Spark概述

Spark-RDD概述
1.持久化与序列化的关系
在Spark中,持久化(Persistence)和序列化(Serialization)是两个关键概念,它们在RDD处理过程中起着重要作用,并且有一定的关联:
(1)持久化(Persistence)
-
持久化指的是将RDD的数据缓存在内存中,以便在后续操作中重复使用,而不必重新计算。

-
这对于需要多次使用同一数据集的情况非常有用,可以提高性能和效率。
-
Spark提供了多种持久化级别,可以选择将数据缓存在内存中、磁盘上或者在内存和磁盘之间进行平衡。
(2)序列化(Serialization)
- 序列化是将数据转换为字节流的过程,以便在网络上传输或者进行持久化存储。
- 反之,反序列化是将字节流转换回原始数据的过程。
- 在Spark中,由于RDD的数据需要在集群中的不同节点之间传输,因此需要对数据进行序列化和反序列化。
- 通常情况下,Spark使用Kryo或者Java序列化来实现对象的序列化。
(3)关系
-
持久化和序列化都涉及到数据的存储和传输,但是侧重点不同。
-
持久化是为了在RDD的生命周期内减少重复计算而将数据缓存在内存或者磁盘上,从而提高性能。
-
序列化是为了在集群中的不同节点之间传输数据或者进行持久化存储时,将数据转换为字节流,以便在网络上传输或者存储到磁盘中。
-
在Spark中,通常会将持久化和序列化结合起来使用,通过将RDD的数据持久化到内存或者磁盘上,并使用序列化来优化数据的传输和存储效率,从而提高整体的性能。
-
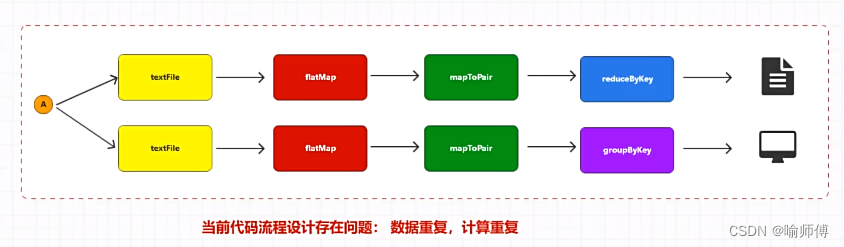
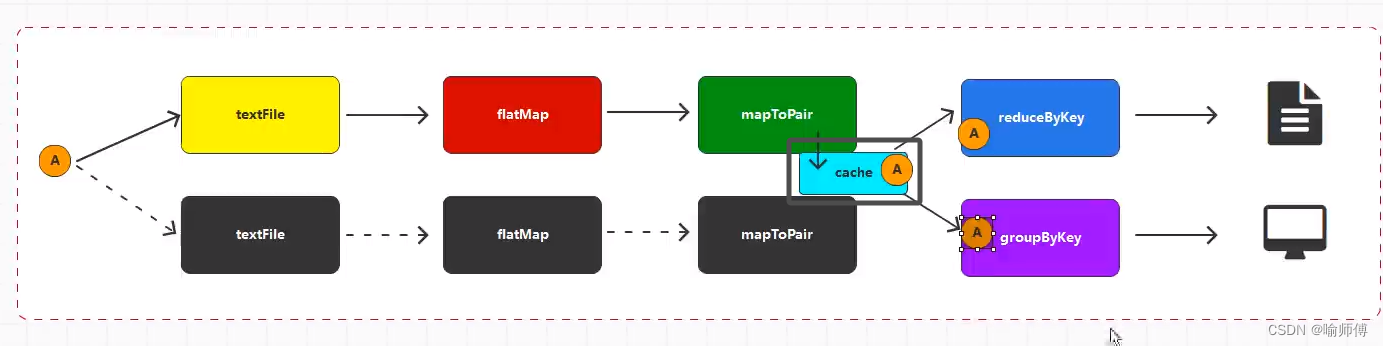
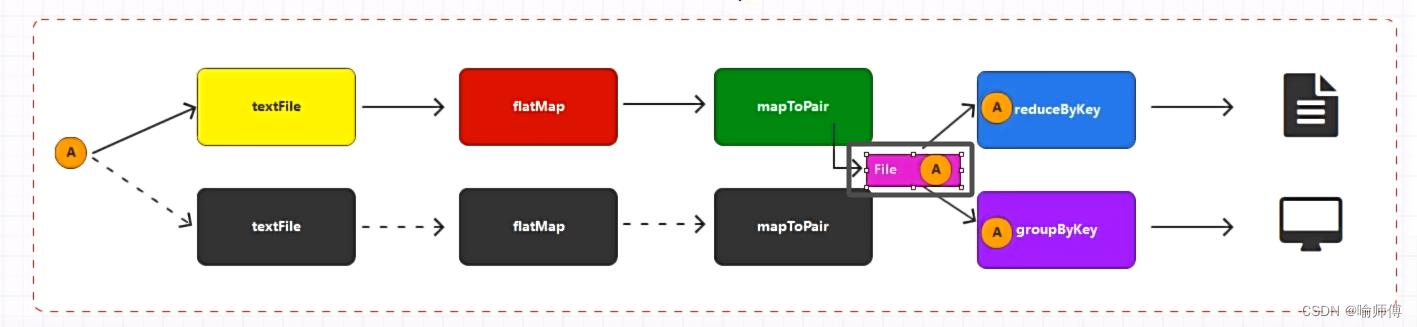
RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的
action算子时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
2.Spark持久化级别
当选择Spark中的持久化级别时,需要考虑多个因素,包括数据规模、内存和磁盘资源、性能需求以及容错性要求。
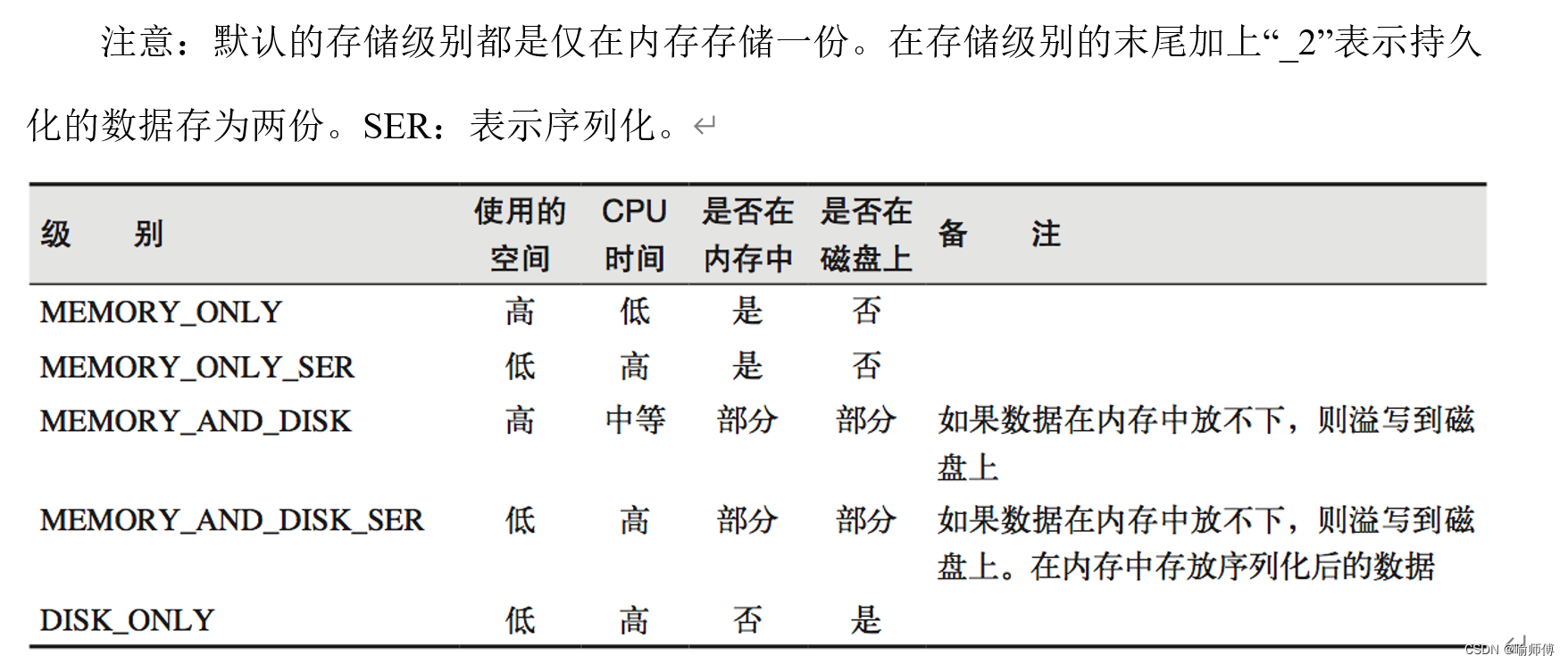
1.MEMORY_ONLY
- 数据存储在内存中,以对象的形式存在,不进行序列化。这意味着数据可以直接使用,速度较快。
- 适用于数据量较小且内存资源充足的情况。
- 由于数据不进行序列化,因此存储和读取速度很快,但是如果数据量过大超过了可用内存,会导致内存溢出。
2.MEMORY_ONLY_SER
- SER表示序列化
- 数据以序列化的形式存储在内存中,以节省内存空间。每次读取数据时,需要进行反序列化。
- 适用于数据量较大,但内存资源有限的情况。
- 序列化后的数据占用的内存空间较小,可以有效地减少内存压力,但相应地增加了序列化和反序列化的开销。
3.MEMORY_AND_DISK
- 数据首先尝试存储在内存中,如果内存不足,则会将部分数据存储到磁盘上,以保证数据的完整性。
- 适用于数据量较大,但内存资源不足以完全存储所有数据的情况。
- 尽管磁盘读取速度较慢,但可以有效地处理大规模数据。
4…MEMORY_AND_DISK_SER
- 类似于MEMORYANDDISK,但数据以序列化的形式存储在内存中,以节省内存空间。
- 需要时,可以将部分数据存储到磁盘上。
- 适用于数据量很大,内存资源有限的情况。通过序列化数据,可以减少内存占用,并允许更多的数据存储在内存中。
5.DISK_ONLY
- 数据完全存储在磁盘上,不存储在内存中。
- 这确保了数据的持久性,但会牺牲读取速度。
- 适用于数据量非常大,无法完全放入内存的情况。
- 尽管磁盘访问速度较慢,但可以保证数据的完整性和持久性。
6.MEMORY_ONLY_2, MEMORY_AND_DISK_2等
- 这些级别与前述相应的级别类似,但它们会将数据备份到不同的节点上,以提高容错性。
- 在存储级别的末尾加上“_2”表示持久化的数据存为两份。
- 备份分区的副本使得在某个节点上数据丢失时可以从备份节点恢复数据。
- 适用于对数据可靠性有较高要求的情况,通过备份可以提高容错性。
3.RDD CheckPoint检查点
RDD Checkpoint(检查点)是一种机制,用于将RDD的中间结果持久化到可靠的存储介质(通常是分布式文件系统),以便在RDD需要重新计算时,可以从检查点处重新加载数据,而不必重新执行整个RDD的计算链。这在需要对RDD进行多次计算或容错恢复时非常有用。

1.工作原理:
-
RDD Checkpoint通过将RDD的数据写入分布式文件系统(如HDFS)来实现。

-
一旦RDD被标记为Checkpoint,Spark会在计算RDD时,将RDD的数据写入到指定的分布式文件系统中,并将该RDD的依赖链截断,使其不再依赖父RDD,从而节省内存空间并提高容错性。

-
当需要重新计算RDD时,Spark会从Checkpoint处读取数据,而不是重新执行RDD的计算链。
-
这大大减少了计算时间,并且由于数据已经持久化,因此可以保证容错性。

2.使用方法:
-
要对RDD进行Checkpoint,首先需要调用RDD的checkpoint()方法,将其标记为Checkpoint。

-
然后,需要调用sc.setCheckpointDir()方法设置Checkpoint的存储目录。
-
在Spark应用程序中,当RDD需要Checkpoint时,可以调用rdd.checkpoint()方法。
3.适用场景:
- RDD Checkpoint适用于那些需要多次使用同一数据集进行计算的场景,以及对容错性要求较高的场景。
- 例如,当某个RDD需要被多个Action操作使用,或者当需要对RDD进行缓存但内存不足时,可以考虑使用Checkpoint。
4.注意事项:
-
RDD Checkpoint会增加存储开销,因为需要将RDD的数据写入到分布式文件系统中。
-
Checkpoint的存储目录应该设置在可靠的分布式文件系统上,并确保有足够的存储空间。
-
RDD Checkpoint应该谨慎使用,因为它会增加IO开销,并且在某些情况下可能会降低性能。
5. 缓存和检查点区别
-
(1)Cache缓存只是将数据保存起来,不切断血缘依赖。Checkpoint检查点切断血缘依赖。
-
(2)Cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint的数据通常存储在HDFS等容错、高可用的文件系统,可靠性高。
-
(3)建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD。
-
(4)如果使用完了缓存,可以通过unpersist()方法释放缓存。