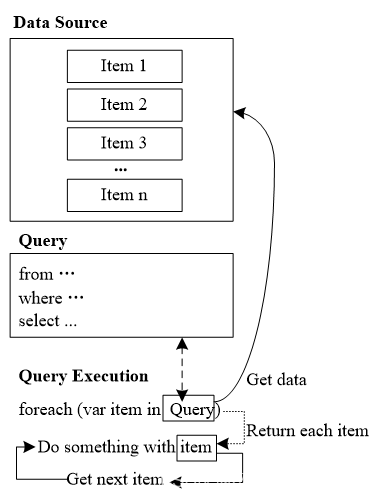
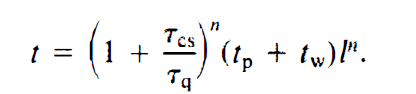Linux处理Packets主逻辑
系统接受数据包的过程
- 当网卡收到第一个包时候,通过DMA把这个包发送给接受队列(rx)
- 系统通过中断的方式通知新数据包的到来,同时也需要把数据包传递给内核的buffer(每个包一个buffer,sk_buff struct).一个数据包到来会触发多次的中断,内核处理完毕后,数据包再次传输到用户态空间
瓶颈分析
- 内核在处理很多包的时候,会消耗非常多的资源,同时也会触发很多次中断,这会严重影响系统处理数据包的性能
- 内核的sk_buff的设计是为了内核协议栈兼容多个协议。因此所有的协议的元数据都会存储在sk_ bff中,这对于包的处理很多协议是不必须要的。
- context上下文切换,当一个用户态app需要发动或者接受数据包时候,会调用系统调用(recv/send),这会导致app进程陷入到内核态,引起了上下文切换,这样会消耗比较多的系统资源
NAPI 解决的问题
- 为了解决上面的问题。在kernel 2.6以后引入的NAPI,它能够每个包的请求不是每次都触发中断,而是多个包到了以后在触发中断,减少中断的次数
- 当网卡在中断模式下工作,一旦数据包到达网卡,它自身会注册一个poll queue和禁用中断,内核周期性检查queue中即将处理的数据包,一旦数据包被处理,网卡会删除queue中的数据包,然后再次触发中断。
DPDK工作流程
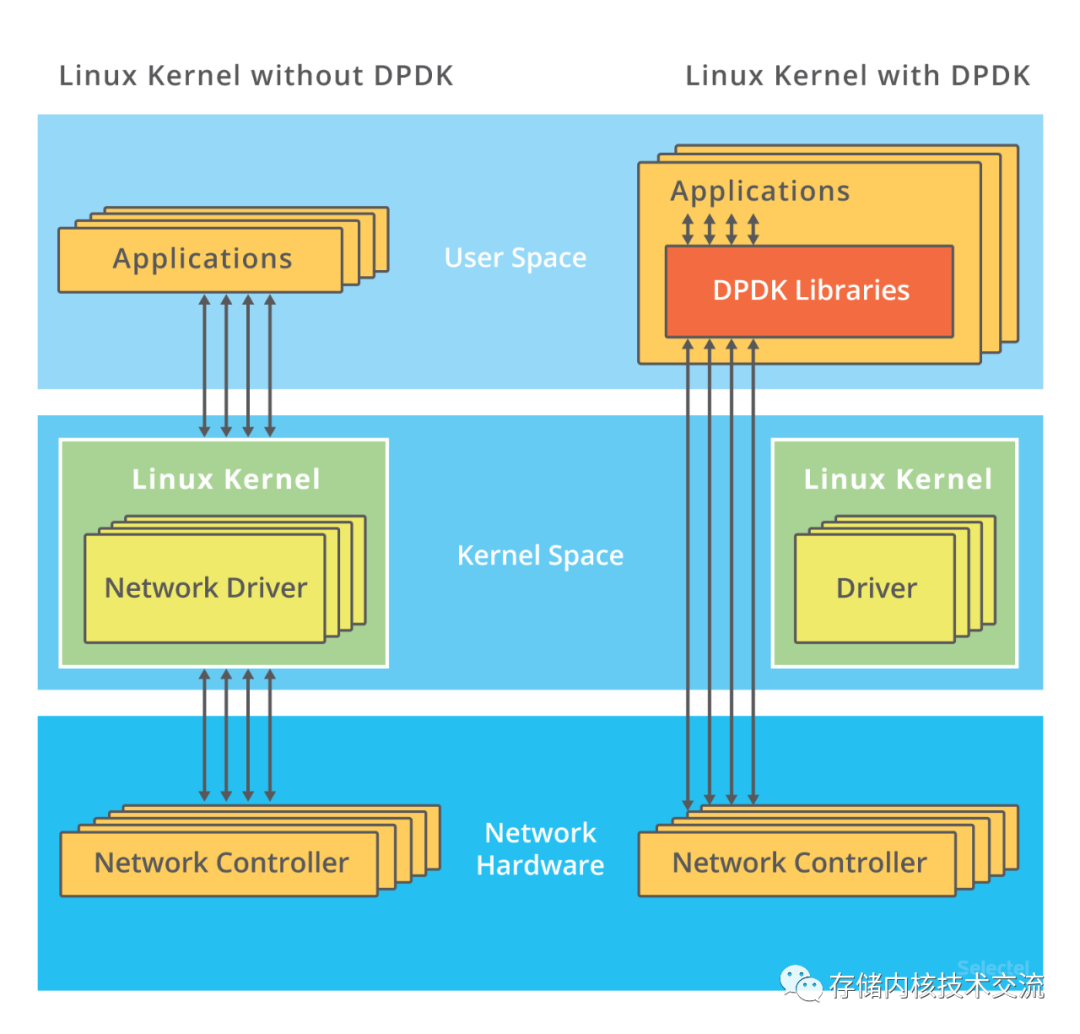
- 上图中的左边是传统的数据包处理过程,右边是DPDK数据包处理的过程。内核中每个driver会bind和unbind多个文件可以通过如下命令查看.对于驱动中的unbind 一个设备,设备总线的编号会写入到unbind 文件中。类似的对于驱动中bind一个设备,对应的总线编号会写入到bind文件中。DPDK会通过命令来知道哪些ports会被vfio_pci,igb_uio或者uio_pci_generic驱动管理。这些驱动在用户态直接和网卡设备交互,这样网卡设备就可以直接和DPDK进行交互。
# ls /sys/bus/pci/drivers/mlx4_core
bind module new_id remove_id uevent unbind
复制
- DPDK需要配置大页,DPDK处理包需要申请内存,这些大页内存被用户DPDK中包的处理,这个和传统的使用DMA处理数据包的用途相同。
DPDK收发数据包的逻辑
- 到达的数据包会被放到ring buffer中,上层的app周期性检查buffer中的新的数据包
- 如果ring buffer中有新的数据包描述符,上层app会在DPDK内存池中分配数据包的缓冲区。
- 如果ring buffer中没有任何数据包,上层app会网卡设备排队到DPDK,再次触发Ring
DPDK 高性能数据结构支撑
EAL: Environment Abstraction
- EAL是DPDK的环境抽象层的库,它的作用是在特殊硬件环境和系统中工作的可编程的工具,在DPDK中EAL实现是在rte_eal的目录中
rte_lcore.h - 管理处理器cores和sockets
rte_memory.h - 内存管理
rte_pci.h - 提供访问pci的地址空间接口
rte_debug.h - 提供trace和debug的函数
rte_interrupts.h - 中断处理
复制
Managing Queues: rte_ring
- 当网络数据包被网卡接受后,会发送给ring buffer.DPDK的ring buffer是充当接受队列。接受到的数据在DPDK中发送到ring buffer,ring buffer的实现是在rte_ring中。rtr_ring是从FreeBSD ring buffer二次开发而来。rte_ring 基于lock free模式的FIFO实现,ring buffer是一个对象数组指针,指针分为4类分别是:pro_tail/prod_head/cons_tail/cons_head
- prods是生产者的简称,cons是消费者的简称。生产者的数据是给点时间由进程写数据到buffer,消费者的数据是进程从buffer中移除。tail是在环形缓冲区上发生写操作位置,head是在给定时间读取缓冲区的位置
- 这样设计会到来很多好处,首先数据写入到buffer非常快,每次从queue中add或者remove大量对象,cache miss情况会发生很少。唯一的弊端是ring buffer是固定大小,一定初始化就不能动态更改。
Memory Management: rte_mempool
- DPDK强烈推荐设置2M的大页内存,这些2M大页会被合并在多个segment,然后划分到多个zone中。这些内存对象是被上层app或者DPDK中queues、packets buffer使用。这些内存对象是通过rte_memory创建,同时采用了对齐技术提供更高的性能.
- Posix提供mlock的系统调用是为了让virtual page(默认是4K)有对应的physical page对应(物理内存中page),实际这仅仅是为了保证虚拟内存不会被swap出去,但是virtual page对应的physical page会改变。但是使用hugepages(默认大页大小有2M/8M/1G),内核对于hugepages不同于常规的4K page.操作系统从来不会去改变通过hugepages申请的virtual page(虚拟内存页面)对应physical page应(物理内存页面)位置。
- 为了防止有瓶颈,每个cpu core会设置一个memory pool的local cache.
Buffer Management: rte_mbuf
- 在linux 网络协议栈中所有的数据包都是通过sk_buff数据结构表示,而在DPDK中数据包是用数据结构rte_mbu.h中的ret_mbuf结构表示。相比sk_buff,rte_mbuf相对会比较小。
DPDK高性能的原因总结
- Processor affinity,通过每个CPU CORE一个进程以达到进程的亲和性
- Huge pages,大页技术,增加TLB的命中率
- UIO,用户态直接和网络驱动进行交互,避免了用户态到内核态拷贝
- Polling,摒弃传统中断的方式采用Polling方式,减少中断的开销
- Lockless synchronization,避免等待
- Batch packets handing,批量包处理,提供更高包处理的吞吐
原文链接:https://cloud.tencent.com/developer/article/2074545
(免费订阅,永久学习)学习地址: Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家-学习视频教程-腾讯课堂
更多DPDK相关学习资料有需要的可以自行报名学习,免费订阅,永久学习,或点击这里加qun免费
领取,关注我持续更新哦! !