文章目录
- 1 前言
- 2 分割数据集格式
- 2.1 原始图像
- 2.2 分割标注
- 2.3 文件名信息
- 3 制作COCO格式基本流程
- 4 根据分割标注制作COCO标注(核心)
- Main
1 前言
最近要开始实例分割任务,由于实例分割是建立再目标检测基础之上的,因此需要制作能用于目标检测的数据集,选择通用的COCO格式数据集进行制作,COCO目标检测数据集简单介绍https://blog.csdn.net/qq_44776065/article/details/128695821,我们基于上述文章进行制作
2 分割数据集格式
分割数据集基本框架如图所示
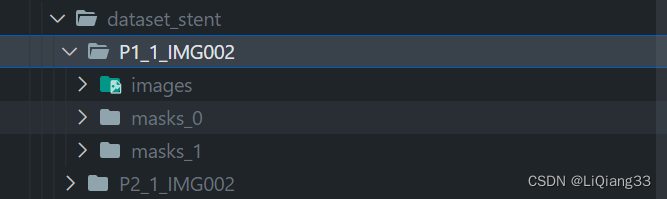
单个病人由原图images和两个不同标签mask_0与mask_1组成,每个IMG组成一个文件夹作为一个样例
2.1 原始图像
- 单个样例
images中的原始图片
- 单个样例由二维的切片序列组成,且具有
三维空间连续性:
2.2 分割标注
标注部分如图所示,类似于二值图像,白色前景的像素值为255,黑色背景的像素值为0

2.3 文件名信息
每个样例文件夹下的文件名均为P1_1_IMG002_frame032.png组成,其中:
P1_1_IMG002为样例信息frame032为顺序信息,用于图片的ID
3 制作COCO格式基本流程
制作原则:单个IMG制作一个标注文件,作为一个样例
根据输入图片的格式,制作的基本步骤为:
- 首先制作
images中的内容,保存图片的基本信息,file_name的值需要采用相对于数据集根路径的文件名,id为frame+1000其中的1000来标记图片信息与P1_1_IMG002中的第二个1对齐,其属于某类文件,因为其文件个数不会超过999(数据集特性) - 制作
categories中的内容,这部分类是规定好的,直接指定ID和Name即可 - 制作
annotations中的内容,这部分是核心内容,section4具体介绍;其基本思想就是提取标注的外轮廓,从而获取外接矩形信息,轮廓信息,面积信息
Code:
准备全局信息
annotations = {
"images": [],
"annotations": [],
"categories": [
{"id": 1, "name": "cerebral"},
{"id": 2, "name": "stent"}
]
}
制作单个标注图像
def write_single_slice_anno(image_path, category=1):
"""
根据单个图片的路径, 读取图片并制作annotations.json中的信息
params: image_path文件的绝对路径, example: r"D:OCT_Dataset_Project/dataset/dataset_stent/P1_1_IMG002/images/P1_1_IMG002_frame032.png"
params: category两种不同的标注
"""
# 1. 制作images
# 获取image_id 与 IMG信息
_, filename = os.path.split(image_path)
image_id = int(filename[-7:-4]) + 1000 # 1021 表示术后
filename_dir = filename[0: -13]
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 由于两类图片的类型一致, 只写入一次images信息
if category == 1:
file_name = f"{filename_dir}/{filename}"
height = image.shape[0]
width = image.shape[1]
annotations["images"].append({
"file_name": file_name,
"id": image_id,
"height": height,
"width": width
})
# 2 制作annotations
# 第1类数据只有一个连通区域, 2类数据分别取出不同目标的连通区域
if category == 1:
imgs = [image]
else:
imgs = get_single_mask_from_image(image)
# 对多个连通区域进行处理, 共同属于P1_1_IMG002_frame032的标注
for img in imgs:
# 使用全局变量ANNOTATION_NUMS, 作为标注的ID, 单个病人从1开始向后排
global ANNOTATION_NUMS
ANNOTATION_NUMS += 1 # 更新ANNO_NUM, 标注的ID
# 获取bbox, area, seg信息, seg为polygon
bbox, area, seg = get_annotation_from_single_image(img, filename=image_path)
annotations["annotations"].append({
"segmentation": [seg], # 这里物体是一体的,是二维数组 [[1, 2, ....]]
"area": area,
"bbox": bbox, # 一维数组
"iscrowd": 0,
"image_id": image_id,
"category_id": category,
"id": ANNOTATION_NUMS
})
制作整个样例
def write_patient_IMG_anno(dataset_root, patient_img_dir):
# 用于查找符合patient_img_dir的re_str_path
re_path = fr'D:\Learning\OCT\oct-dataset-master\dataset\dataset_stent\{patient_img_dir}\masks_0\{patient_img_dir}_frame*.png'
filepaths = glob.glob(re_path)
# 遍历文件路径进行处理
for filepath in filepaths:
# 处理第一类标注
masks_0_filepath = filepath
write_single_slice_anno(image_path=masks_0_filepath, category=1)
# 处理第二类标注
masks_1_filepath = filepath.replace("masks_0", "masks_1")
write_single_slice_anno(image_path=masks_1_filepath, category=2)
# 写入json
json_file = f'{dataset_root}/{patient_img_dir}_annotations.json'
with open(json_file, 'w') as f:
json.dump(annotations, fp=f)
4 根据分割标注制作COCO标注(核心)
根据二值分割标注制作COCO格式,基本思路:
-
对标注图像进行
阈值化处理,防止出现除0或者255之外的值,本次处理的图像都是8bit,单通道灰度图 -
对于阈值化处理之后的图像,再对不同类型的标注图像进行处理,
category_id=1的图像只允许由一个连通区域(标注特性);category_id=2的图像有多个连通区域,分别提取这些连通区域,将单个连通区域绘制为单个二值图像后返回 -
对于阈值处理之后的图像,提取
其轮廓,方式为:提取所有轮廓并保留,保留轮廓关键点;关于轮廓提取方式参考:https://blog.csdn.net/weixin_43869605/article/details/119921444 -
对
提取的轮廓获取其最大外接矩形,获取轮廓的面积,将轮廓点转化为coco polygon格式,并返回获取的bbox,area,segmentation信息
Code:
获取连通区域的图片
# 获取连通区域
def get_masks_from_image(stent_image):
# 提取标签和数目
num, labels = cv2.connectedComponents(image=stent_image) # 直接提取图片的连通区域 #num检测的值为2
# 数目作为类型,保存到字典中
labels_dict = {i: [] for i in range(1, num)} # num多检测了一个
# 遍历像素点,label像素值在label_dict中, 保存到类型字典的数组中
for h in range(stent_image.shape[0]):
for w in range(stent_image.shape[1]):
if labels[h, w] in labels_dict:
labels_dict[labels[h, w]].append([h, w])
# 绘制支架点所在的区域
imgs = []
for key in labels_dict:
# 如何取得拿块区域
img = np.zeros(stent_image.shape, dtype=np.uint8)
for point in labels_dict[key]:
img[point[0], point[1]] = 255
imgs.append(img)
# imgs.pop() # 不知道为什么,图像中数组元素多一个
return imgs
获取标注信息
# 获取标注信息
def get_annotations_from_single_image(image, filename):
## 对图片进行阈值处理
ret, thresh = cv2.threshold(image, 128, 255, cv2.THRESH_BINARY_INV)
# 取轮廓方式 检测所有的轮廓(RETR_TREE), 以只保留重点部分的形式输出轮廓
contours, hierarchy = cv2.findContours(thresh, mode=cv2.RETR_TREE, method=cv2.CHAIN_APPROX_SIMPLE)
# 标注异常检测1: 输出有多个区域的情况,进行检测
if len(contours) > 2:
print("contour > 2 :", filename)
main_contour = contours[1] # 取第一个轮廓
# 标注异常检测2: 检测是否有单个点
if len(main_contour) < 5:
print("main_contour points is low", filename)
# 计算最外面的矩形边界
x, y, w, h = cv2.boundingRect(main_contour)
bbox = [float(x), float(y), float(w), float(h)]
# 计算轮廓的面积
main_contour_area = cv2.contourArea(main_contour)
# 取多边形的点,组成segmentation格式
seg = []
for pt in main_contour:
seg.append(float(pt[0][0]))
seg.append(float(pt[0][1]))
return bbox, main_contour_area, seg
Main
if __name__ == "__main__":
dataset_root = '../dataset/dataset_stent_coco'
# 每个文件单独执行
# P1_1_IMG002
write_patient_IMG_anno(dataset_root=dataset_root, patient_img_dir="P1_1_IMG002")
参考:
COCO_01 数据集介绍 COCO目标检测分割数据集格式: https://blog.csdn.net/qq_44776065/article/details/128695821
cv2.findContours(): https://blog.csdn.net/weixin_43869605/article/details/119921444
python-opencv 实现连通域处理函数 cv2.connectedComponentsWithStats()和cv2.connectedComponents()
https://blog.csdn.net/qq_40784418/article/details/106023288