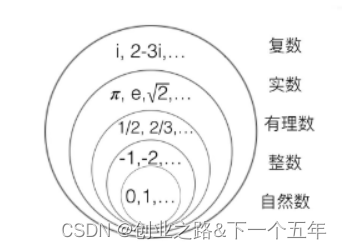
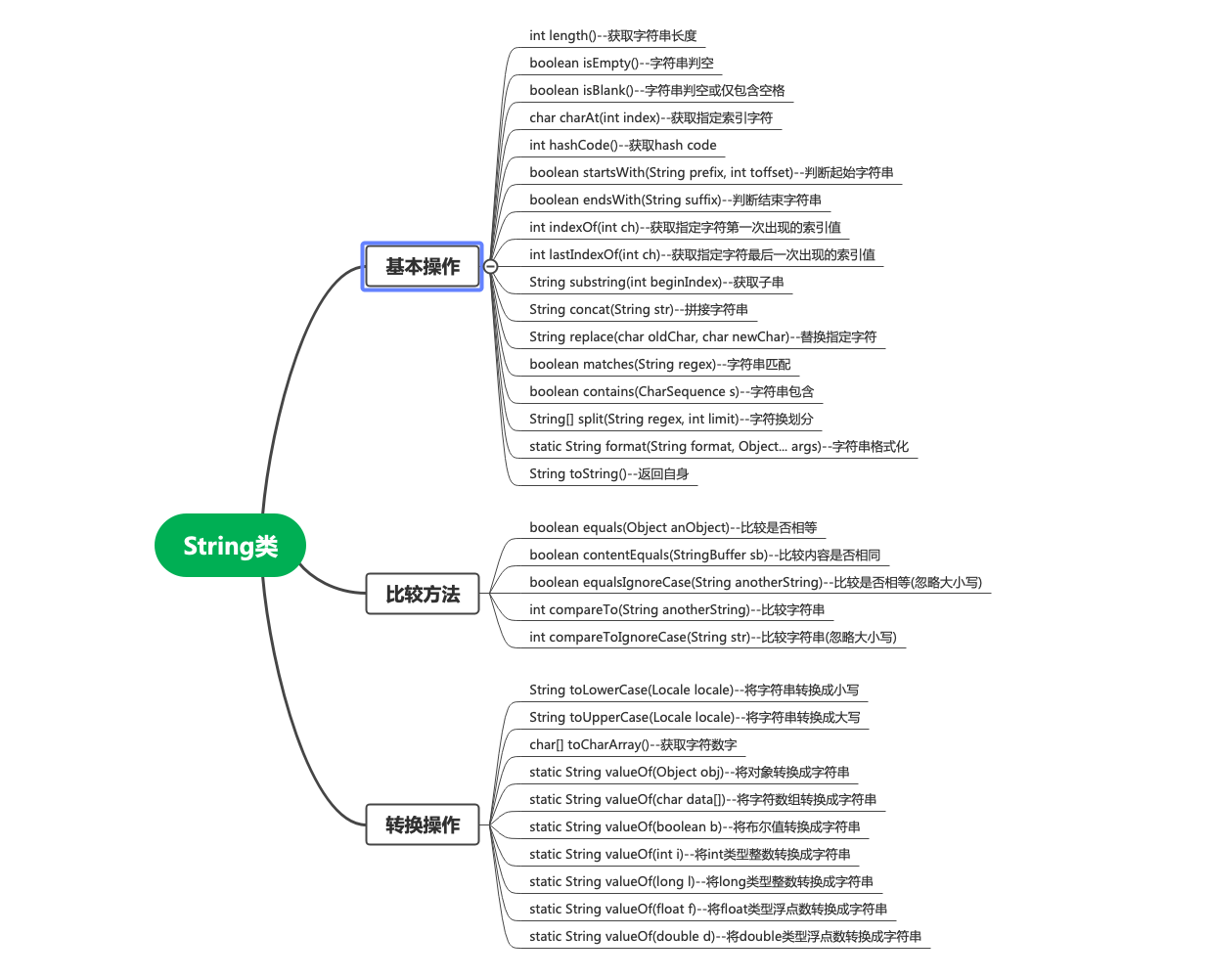
5.多层感知机
目录
- 感知机
- 基本内容
- 训练感知机
- 感知机存在的问题
- 总结
- 多层感知机
- 隐藏层
- 单隐藏层-单分类
- 激活函数
- ReLU函数
- sigmoid函数
- tanh函数
- 总结
- 多类分类
- 隐藏层
- 多层感知机的从零开始实现
- 初始化模型参数
- 激活函数
- 模型
- 损失函数
- 训练
- 多层感知机的简洁实现
- 模型
- 模型选择、欠拟合和过拟合
- 训练误差和泛化误差
- 模型选择
- 验证数据集和测试数据集
- K折交叉验证
- 欠拟合和过拟合
- 模型容量
- 模型复杂度
- 数据集大小
- 多项式回归
- 生成数据集
- 对模型进行训练和测试
- 三阶多项式函数拟合(正常)
- 线性函数拟合(欠拟合)
- 高阶多项式函数拟合(过拟合)
- 总结
- 权重衰减
- 使用均方范数作为硬性限制
- 使用均方范数作为柔性限制
- 参数更新法则
- 高维线性回归
- 从零开始实现
- 初始化模型参数
- 定义L_2范数惩罚
- 定义训练代码实现
- 忽略正则化直接训练
- 使用权重衰减
- 简洁实现
- 丢弃法Dropout
- 使用丢弃法
- 从零开始实现
- 定义模型参数
- 训练和测试
- 简洁实现
- 总结
- 数值稳定性和模型初始化
- 神经网络的梯度
- 数值稳定性的常见两个问题
- 梯度消失
- 梯度爆炸
感知机
基本内容

可以变成一个二分类的问题

训练感知机

在预测y<0之后,说明这一层的预测是错误的,权重和偏置不正确,要进行更新。
感知机存在的问题

总结
- 感知机是一个二分类模型,是最早的AI模型之一
- 它的求解算法等价于使用批量大小为1的梯度下降
- 它不能拟合XOR函数,导致了第一次AI寒冬
多层感知机

想要解决XOR问题,我们需要两根线x和y
隐藏层
我们可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。 要做到这一点,最简单的方法是将许多全连接层堆叠在一起。 每一层都输出到上面的层,直到生成最后的输出。 我们可以把前 L − 1 L-1 L−1层看作表示,把最后一层看作线性预测器。 这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP。

这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。 输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算。 因此,这个多层感知机中的层数为2。 注意,这两个层都是全连接的。 每个输入都会影响隐藏层中的每个神经元, 而隐藏层中的每个神经元又会影响输出层中的每个神经元。
📌隐藏层的大小是一个超参数
单隐藏层-单分类

为什么需要非线性激活函数

激活函数
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。 大多数激活函数都是非线性的。 由于激活函数是深度学习的基础,下面简要介绍一些常见的激活函数。
%matplotlib inline
import torch
from d2l import torch as d2l
ReLU函数
最受欢迎的激活函数是_修正线性单元_(Rectified linear unit,ReLU), 因为它实现简单,同时在各种预测任务中表现良好。 ReLU提供了一种非常简单的非线性变换。 给定元素x,ReLU函数被定义为该元素与0的最大值:
ReLU ( x ) = max ( x , 0 ) \operatorname{ReLU}(x)=\max (x, 0) ReLU(x)=max(x,0)
通俗地说,ReLU函数通过将相应的活性值设为0,仅保留正元素并丢弃所有负元素。 为了直观感受一下,我们可以画出函数的曲线图。 正如从图中所看到,激活函数是分段线性的
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.relu(x)
d2l.plot(x.detach(), y.detach(), 'x', 'relu(x)', figsize=(5, 2.5))

当输入为负时,ReLU函数的导数为0,而当输入为正时,ReLU函数的导数为1。 注意,当输入值精确等于0时,ReLU函数不可导。 在此时,我们默认使用左侧的导数,即当输入为0时导数为0。 我们可以忽略这种情况,因为输入可能永远都不会是0。 这里引用一句古老的谚语,“如果微妙的边界条件很重要,我们很可能是在研究数学而非工程”, 这个观点正好适用于这里。 下面我们绘制ReLU函数的导数。
y.backward(torch.ones_like(x), retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of relu', figsize=(5, 2.5))

使用ReLU的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。 这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题(稍后将详细介绍)。
注意,ReLU函数有许多变体,包括_参数化ReLU_(Parameterized ReLU,pReLU) 函数 (He et al., 2015)。 该变体为ReLU添加了一个线性项,因此即使参数是负的,某些信息仍然可以通过:
pReLU ( x ) = max ( 0 , x ) + α min ( 0 , x ) \operatorname{pReLU}(x)=\max (0, x)+\alpha \min (0, x) pReLU(x)=max(0,x)+αmin(0,x)
sigmoid函数
对于一个定义域在 R R R中的输入, sigmoid函数_将输入变换为区间(0, 1)上的输出。 因此,sigmoid通常称为_挤压函数(squashing function): 它将范围(-inf, inf)中的任意输入压缩到区间(0, 1)中的某个值:
sigmoid ( x ) = 1 1 + exp ( − x ) \operatorname{sigmoid}(x)=\frac{1}{1+\exp (-x)} sigmoid(x)=1+exp(−x)1
当人们逐渐关注到到基于梯度的学习时, sigmoid函数是一个自然的选择,因为它是一个平滑的、可微的阈值单元近似。 当我们想要将输出视作二元分类问题的概率时, sigmoid仍然被广泛用作输出单元上的激活函数 (sigmoid可以视为softmax的特例)。 然而,sigmoid在隐藏层中已经较少使用, 它在大部分时候被更简单、更容易训练的ReLU所取代。 在后面关于循环神经网络的章节中,我们将描述利用sigmoid单元来控制时序信息流的架构。
y = torch.sigmoid(x)
d2l.plot(x.detach(), y.detach(), 'x', 'sigmoid(x)', figsize=(5, 2.5))

sigmoid函数的导数为下面的公式:
d d x sigmoid ( x ) = exp ( − x ) ( 1 + exp ( − x ) ) 2 = sigmoid ( x ) ( 1 − sigmoid ( x ) ) . \frac{d}{d x} \operatorname{sigmoid}(x)=\frac{\exp (-x)}{(1+\exp (-x))^{2}}=\operatorname{sigmoid}(x)(1-\operatorname{sigmoid}(x)). dxdsigmoid(x)=(1+exp(−x))2exp(−x)=sigmoid(x)(1−sigmoid(x)).
sigmoid函数的导数图像如下所示。 注意,当输入为0时,sigmoid函数的导数达到最大值0.25; 而输入在任一方向上越远离0点时,导数越接近0。
# 清除以前的梯度
x.grad.data.zero_()
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of sigmoid', figsize=(5, 2.5))

tanh函数
与sigmoid函数类似, tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上。 tanh函数的公式如下:
tanh ( x ) = 1 − exp ( − 2 x ) 1 + exp ( − 2 x ) \tanh (x)=\frac{1-\exp (-2 x)}{1+\exp (-2 x)} tanh(x)=1+exp(−2x)1−exp(−2x)
下面我们绘制tanh函数。 注意,当输入在0附近时,tanh函数接近线性变换。 函数的形状类似于sigmoid函数, 不同的是tanh函数关于坐标系原点中心对称。
y = torch.tanh(x)
d2l.plot(x.detach(), y.detach(), 'x', 'tanh(x)', figsize=(5, 2.5))

tanh函数的导数是:
d d x tanh ( x ) = 1 − tanh 2 ( x ) \frac{d}{d x} \tanh (x)=1-\tanh ^{2}(x) dxdtanh(x)=1−tanh2(x)
tanh函数的导数图像如下所示。 当输入接近0时,tanh函数的导数接近最大值1。 与我们在sigmoid函数图像中看到的类似, 输入在任一方向上越远离0点,导数越接近0。
# 清除以前的梯度
x.grad.data.zero_()
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of tanh', figsize=(5, 2.5))

总结
- 多层感知机在输出层和输入层之间增加一个或多个全连接隐藏层,并通过激活函数转换隐藏层的输出。
- 常用的激活函数包括ReLU函数、sigmoid函数和tanh函数。
多类分类
y 1 , y 2 , … , y k = softmax ( o 1 , o 2 , … , o k ) y_{1}, y_{2}, \ldots, y_{k}=\operatorname{softmax}\left(o_{1}, o_{2}, \ldots, o_{k}\right) y1,y2,…,yk=softmax(o1,o2,…,ok)


多层感知机的从零开始实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
初始化模型参数
回想一下,Fashion-MNIST中的每个图像由 28×28=784个灰度像素值组成。 所有图像共分为10个类别。 忽略像素之间的空间结构, 我们可以将每个图像视为具有784个输入特征 和10个类的简单分类数据集。
首先,我们将实现一个具有单隐藏层的多层感知机, 它包含256个隐藏单元。 注意,我们可以将这两个变量都视为超参数。 通常,我们选择2的若干次幂作为层的宽度。 因为内存在硬件中的分配和寻址方式,这么做往往可以在计算上更高效。
我们用几个张量来表示我们的参数。 注意,对于每一层我们都要记录一个权重矩阵和一个偏置向量。 跟以前一样,我们要为损失关于这些参数的梯度分配内存。
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
这段代码定义了一个多层感知机模型,并初始化了模型的参数。
具体来说,代码中定义了四个参数:W1、b1、W2、b2。W1 和 W2 是权重矩阵,b1 和 b2 是偏移量。这些参数都是 torch.nn.Parameter 类型的,并且它们的形状分别为:
- W1:(num_inputs, num_hiddens)
- b1:(num_hiddens)
- W2:(num_hiddens, num_outputs)
- b2:(num_outputs)
这些参数都是随机初始化的,使用的是 PyTorch 的 randn 函数。randn 函数生成的是一个正态分布的随机数。这些参数的初始值是随机的,但是它们的分布是一致的。
参数的值在模型训练中会不断更新,以便最小化损失函数。
最后,将这四个参数放在一个列表中,方便之后对它们进行操作。

激活函数
为了确保我们对模型的细节了如指掌, 我们将实现ReLU激活函数, 而不是直接调用内置的relu函数。
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
这段代码定义了一个 ReLU 函数。ReLU(Rectified Linear Unit)是一种常用的激活函数。
ReLU 的计算方式很简单:对于输入 X,将其中的负数设为 0,正数不变。
在这段代码中,使用了 PyTorch 的 torch.zeros_like 函数来创建一个和 X 形状相同的全 0 张量 a。然后,使用 torch.max 函数来计算 X 和 a 中的最大值。
这样,就实现了对 X 的 ReLU 运算。
模型
因为我们忽略了空间结构, 所以我们使用reshape将每个二维图像转换为一个长度为num_inputs的向量。 只需几行代码就可以实现我们的模型。
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
这段代码定义了一个函数 net,该函数接受一个参数 X,并对其进行如下操作:
- 使用
X.reshape((-1, num_inputs))将X转换为形状为(-1, num_inputs)的矩阵,其中-1表示按照数组的大小自动计算第一维的大小。 - 使用
relu(X@W1 + b1)计算关于输入X的线性函数,然后将其传递给 ReLU 函数,作为 ReLU 的输入。这里的@代表矩阵乘法,W1和b1是网络的参数,用于学习。 - 返回关于输入
X的线性函数的输出,即H@W2 + b2。
这段代码中,W1 和 W2 是权值矩阵,b1 和 b2 是偏置向量。这些参数将在网络的训练过程中学习,以便将输入 X 映射到输出。
损失函数
loss = nn.CrossEntropyLoss(reduction='none')
nn.CrossEntropyLoss 是 PyTorch 中的一种损失函数,用于计算分类问题中的交叉熵损失。
在这里,reduction='none' 表示不对损失进行简化,即不对损失的结果进行求和或平均。这意味着输出的损失将是与输入相同形状的张量,每个位置对应一个样本的损失。
例如,如果输入是形状为 (batch_size, num_classes) 的矩阵,那么输出的损失将是形状为 (batch_size) 的向量,其中每个元素对应着一个样本的损失。
如果你想对损失进行简化,可以将 reduction 参数设置为 'sum' 或 'mean'。在这种情况下,输出的损失将是所有样本的损失的和或平均值。
训练
幸运的是,多层感知机的训练过程与softmax回归的训练过程完全相同。 可以直接调用d2l包的train_ch3函数, 将迭代周期数设置为10,并将学习率设置为0.1.
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)

为了对学习到的模型进行评估,我们将在一些测试数据上应用这个模型。
d2l.predict_ch3(net, test_iter)

多层感知机的简洁实现
import torch
from torch import nn
from d2l import torch as d2l
模型
添加了2个全连接层(之前我们只添加了1个全连接层)。 第一层是隐藏层,它包含256个隐藏单元,并使用了ReLU激活函数。 第二层是输出层。
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256), #隐藏层
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
这段代码定义了一个 PyTorch 神经网络,该网络包含以下四层:
nn.Flatten():将输入展平为一维张量,以便于输入到线性层中。nn.Linear(784, 256):一个具有 784 个输入特征和 256 个输出特征的线性层,用于学习网络的第一个隐藏层。nn.ReLU():一个将输入的所有元素的绝对值取最大值的函数,用于将线性层的输出传递给非线性激活函数。nn.Linear(256, 10):一个具有 256 个输入特征和 10 个输出特征的线性层,用于学习网络的输出层。
然后,定义了一个名为 init_weights 的函数,该函数接受一个参数 m,并判断其类型是否为 nn.Linear。如果是,则使用 PyTorch 的 nn.init 模块中的 normal_ 函数,将该层的权值初始化为服从标准正态分布的随机值,其中标准差为 0.01。
最后,使用 net.apply 函数将 init_weights 函数应用于网络中的所有层。这意味着,对于网络中的每一层,都将执行一次 init_weights(m),其中 m 是当前层的实例。
训练过程的实现与我们实现softmax回归时完全相同, 这种模块化设计使我们能够将与模型架构有关的内容独立出来。
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)

模型选择、欠拟合和过拟合
将模型在训练数据上拟合的比在潜在分布中更接近的现象称为过拟合(overfitting), 用于对抗过拟合的技术称为正则化(regularization)。
训练误差和泛化误差
训练误差:模型在训练数据上的误差
泛化数据:模型在新数据上的误差
下面的三个思维实验将有助于更好地说明这种情况。 假设一个大学生正在努力准备期末考试。 一个勤奋的学生会努力做好练习,并利用往年的考试题目来测试自己的能力。 尽管如此,在过去的考试题目上取得好成绩并不能保证他会在真正考试时发挥出色。 例如,学生可能试图通过死记硬背考题的答案来做准备。 他甚至可以完全记住过去考试的答案。 另一名学生可能会通过试图理解给出某些答案的原因来做准备。 在大多数情况下,后者会考得更好。
模型选择
验证数据集和测试数据集
验证数据集:一个用来评估模型好坏的数据集
- 例如拿出50%的训练数据
- 不要跟训练数据混在一起(常犯错误)
测试数据集:只用一次的数据集。例如
- 未来的考试
- 我出价的房子的实际成交价
- 用在Kaggle私有排行榜中的数据集
K折交叉验证
当训练数据稀缺时,我们甚至可能无法提供足够的数据来构成一个合适的验证集。 这个问题的一个流行的解决方案是采用K折交叉验证。
原始训练数据被分成K个不重叠的子集。 然后执行K次模型训练和验证,每次在K-1个子集上进行训练, 并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。 最后,通过对K次实验的结果取平均来估计训练和验证误差。
欠拟合和过拟合

当我们比较训练和验证误差时,我们要注意两种常见的情况。 首先,我们要注意这样的情况:训练误差和验证误差都很严重, 但它们之间仅有一点差距。 如果模型不能降低训练误差,这可能意味着模型过于简单(即表达能力不足), 无法捕获试图学习的模式。 此外,由于我们的训练和验证误差之间的_泛化误差_很小, 我们有理由相信可以用一个更复杂的模型降低训练误差。 这种现象被称为_欠拟合_(underfitting)。
另一方面,当我们的训练误差明显低于验证误差时要小心, 这表明严重的_过拟合*(overfitting)。 注意,* 过拟合_并不总是一件坏事。 特别是在深度学习领域,众所周知, 最好的预测模型在训练数据上的表现往往比在保留(验证)数据上好得多。 最终,我们通常更关心验证误差,而不是训练误差和验证误差之间的差距。
模型容量

模型复杂度

数据集大小
另一个重要因素是数据集的大小。 训练数据集中的样本越少,我们就越有可能(且更严重地)过拟合。 随着训练数据量的增加,泛化误差通常会减小。 此外,一般来说,更多的数据不会有什么坏处。 对于固定的任务和数据分布,模型复杂性和数据集大小之间通常存在关系。 给出更多的数据,我们可能会尝试拟合一个更复杂的模型。 能够拟合更复杂的模型可能是有益的。 如果没有足够的数据,简单的模型可能更有用。 对于许多任务,深度学习只有在有数千个训练样本时才优于线性模型。 从一定程度上来说,深度学习目前的生机要归功于 廉价存储、互联设备以及数字化经济带来的海量数据集。
多项式回归
我们现在可以通过多项式拟合来探索这些概念。
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
生成数据集
给定 x x x,我们将使用以下三阶多项式来生成训练和测试数据的标签:
y = 5 + 1.2 x − 3.4 x 2 2 ! + 5.6 x 3 3 ! + ϵ w h e r e ϵ ∼ N ( 0 , 0. 1 2 ) y=5+1.2 x-3.4 \frac{x^{2}}{2 !}+5.6 \frac{x^{3}}{3 !}+\epsilon where \epsilon \sim \mathcal{N}\left(0,0.1^{2}\right) y=5+1.2x−3.42!x2+5.63!x3+ϵwhereϵ∼N(0,0.12)
噪声项 𝜖 服从均值为0且标准差为0.1的正态分布。 在优化的过程中,我们通常希望避免非常大的梯度值或损失值。 这就是我们将特征从 x i x^i xi调整为 x i i ! \frac{x^i}{i!} i!xi的原因, 这样可以避免很大的 𝑖 带来的特别大的指数值。 我们将为训练集和测试集各生成100个样本。
max_degree = 20 # 多项式的最大阶数
n_train, n_test = 100, 100 # 训练和测试数据集大小
true_w = np.zeros(max_degree) # 分配大量的空间
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])
features = np.random.normal(size=(n_train + n_test, 1)) # 随机正态分布数据
np.random.shuffle(features)
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!
# labels的维度:(n_train+n_test,)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape)
这段代码定义了一个用于生成多项式数据的过程。
首先,它定义了一个变量 max_degree,表示多项式的最大阶数,并定义了训练和测试数据集的大小。然后,它初始化了一个用于存储多项式真实系数的数组 true_w,并将前 4 个元素设为指定的值。
接下来,使用 np.random.normal 函数生成了形状为 (n_train + n_test, 1) 的随机正态分布数据,并使用 np.shuffle 函数随机打乱了数据的顺序。
然后,使用 np.power 函数和 np.arange 函数生成了形状为 (1, max_degree) 的数组,并将其广播到形状为 (n_train + n_test, max_degree) 的多项式特征矩阵。接着,使用 math.gamma 函数对每一列进行标准化。
最后,使用 np.dot 函数计算多项式的点积,并将随机的正态分布噪声添加到标签中。这样,就生成了形状为 (n_train + n_test,) 的标签数组。
同样,存储在poly_features中的单项式由gamma函数重新缩放, 其中
Γ
(
n
)
=
(
n
−
1
)
!
\Gamma(n)=(n-1)!
Γ(n)=(n−1)!。 从生成的数据集中查看一下前2个样本, 第一个值是与偏置相对应的常量特征。
# NumPy ndarray转换为tensor
true_w, features, poly_features, labels = [torch.tensor(x, dtype=
torch.float32) for x in [true_w, features, poly_features, labels]]
features[:2], poly_features[:2, :], labels[:2]
这段代码将 true_w, features, poly_features, labels 这四个 NumPy ndarray 转换为 PyTorch tensor。
它使用了列表推导式的形式,对这四个数组分别调用了 torch.tensor 函数,并将结果赋值给对应的变量。torch.tensor 函数的 dtype 参数设为 torch.float32,表示将输入数据转换为 32 位浮点数的 tensor。
接着,输出了前两个数据的特征和标签。这些操作的作用是将数据的前两个样本的特征和标签输出到控制台,方便进行检查。
输出
(tensor([[ 0.3666],
[-0.1542]]),
tensor([[ 1.0000e+00, 3.6661e-01, 6.7201e-02, 8.2122e-03, 7.5267e-04,
5.5187e-05, 3.3720e-06, 1.7660e-07, 8.0931e-09, 3.2967e-10,
1.2086e-11, 4.0280e-13, 1.2306e-14, 3.4704e-16, 9.0876e-18,
2.2211e-19, 5.0892e-21, 1.0975e-22, 2.2353e-24, 4.3131e-26],
[ 1.0000e+00, -1.5424e-01, 1.1894e-02, -6.1151e-04, 2.3579e-05,
-7.2735e-07, 1.8697e-08, -4.1197e-10, 7.9426e-12, -1.3611e-13,
2.0994e-15, -2.9436e-17, 3.7834e-19, -4.4888e-21, 4.9452e-23,
-5.0848e-25, 4.9017e-27, -4.4471e-29, 3.8106e-31, -3.0933e-33]]),
tensor([5.2560, 4.7245]))
对模型进行训练和测试
首先让我们实现一个函数来评估模型在给定数据集上的损失。
def evaluate_loss(net, data_iter, loss): #@save
"""评估给定数据集上模型的损失"""
metric = d2l.Accumulator(2) # 损失的总和,样本数量
for X, y in data_iter:
out = net(X)
y = y.reshape(out.shape)
l = loss(out, y)
metric.add(l.sum(), l.numel())
return metric[0] / metric[1]
这是一个评估模型在给定数据集上的损失的函数。它接受三个参数:
net:模型。data_iter:数据迭代器。loss:损失函数。
函数的流程如下:
- 初始化一个名为
metric的计数器,用于记录损失的总和和样本数量。 - 遍历数据迭代器中的所有数据,计算模型的输出和真实标签,并计算损失。
- 使用计数器累加损失的总和和样本数量。
- 返回损失的平均值。
现在定义训练函数。
def train(train_features, test_features, train_labels, test_labels,
num_epochs=400):
loss = nn.MSELoss(reduction='none')
input_shape = train_features.shape[-1]
# 不设置偏置,因为我们已经在多项式中实现了它
net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))
batch_size = min(10, train_labels.shape[0])
train_iter = d2l.load_array((train_features, train_labels.reshape(-1,1)),
batch_size)
test_iter = d2l.load_array((test_features, test_labels.reshape(-1,1)),
batch_size, is_train=False)
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',
xlim=[1, num_epochs], ylim=[1e-3, 1e2],
legend=['train', 'test'])
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:
animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),
evaluate_loss(net, test_iter, loss)))
print('weight:', net[0].weight.data.numpy())
这是一个训练模型的函数。它接受四个参数:
train_features:训练数据的特征。test_features:测试数据的特征。train_labels:训练数据的标签。test_labels:测试数据的标签。
函数的流程如下:
- 初始化损失函数,以及输入数据的形状。
- 初始化一个线性模型,并将其包装成一个
Sequential模型。 - 初始化训练和测试数据的迭代器。这里的迭代器是使用
d2l.load_array函数创建的,用于加载训练或测试数据,并将其分成若干个小批量。 - 初始化优化器。这里使用的是随机梯度下降 (SGD) 优化器。
- 初始化一个动画对象,用于绘制训练和测试损失的变化情况。
- 在训练数据上进行 num_epochs 轮迭代。每轮迭代中,调用
d2l.train_epoch_ch3函数,在训练数据上进行前向传播、反向传播和优化操作。 - 每训练 20 轮后,调用
evaluate_loss函数,计算训练数据和测试数据上的损失,并将结果添加到动画对象中。 - 最后,输出模型的权重。
三阶多项式函数拟合(正常)
我们将首先使用三阶多项式函数,它与数据生成函数的阶数相同。 结果表明,该模型能有效降低训练损失和测试损失。 学习到的模型参数也接近真实值 w = [ 5 , 1.2 , − 3.4 , 5.6 ] w = [5, 1.2, -3.4, 5.6] w=[5,1.2,−3.4,5.6]。
# 从多项式特征中选择前4个维度,即1,x,x^2/2!,x^3/3!
train(poly_features[:n_train, :4], poly_features[n_train:, :4],
labels[:n_train], labels[n_train:])
这段代码调用了 train 函数,并传入了训练数据和测试数据。
其中,训练数据由前 n_train 个样本和前 4 个特征组成;测试数据由后 n_test 个样本和前 4 个特征组成。
这段代码的作用是训练一个线性模型,并绘制训练和测试损失的变化情况。训练和测试数据的损失越小,说明模型的拟合能力越强。
训练完成后,函数还会输出模型的权重。这些权重可以帮助我们理解模型的决策规则,以及模型对不同特征的重视程度。
输出
weight: [[ 5.000446 1.1925726 -3.3994446 5.613429 ]]

线性函数拟合(欠拟合)
让我们再看看线性函数拟合,减少该模型的训练损失相对困难。 在最后一个迭代周期完成后,训练损失仍然很高。 当用来拟合非线性模式(如这里的三阶多项式函数)时,线性模型容易欠拟合。
# 从多项式特征中选择前2个维度,即1和x
train(poly_features[:n_train, :2], poly_features[n_train:, :2],
labels[:n_train], labels[n_train:])
输出
weight: [[3.3861537 3.623168 ]]

高阶多项式函数拟合(过拟合)
现在,让我们尝试使用一个阶数过高的多项式来训练模型。 在这种情况下,没有足够的数据用于学到高阶系数应该具有接近于零的值。 因此,这个过于复杂的模型会轻易受到训练数据中噪声的影响。 虽然训练损失可以有效地降低,但测试损失仍然很高。 结果表明,复杂模型对数据造成了过拟合。
# 从多项式特征中选取所有维度
train(poly_features[:n_train, :], poly_features[n_train:, :],
labels[:n_train], labels[n_train:], num_epochs=1500)
输出
weight: [[ 4.976002 1.2835668 -3.2593832 5.150967 -0.41944516 1.348935
-0.17952554 0.15169154 -0.15447472 0.15434313 0.11540707 -0.20328848
0.20229222 -0.19785015 -0.13074256 -0.16738276 0.03405237 -0.03323355
-0.08506632 0.14969553]]

总结
- 欠拟合是指模型无法继续减少训练误差。过拟合是指训练误差远小于验证误差。
- 由于不能基于训练误差来估计泛化误差,因此简单地最小化训练误差并不一定意味着泛化误差的减小。机器学习模型需要注意防止过拟合,即防止泛化误差过大。
- 验证集可以用于模型选择,但不能过于随意地使用它。
- 我们应该选择一个复杂度适当的模型,避免使用数量不足的训练样本。
权重衰减
前一节我们描述了过拟合的问题,本节我们将介绍一些正则化模型的技术。 我们总是可以通过去收集更多的训练数据来缓解过拟合。 但这可能成本很高,耗时颇多,或者完全超出我们的控制,因而在短期内不可能做到。 假设我们已经拥有尽可能多的高质量数据,我们便可以将重点放在正则化技术上。
使用均方范数作为硬性限制

使用均方范数作为柔性限制

参数更新法则

权重衰退通过L2正则项使得模型参数不会过大。从而控制模型复杂度
正则项权重是控制模型复杂度的超参数
高维线性回归
我们通过一个简单的例子来演示权重衰减。
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
首先,我们像以前一样生成一些数据,生成公式如下:
y = 0.05 + ∑ i = 1 d 0.01 x i + ϵ w h e r e ϵ ∼ N ( 0 , 0.0 1 2 ) . y=0.05+\sum_{i=1}^{d} 0.01 x_{i}+\epsilon where \epsilon \sim \mathcal{N}\left(0,0.01^{2}\right). y=0.05+i=1∑d0.01xi+ϵwhereϵ∼N(0,0.012).
我们选择标签是关于输入的线性函数。 标签同时被均值为0,标准差为0.01高斯噪声破坏。 为了使过拟合的效果更加明显,我们可以将问题的维数增加到d = 200, 并使用一个只包含20个样本的小训练集。
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
这段代码初始化了一些变量,这些变量用于训练和测试线性模型。
这些变量包括:
n_train:训练样本的数量n_test:测试样本的数量num_inputs:输入特征的数量batch_size:训练和测试的批量大小true_w:线性模型的真实权重参数true_b:线性模型的真实偏差参数
代码还使用 synthetic_data 函数生成了训练和测试数据。这个函数使用真实的权重和偏差参数以及一些随机噪声生成 y 值。然后,使用 load_array 函数将训练和测试数据加载到 PyTorch 数据加载器 train_iter 和 test_iter 中。在训练模型和评估模型时,我们会使用这些数据加载器遍历训练集和测试集。
从零开始实现
下面我们将从头开始实现权重衰减,只需将 L 2 L_2 L2的平方惩罚添加到原始目标函数中。
初始化模型参数
def init_params():
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
这段代码定义了一个名为 init_params 的函数,用于初始化线性模型的权重和偏差参数。权重参数 w 使用从均值为 0,标准差为 1 的正态分布中随机抽取的值进行初始化。偏差参数 b 被初始化为标量,值为 0。w 和 b 的 requires_grad 都被设置为 True,这意味着 PyTorch 将在反向传播期间跟踪它们的梯度,并在优化过程中更新它们。这对于训练模型是必要的。
定义 L 2 L_2 L2范数惩罚
实现这一惩罚最方便的方法是对所有项求平方后并将它们求和。
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
定义训练代码实现
下面的代码将模型拟合训练数据集,并在测试数据集上进行评估。 从 3节以来,线性网络和平方损失没有变化, 所以我们通过d2l.linreg和d2l.squared_loss导入它们。 唯一的变化是损失现在包括了惩罚项。
def train(lambd):
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
# 增加了L2范数惩罚项,
# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w).item())
这段代码实现了一个用于训练线性回归模型的函数。它首先使用 init_params 函数初始化模型的权重和偏差。然后它定义了模型和损失函数:模型是一个线性回归模型,损失函数是平方损失。
接下来,它进入了一个循环,其中每个循环迭代都会对训练数据进行一次前向传播、后向传播和参数更新。在每个循环迭代中,对于训练数据中的每一个批次,它都会计算损失函数的值,并在此基础上加上 L2 正则化项的值,以防止过拟合。然后它使用随机梯度下降(SGD)优化算法更新模型的参数。
在每个五次循环迭代之后,它会使用 d2l.evaluate_loss 函数评估训练数据和测试数据上模型的损失。最后,它输出模型的权重的 L2 范数。
忽略正则化直接训练
我们现在用lambd = 0禁用权重衰减后运行这个代码。 注意,这里训练误差有了减少,但测试误差没有减少, 这意味着出现了严重的过拟合。
train(lambd=0)
输出
w的L2范数是: 13.97721004486084

使用权重衰减
下面,我们使用权重衰减来运行代码。 注意,在这里训练误差增大,但测试误差减小。 这正是我们期望从正则化中得到的效果。
train(lambd=3)
输出
w的L2范数是: 0.3624069094657898

简洁实现
由于权重衰减在神经网络优化中很常用, 深度学习框架为了便于我们使用权重衰减, 将权重衰减集成到优化算法中,以便与任何损失函数结合使用。 此外,这种集成还有计算上的好处, 允许在不增加任何额外的计算开销的情况下向算法中添加权重衰减。 由于更新的权重衰减部分仅依赖于每个参数的当前值, 因此优化器必须至少接触每个参数一次。
在下面的代码中,我们在实例化优化器时直接通过weight_decay指定weight decay超参数。 默认情况下,PyTorch同时衰减权重和偏移。 这里我们只为权重设置了weight_decay,所以偏置参数b不会衰减。
def train_concise(wd):
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss(reduction='none')
num_epochs, lr = 100, 0.003
# 偏置参数没有衰减
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1,
(d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数:', net[0].weight.norm().item())
这段代码实现了一个用于训练线性回归模型的函数,并使用 PyTorch 的神经网络(nn)模块实现了模型和损失函数。
首先,它使用 nn.Sequential 定义了一个简单的单层神经网络,其中包含一个线性层。然后,它使用一个循环对模型的参数进行了初始化。接下来,它定义了平方损失函数(MSE loss),并使用 PyTorch 的随机梯度下降(SGD)优化器进行优化。它在每个五次循环迭代之后使用 d2l.evaluate_loss 函数评估训练数据和测试数据上的损失。最后,它输出了模型的权重的 L2 范数。
这些图看起来和我们从零开始实现权重衰减时的图相同。 然而,它们运行得更快,更容易实现。 对于更复杂的问题,这一好处将变得更加明显。
train_concise(0)
输出
w的L2范数: 14.670721054077148

train_concise(3)
输出
w的L2范数: 0.3454631567001343

丢弃法Dropout
一个好的模型需要对输入数据的扰动鲁棒
- 使用有噪音的数据等价于Tikhonov正则
- 丢弃法:在层之间加入噪音
📌丢弃法在前向传播过程中,计算每一内部层的同时注入噪声,这已经成为训练神经网络的常用技术。 这种方法之所以被称为丢弃法,因为我们从表面上看是在训练过程中丢弃(drop out)一些神经元。 在整个训练过程的每一次迭代中,标准暂退法包括在计算下一层之前将当前层中的一些节点置零。
无偏差的加入噪音

使用丢弃法
通常将丢弃法作用在隐藏全连接层的输出上(训练时使用)

h = σ ( W 1 x + b 1 ) h ′ = dropout ( h ) o = W 2 h ′ + b 2 y = softmax ( o ) \begin{aligned} \mathbf{h} & =\sigma\left(\mathbf{W}_{1} \mathbf{x}+\mathbf{b}_{1}\right) \\ \mathbf{h}^{\prime} & =\operatorname{dropout}(\mathbf{h}) \\ \mathbf{o} & =\mathbf{W}_{2} \mathbf{h}^{\prime}+\mathbf{b}_{2} \\ \mathbf{y} & =\operatorname{softmax}(\mathbf{o})\end{aligned} hh′oy=σ(W1x+b1)=dropout(h)=W2h′+b2=softmax(o)
通常,我们在测试时不用暂退法。 给定一个训练好的模型和一个新的样本,我们不会丢弃任何节点,因此不需要标准化。 然而也有一些例外:一些研究人员在测试时使用暂退法, 用于估计神经网络预测的“不确定性”: 如果通过许多不同的暂退法遮盖后得到的预测结果都是一致的,那么我们可以说网络发挥更稳定。
- 丢弃法将一些输出项随机置0来控制模型复杂度
- 常作用在多层感知机的隐藏层输出上
- 丢弃概率是控制模型复杂度的超参数
从零开始实现
要实现单层的丢弃法函数, 我们从均匀分布 U [ 0 , 1 ] U[0,1] U[0,1]中抽取样本,样本数与这层神经网络的维度一致。 然后我们保留那些对应样本大于 p p p的节点,把剩下的丢弃。
在下面的代码中,我们实现 dropout_layer 函数, 该函数以dropout的概率丢弃张量输入X中的元素, 如上所述重新缩放剩余部分:将剩余部分除以1.0-dropout。
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)
这段代码实现了一个 dropout 层,主要作用是在神经网络训练过程中随机“丢弃”一些结点的输出,用来防止过拟合。
首先,在函数开头使用了 assert 语句来确保输入的 dropout 值在合理范围内(0 <= dropout <= 1),如果 dropout 值不在合理范围内就会抛出 AssertionError。
接下来,如果 dropout 等于 1,直接返回一个和输入张量 X 形状相同的全零张量,这意味着本层的输出都将被丢弃。如果 dropout 等于 0,直接返回 X,这意味着不会有结点被丢弃。
最后,在 0 < dropout < 1 的情况下,生成一个和 X 形状相同的张量 mask,并使用torch.rand(X.shape)生成一个均匀分布的随机数,将它与 dropout 进行比较,得到一个bool型的张量。接着将其转换为浮点型,在和 X 进行按元素乘法。最后除以(1.0 - dropout)这样可以保证输出值的期望不变。
这段代码实现了一个简单的dropout层,用来在神经网络中避免过拟合,使用时需要注意dropout一般只会在训练时使用,在测试时要将dropout设为0
比如说我们有一个2x3的输入矩阵X,dropout=0.5
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
dropout = 0.5
首先生成一个和X形状相同的随机数矩阵
torch.rand(X.shape)
# tensor([[0.5485, 0.6368, 0.5799],
# [0.2757, 0.1820, 0.8102]])
比较,得到一个bool类型的矩阵
torch.rand(X.shape) > dropout
# tensor([[ True, True, False],
# [False, False, True]])
转换成float, 1代表保留这个位置,0代表丢弃
mask = (torch.rand(X.shape) > dropout).float()
# tensor([[1., 1., 0.],
# [0., 0., 1.]])
通过这个 mask 与 X 进行按元素乘法, 得到dropout之后的输出
mask * X / (1.0 - dropout)
# tensor([[1., 2., 0.],
# [0., 0., 6.]])
这样就实现了一次 dropout 操作,通过随机的将一些元素置为0来减小网络的过拟合.
我们可以通过下面几个例子来测试dropout_layer函数。 我们将输入X通过暂退法操作,暂退概率分别为0、0.5和1。
X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))
输出
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 2., 4., 6., 8., 10., 0., 14.],
[16., 18., 20., 22., 0., 0., 0., 30.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
同样,我们引入的Fashion-MNIST数据集。 我们定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元。
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
定义模型参数
我们可以将丢弃法应用于每个隐藏层的输出(在激活函数之后), 并且可以为每一层分别设置丢弃概率: 常见的技巧是在靠近输入层的地方设置较低的丢弃概率。 下面的模型将第一个和第二个隐藏层的丢弃概率分别设置为0.2和0.5, 并且丢弃法只在训练期间有效。
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
这段代码定义了一个 Net 类,它继承了 PyTorch 中 nn.Module 类,是一个多层感知机模型。
首先定义了两个变量:
- dropout1: 0.2,表示第一个隐藏层使用 dropout 时随机“丢弃”结点的概率
- dropout2: 0.5,表示第二个隐藏层使用 dropout 时随机“丢弃”结点的概率
在初始化函数 __init__ 中,
- 首先通过父类的初始化函数来初始化这个模型
- 通过 nn.Linear 定义三个全连接层 lin1, lin2, lin3,分别连接输入层、第一个隐藏层和第二个隐藏层、输出层。
- 定义了一个ReLU激活函数
- 定义了一个forward函数,它是核心函数,用于进行前向传播,每次前向传播都会调用这个函数。
在 forward 函数中:
- 首先将输入数据 reshape 成(batch_size, num_inputs)的形状并通过第一个全连接层和ReLU激活函数进行处理,得到第一个隐藏层的输出 H1
- 根据是否在训练模式,使用dropout_layer函数进行 dropout 操作来丢弃部分结点,得到第一个dropout层的输出
- 通过第二个全连接层和ReLU激活函数处理第一个隐藏层的输出,得到第二个隐藏层的输出 H2
- 同样根据是否在训练模式,使用dropout_layer函数进行 dropout 操作来丢弃部分结点,得到第二个dropout层的输出
- 最后将第二个隐藏层的输出通过第三个全连接层进行处理,得到最终的输出
最后用 net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2) 初始化这个模型。
这样就定义好了一个多层感知机模型,这个模型结构是通过输入层和2个隐藏层组成的,在隐藏层之间使用dropout来防止过拟合。可以使用这个模型来训练和预测。
训练和测试
这类似于前面描述的多层感知机训练和测试。
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MSfi1dft-1673765611318)(image/image_9o4H2mUPcy.png)]
简洁实现
对于深度学习框架的高级API,我们只需在每个全连接层之后添加一个Dropout层, 将暂退概率作为唯一的参数传递给它的构造函数。 在训练时,Dropout层将根据指定的暂退概率随机丢弃上一层的输出(相当于下一层的输入)。 在测试时,Dropout层仅传递数据。
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
这里定义了一个新的多层感知机模型。这次是使用 nn.Sequential 类来定义模型的结构。
- 首先是nn.Flatten()层,这一层的作用是将输入数据的形状从(batch_size, num_channels, height, width)变成(batch_size, num_channels * height * width),方便下一层线性层直接接受输入。
- 下面是第一个全连接层 nn.Linear(784, 256)。这一层输入是上面Flatten层输出的数据,输出有256个节点。
- 接着是ReLU激活层 nn.ReLU()
- dropout1 在第一个全连接层之后添加一个dropout层 nn.Dropout(dropout1)
- 第二个全连接层nn.Linear(256, 256),输入为256个节点,输出也是256个节点
- 同样有一个ReLU激活层nn.ReLU()
- dropout2 在第二个全连接层之后添加一个dropout层 nn.Dropout(dropout2)
- 最后是输出层nn.Linear(256, 10),输入为256个节点,输出为10个节点。
然后定义了一个init_weights函数,当模型中的子模块是nn.Linear的时候就使用nn.init.normal_来初始化权重,标准差为0.01
最后使用 net.apply(init_weights)来应用初始化权重的函数初始化网络参数。
这样定义的模型结构和之前的模型是相似的,并且这次的模型结构代码简洁明了,可以更加灵活地组合网络结构。
接下来,我们对模型进行训练和测试。
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rCfmtf4g-1673765611319)(image/image_rooZgwJzhw.png)]
总结
- 暂退法在前向传播过程中,计算每一内部层的同时丢弃一些神经元。
- 暂退法可以避免过拟合,它通常与控制权重向量的维数和大小结合使用的。
- 暂退法将活性值h替换为具有期望值h的随机变量。
- 暂退法仅在训练期间使用。
数值稳定性和模型初始化
到目前为止,我们实现的每个模型都是根据某个预先指定的分布来初始化模型的参数。 有人会认为初始化方案是理所当然的,忽略了如何做出这些选择的细节。甚至有人可能会觉得,初始化方案的选择并不是特别重要。 相反,初始化方案的选择在神经网络学习中起着举足轻重的作用, 它对保持数值稳定性至关重要。 此外,这些初始化方案的选择可以与非线性激活函数的选择有趣的结合在一起。 我们选择哪个函数以及如何初始化参数可以决定优化算法收敛的速度有多快。 糟糕选择可能会导致我们在训练时遇到梯度爆炸或梯度消失。 本节将更详细地探讨这些主题,并讨论一些有用的启发式方法。 这些启发式方法在整个深度学习生涯中都很有用。
神经网络的梯度

数值稳定性的常见两个问题


梯度消失

%matplotlib inline
import torch
from d2l import torch as d2l
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.sigmoid(x)
y.backward(torch.ones_like(x))
d2l.plot(x.detach().numpy(), [y.detach().numpy(), x.grad.numpy()],
legend=['sigmoid', 'gradient'], figsize=(4.5, 2.5))
这段代码使用了 PyTorch 库来绘制 sigmoid 函数和它的梯度。
首先, 使用torch.arange函数创建一个数组x,这个数组的范围是从-8到8,步长是0.1。并且将 requires_grad 设置为True,表示这个张量需要跟踪其在反向传播过程中的历史记录。
然后,使用torch.sigmoid函数计算出y。
接着,调用y.backward(torch.ones_like(x))来计算x的梯度.torch.ones_like(x)的作用是创建一个和x形状相同的全1数组。
最后,使用 d2l.plot 函数来绘制 sigmoid 函数和它的梯度。x.detach().numpy()和y.detach().numpy()将 x 和 y 转换为 numpy 格式,x.grad.numpy()则是获取x的梯度值。
这样就会得到 sigmoid 函数和它的梯度的图形,可以看出sigmoid函数的导数是单峰的,导数值为1的地方在0附近,导数值越小越接近于0,而且 sigmoid 函数在 x 较大或较小时的值都接近 0,所以在这些区域的梯度值也接近0。

正如上图,当sigmoid函数的输入很大或是很小时,它的梯度都会消失。 此外,当反向传播通过许多层时,除非我们在刚刚好的地方, 这些地方sigmoid函数的输入接近于零,否则整个乘积的梯度可能会消失。 当我们的网络有很多层时,除非我们很小心,否则在某一层可能会切断梯度。 事实上,这个问题曾经困扰着深度网络的训练。 因此,更稳定的ReLU系列函数已经成为从业者的默认选择(虽然在神经科学的角度看起来不太合理)。
梯度爆炸

相反,梯度爆炸可能同样令人烦恼。 为了更好地说明这一点,我们生成100个高斯随机矩阵,并将它们与某个初始矩阵相乘。 对于我们选择的尺度(方差 σ 2 = 1 \sigma^2=1 σ2=1),矩阵乘积发生爆炸。 当这种情况是由于深度网络的初始化所导致时,我们没有机会让梯度下降优化器收敛。
M = torch.normal(0, 1, size=(4,4))
print('一个矩阵 \n',M)
for i in range(100):
M = torch.mm(M,torch.normal(0, 1, size=(4, 4)))
print('乘以100个矩阵后\n', M)
这段代码是在使用 PyTorch 库来创建一个4x4的随机矩阵,并将其乘以100个随机矩阵。
首先,使用 torch.normal(0, 1, size=(4, 4)) 函数创建一个4x4的随机矩阵M,其中 mean=0, std=1。
然后使用一个 for 循环来重复进行矩阵乘法运算 100 次。每次循环中,使用 torch.mm(M,torch.normal(0, 1, size=(4, 4))) 函数来计算M矩阵和一个新的随机矩阵的乘积,然后将结果赋值给 M。
最后输出最终的矩阵 M,输出的矩阵可能已经非常接近于随机
输出
一个矩阵
tensor([[-0.4430, 1.8467, 1.2274, 0.2537],
[ 1.6749, -1.5996, 0.6402, 0.1141],
[-0.1859, -0.4506, 2.5819, -1.3329],
[ 2.7346, 0.1642, -0.6078, -0.0507]])
乘以100个矩阵后
tensor([[ 6.9875e+23, 5.5570e+23, 7.6843e+23, -1.9781e+23],
[-6.3054e+23, -5.0146e+23, -6.9342e+23, 1.7850e+23],
[ 6.4354e+23, 5.1180e+23, 7.0772e+23, -1.8218e+23],
[-1.1732e+24, -9.3301e+23, -1.2902e+24, 3.3212e+23]])