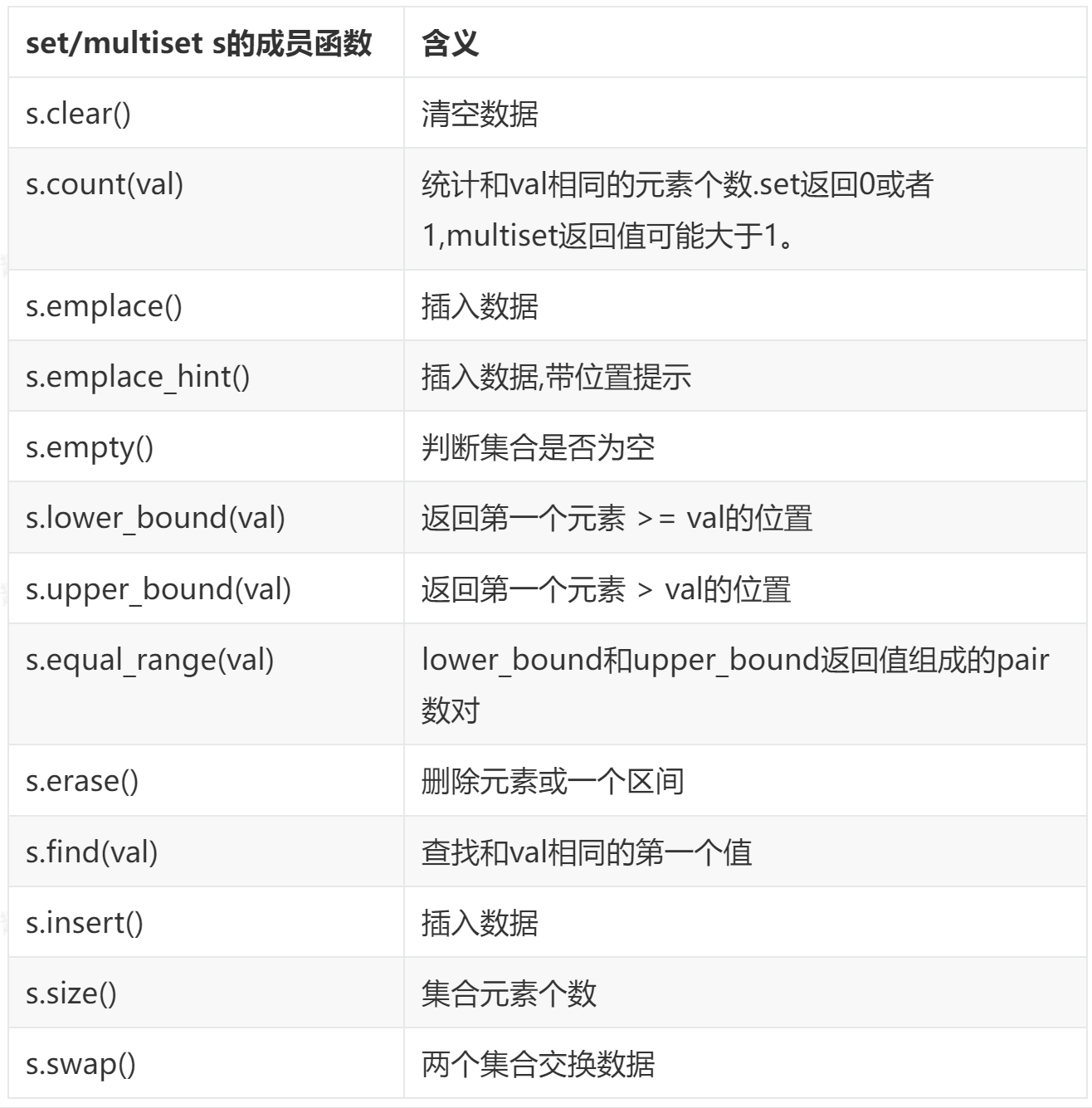
1.2.1.3. set应用场景
去重操作
当需要从一个数据集合中去除重复元素时,set是一个很好的选择。由于其不允许存储重复的元素,因此可以很容易地实现去重功能。这在处理原始数据或进行数据分析时特别有用。
自动排序
如果需要对元素保持持续的排序状态,如维持一个按字母顺序排列的单词列表、存储并维护一个按年龄升序或降序排列的人口数据库等,std::set 可以实现这一功能。每次插入新元素,容器都会自动调整元素的顺序。
- 当然如果仅仅是排序,可以使用sort函数进行排序.
- sort排序是在排序瞬间的,如果又插入新的数据可能不再有序
- set的有序是持续的,不管插入还是删除数据它始终有序
快速查找
由于set内部采用了高效的平衡查找二叉树(如红黑树),因此它提供快速的查找性能。包括检查元素是否已存在(.count() 或 .find())、查找特定值的下一个/前一个元素(迭代器操作)。这对于实现诸如查找词汇表中的下一个更大词、或者在游戏中查找排名高于当前玩家的下一个玩家等场景很有用。
1.2.2. map和multimap:
map和 multimap映射 将 key - value数对(也称键值对)当作元素进行管理,它们可根据 key 的排序准则自动为元素排序。multimap 允许key重复,map 不允许key重复,对于value不考虑 。
使用map和multimap必须引用头文件map
#include <map>
using namespace std;map和multimap 会根据元素的 key 自动对元素排序。这么一来,根据已知的 key 查找某个元素时就能够有很好的效率O(logn),而根据已知 value 查找元素时,效率就很糟糕 O(n)。
1.2.2.1. 常用迭代器:
map和multimap支持双向迭代器,不支持随机迭代器,可以往前和往后,但不能+1,-1(这是随机迭代器)等。
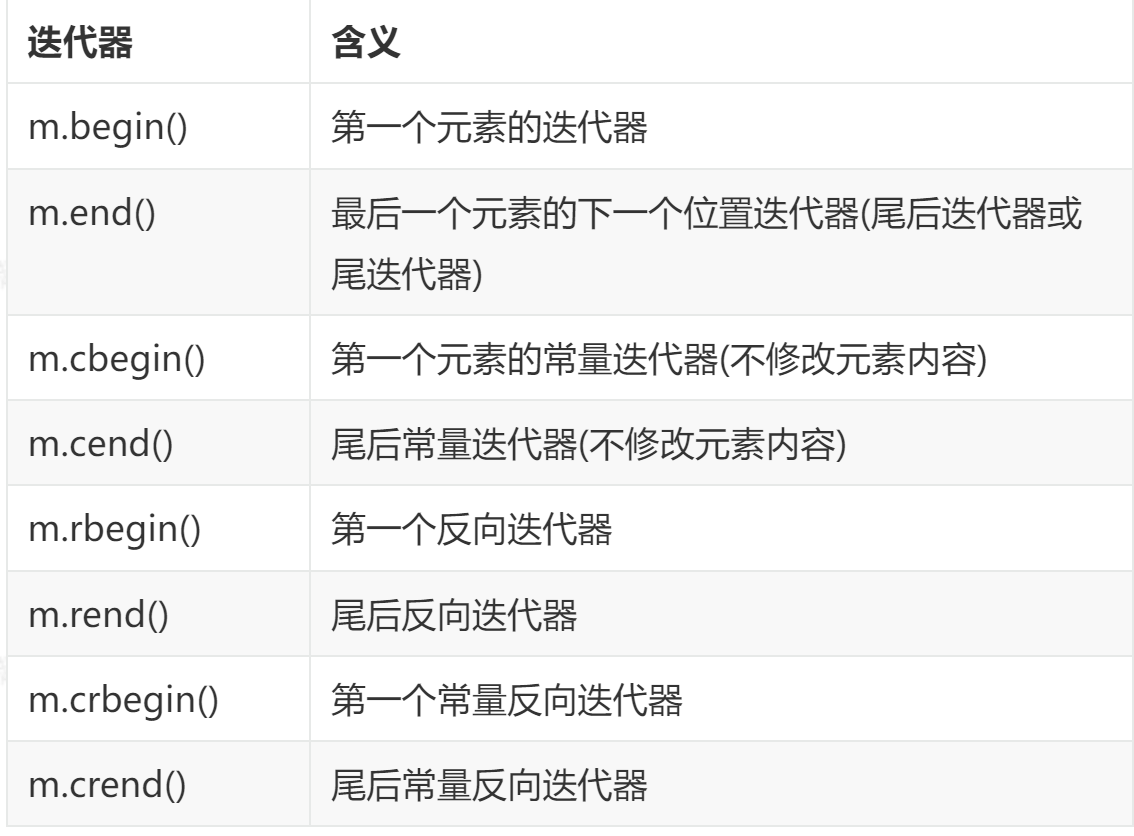
1.2.2.2. 常用运算符:
- [ ]是map中最重要和常用的运算符,它可以通过key访问元素。如果这个key存在则返回元素的引用,如果key不存在则添加新元素。但multimap不支持[ ]。
- 注意m[key]中的key是关键字,可以是任意类型,不是下标。map和multimap没有下标访问。

1.2.2.3. 常用函数:
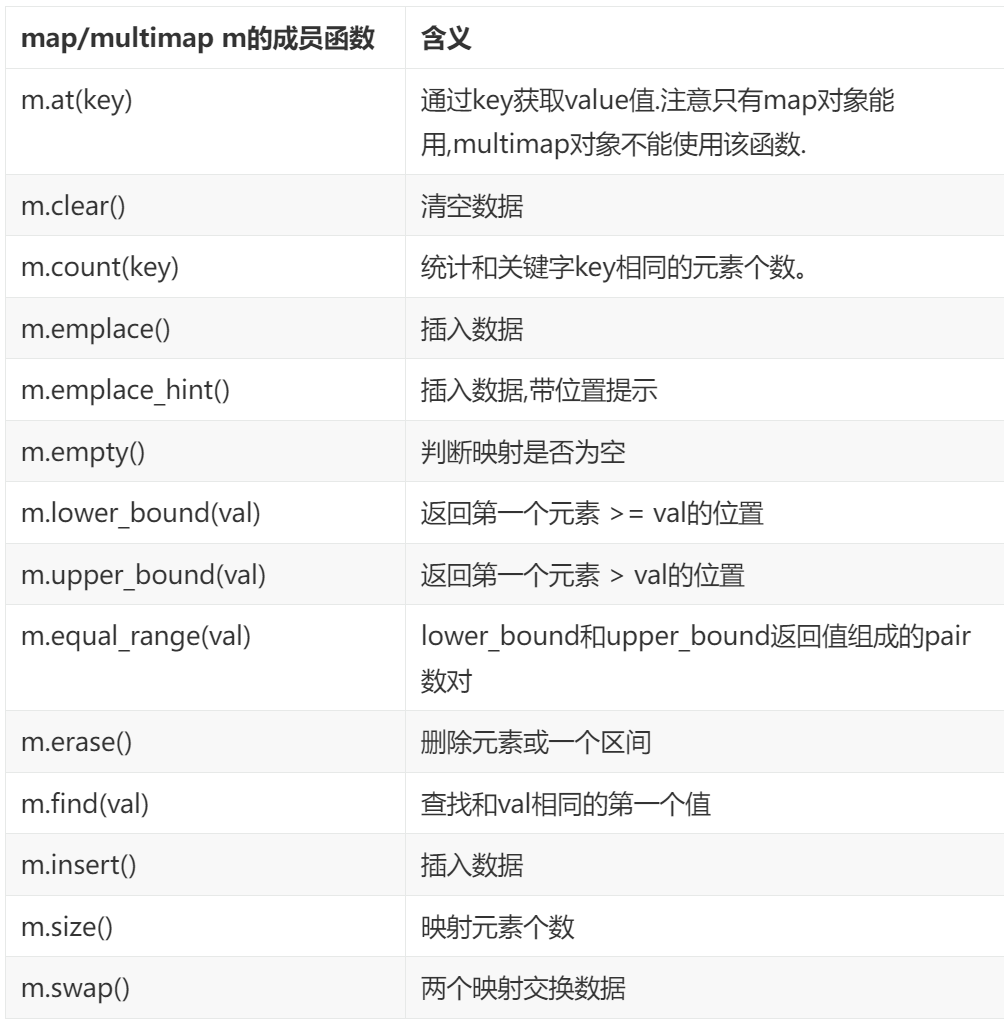
1.2.3. 有序关联容器特有函数:
lower_bound成员函数
返回第一个元素值 >= val的位置(迭代器)。
upper_bound成员函数
返回第一个元素值 > val的位置(迭代器)。
int main()
{
set<int> s1{1, 2, 3, 4, 5};
auto it1 = s1.lower_bound(2);
if (it1 != s1.end())//找到>=2的迭代器
cout << "在s1中找到>=2的元素" << * it1 << endl;
set<int>::iterator it2 = s1.lower_bound(6);
if (it2 == s1.end())//没有找到>=6的元素
cout << "在s1中没有找到>=6的元素" << endl;
it1 = s1.upper_bound(2);//找>2的迭代器
if (it1 != s1.end())//找到>2的迭代器
cout << "在s1中找到>2的元素" << *it1 << endl;
multiset<int> s2{1, 1, 2, 3, 3, 4, 5, 5};
auto it3 = s2.upper_bound(4); //找>4的迭代器
if (it3 != s2.end())//找到>4的迭代器
cout << "在s2中找到>4的元素" << *it3 << endl;
auto p = s2.equal_range(3);//查找3的区间
if ((p.first != s2.end()) && (p.second != s2.end()))
{
cout<< "在s2中找3的区间是(第一个>=3 ~ 第一个>3):" << *p.first << "~" << *p.second;
}
return 0;
}1.3. 无序关联容器:
无序(unordered)容器也称无序关联(unordered associative)容器。unordered 无序容器存放的元素是无序的。无序容器一个有4个,分别是unordered set ,unordered multiset, unordered map,unordered multimap。
使用unordered set 或者unordered multiset需要引用<unordered_set>头文件
#include <unordered_set>使用unordered map或者unordered multimap需要引用<unordered_map>头文件。
#include <unordered_map>这四个类型都是定义在std中的类模板。
namespace std{
template <typename T,
typename Hash = hash<T>,
typename EqPred = equal_to<T>,
typename Allocator = allocator<T> >
class unordered_set;//unordered_set类
template <typename T,
typename Hash = hash<T>,
typename EqPred = equal_to<T>,
typename Allocator = allocator<T> >
class unordered_multiset;//unordered_multiset类
template <typename Key, typename T,
typename Hash = hash<T>,
typename EqPred = equal_to<T>,
typename Allocator = allocator<pair<const Key,T>>>
class unordered_map;//unordered_map类
template <typename Key,typename T,
typename Hash = hash<T>,
typename EqPred = equal_to<T>,
typename Allocator = allocator<pair<const Key,T>>>
class unordered_multimap;//unordered_multimap类
}其中T是value值的类型,Key是关键字类型。
如果没有指明hash 函数,就使用默认的hash<>,这个函数可以用于所有内置类型、指针、string及若干特殊类型。对于自定义的类型可能需要自定义hash 函数。
EqPred,用来判断两个元素是否相等。默认使用equal_to<>。它会以operator==比较两个元素。
这几个无序容器内部利用hash table(哈希表)为基础。
无序关联容器除了没有有序关联容器特有的比较函数,其他与有序关联容器的函数用法类似
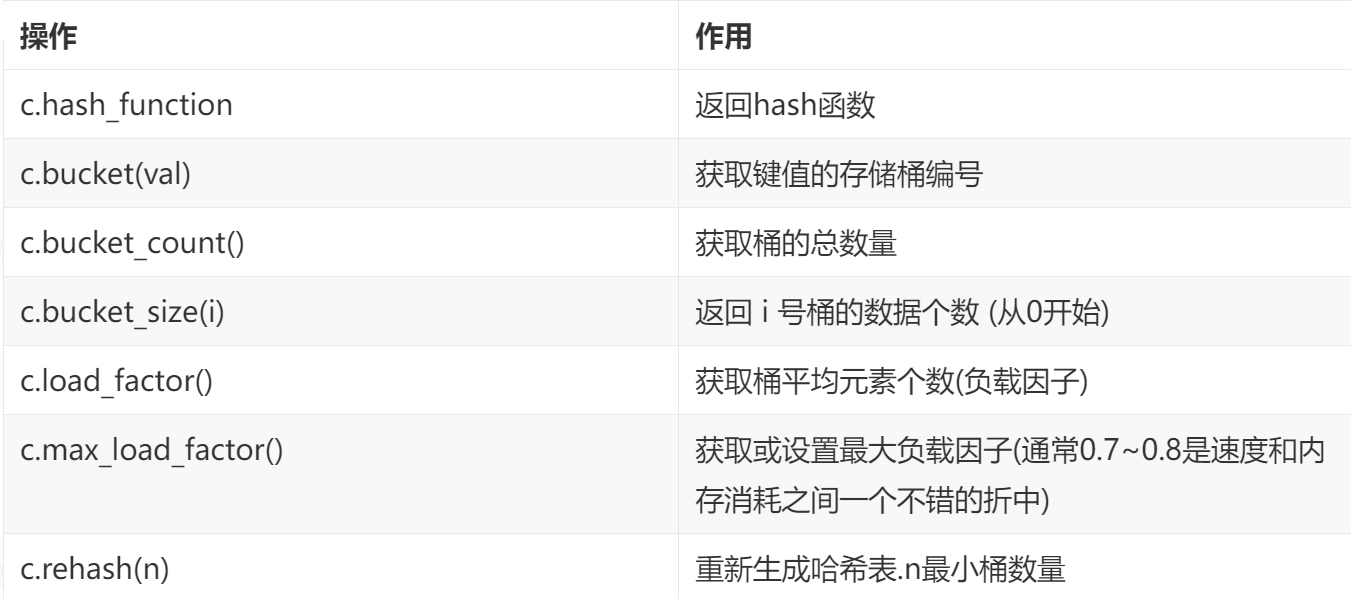
2. 无序容器布局操作函数
无序容器内部利用hash table(哈希表)为基础
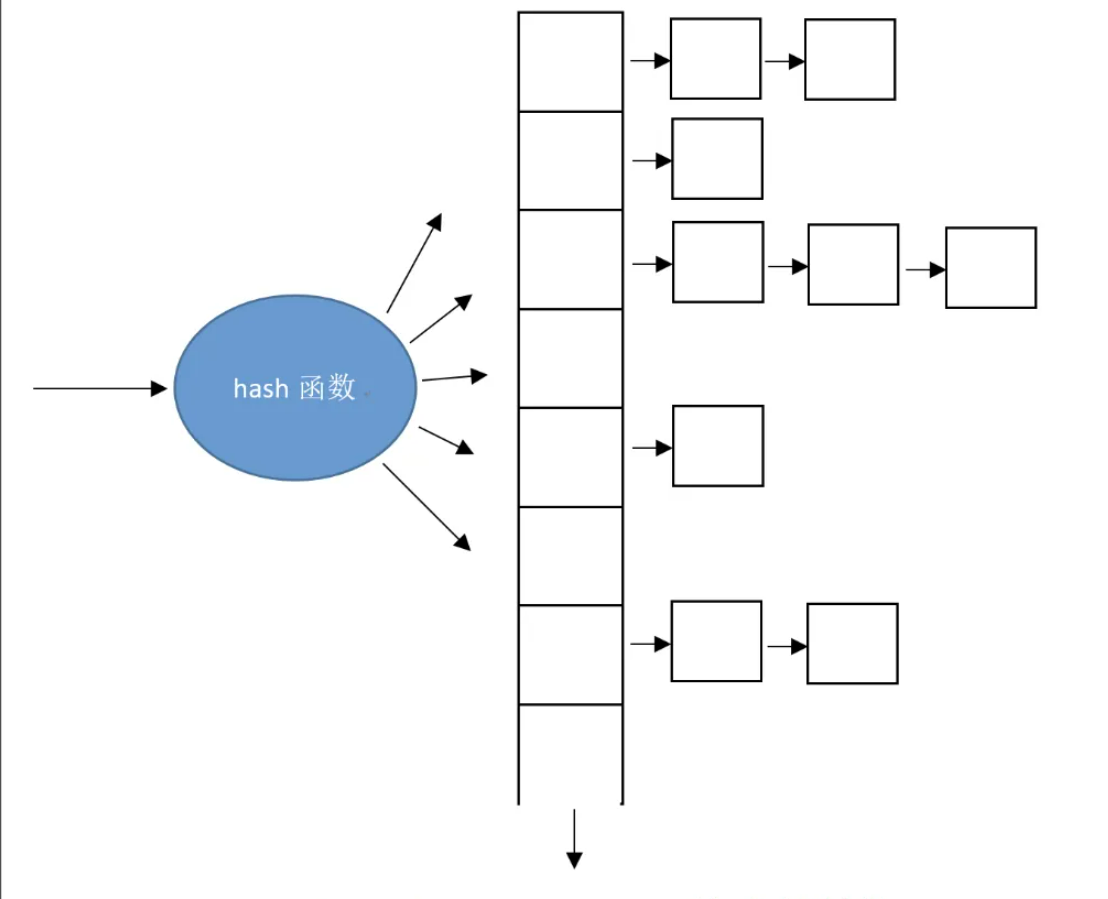
上图是unordered set/multiset的内部结构图,通过哈希函数将数据value映射到某个bucket(slot 桶)中
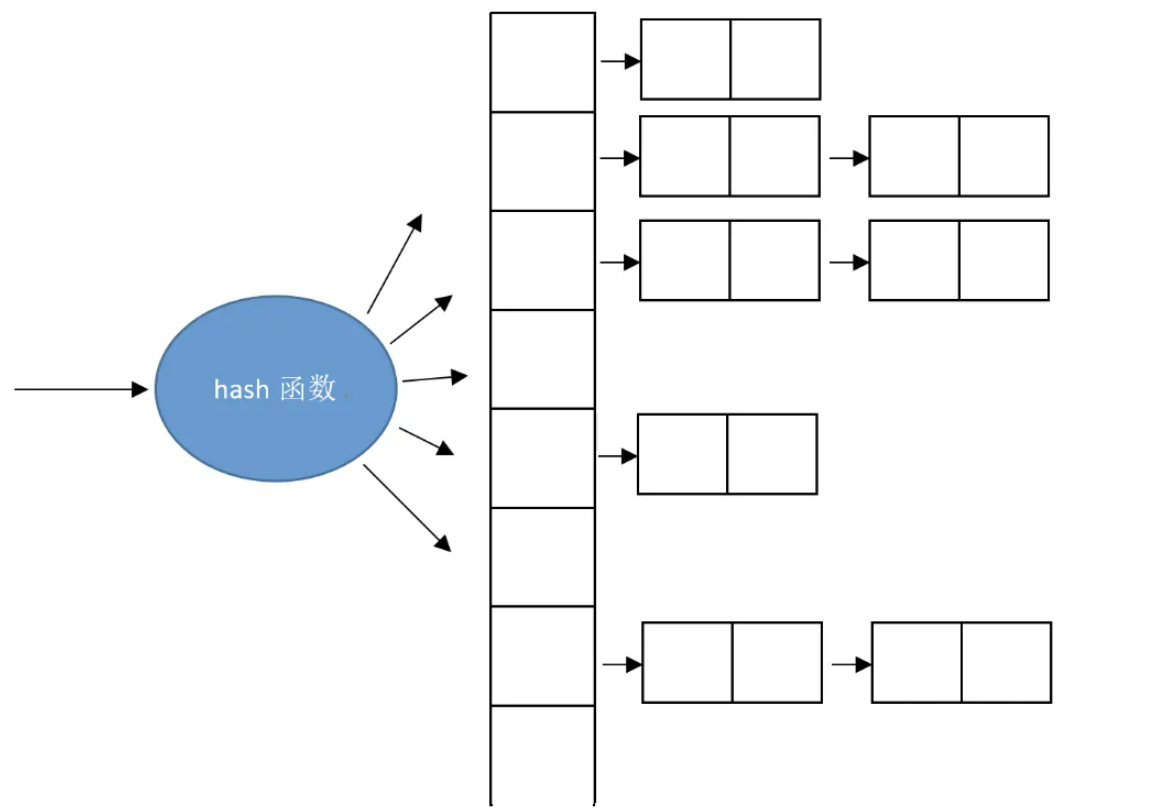
上图是unordered map/multimap的内部结构图,通过哈希函数将数据key-value映射到某个bucket(slot 桶)中。
每一个bucket管理一个链表,这个链表包含的是通过哈希函数产生相同哈希值的元素。这个链表是单链表还是双向链表C++标准并没有规定。(vs2022是双向链表)。下面两行代码是vs2022 xhash 文件中的代码
//插入新节点,需要修改前驱指针和后继指针
_Insert_after->_Next = _Newnode;
_Insert_before->_Prev = _Newnode;通过hash管理在插入,删除和查找元素时都能达到平均常量(O(1))时间的复杂度。
int main()
{
unordered_set<int>s1{1,2,4,2,4,2,4,2,6,6,7,8,9,5,11,22,33,44};
auto hashfun = s1.hash_function();//获取当前的哈希函数,默认的hash函数
cout << "hashfun(11) = " << hashfun(11) << endl;//内部在计算桶编号时对这个值又进行了计算
cout << "val为2 的桶值编号 = " << s1.bucket(2)<<endl;
cout << "val为2 的桶值编号 = " << s1.bucket(4) << endl;
cout << "val为2 的桶值编号 = " << s1.bucket(6) << endl;
cout << "val为2 的桶值编号 = " << s1.bucket(7) << endl;
cout << "val为2 的桶值编号 = " << s1.bucket(8) << endl;
cout << "val为2 的桶值编号 = " << s1.bucket(9) << endl;
int n = s1.bucket_count();
cout << " 桶的总数量为:" << n << endl;
for (int i = 0; i < n; i++)
{
cout << i << "号桶的数据个数为:" << s1.bucket_size(i) << endl;
}
cout << "桶的平均元素个数为(负载因子):" << s1.load_factor()<<endl;
cout << "桶的最大元素个数为(负载因子):" << s1.max_load_factor() << endl;
cout << "重新生成哈希表后的hash函数为s1.rehash(15):" << endl;
s1.rehash(99);
cout << "桶的平均元素个数为(负载因子):" << s1.load_factor() << endl;
cout << "桶的最大元素个数为(负载因子):" << s1.max_load_factor() << endl;
return 0;
}3. 综合应用:
3.1. 1.测试有序容器和无序容器性能差别:
生成1,000,000个随机数,范围(0~100000000 ,1亿),分别插入到set和unordered_set中,统计插入的时间区别,统计查找的时间区别。
步骤:
- 产生1,000,000个随机数并保存到vector中(保证数据样本相同)。
- 把这1,000,000个数字从vector插入到set中并记录时间\插入到unordered_set中并记录时间。
- 在set中\在unordered_set查询0~1,000,000(不需要记录是否查询成功)并记录时间。
#include <iostream>
#include <random>
#include <set>
#include <unordered_set>
using namespace std;
int main()
{
vector<unsigned int>v;
set<unsigned int>s1;
unordered_set<unsigned int> s2;
const int n = 1000000;//数据样本 1百万
default_random_engine engine;//默认随机引擎
uniform_int_distribution<unsigned int> di(0, 100000000);//随机数范围0~1亿
//给向量v插入数据
for (int i = 0; i < n; ++i) //产生随机数,并存放到v中
v.push_back(di(engine));
//把数据插入到set集合中并记录时间
clock_t c1 = clock();
for (auto x : v)
s1.insert(x);
clock_t c2 = clock();//结束插入数据
//把数据插入到unordered_set集合中并记录时间
for (auto x : v)
s2.insert(x);
clock_t c3 = clock();
cout << "插入1百万数据时间比较. set:" << c2 - c1;
cout<< "毫秒,unordered_set:"<<c3-c2<<"毫秒"<< endl;
//在set中查询0~1,000,000并统计时间
c1 = clock();
for (unsigned int i = 0; i < 1000000; i++)
s1.find(i);//不处理查询结果
c2 = clock();
//在unordered_set中查询0~1,000,000并统计时间
for (unsigned int i = 0; i < 1000000; i++)
s2.find(i);//不处理查询结果
c3 = clock();
cout << "查询1百万数据时间比较. set:" << c2 - c1;
cout << "毫秒,unordered_set:" << c3 - c2 << "毫秒" << endl;
return 0;
}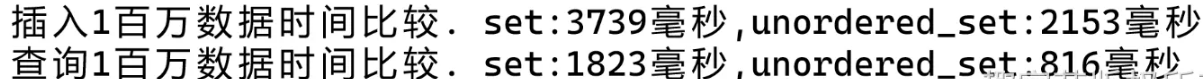
关联容器(set,multiset,map,multimap)有序,插入的时间复杂度为O(logn),查询的时间复杂度为O(logn)
无序容器(unordered_set,unordered_multiset,unordered_map,unordered_multimap),内部利用哈希表,插入的时间复杂度平均为O(1),查询的时间复杂度平均为O(1)。
如果对数据有序性没有要求,请优先使用无序容器。
3.2. 2.测试无序容器最大负载因子对性能的影响:
#include <iostream>
#include <random>
#include <unordered_set>
#include<vector>
using namespace std;
//2.测试无序容器最大负载因子对性能的影响
int main()
{
vector<unsigned int>v;
unordered_set<unsigned int>s;//s1为默认负载因子
unordered_set<unsigned int>s1;//可设置负载因子
unordered_set<unsigned int>s2;//可设置负载因子
unordered_set<unsigned int>s3;//可设置负载因子
unordered_set<unsigned int>s4;//可设置负载因子
unordered_set<unsigned int>s5;//可设置负载因子
unordered_set<unsigned int>s6;//可设置负载因子
unordered_set<unsigned int>s7;//可设置负载因子
s1.max_load_factor(0.1f);//设置最大负载因子
s2.max_load_factor(0.2f);//设置最大负载因子
s3.max_load_factor(0.3f);//设置最大负载因子
s4.max_load_factor(0.4f);//设置最大负载因子
s5.max_load_factor(0.5f);//设置最大负载因子
s6.max_load_factor(0.6f);//设置最大负载因子
s7.max_load_factor(0.7f);//设置最大负载因子
const int n = 1e6;//数据样本 1百万
default_random_engine engine;//默认随机引擎
uniform_int_distribution<unsigned int>rand;//随机数范围0~1亿
//给向量v插入数据
for (int i = 0; i < n; i++)
v.push_back(rand(engine));//插入生成的随机数
//把数据插入到s1中并记录时间
clock_t c0 = clock();
for (int t : v)
s.insert(t);
clock_t cc = clock();//结束插入数据
//把数据插入到s2中并记录时间
for (auto x : v)
s1.insert(x);
clock_t c1= clock();
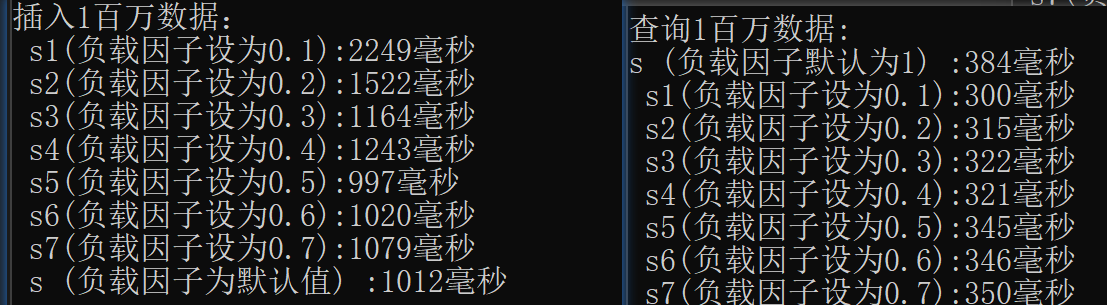
cout << "插入1百万数据:"<<endl;
cout << " s1(负载因子设为0.1):" << c1 - cc << "毫秒" << endl;
for (auto x : v)
s2.insert(x);
clock_t c2 = clock();
cout << " s2(负载因子设为0.2):" << c2 - c1 << "毫秒" << endl;
for (auto x : v)
s3.insert(x);
clock_t c3 = clock();
cout << " s3(负载因子设为0.3):" << c3 - c2 << "毫秒" << endl;
for (auto x : v)
s4.insert(x);
clock_t c4 = clock();
cout << " s4(负载因子设为0.4):" << c4 - c3 << "毫秒" << endl;
for (auto x : v)
s5.insert(x);
clock_t c5 = clock();
cout << " s5(负载因子设为0.5):" << c5 - c4 << "毫秒" << endl;
for (auto x : v)
s6.insert(x);
clock_t c6 = clock();
cout << " s6(负载因子设为0.6):" << c6 - c5 << "毫秒" << endl;
for (auto x : v)
s7.insert(x);
clock_t c7 = clock();
cout << " s7(负载因子设为0.7):" << c7 - c6 << "毫秒" << endl;
cout << " s (负载因子为默认值) :" << cc - c0 << "毫秒" << endl<<endl;
//在s 中查询0~1,000,000并统计时间
c0= clock();
for (unsigned int i = 0; i < 1000000; i++)
s.find(i);//不处理查询结果
cc = clock();
//在s1中查询0~1,000,000并统计时间
for (unsigned int i = 0; i < 1000000; i++)
s1.find(i);//不处理查询结果
c1 = clock();
for (unsigned int i = 0; i < 1000000; i++)
s2.find(i);//不处理查询结果
c2= clock();
for (unsigned int i = 0; i < 1000000; i++)
s3.find(i);//不处理查询结果
c3 = clock();
for (unsigned int i = 0; i < 1000000; i++)
s4.find(i);//不处理查询结果
c4 = clock();
for (unsigned int i = 0; i < 1000000; i++)
s5.find(i);//不处理查询结果
c5 = clock();
for (unsigned int i = 0; i < 1000000; i++)
s6.find(i);//不处理查询结果
c6 = clock();
for (unsigned int i = 0; i < 1000000; i++)
s7.find(i);//不处理查询结果
c7 = clock();
cout << "查询1百万数据:" << endl;
cout<<"s (负载因子默认为1) :" << cc - c0 << "毫秒" << endl;
cout << " s1(负载因子设为0.1):" << c1 - cc << "毫秒" << endl;
cout << " s2(负载因子设为0.2):" << c2 - c1 << "毫秒" << endl;
cout << " s3(负载因子设为0.3):" << c3 - c2 << "毫秒" << endl;
cout << " s4(负载因子设为0.4):" << c4 - c3 << "毫秒" << endl;
cout << " s5(负载因子设为0.5):" << c5 - c4 << "毫秒" << endl;
cout << " s6(负载因子设为0.6):" << c6 - c5 << "毫秒" << endl;
cout << " s7(负载因子设为0.7):" << c7 - c6 << "毫秒" << endl;
cout << "s默认的最大负载因子:" << s.max_load_factor() << endl;
cout << "s实际的负载因子:" << s.load_factor() << endl;
cout << "s1设置的最大负载因子:" << s1.max_load_factor() << endl;
cout << "s1实际的负载因子:" << s1.load_factor() << endl;
cout << "s2默认的最大负载因子:" << s2.max_load_factor() << endl;
cout << "s2实际的负载因子:" << s2.load_factor() << endl;
cout << "s3默认的最大负载因子:" << s3.max_load_factor() << endl;
cout << "s3实际的负载因子:" << s3.load_factor() << endl;
cout << "s4默认的最大负载因子:" << s4.max_load_factor() << endl;
cout << "s4实际的负载因子:" << s4.load_factor() << endl;
cout << "s5默认的最大负载因子:" << s5.max_load_factor() << endl;
cout << "s5实际的负载因子:" << s5.load_factor() << endl;
cout << "s6默认的最大负载因子:" << s6.max_load_factor() << endl;
cout << "s6实际的负载因子:" << s6.load_factor() << endl;
cout << "s7默认的最大负载因子:" << s7.max_load_factor() << endl;
cout << "s7实际的负载因子:" << s7.load_factor() << endl;
return 0;
}输出结果:
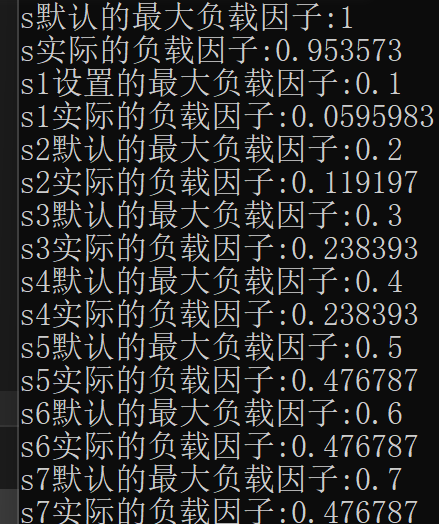
由结果我们得出:当修改默认的负载因子时:
对于插入的执行影响较大,当负载因子过小时,执行时间为最佳执行时间的两倍;
对于查找的执行效率影响较小;
使用默认的负载因子效率极为贴近最佳的执行效率