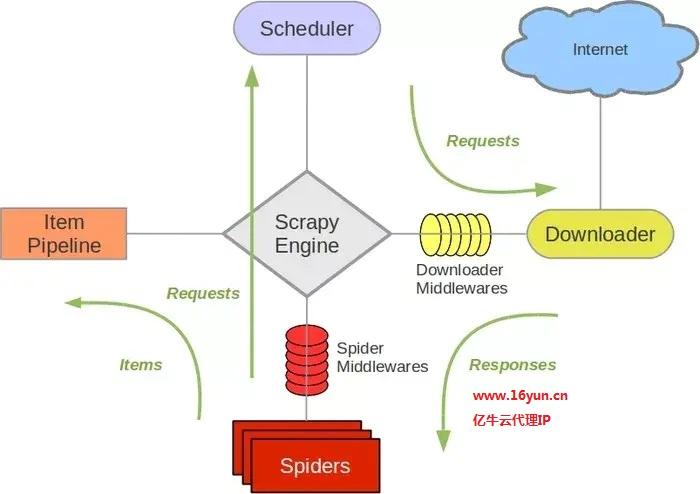
Scrapy 框架
Scrapy实例
下载安装
pip install scrapy
Hello World
创建工程
在 cmd 下切换到想创建 scrapy 项目的地方,然后使用命名
scrapy startproject tutorial
注:tutorial 为工程名
然后就会发现在当前位置会多出一个文件夹,名字是 tutorial。它的目录结构是这样的:
tutorial/
scrapy.cfg
tutorial/
spiders/
init.py
init.py
items.py
pipelines.py
settings.py
注:
scrapy.cfg 是该项目的全局配置文件
tutorial/: 该项目的python模块。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录.
定义 Item
Item 是保存爬取到的数据的容器;其使用方法和python字典类似。虽然您也可以在 Scrapy 中直接使用dict,但是 Item 提供了额外保护机制来避免拼写错误导致的未定义字段错误。
这里这样写
-- coding: utf-8 --
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
DmozItem 为该 Item 的名字, 该类是一个 scrapy.Item 类。
我这里想获取到的信息是 title、link 和 desc 这三个字段,它们都是 scrapy.Field 类型的。
编写爬虫
在 tutorial/spiders/ 下创建一个 py 文件 dmoz_spider.py,它是这样定义的:
import scrapy
from tutorial.items import DmozItem
class DmozSpider(scrapy.Spider):
name = ‘dmoz’
allowed_domains = [‘dmoz.org’]
start_urls = [
“http://www.dmoz.org/Computers/Programming/Languages/Python/Books/”,
“http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/”
]
def parse(self, response):
sel = Selector(response)
sites = sel.xpath(’//ul[@class=“directory-url”]/li’)
for sel in sites:
item = DmozItem() # 实例化一个 DmozItem 类
item[‘title’] = sel.xpath(‘a/text()’).extract()
item[‘link’] = sel.xpath(‘a/@href’).extract()
item[‘desc’] = sel.xpath(‘text()’).extract()
yield item
爬虫类必须继承自 scrapy.Spider 类, 且定义一些属性:
name: 用于区别 Spider。 该名字必须是唯一的,不可以为不同的 Spider 设定相同的名字。
start_urls: 包含了 Spider 在启动时进行爬取的 url 列表。 因此,第一个被获取到的页面将是其中之一, 后续的URL则从初始的URL获取到的数据中提取。
parse() 是 spider 的一个方法。 被调用时,每个初始 URL 完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成 item )以及生成需要进一步处理的 URL 的 Request 对象。scrapy 为 Spider 的 start_urls 属性中的每个URL创建了 scrapy.Request 对象,并将 parse 方法作为回调函数(callback)赋值给了 Request。Request 对象经过调度,执行生成 scrapy.http.Response 对象并送回给 spider parse() 方法, 一般返回 Item 实例。
爬取
进入该工程目录,本例中就是 tutorial/, 在命令行执行
scrapy crawl dmoz
保存
可以使用如下命令
scrapy crawl dmoz -o items.json
该命令是说将结果保存在 items.json 文件中。
常用的命令行工具
创建项目
scrapy startproject myproject
帮助信息
scrapy -h
帮助信息
scrapy -h
使用下载器下载指定的url,并将获取到的内容送到标准输出
scrapy fetch
在浏览器中打开给定的URL,并以Scrapy spider获取到的形式展现
scrapy view
以给定的URL(如果给出)或者空(没有给出URL)启动Scrapy shell
scrapy shell [url]
#在未创建项目的情况下,运行一个编写在Python文件中的spider
scrapy runspider <spider_file.py>
获取Scrapy的设定
scrapy settings [options]
-------------------------以上不需要项目,以下需要在项目中----------------------------------------
使用 template 模版来信创建一个 spider, name 值为, allowed_domains 值为
scrapy genspider [-t template]
查看可用的模版,默认有 basic、crawl、csvfeed 和 xmlfeed 4个
scrapy genspider -l
查看 TEMPLATE 信息
scrapy genspider -d TEMPLATE
使用进行爬取数据
scrapy crawl
列出当前项目中所有可用的 spider
scrapy list
运行contract检查。
scrapy check [-l]
获取给定的URL并使用相应的spider分析处理,可以解析成自己写的 item
scrapy parse [options] 以上4章节是关于Scrapy基础的详细介绍,当然HTTP代理也要选择一些更加稳定的爬虫IP配合爬虫程序一起采集(亿牛云http代理www.16yun.cn),才能更加高效稳定的采集数据。