前言
仅记录学习过程,有问题欢迎讨论
大模型的演化:
ElMO : 类似双向lstm 结果和词向量拼接 预训练鼻祖
GPT :使用了Transformer 模型 开始使用Token (发现预训练的作用)
Bert:认为双向比单向好 MLM(双向) 优于 LTR
Ernie-baidu:中文强于bert mask训练改为词组而非token
GPT2:继续使用Transformer 使用单向 more data
UNILM:使用Transformer + Mask attention 所以双向和单向都可以训
Transformer-XL & XLNet: 循环机制(利用attention|)解决bert输入长度限制(max_len = 512)
Roberta: bert变体 ,more data/去掉NSP/长样本/动态改变Mask位置 效果更好
Span bert:去掉NSP 随机mask连续token SBO
ALBert: 试图解决bert模型过大的问题(因式分解 vh = vE + E*h) 想办法减少参数( 跨层参数共享)
T5:Text-to-Text Transfer Transformer:Seq2Seq理论解决一切NLP问题
GPT3:参数量1750亿 目标:像人一样学习
总结
使用类bert形式训练 还是需要一个线性层配合任务改变 使用还是不便
更加理想的方式,使用文本来描述任务答案,训练方式统一(text-text),推理方式统一(无需解码结果 index-result)
Instruct GPT:
SFT训练 从续写到回答 输入的x 为问题 x+y为答案
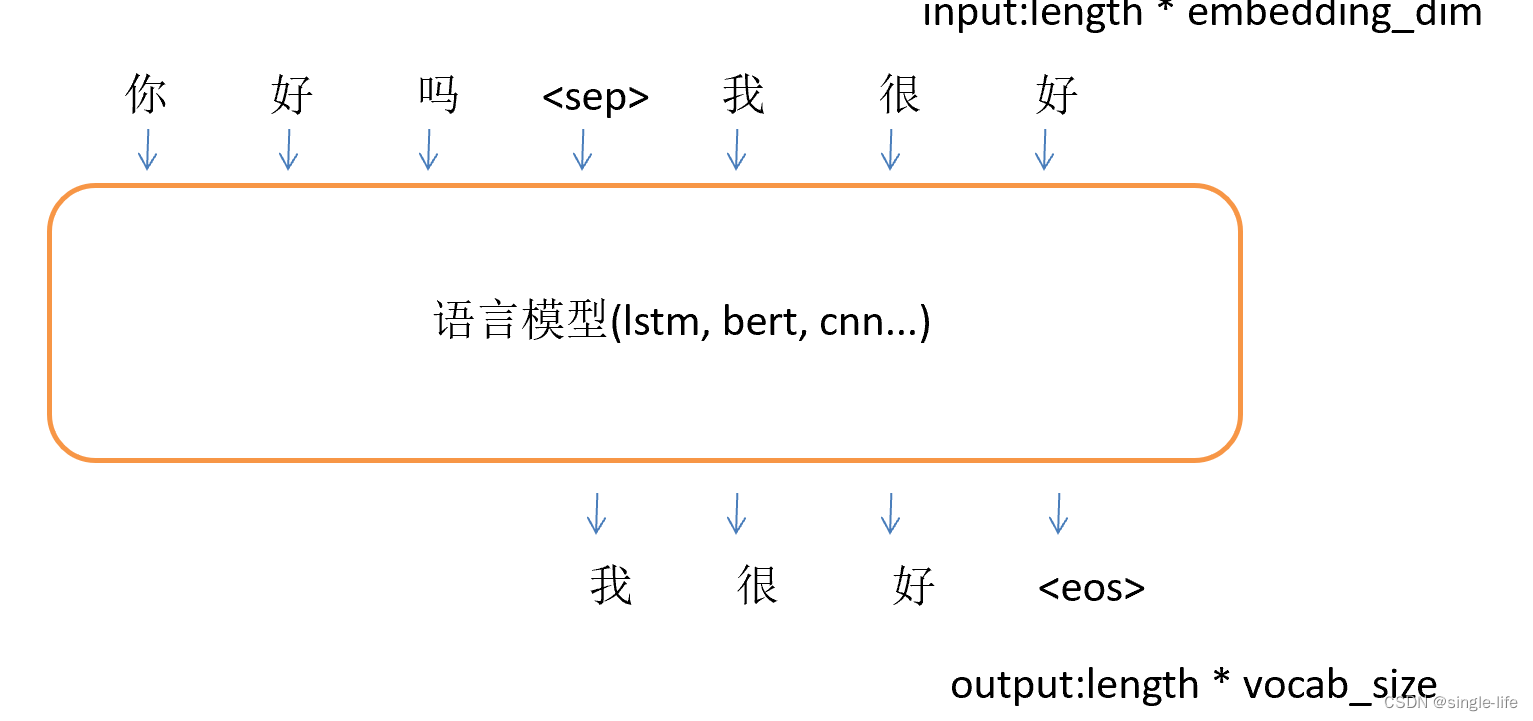
RW训练(判断答案好坏的模型):强化学习 一个问题对应多个答案,由人工排序打分 y(w)=更好的答案 y(L) =差的 (类似于loss)
RL训练 在SFT上发展,但期望和SFT训练后结果分布相差不大 目标是使得RW model最大
In context learning:
训练内容直接在对话中产生,学习后输出内容(模型权重没变)
Z-s o-s f-s (zero/one/few shot) 问题中是否包含样例(和prompt)
提示工程:
- 提示词(prompt) 提示词是模型在训练过程中学习到的,模型在训练过程中会学习到一些通用的模式,这些模式可以作为提示词来指导模型的训练。
- 复杂任务可以拆解为多个步骤一步一训练,训练完成后再组合起来
代码
使用bert实现自回归训练模型,
添加mask attention 来实现
标题/内容任务,也是自回归模型,
对于输入输出长度不一致的问题,可以仔细看看怎么实现的,mask怎么实现的(采用mask使得x,y相互不可见)
# coding:utf8
import json
import torch
import torch.nn as nn
import numpy as np
import math
import random
import os
import re
from torch.utils.data import DataLoader
from transformers import BertModel, BertTokenizer
"""
基于pytorch的LSTM语言模型
使用SFT训练 Q&A
"""
class LanguageModel(nn.Module):
def __init__(self, input_dim, vocab_size):
super(LanguageModel, self).__init__()
# self.embedding = nn.Embedding(len(vocab), input_dim)
# self.layer = nn.LSTM(input_dim, input_dim, num_layers=1, batch_first=True)
self.bert = BertModel.from_pretrained(r"D:\NLP\video\第六周\bert-base-chinese", return_dict=False)
self.classify = nn.Linear(input_dim, vocab_size)
# self.dropout = nn.Dropout(0.1)
self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1)
# 当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None, mask=None):
# x = self.embedding(x) # output shape:(batch_size, sen_len, input_dim)
# 使用mask来防止提前预知结果
if y is not None:
x, _ = self.bert(x, attention_mask=mask)
y_pred = self.classify(x)
return self.loss(y_pred.view(-1, y_pred.shape[-1]), y.view(-1))
else:
x, _ = self.bert(x)
y_pred = self.classify(x)
return torch.softmax(y_pred, dim=-1)
# 加载语料
def load_corpus(path):
title_list = []
content_list = []
with open(path, encoding="utf8") as f:
for i, line in enumerate(f):
line = json.loads(line)
title_list.append(line["title"])
content_list.append(line["content"])
return [title_list, content_list]
# 建立数据集
# sample_length 输入需要的样本数量。需要多少生成多少
# vocab 词表
# window_size 样本长度
# corpus 语料字符串
def build_dataset(sample_length, tokenizer, corpus, max_len, valid_flag=False):
# dataset_x = []
# dataset_y = []
# dataset_mask = []
dataset = []
for i in range(sample_length):
dataiter = build_sample(tokenizer, corpus, max_len, valid_flag)
# dataset_x.append(x)
# dataset_y.append(y)
# dataset_mask.append(mask)
dataset.append(dataiter)
return DataLoader(dataset, batch_size=32, shuffle=True, num_workers=0)
# 构建一个的mask
def create_mask(question_size, answer_size):
len_s1 = question_size + 2 # cls + sep
len_s2 = answer_size + 1 # sep
# 创建掩码张量
mask = torch.ones(len_s1 + len_s2, len_s1 + len_s2)
# 遍历s1的每个token
for i in range(len_s1):
# s1的当前token不能看到s2的任何token
mask[i, len_s1:] = 0
# 遍历s2的每个token
for i in range(len_s2):
# s2的当前token不能看到后面的s2 token
mask[len_s1 + i, len_s1 + i + 1:] = 0
return mask
def pad_mask(tensor, target_shape):
# 获取输入张量和目标形状的长宽
height, width = tensor.shape
target_height, target_width = target_shape
# 创建一个全零张量,形状为目标形状
result = torch.zeros(target_shape, dtype=tensor.dtype, device=tensor.device)
# 计算需要填充或截断的区域
h_start = 0
w_start = 0
h_end = min(height, target_height)
w_end = min(width, target_width)
# 将原始张量对应的部分填充到全零张量中
result[h_start:h_end, w_start:w_end] = tensor[:h_end - h_start, :w_end - w_start]
return result
def build_sample(tokenizer, corpus, max_len, valid_flag=False):
x_list, y_list = corpus
# 随机获取一组样本:
random_index = random.randint(0, len(x_list) - 1)
x = x_list[random_index]
if valid_flag:
print(x)
y = y_list[random_index]
# 中文的文本转化为tokenizer的id 不添加【CLS】
input_ids_x = tokenizer.encode(x, add_special_tokens=False)
input_ids_y = tokenizer.encode(y, add_special_tokens=False)
pad_x = [tokenizer.cls_token_id] + input_ids_x + [tokenizer.sep_token_id] + input_ids_y
pad_y = len(input_ids_x) * [-1] + [tokenizer.sep_token_id] + input_ids_y
# 自己对长度做处理 padding 到 max_len
pad_x = pad_x[:max_len] + [0] * (max_len - len(pad_x))
pad_y = pad_y[:max_len] + [0] * (max_len - len(pad_y))
# 构建一个的mask矩阵,让prompt内可以交互,answer中上下文之间没有交互
mask = create_mask(len(input_ids_x), len(input_ids_y))
mask = pad_mask(mask, (max_len, max_len))
return [torch.LongTensor(pad_x), torch.LongTensor(pad_y), mask]
# 建立模型
def build_model(vocab_size, char_dim):
model = LanguageModel(char_dim, vocab_size)
return model
# 采样方式
def sampling_strategy(prob_distribution):
if random.random() > 0.1:
strategy = "greedy"
else:
strategy = "sampling"
if strategy == "greedy":
return int(torch.argmax(prob_distribution))
elif strategy == "sampling":
prob_distribution = prob_distribution.cpu().numpy()
return np.random.choice(list(range(len(prob_distribution))), p=prob_distribution)
def evaluate(openings, model, tokenizer, corpus):
model.eval()
# 转化为input_id
openings = tokenizer.encode(openings)
# 控制生成的字数
with torch.no_grad():
while len(openings) <= 50:
x = torch.LongTensor([openings])
if torch.cuda.is_available():
x = x.cuda()
# 因为有了mask 所以输入就是输出,看最后一个字的预测
y_pred = model(x)[0][-1]
index = sampling_strategy(y_pred)
openings.append(index)
return tokenizer.decode(openings)
def train(corpus_path, save_weight=True):
epoch_num = 15 # 训练轮数
batch_size = 32 # 每次训练样本个数
train_sample = 1000 # 每轮训练总共训练的样本总数
char_dim = 768 # 每个字的维度
tokenizer = BertTokenizer.from_pretrained(r"D:\NLP\video\第六周\bert-base-chinese")
vocab_size = 21128
max_len = 50
corpus = load_corpus(corpus_path) # 加载语料
model = build_model(vocab_size, char_dim) # 建立模型
if torch.cuda.is_available():
model = model.cuda()
optim = torch.optim.Adam(model.parameters(), lr=0.001) # 建立优化器
# data
dataset = build_dataset(train_sample, tokenizer, corpus, max_len)
print("文本词表模型加载完毕,开始训练")
for epoch in range(epoch_num):
model.train()
watch_loss = []
for x, y, mask in dataset: # 构建一组训练样本
if torch.cuda.is_available():
x, y, mask = x.cuda(), y.cuda(), mask.cuda()
optim.zero_grad() # 梯度归零
loss = model(x, y, mask) # 计算loss
loss.backward() # 计算梯度
optim.step() # 更新权重
watch_loss.append(loss.item())
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
result1 = evaluate("阿根廷歹徒抢服装尺码不对拿回店里换", model, tokenizer, corpus)
print(result1)
if not save_weight:
return
else:
base_name = os.path.basename(corpus_path).replace("txt", "pth")
model_path = os.path.join("model", base_name)
torch.save(model.state_dict(), model_path)
return
if __name__ == "__main__":
train("sample_data.json", False)
# mask = torch.tril(torch.ones(4, 4)).unsqueeze(0).unsqueeze(0)
# print(mask)





![SpringMVC源码解读[1] -Spring MVC 环境搭建](https://img-blog.csdnimg.cn/direct/41f2bce2f3f64511bc68f17626e573ee.png)

![[图解]产品经理创新模式01物流变成信息流](https://img-blog.csdnimg.cn/direct/f870890de5c34f78b01c9c35a9f70d29.png)