前不久OpenAI发布全新模型——o1模型,也就是业界说的“草莓模型”,包含三款型号:OpenAI o1、OpenAI o1-preview和OpenAI o1-mini。

其中,OpenAI o1-mini和 o1-preview已经对用户开放使用:
OpenAI o1:高级推理模型,暂不对外开放;
OpenAI o1-preview:这个版本更注重深度推理处理,每周可以使用50条;
OpenAI o1-mini:这个版本更高效、划算,适用于编码任务,每天都能使用50条。
不过,从OpenAI文章中的附录来看,这次放出的preview和mini似乎都只是o1的阉割版,OpenAI o1更加值得期待。
o1模型推理能力大幅提升
对于为什么不用过去GPT系列命名,而是重新起了一个o系列,OpenAI的首席研究官鲍勃·麦格鲁(Bob McGrew)在一次采访中透露,“o1”这个名字是为了表示“将计数器重置为1”。这意味着OpenAI希望通过这个模型,重新定义人工智能的推理能力,开启一个新的纪元。
根据OpenAI的技术报告显示:
编程方面,模型在Codeforces竞赛上超过了83%的专业人员,要知道这是个很厉害的竞赛;
数学方面,以2024年的美国数学邀请赛为测试集,o1单次生成可解决74%的问题,多次生成后进一步提升正确率到83%,而GPT-4只能解决12%的问题;
科学方面,模型GPQA Dimond测试集正确率78%,超越人类专家70%水平。
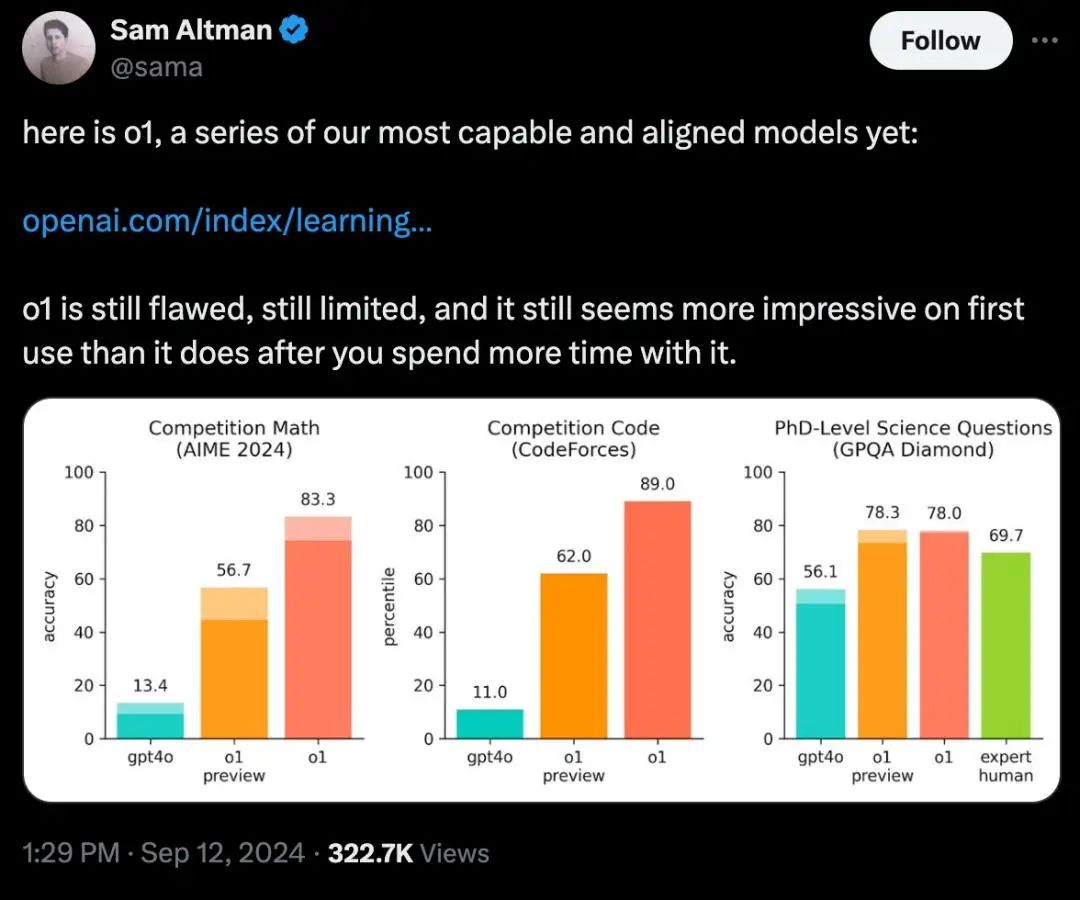
和之前的大语言模型相比,全新的o1系列,在复杂推理上的性能又提升到了一个全新级别,主要体现在数据分析、数学和编程方面,可以说拥有了真正的通用推理能力。
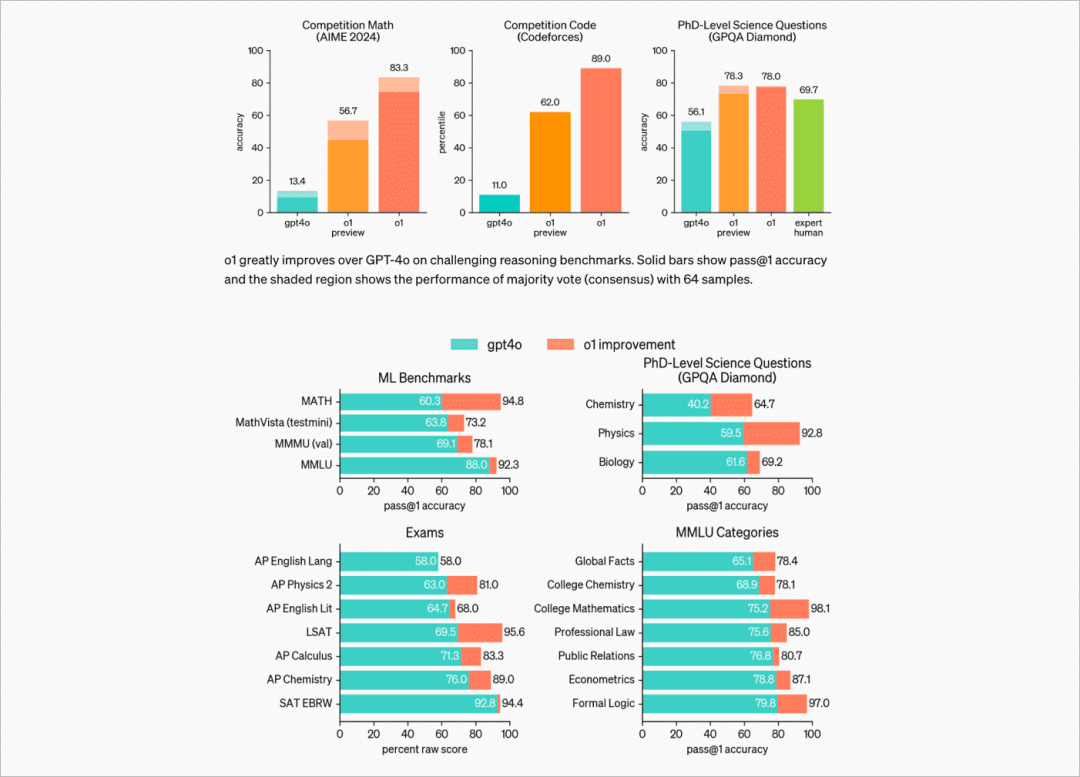
OpenAI称,这是它目前为止推理能力最好的模型,下一个模型将在物理、化学和生物学方面达到与博士生接近的水平。
o1模型背后的原理
OpenAI的研究负责人杰里·特沃瑞克(Jerry Tworek)表示,o1背后的训练与前代产品有本质区别。他透露,o1“采用了全新的优化算法和专门为其定制的新训练数据集”。这种新的训练方法,使得o1在处理复杂推理任务时,能够更加准确和高效。
OpenAI的o1模型在设计之初就瞄准了复杂推理任务,这些任务通常需要模型具备高度的逻辑推理能力和深度学习能力。为了实现这一目标,OpenAI采用了强化学习(Reinforcement Learning, RL)作为其核心训练方法。通过强化学习,o1学会了识别并纠正自己的错误,并将复杂的步骤分解为更简单的步骤。在当前方法不起作用时,它还会尝试不同的方法。这个过程显著提高了模型的推理能力。
在OpenAI o1发布后不久,其团队组织了一个 AMA(Ask Me Anything)的活动,团队通过社交媒体下的评论和用户互动。国外网友已经整理了AMA的核心内容,下面做下分享,帮助大家更全面的了解o1系列模型:
01
o1模型的大小和性能
o1-mini比o1-preview小得多且更快,因此未来将提供给免费用户;
o1-preview是o1模型的早期检查点,既不大也不小;
o1-mini在STEM任务中表现更好,但世界知识有限;
与o1-preview相比,o1-mini在某些任务上表现更好,尤其是在代码相关任务中;
与o1-preview相比,o1-mini在某些任务上表现更好,尤其是在代码相关任务中;
o1的输入Tokent算方式与GPT-4o相同,使用相同的分词器;
o1-mini可以比o1-preview探索更多思维链。
02
输入Token上下文和模型能力
更大的输入上下文即将为o1模型提供;
o1模型能够处理更长、更开放的任务,较少需要像GPT-4o那样进行输入分块;
o1可以在给出答案之前生成长推理链,这不同于之前的模型;
当前无法在链式推理(CoT)过程中暂停推理以添加更多上下文,但正在为未来模型探索此功能。
03
工具、功能和即将推出的特性
o1-preview目前还不使用工具,但计划支持函数调用、代码解释器和浏览;
工具支持、结构化输出和系统提示将在未来更新中添加;
用户最终可能会获得对思考时间和Token限制的控制权;
正在计划启用流式传输并在API中考虑推理进展;
多模态能力内置于o1中,旨在在诸如MMMU等任务中达到最先进的表现。
04
链式推理(CoT)
o1在推理过程中生成隐藏的推理链;
目前没有计划向API用户或ChatGPT公开CoT Token;
CoT Token被总结,但无法保证其完全忠实于实际推理过程;
提示词中的指令可以影响模型如何思考问题;使用强化学习(RL)改进了o1的链式推理性能,GPT-4o无法仅通过提示词匹配其COT表现;
思维阶段看起来较慢,因为它总结了思维过程,但生成答案的速度通常更快。
05
模型开发和研究见解
o1通过强化学习训练以实现推理性能;
该模型在诗歌等横向任务中展现了创造性思维和强大的表现;
o1的哲学推理和泛化能力 (例如破译密码)令人印象深刻;
研究人员使用o1创建了一个GitHub机器人,该机器人可以提醒正确的CODEOWNERS进行代码审查;
在内部测试中,o1通过对自己提出困难问题来评估其能力;
正在添加广泛的世界领域知识,未来版本会有所改进;
计划为未来迭代的o1-mini提供更新的数据 (当前截至2023年10月)。
06
提示技巧和最佳实践
o1受益于提供边界情况或推理风格的提示技巧;
与早期模型相比,o1模型对提示中的推理线索更为敏感;
在检索增强生成(RAG)中提供相关的上下文可以改善性能;不相关的部分可能会削弱推理。





![[Unity Demo]从零开始制作空洞骑士Hollow Knight第六集:制作小骑士完整的跳跃落地行为](https://i-blog.csdnimg.cn/direct/6e7912ad92324467872b2f8e8ea196f1.png)