ipvs nat模式下独立于iptables与conntrack的连接跟踪表和NAT机制
ipvs的连接跟踪表和NAT机制
ipvs只有DNAT和de-DNAT功能 ,它独立与iptables和conntrack,实现了自己的一套连接跟踪表和NAT机制。ipvs仅仅在做DNAT后对conntrack连接进行更新,防止回包因为没有记录而被丢弃。
ipvs独立的dnat与snat机制分析:
IPVS中tcp协议的状态转换表:
/*
* Timeout table[state]
*/
static const int tcp_timeouts[IP_VS_TCP_S_LAST+1] = {
[IP_VS_TCP_S_NONE] = 2*HZ,
[IP_VS_TCP_S_ESTABLISHED] = 15*60*HZ,
[IP_VS_TCP_S_SYN_SENT] = 2*60*HZ,
[IP_VS_TCP_S_SYN_RECV] = 1*60*HZ,
[IP_VS_TCP_S_FIN_WAIT] = 2*60*HZ,
[IP_VS_TCP_S_TIME_WAIT] = 2*60*HZ,
[IP_VS_TCP_S_CLOSE] = 10*HZ,
[IP_VS_TCP_S_CLOSE_WAIT] = 60*HZ,
[IP_VS_TCP_S_LAST_ACK] = 30*HZ,
[IP_VS_TCP_S_LISTEN] = 2*60*HZ,
[IP_VS_TCP_S_SYNACK] = 120*HZ,
[IP_VS_TCP_S_LAST] = 2*HZ,
};
#define sNO IP_VS_TCP_S_NONE
#define sES IP_VS_TCP_S_ESTABLISHED
#define sSS IP_VS_TCP_S_SYN_SENT
#define sSR IP_VS_TCP_S_SYN_RECV
#define sFW IP_VS_TCP_S_FIN_WAIT
#define sTW IP_VS_TCP_S_TIME_WAIT
#define sCL IP_VS_TCP_S_CLOSE
#define sCW IP_VS_TCP_S_CLOSE_WAIT
#define sLA IP_VS_TCP_S_LAST_ACK
#define sLI IP_VS_TCP_S_LISTEN
#define sSA IP_VS_TCP_S_SYNACK
static struct tcp_states_t tcp_states[] = {
/* INPUT ip_vs_in调用 */
/* sNO, sES, sSS, sSR, sFW, sTW, sCL, sCW, sLA, sLI, sSA 初始状态 */
/*syn*/ {{sSR, sES, sES, sSR, sSR, sSR, sSR, sSR, sSR, sSR, sSR }},
/*fin*/ {{sCL, sCW, sSS, sTW, sTW, sTW, sCL, sCW, sLA, sLI, sTW }},
/*ack*/ {{sES, sES, sSS, sES, sFW, sTW, sCL, sCW, sCL, sLI, sES }},
/*rst*/ {{sCL, sCL, sCL, sSR, sCL, sCL, sCL, sCL, sLA, sLI, sSR }},
/* OUTPUT ip_vs_out调用 */
/* sNO, sES, sSS, sSR, sFW, sTW, sCL, sCW, sLA, sLI, sSA 初始状态 */
/*syn*/ {{sSS, sES, sSS, sSR, sSS, sSS, sSS, sSS, sSS, sLI, sSR }},
/*fin*/ {{sTW, sFW, sSS, sTW, sFW, sTW, sCL, sTW, sLA, sLI, sTW }},
/*ack*/ {{sES, sES, sSS, sES, sFW, sTW, sCL, sCW, sLA, sES, sES }},
/*rst*/ {{sCL, sCL, sSS, sCL, sCL, sTW, sCL, sCL, sCL, sCL, sCL }},
/* INPUT-ONLY ip_vs_in在没有收到回包时调用*/
/* sNO, sES, sSS, sSR, sFW, sTW, sCL, sCW, sLA, sLI, sSA */
/*syn*/ {{sSR, sES, sES, sSR, sSR, sSR, sSR, sSR, sSR, sSR, sSR }},
/*fin*/ {{sCL, sFW, sSS, sTW, sFW, sTW, sCL, sCW, sLA, sLI, sTW }},
/*ack*/ {{sES, sES, sSS, sES, sFW, sTW, sCL, sCW, sCL, sLI, sES }},
/*rst*/ {{sCL, sCL, sCL, sSR, sCL, sCL, sCL, sCL, sLA, sLI, sCL }},
};
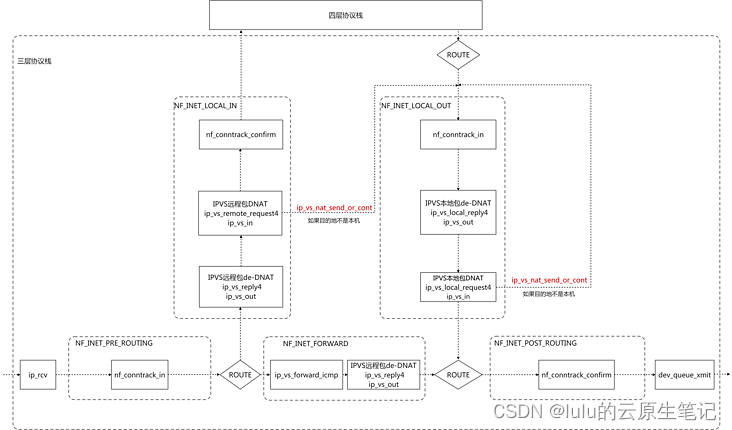
ipvs nat模式下DNAT在哪里做的
HOOK 函数 核心函数
NF_INET_LOCAL_IN ip_vs_reply4 ip_vs_out
NF_INET_LOCAL_IN ip_vs_remote_request4 ip_vs_in
NF_INET_LOCAL_OUT ip_vs_local_reply4 ip_vs_out
NF_INET_LOCAL_OUT ip_vs_local_request4 ip_vs_in
NF_INET_FORWARD ip_vs_forward_icmp ip_vs_in_icmp
NF_INET_FORWARD ip_vs_reply4 ip_vs_out
ipvs在input,在output注册了ip_vs_remote_request4和ip_vs_local_request4,这些都对应ip_vs_in函数,这个逻辑就是负责做DNAT的
ip_vs_in函数分析:
-
数据包四元组匹配到了连接记录
-
连接不复用
- 释放连接
- 连接复用
-
复用连接
- 数据包四元组没有匹配到连接记录,或者连接被释放
-
-
目的地是虚拟服务器
- 分配后端,新建连接
-
目的地不是虚拟服务器
- 返回ACCEPT
-
统计计数,更新四层协议连接状态
-
执行DNAT,转发数据包到LOCAL_OUT
-
更新连接保持时间
源码剖析:
/*
* Check if it's for virtual services, look it up,
* and send it on its way...
*/
static unsigned int
ip_vs_in(struct netns_ipvs *ipvs, unsigned int hooknum, struct sk_buff *skb, int af)
{
struct ip_vs_iphdr iph;
struct ip_vs_protocol *pp;
struct ip_vs_proto_data *pd;
struct ip_vs_conn *cp;
int ret, pkts;
int conn_reuse_mode;
struct sock *sk;
/* 已经被ipvs处理过则不处理 */
/* Already marked as IPVS request or reply? */
if (skb->ipvs_property)
return NF_ACCEPT;
/*
* Big tappo:
* - remote client: only PACKET_HOST
* - route: used for struct net when skb->dev is unset
*/
if (unlikely((skb->pkt_type != PACKET_HOST &&
hooknum != NF_INET_LOCAL_OUT) ||
!skb_dst(skb))) {
ip_vs_fill_iph_skb(af, skb, false, &iph);
IP_VS_DBG_BUF(12, "packet type=%d proto=%d daddr=%s"
" ignored in hook %u\n",
skb->pkt_type, iph.protocol,
IP_VS_DBG_ADDR(af, &iph.daddr), hooknum);
return NF_ACCEPT;
}
/* ipvs enabled in this netns ? */
if (unlikely(sysctl_backup_only(ipvs) || !ipvs->enable))
return NF_ACCEPT;
/* 获取ip头 */
ip_vs_fill_iph_skb(af, skb, false, &iph);
/* 获取数据包所属sock */
/* Bad... Do not break raw sockets */
sk = skb_to_full_sk(skb);
if (unlikely(sk && hooknum == NF_INET_LOCAL_OUT &&
af == AF_INET)) {
if (sk->sk_family == PF_INET && inet_sk(sk)->nodefrag)
return NF_ACCEPT;
}
#ifdef CONFIG_IP_VS_IPV6
if (af == AF_INET6) {
if (unlikely(iph.protocol == IPPROTO_ICMPV6)) {
int related;
int verdict = ip_vs_in_icmp_v6(ipvs, skb, &related,
hooknum, &iph);
if (related)
return verdict;
}
} else
#endif
if (unlikely(iph.protocol == IPPROTO_ICMP)) {
int related;
int verdict = ip_vs_in_icmp(ipvs, skb, &related,
hooknum);
if (related)
return verdict;
}
/* Protocol supported? */
/* 判断是否为ipvs支持的协议 */
pd = ip_vs_proto_data_get(ipvs, iph.protocol);
if (unlikely(!pd)) {
/* The only way we'll see this packet again is if it's
* encapsulated, so mark it with ipvs_property=1 so we
* skip it if we're ignoring tunneled packets
*/
if (sysctl_ignore_tunneled(ipvs))
skb->ipvs_property = 1;
return NF_ACCEPT;
}
pp = pd->pp;
/*
* Check if the packet belongs to an existing connection entry
*/
/* 在ipvs连接跟踪表里查找数据包所属连接 */
cp = INDIRECT_CALL_1(pp->conn_in_get, ip_vs_conn_in_get_proto,
ipvs, af, skb, &iph);
/* conn_reuse_mode是ipvs连接复用参数
* frag是分片偏移量
* is_new_conn()是判断tcp头的syn标志位
*/
conn_reuse_mode = sysctl_conn_reuse_mode(ipvs);
if (conn_reuse_mode && !iph.fragoffs && is_new_conn(skb, &iph) && cp) {
/* 找到了所属连接并且是SYN,非分片,reuse_mode==1,时会走到这里 */
bool uses_ct = false, resched = false;
/* 判断expire_nodest_conn和连接的目的地的weight */
if (unlikely(sysctl_expire_nodest_conn(ipvs)) && cp->dest &&
unlikely(!atomic_read(&cp->dest->weight))) {
/* expire_nodest_conn表示释放不可用后端的连接
* 后端不可用会走到这里
*/
resched = true;
/* 是否使用了nf_conntrack */
uses_ct = ip_vs_conn_uses_conntrack(cp, skb);
/* 判断之前的连接是否可以释放 */
} else if (is_new_conn_expected(cp, conn_reuse_mode)) {
/* 是否使用了nf_conntrack */
uses_ct = ip_vs_conn_uses_conntrack(cp, skb);
if (!atomic_read(&cp->n_control)) {
resched = true;
} else {
/* Do not reschedule controlling connection
* that uses conntrack while it is still
* referenced by controlled connection(s).
*/
resched = !uses_ct;
}
}
if (resched) {
/* 提前释放之前的连接 */
if (!atomic_read(&cp->n_control))
ip_vs_conn_expire_now(cp);
__ip_vs_conn_put(cp);
/* 这里有一个bug,如果使用了conntrack,直接丢包,客户端必须重传
* 重传导致产生1s延迟 */
if (uses_ct)
return NF_DROP;
cp = NULL;
}
}
if (unlikely(!cp)) {
/* 没有连接记录和不复用连接记录会走到这里 */
int v;
/* 进行连接记录的创建和目的地的确认 */
if (!ip_vs_try_to_schedule(ipvs, af, skb, pd, &v, &cp, &iph))
/* 没有匹配到service的不属于ipvs的数据包返回ACCEPT */
return v;
}
/* 属于IPVS的service的数据包会走到这里 */
IP_VS_DBG_PKT(11, af, pp, skb, iph.off, "Incoming packet");
/* Check the server status */
if (cp->dest && !(cp->dest->flags & IP_VS_DEST_F_AVAILABLE)) {
/* the destination server is not available */
__u32 flags = cp->flags;
/* when timer already started, silently drop the packet.*/
if (timer_pending(&cp->timer))
__ip_vs_conn_put(cp);
else
ip_vs_conn_put(cp);
if (sysctl_expire_nodest_conn(ipvs) &&
!(flags & IP_VS_CONN_F_ONE_PACKET)) {
/* try to expire the connection immediately */
ip_vs_conn_expire_now(cp);
}
return NF_DROP;
}
/* 统计计数 */
ip_vs_in_stats(cp, skb);
/* 更新四层协议连接状态 */
ip_vs_set_state(cp, IP_VS_DIR_INPUT, skb, pd);
if (cp->packet_xmit)
/* DNAT之后,发送数据包
这里packet_xmit是个函数指针,具体对应的函数由ipvs运行模式而定
* 发送成功ret = NF_STOLEN
*/
ret = cp->packet_xmit(skb, cp, pp, &iph);
/* do not touch skb anymore */
else {
IP_VS_DBG_RL("warning: packet_xmit is null");
ret = NF_ACCEPT;
}
/* Increase its packet counter and check if it is needed
* to be synchronized
*
* Sync connection if it is about to close to
* encorage the standby servers to update the connections timeout
*
* For ONE_PKT let ip_vs_sync_conn() do the filter work.
*/
if (cp->flags & IP_VS_CONN_F_ONE_PACKET)
pkts = sysctl_sync_threshold(ipvs);
else
pkts = atomic_add_return(1, &cp->in_pkts);
if (ipvs->sync_state & IP_VS_STATE_MASTER)
ip_vs_sync_conn(ipvs, cp, pkts);
else if ((cp->flags & IP_VS_CONN_F_ONE_PACKET) && cp->control)
/* increment is done inside ip_vs_sync_conn too */
atomic_inc(&cp->control->in_pkts);
/* 更新连接记录保持时间 */
ip_vs_conn_put(cp);
return ret;
}
上述对于包的处理调用了packet_xmit这个函数,这个是一个函数指针,具体由ipvs模式来决定初始化的时候是哪个函数,nat模式下,会被初始化为:ip_vs_nat_xmit
struct ip_vs_conn {
struct list_head c_list; /* 用于连接到哈希表 */
__u32 caddr; /* 客户端IP地址 */
__u32 vaddr; /* 虚拟IP地址 */
__u32 daddr; /* 真实服务器IP地址 */
__u16 cport; /* 客户端端口 */
__u16 vport; /* 虚拟端口 */
__u16 dport; /* 真实服务器端口 */
__u16 protocol; /* 协议类型(UPD/TCP) */
...
/* 用于发送数据包的接口 */
int (*packet_xmit)(struct sk_buff *skb, struct ip_vs_conn *cp);
...
};
packet_xmit初始化:
static inline void ip_vs_bind_xmit(struct ip_vs_conn *cp)
{
switch (IP_VS_FWD_METHOD(cp)) {
case IP_VS_CONN_F_MASQ: // NAT模式
cp->packet_xmit = ip_vs_nat_xmit;
break;
case IP_VS_CONN_F_TUNNEL: // TUN模式
cp->packet_xmit = ip_vs_tunnel_xmit;
break;
case IP_VS_CONN_F_DROUTE: // DR模式
cp->packet_xmit = ip_vs_dr_xmit;
break;
...
}
}
在nat模式下,其实最终调用packet_xmit,实际就是调用了ip_vs_nat_xmit:
int ip_vs_nat_xmit(struct sk_buff *skb, struct ip_vs_conn *cp,
struct ip_vs_protocol *pp, struct ip_vs_iphdr *ipvsh)
{
struct rtable *rt; /* Route to the other host */
int local, rc, was_input;
EnterFunction(10);
rcu_read_lock();
/* check if it is a connection of no-client-port */
if (unlikely(cp->flags & IP_VS_CONN_F_NO_CPORT)) {
__be16 _pt, *p;
p = skb_header_pointer(skb, ipvsh->len, sizeof(_pt), &_pt);
if (p == NULL)
goto tx_error;
ip_vs_conn_fill_cport(cp, *p);
IP_VS_DBG(10, "filled cport=%d\n", ntohs(*p));
}
was_input = rt_is_input_route(skb_rtable(skb));
// 找到真实服务器IP的路由信息
//根据 cp->daddr.ip 查找路由,而不是根据skb中的目的ip(vip)
local = __ip_vs_get_out_rt(cp->af, skb, cp->dest, cp->daddr.ip,
IP_VS_RT_MODE_LOCAL |
IP_VS_RT_MODE_NON_LOCAL |
IP_VS_RT_MODE_RDR, NULL, ipvsh);
if (local < 0)
goto tx_error;
rt = skb_rtable(skb);
...
// 调用协议相关的 tcp_dnat_handler,修改数据包的目的port为cp->dport
/* mangle the packet */
if (pp->dnat_handler && !pp->dnat_handler(skb, pp, cp, ipvsh))
goto tx_error;
// 修改目标IP地址为真实服务器IP地址
ip_hdr(skb)->daddr = cp->daddr.ip;
// 重新计算校验和
ip_send_check(ip_hdr(skb));
IP_VS_DBG_PKT(10, AF_INET, pp, skb, 0, "After DNAT");
/* FIXME: when application helper enlarges the packet and the length
is larger than the MTU of outgoing device, there will be still
MTU problem. */
/* Another hack: avoid icmp_send in ip_fragment */
skb->ignore_df = 1;
rc = ip_vs_nat_send_or_cont(NFPROTO_IPV4, skb, cp, local);
rcu_read_unlock();
LeaveFunction(10);
return rc;
tx_error:
kfree_skb(skb);
rcu_read_unlock();
LeaveFunction(10);
return NF_STOLEN;
}
static inline int ip_vs_nat_send_or_cont(int pf, struct sk_buff *skb,
struct ip_vs_conn *cp, int local)
{
int ret = NF_STOLEN;
skb->ipvs_property = 1;
if (likely(!(cp->flags & IP_VS_CONN_F_NFCT)))
ip_vs_notrack(skb);
else
ip_vs_update_conntrack(skb, cp, 1);
/* Remove the early_demux association unless it's bound for the
* exact same port and address on this host after translation.
*/
if (!local || cp->vport != cp->dport ||
!ip_vs_addr_equal(cp->af, &cp->vaddr, &cp->daddr))
ip_vs_drop_early_demux_sk(skb);
if (!local) {
skb_forward_csum(skb);
// 同样的,将dnat后的数据包调用local out发送出去
NF_HOOK(pf, NF_INET_LOCAL_OUT, skb, NULL, skb_dst(skb)->dev,
dst_output);
} else
ret = NF_ACCEPT;
return ret;
}
调用分析:
ip_vs_in -> packet_xmit == ip_vs_nat_xmit -> ip_vs_nat_send_or_cont
packet_xmit在nat模式下实际就是: ip_vs_nat_xmit -> ip_vs_nat_send_or_cont
ipvs nat模式下SNAT在哪里做的
为什么需要SNAT:
到达lb的数据流为:cip:cport->vip:vport,
经过dnat后的数据流为:cip:cport->rip:rport.
rs处理完后的响应数据流为:rip:rport->cip:cport
需要将rip:rport还原成vip:vport,所以此数据流必须发给lb做snat。
为什么需要将rs的默认网关指向lb:
因为目的ip不是lb的ip,所以必须将rs的默认网关指向lb。当数据流到达lb后,查找路由表发现目的ip不是lb的ip,所以需要转发此数据包(必须保证net.ipv4.ip_forward = 1),将走ip_forward函数转发,函数最后需要经过NF_INET_FORWARD hook点的处理
该hook定义:
NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD, skb, skb->dev,
rt->dst.dev, ip_forward_finish);
此hook点注册了两个和ipvs相关的函数ip_vs_forward_icmp和ip_vs_reply4,很显然前一个是处理icmp的,重点是ip_vs_reply4,这里面如果匹配到了ipvs连接表,就做snat
static unsigned int
ip_vs_reply4(const struct nf_hook_ops *ops, struct sk_buff *skb,
const struct net_device *in, const struct net_device *out,
int (*okfn)(struct sk_buff *))
{
return ip_vs_out(ops->hooknum, skb, AF_INET);
}
static unsigned int
ip_vs_out(unsigned int hooknum, struct sk_buff *skb, int af)
{
struct net *net = NULL;
struct ip_vs_iphdr iph;
struct ip_vs_protocol *pp;
struct ip_vs_proto_data *pd;
struct ip_vs_conn *cp;
EnterFunction(11);
/* Already marked as IPVS request or reply? */
if (skb->ipvs_property)
return NF_ACCEPT;
/* Bad... Do not break raw sockets */
if (unlikely(skb->sk != NULL && hooknum == NF_INET_LOCAL_OUT &&
af == AF_INET)) {
struct sock *sk = skb->sk;
struct inet_sock *inet = inet_sk(skb->sk);
if (inet && sk->sk_family == PF_INET && inet->nodefrag)
return NF_ACCEPT;
}
if (unlikely(!skb_dst(skb)))
return NF_ACCEPT;
net = skb_net(skb);
if (!net_ipvs(net)->enable)
return NF_ACCEPT;
ip_vs_fill_iph_skb(af, skb, &iph);
#ifdef CONFIG_IP_VS_IPV6
if (af == AF_INET6) {
if (unlikely(iph.protocol == IPPROTO_ICMPV6)) {
int related;
int verdict = ip_vs_out_icmp_v6(skb, &related,
hooknum, &iph);
if (related)
return verdict;
}
} else
#endif
if (unlikely(iph.protocol == IPPROTO_ICMP)) {
int related;
int verdict = ip_vs_out_icmp(skb, &related, hooknum);
if (related)
return verdict;
}
pd = ip_vs_proto_data_get(net, iph.protocol);
if (unlikely(!pd))
return NF_ACCEPT;
pp = pd->pp;
/* reassemble IP fragments */
#ifdef CONFIG_IP_VS_IPV6
if (af == AF_INET)
#endif
if (unlikely(ip_is_fragment(ip_hdr(skb)) && !pp->dont_defrag)) {
if (ip_vs_gather_frags(skb,
ip_vs_defrag_user(hooknum)))
return NF_STOLEN;
ip_vs_fill_ip4hdr(skb_network_header(skb), &iph);
}
/*
* Check if the packet belongs to an existing entry
*/
// 因为从client到rs是通过cip和cport创建的连接表,所以反方向
// 是通过目的ip和port(也就是cip和cport)查找是否有连接表
cp = pp->conn_out_get(af, skb, &iph, 0);
// 如果查找到连接表,才需要处理
if (likely(cp))
return handle_response(af, skb, pd, cp, &iph);
...
}
static unsigned int
handle_response(int af, struct sk_buff *skb, struct ip_vs_proto_data *pd,
struct ip_vs_conn *cp, struct ip_vs_iphdr *iph)
{
struct ip_vs_protocol *pp = pd->pp;
IP_VS_DBG_PKT(11, af, pp, skb, 0, "Outgoing packet");
if (!skb_make_writable(skb, iph->len))
goto drop;
/* mangle the packet */
//调用协议相关的 snat_handler 处理数据包,即
// tcp_snat_handler将源port换成vport
if (pp->snat_handler && !pp->snat_handler(skb, pp, cp, iph))
goto drop;
{
//修改源ip为vaddr
ip_hdr(skb)->saddr = cp->vaddr.ip;
ip_send_check(ip_hdr(skb));
}
/*
* nf_iterate does not expect change in the skb->dst->dev.
* It looks like it is not fatal to enable this code for hooks
* where our handlers are at the end of the chain list and
* when all next handlers use skb->dst->dev and not outdev.
* It will definitely route properly the inout NAT traffic
* when multiple paths are used.
*/
/* For policy routing, packets originating from this
* machine itself may be routed differently to packets
* passing through. We want this packet to be routed as
* if it came from this machine itself. So re-compute
* the routing information.
*/
if (ip_vs_route_me_harder(af, skb))
goto drop;
IP_VS_DBG_PKT(10, af, pp, skb, 0, "After SNAT");
ip_vs_out_stats(cp, skb);
ip_vs_set_state(cp, IP_VS_DIR_OUTPUT, skb, pd);
skb->ipvs_property = 1;
if (!(cp->flags & IP_VS_CONN_F_NFCT))
ip_vs_notrack(skb);
else
ip_vs_update_conntrack(skb, cp, 0);
ip_vs_conn_put(cp);
LeaveFunction(11);
//最后返回accept即可,从hook函数返回后,会调用
//ip_forward_finish最终发给client端
return NF_ACCEPT;
drop:
ip_vs_conn_put(cp);
kfree_skb(skb);
LeaveFunction(11);
return NF_STOLEN;
}