©PaperWeekly 原创 · 作者 | 许皓天

导读
LLM 在 NLP 以及 ai-agent 等场景展现出了巨大的应用潜力,并且在复杂推理任务如 math 等任务极大提升了模型性能。
近期,基于 llama2 的 RFT [1] 以及 wizard-math [2] 等通过 rejection-sampling、RLEIF(从 Evol-Instruct 反馈中强化学习(RLEIF)等提升了开源模型的数学能力。比如,wizard-math 使用 Evol-instruct 构造更多量的 SFT 数据,并且引入基于 chatgpt 的过程打分、结果打分的 reward 建模和 PPO 等,使得开源模型能够与闭源模型如 chatgpt 等相当。
然而,这些方法主要通过构造更多的数据实现效果的提升。我们认为,底座模型已经具备一定的推理能力,但缺少有效的采样方法。传统采样方法如 greedy-decoding、beam-search 等均是根据当前 token 的输出概率进行采样,缺少全局评估反馈。这种局部 token 采样的方法,极大限制了模型性能。
为此,我们提出了基于 Residual-EBM [3] 和 MCTS [5] 的方法,在微调好的模型上,使用 EBM 和 MCTS 采样,初步实验显示,该方法能极大提升微调好的模型的数学能力,而不需要使用额外数据重新训练或者 RLHF 等对齐方法。

Residual-EBM and PPO
Residual-EBM [3] 构建了一个基于自回归模型的能量语言模型,可以有效降低 exposure bias。同时,[4] 也指出,PPO+KL-divergence 是边际分布的变分近似,而其最优解为:
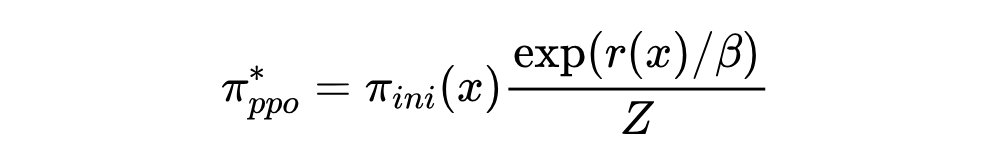
这里,我们可以看到最优解与 Residual-EBM [3] 有着类似形式:
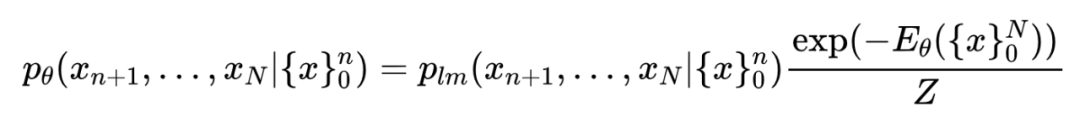
这里, 为输入序列如 prompt, 为输出序列。我们可以看到,Residual-EBM 等价于自回归语言模型与句子级别的能量模型的乘积。而 通过全局能量模型对输出句子打分,从而降低模型的 exposure bias。

MCTS
MCTS [5] 是一种解决高维推理问题强有力的工具,在诸如 alpha-go、游戏 ai 等均有应用。近期,TOT [6] 等工作提出了基于树搜索的 COT 算法,提升复杂推理问题的解决能力。这些方法通过使用 BFS、DFS 等搜索算法实现 exploration,并且使用 chatgpt 等接口对中间过程进行打分。[7] 也提出了类似的算法但使用不同的排序函数,实现更高的推理能力。
然而,这些方法均使用了确定性的探索方法如 BFS 等,缺少高效探索。同时,路径打分和排序都需要较为强大的模型如 chatgpt 进行评估。
相比之前的方法,MCTS 能够具备更好的复杂空间探索能力,是解决复杂决策或者组合问题的 SOTA。然而,为了应用 MCTS,依然需要训练一个 task-specific的打分模型,对潜在的决策路径打分。[7][8][9] 均提出了不同的路径打分模型。这些路径打分模型依赖一定量的标注数据,在 sample-then-rank 的设置下,[8][9] 的打分模型并没有对结果带来显著提升。也从一定程度说明,这些打分函数很难很好的评估输出路径。

NCE
从 Residual-EBM 以及 MCTS 的基本介绍我们可以看到,我们可以使用能量函数可以对完整句子打分并作为 MCTS 的路径评分函数。为了优化能量模型,我们使用 Noise Contrastive Estimation(NCE)[10] 优化。得益于 Residual-EBM 的形式,最终的优化目标函数如下:
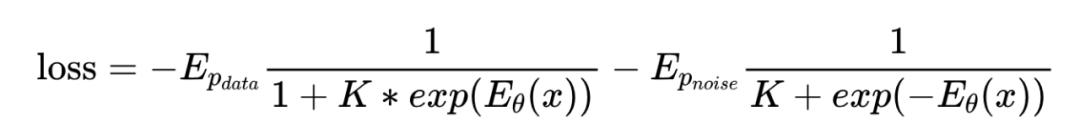
具体推导过程可以参考 [10]。这里,K 为负样本数量。

我们的方法
5.1 能量模型参数估计
我们将训练好的 SFT 模型作为基础模型,并使用 Residual-EBM 的形式得到最终的采样模型。为了高效训练能量模型,我们使用 NCE 算法估计(这里,隐含了归一化系数为常数的假设。实际中不一定成立)。
使用 NCE 优化能量模型,我们需要从数据分布和 noise 分布分别采样样本。数据分布为 SFT 训练集。noise 分布为 SFT 模型 [11]。noise 分布可以使用 infilling、reorder 等不同的生成模型建模。使用 SFT 模型是最为简单直接的方案。
NCE 的负样本为从 SFT 模型采样的样本集合。我们考虑了 2 种不同的负样本生成方法。
给定 prompt,多次随机采样。过滤错误答案、过程高度相似的样本 [1]。为了节约采样成本,我们使用 [1] 中提供的样本作为负样本。记作 RFT
给定 prompt 和 suboutput(训练集正确推理路径的前 N 步),生成后续的推理过程。将 suboutput 拼接生成的推理路径作为负样本。记作 suboutput
我们使用 Deberta-large 作为能量模型在 RFT、RFT&suboutput 两个负样本上面完成训练。
5.2 基于MCTS的采样
MCTS 是解决组合问题强有力的武器。然而,文本生成问题,每一个 step 需要对 大小(这里, 是词表大小)的 action 空间采样。极大降低了采样效率。为此,我们将生成的句子作为 MCTS 中的节点,有效降低了 MCTS 的采样成本 [9]。 下图为 MCTS的基本算法流程。具体原理可参考 [5]。
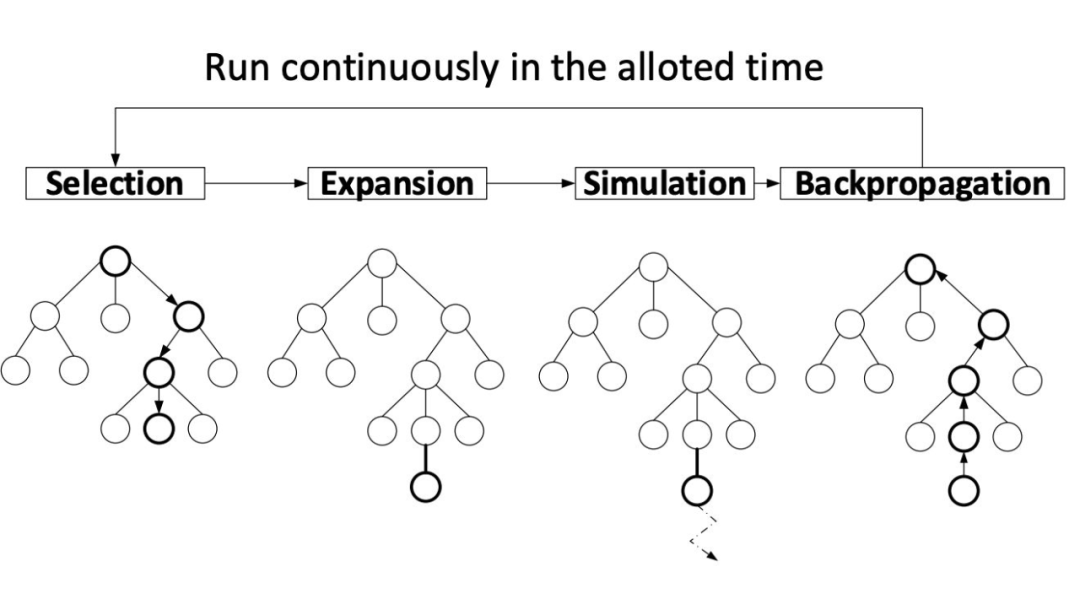
▲ MCTS算法流程

实验结果
我们基于 GSM-8k 以及 LLama2-7b 作为我们的实验数据和基础模型。在 gsm-8k 数据 SFT 模型的基础上,探讨了不同采样方法的效果。评价指标为答案的 acc。我们主要参考并修改了 [9][15][16] 的开源代码。
6.1 基于Residual-EBM的重要性采样
这里,我们对比了 greedy-decoding、self-consistency majority-voting 以及基于同一批采样数据的 Residual-EBM 重要性采样(类 softmax 排序)结果。
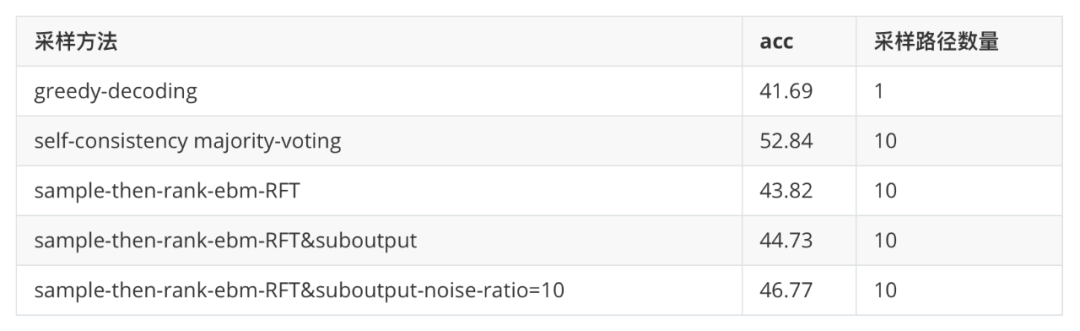
从上表可以看到,基于能量模型的采样 [3] 可以有效提升推理效果。pass@1 的 acc 从 41.69 提升到 46.77。基于不同负样本和 noise-ratio 的 NCE 训练也对采样结果有较大的影响。
基于 RFT 的负样本比 RFT+suboutput 的效果更差一些。suboutput 生成的数据与原始数据有更高的重合度,增加了能量模型的学习难度。
当我们增加负样本后(大概一条训练数据样本有 10 条负样本)。noise-ratio 的 NCE 具有更好的判别效果。
6.2 基于MCTS的采样
为了进一步验证 MCTS 的采样效果,我们使用 ebm-RFT&suboutput-noise-ratio=10 的能量模型作为打分模型,对 MCTS-rollout 的样本进行评估。并根据 node-visit 和 node-reward 的最大值(如先看 node-visit 的最大值,如果有多个,则选择 node-reward 最大的)选择 node 作为当前 step 的决策输出路径。最终,我们仅输出一条路径作为最终的推理路径(但 MCTS 迭代会产生很多中间路径)。
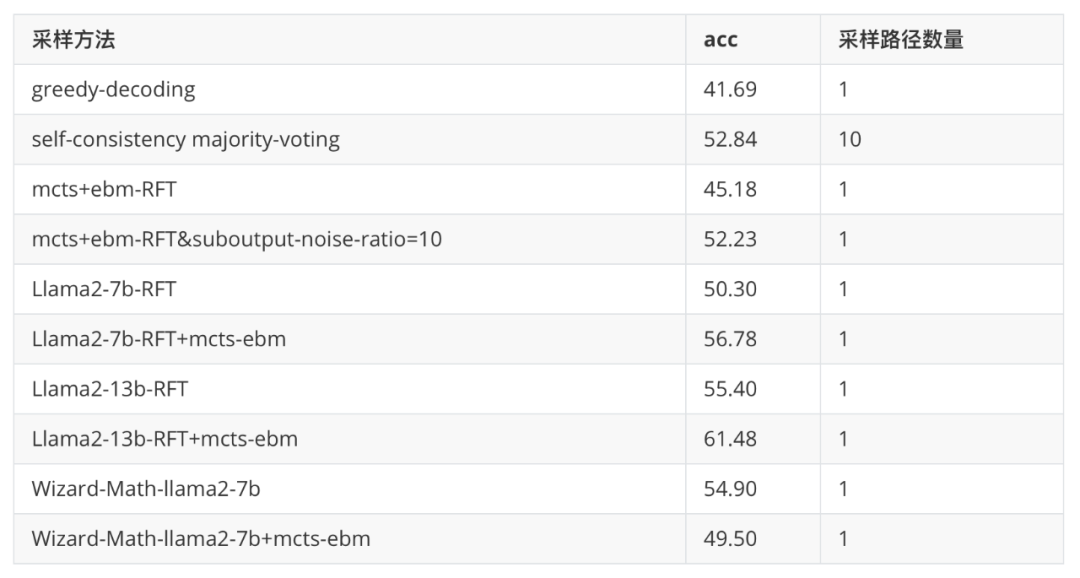
从上表可以看到,基于 MCTS+EBM 打分的方法,能够将 pass@1 只有 41.69 的模型提升到 52.23,提升了 10 个点以上。媲美使用 RFT、RLEIF 等使用更多 SFT 数据或者 RL 对齐的方法。也验证了弱模型也能通过更合理的采样方法实现更高的推理效果。从而,在微调好的模型基础上提升模型的推理效果。
基于 RFT 的 EBM 能量模型的 MCTS 采样,由于输出只采样了答案正确的路径,对于 suboutput 的路径判别能力较弱,相比原始的 greedy-decoding、sample-then-rank 有一定提升,但远远差于使用加入 suboutput 的 EBM+MCTS 的效果,也一定程度说明路径打分模型需要更好的适配采样过程。
为了验证 MCTS-EBM 是否能迁移到其它 SFT 模型,我们基于 RFT-7b、RFT-13b 以及 wizard-math-7b 分别应用 mcts+ebm。从上表可以看出,RFT-7b 和 RFT-13b 均是在原始 gsm8k 数据集训练得到,与能量函数的训练数据分布一致。在这两个模型上,我们也能看到较为一致的提升,即 RFT-7b 从 50.30 提升到 56.78,RFT-13b 从 55.40 提升到 61.46。
而 wizard-math 由于引入了强化学习对齐、过程 reward 等等,导致 wizard-math 的训练数据分布与 gsm8k 的数据分布相差较大,所以,我们也能看到,在 wizard-math 上加 mcts-ebm 的采样效果下降较为明显,也间接表明 energy-function 即使在同一个任务但不同的数据格式上的迁移能力会比较弱,未来,需要探索 energy-function 的泛化能力提升方案如使用更多样的 noise-distribution、noise 构造方法等生成更多样的 noise-sample。
MCTS-EBM 在不同的基础 带来的提升不一致,比如底座越弱,带来的提升越明显(如 sft-greedy-decoding 从 41.69 提升到 52.23),而更强的底座如 RFT-7b, RFT-13b 带来的提升越弱,RFT-7b 从 50.30 提升到 56.78,而 RFT-13b 只能从 55.40 提升到 61.48。

总结
本文提出了基于 Residual-EBM 和 MCTS 的采样方法,不需要重新训练模型的条件下,能够提升 GSM-8k 模型的推理效果,将 greedy-decoding 只有 41.69 的 pass@1 acc 提升到 52.23,从而初步验证了“通过更好的采样方法,可以实现弱鸡模型能力的巨大提升”。
本文提出的能量模型训练可以扩展到其它应用场景,通过 SFT/infilling 等不同的方法完成 noise-distribution 的模型训练和采样,从而实现无监督的打分模型训练,降低打分模型的构建成本。同时,该方法构建的打分模型在 sample-then-rank 的设置下,也具有一定的效果提升。
未来,我们也会探讨能量模型在不同数据集、不同任务的迁移能力。其它材料可参考 [12][13][14]。
本文初步验证了 Residual-EBM+MCTS 在不训练模型的条件下,可以极大提升模型的推理效果。然而,MCTS 的采样成本相比直接采样要高很多,从而降低了实际应用价值。另外,我们通过使用 "tiny" 能量模型(deberta-large 相比 llama2-7b,前者已然属于 tiny 模型)打分,也能帮助大模型实现更好的效果。

参考文献
[1] SCALING RELATIONSHIP ON LEARNING MATHEMATICAL REASONING WITH LARGE LANGUAGE MODELS
[2] WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct
[3] Residual Energy-Based Models for Text Generation
[4] RL with KL penalties is better viewed as Bayesian inference
[5] Monte Carlo Tree Search: A Review of Recent Modifications and Applications
[6] Deliberate Problem Solving with Large Language Models
[7] Large Language Model as Autonomous Decision Maker
[8] Discriminator-Guided Multi-step Reasoning with Language Models
[9] Solving Math Word Problems via Cooperative Reasoning induced Language Models
[10] https://leimao.github.io/article/Noise-Contrastive-Estimation/
[11] Joint Energy-based Model Training for Better Calibrated Natural Language Understanding Models
[12] https://zhuanlan.zhihu.com/p/648136217
[13] https://zhuanlan.zhihu.com/p/645388566
[14] https://zhuanlan.zhihu.com/p/650438958
[15] https://github.com/NohTow/PPL-MCTS
[16] https://github.com/TianHongZXY/CoRe
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·