一、问题描述
线上某一项目以jar包的方式发布,需要健康检查,若15次健康检查页面状态均为非200则健康检查失败,就会导致tomcat服务加载失败。前几天版本迭代,发布该项目时,因最后一次健康检查的时间比启动完成时早,所以认为启动失败,导致该项目未发布成功。
二、分析定位
项目以war包方式启动和jar包方式启动在开启8080端口的时间点上不一样。以war包的方式启动是在应用启动时就开启8080端口,此时应用还没启动成功,虽然健康检查接口访问不了,但因为端口是开的,所以Rundeck访问健康检查接口时会卡住,直到自行超时,所以整个健康检查的过程会被应用启动成功前的超时时间拉长。而以jar的方式启动,在应用启动成功之后才开启8080端口,在应用没启动成功前,Rundeck访问健康检查接口会直接报地址无法访问,一旦应用启动时间稍长,就会很快把Rundeck健康检查重试次数耗完,之后就认为启动失败了。
解决方法:
可以修改Rundeck启动超时时间。以上例为例,之前Rundeck超时时间是1分钟,可以修改为2分钟。
优化Sharding-JDBC。
方法一没什么好说的,肯定能解决问题。下面说下方法二,不仅能解决问题,同时也能让我们在本地启动项目时更快些。
二、背景
SringBoot版本:2.3.3.RELEASE
ShardingSphere版本:5.0.0
数据源连接池:Druid
数据库数为5,逻辑库名分别为dbm,db0,db1,db2,db3。其中dbm中存放单表(即不分库分表的表),db0~db3库用于分库。每个需要分库分表的表,按4库50表根据自定义分库分表算法进行水平切分。该项目单表数量为11,需要进行分库分表的表的数量为8。
配置文件大致如下:
# 数据源参数配置
initialSize=5
minIdle=5
maxIdle=100
maxActive=20
maxWait=60000
timeBetweenEvictionRunsMillis=60000
minEvictableIdleTimeMillis=300000
# Sharding Jdbc配置
# 分库的数量(注意:需要排除主库)
databaseSize=4
# 分表的数量
tableSize=50
# dbm为主库,db0,db1,db2,db3
spring.shardingsphere.datasource.names=dbm,db0,db1,db2,db3
# 配置主库
spring.shardingsphere.datasource.dbm.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dbm.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.dbm.url=jdbc:mysql://ip:3306/rt_warehouse_inventory?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false&tinyInt1isBit=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.dbm.username=username
spring.shardingsphere.datasource.dbm.password=password
spring.shardingsphere.datasource.dbm.initialSize=${initialSize}
spring.shardingsphere.datasource.dbm.minIdle=${minIdle}
spring.shardingsphere.datasource.dbm.maxActive=${maxActive}
spring.shardingsphere.datasource.dbm.maxWait=${maxWait}
spring.shardingsphere.datasource.dbm.validationQuery=SELECT 1 FROM DUAL
spring.shardingsphere.datasource.dbm.timeBetweenEvictionRunsMillis=${timeBetweenEvictionRunsMillis}
spring.shardingsphere.datasource.dbm.minEvictableIdleTimeMillis=${minEvictableIdleTimeMillis}
# 配置db0
spring.shardingsphere.datasource.db0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db0.url=jdbc:mysql://ip:3306/rt_warehouse_inventory_00?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false&tinyInt1isBit=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.db0.username=username
spring.shardingsphere.datasource.db0.password=password
spring.shardingsphere.datasource.db0.initialSize=${initialSize}
spring.shardingsphere.datasource.db0.minIdle=${minIdle}
spring.shardingsphere.datasource.db0.maxActive=${maxActive}
spring.shardingsphere.datasource.db0.maxWait=${maxWait}
spring.shardingsphere.datasource.db0.validationQuery=SELECT 1 FROM DUAL
spring.shardingsphere.datasource.db0.timeBetweenEvictionRunsMillis=${timeBetweenEvictionRunsMillis}
spring.shardingsphere.datasource.db0.minEvictableIdleTimeMillis=${minEvictableIdleTimeMillis}
# 配置db1
spring.shardingsphere.datasource.db1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db1.url=jdbc:mysql://ip:3306/rt_warehouse_inventory_01?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false&tinyInt1isBit=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.db1.username=username
spring.shardingsphere.datasource.db1.password=password
spring.shardingsphere.datasource.db1.initialSize=${initialSize}
spring.shardingsphere.datasource.db1.minIdle=${minIdle}
spring.shardingsphere.datasource.db1.maxActive=${maxActive}
spring.shardingsphere.datasource.db1.maxWait=${maxWait}
spring.shardingsphere.datasource.db1.validationQuery=SELECT 1 FROM DUAL
spring.shardingsphere.datasource.db1.timeBetweenEvictionRunsMillis=${timeBetweenEvictionRunsMillis}
spring.shardingsphere.datasource.db1.minEvictableIdleTimeMillis=${minEvictableIdleTimeMillis}
# 配置db2
spring.shardingsphere.datasource.db2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db2.url=jdbc:mysql://ip:3306/rt_warehouse_inventory_02?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false&tinyInt1isBit=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.db2.username=username
spring.shardingsphere.datasource.db2.password=password
spring.shardingsphere.datasource.db2.initialSize=${initialSize}
spring.shardingsphere.datasource.db2.minIdle=${minIdle}
spring.shardingsphere.datasource.db2.maxActive=${maxActive}
spring.shardingsphere.datasource.db2.maxWait=${maxWait}
spring.shardingsphere.datasource.db2.validationQuery=SELECT 1 FROM DUAL
spring.shardingsphere.datasource.db2.timeBetweenEvictionRunsMillis=${timeBetweenEvictionRunsMillis}
spring.shardingsphere.datasource.db2.minEvictableIdleTimeMillis=${minEvictableIdleTimeMillis}
# 配置db3
spring.shardingsphere.datasource.db3.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db3.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db3.url=jdbc:mysql://ip:3306/rt_warehouse_inventory_03?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false&tinyInt1isBit=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.db3.username=username
spring.shardingsphere.datasource.db3.password=password
spring.shardingsphere.datasource.db3.initialSize=${initialSize}
spring.shardingsphere.datasource.db3.minIdle=${minIdle}
spring.shardingsphere.datasource.db3.maxActive=${maxActive}
spring.shardingsphere.datasource.db3.maxWait=${maxWait}
spring.shardingsphere.datasource.db3.validationQuery=SELECT 1 FROM DUAL
spring.shardingsphere.datasource.db3.timeBetweenEvictionRunsMillis=${timeBetweenEvictionRunsMillis}
spring.shardingsphere.datasource.db3.minEvictableIdleTimeMillis=${minEvictableIdleTimeMillis}
# 分库配置
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=store_no
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=preciseShardingDatabaseAlgorithm
# 分表配置
# test1表配置
spring.shardingsphere.rules.sharding.tables.test1.actual-data-nodes=db$->{0..3}.test1_0$->{0..9},db$->{0..3}.test1_$->{10..49}
spring.shardingsphere.rules.sharding.tables.test1.table-strategy.standard.sharding-column=store_no
spring.shardingsphere.rules.sharding.tables.test1.table-strategy.standard.sharding-algorithm-name=preciseShardingTableAlgorithm
# test2表配置
spring.shardingsphere.rules.sharding.tables.test2.actual-data-nodes=db$->{0..3}.test2_0$->{0..9},db$->{0..3}.test2_$->{10..49}
spring.shardingsphere.rules.sharding.tables.test2.table-strategy.standard.sharding-column=store_no
spring.shardingsphere.rules.sharding.tables.test2.table-strategy.standard.sharding-algorithm-name=preciseShardingTableAlgorithm
# test3表配置
spring.shardingsphere.rules.sharding.tables.test3.actual-data-nodes=db$->{0..3}.test3_0$->{0..9},db$->{0..3}.test3_$->{10..49}
spring.shardingsphere.rules.sharding.tables.test3.table-strategy.standard.sharding-column=store_no
spring.shardingsphere.rules.sharding.tables.test3.table-strategy.standard.sharding-algorithm-name=preciseShardingTableAlgorithm
# test4表配置
spring.shardingsphere.rules.sharding.tables.test4.actual-data-nodes=db$->{0..3}.test4_0$->{0..9},db$->{0..3}.test4_$->{10..49}
spring.shardingsphere.rules.sharding.tables.test4.table-strategy.standard.sharding-column=store_no
spring.shardingsphere.rules.sharding.tables.test4.table-strategy.standard.sharding-algorithm-name=preciseShardingTableAlgorithm
# test5表配置
spring.shardingsphere.rules.sharding.tables.test5.actual-data-nodes=db$->{0..3}.test5_0$->{0..9},db$->{0..3}.test5_$->{10..49}
spring.shardingsphere.rules.sharding.tables.test5.table-strategy.standard.sharding-column=store_no
spring.shardingsphere.rules.sharding.tables.test5.table-strategy.standard.sharding-algorithm-name=preciseShardingTableAlgorithm
# test6表配置
spring.shardingsphere.rules.sharding.tables.test6.actual-data-nodes=db$->{0..3}.test6_0$->{0..9},db$->{0..3}.test6_$->{10..49}
spring.shardingsphere.rules.sharding.tables.test6.table-strategy.standard.sharding-column=store_no
spring.shardingsphere.rules.sharding.tables.test6.table-strategy.standard.sharding-algorithm-name=preciseShardingTableAlgorithm
# test7表配置
spring.shardingsphere.rules.sharding.tables.test7.actual-data-nodes=db$->{0..3}.test7_0$->{0..9},db$->{0..3}.test7_$->{10..49}
spring.shardingsphere.rules.sharding.tables.test7.table-strategy.standard.sharding-column=store_no
spring.shardingsphere.rules.sharding.tables.test7.table-strategy.standard.sharding-algorithm-name=preciseShardingTableAlgorithm
# test8表配置
spring.shardingsphere.rules.sharding.tables.test8.actual-data-nodes=db$->{0..3}.test8_0$->{0..9},db$->{0..3}.test8_$->{10..49}
spring.shardingsphere.rules.sharding.tables.test8.table-strategy.standard.sharding-column=store_no
spring.shardingsphere.rules.sharding.tables.test8.table-strategy.standard.sharding-algorithm-name=preciseShardingTableAlgorithm
# 打印分库分表日志
spring.shardingsphere.props.sql-show=true本地测试十次启动时间,启动时间如下图:
启动次数 | 第一次 | 第二次 | 第三次 | 第四次 | 第五次 | 第六次 | 第七次 | 第八次 | 第九次 | 第十次 |
启动时间 | 29.625s | 23.748s | 24.299s | 22.575s | 24.167s | 23.13s | 23.73s | 23.419s | 22.91s | 23.04s |
二、优化方式
先来看下在启动时,ShardingSphere-JDBC如何加载单表规则。
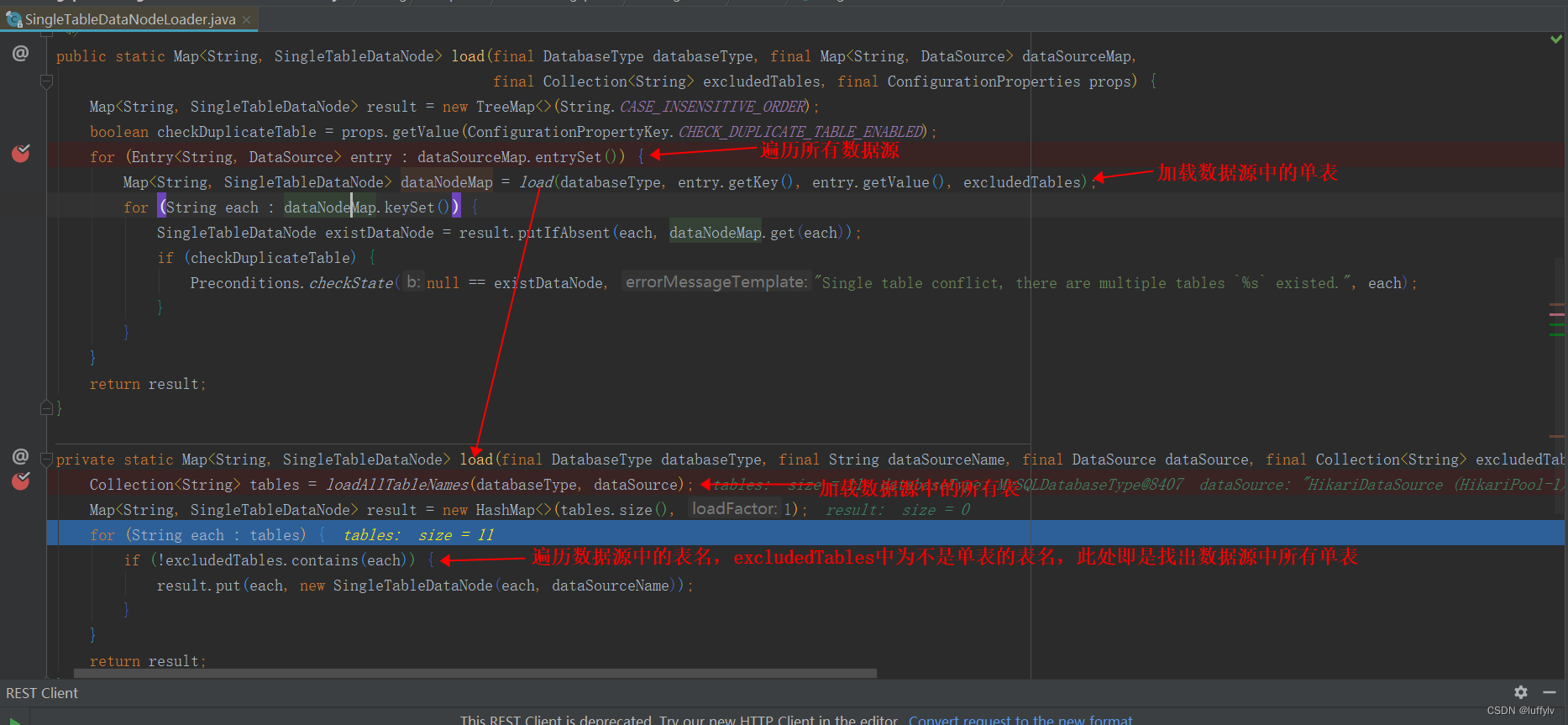
首先在创建单表规则SingleTableRule时,通过getAggregateDataSourceMap方法获取所有数据源。以本例为例,即通过该方法将获取dbm,db0,db1,db2,db3数据源。然后通过单表数据节点加载器加载所有数据源中的单表。其中通过getExcludedTables(builtRules)方法获取所有数据分片的表,包括逻辑表名和真实表名。如下图:

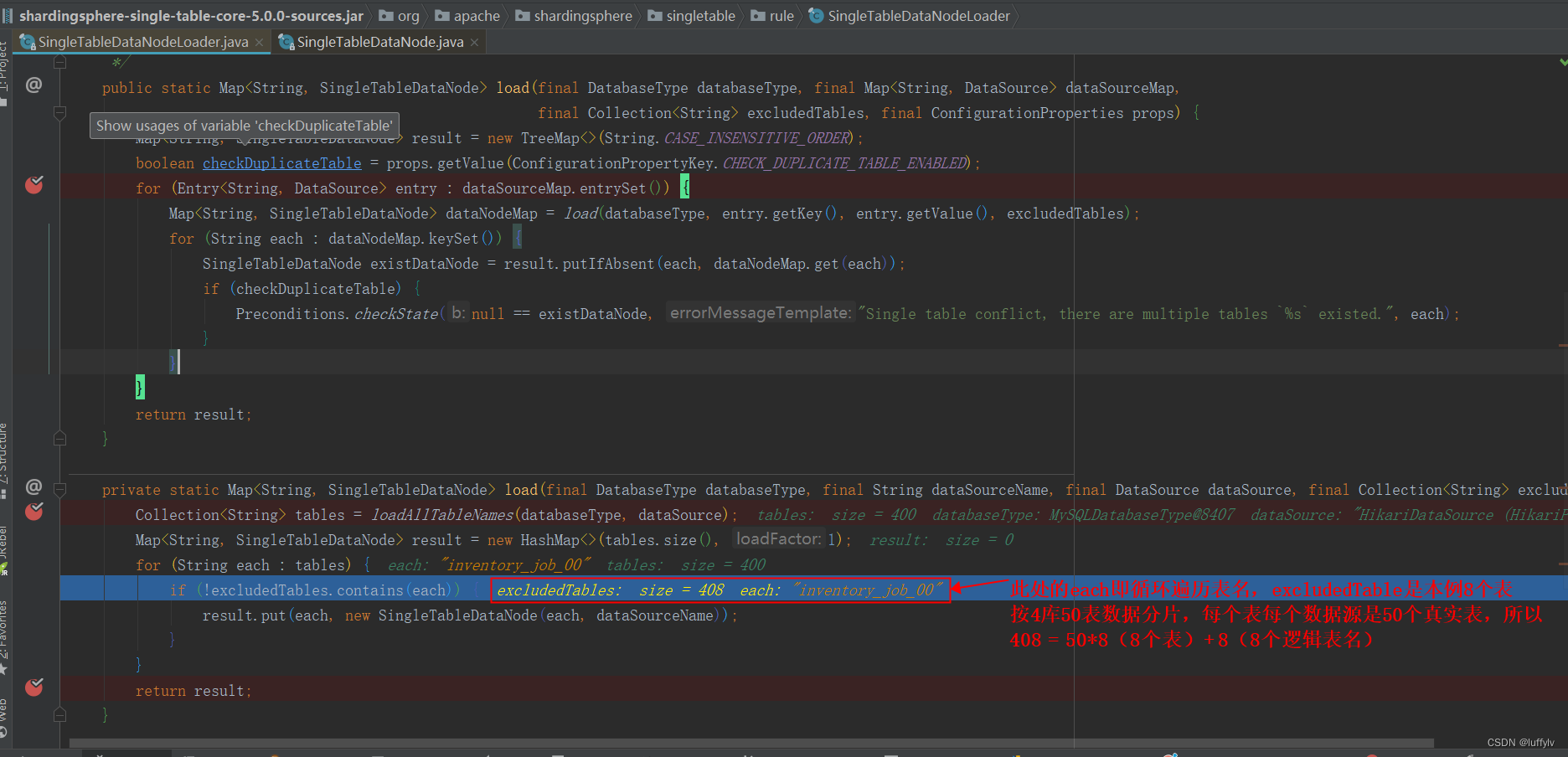
然后循环遍历所有数据源,首先加载每个数据源的所有表名,然后判断改表是否是要数据分片的表,若不是,则即是单表,根据该单表名和数据源逻辑名创建单表数据节点。如前所述,对于dbm数据源,我们只存放单表,共11张表,通过SingleTableDataNodeLoader.loadAllTableNames方法即获得11张单表,循环遍历11次,并且这11张表不在excludedTables(需要数据分片的表名,本例共8个表需要数据分片,每个表水平切分50个真实表,加上逻辑表名,共408个表名,为test1,test2,test3,test4,test5,test6,test7,test8,test1_00~test1_19,test2_00~test2_19,test3_00~test3_19,test4_00~test4_19,test5_00~test5_19,test6_00~test6_19,test7_00~test7_19,test8_00~test8_19)中,根据这11个单表表明和dbm数据源创建11个单表数据节点,本次循环结束。对于db0数据源,共存放8 * 50 共400张真实表,表名为test1_00~test1_19,test2_00~test2_19,test3_00~test3_19,test4_00~test4_19,test5_00~test5_19,test6_00~test6_19,test7_00~test7_19,test8_00~test8_19。通过SingleTableDataNodeLoader.loadAllTableNames方法即获得上述400个表名,循环遍历400次,判断表明是否存在于excludedTables中,显然时存在的。显然这400次循环遍历判断是多余的,因为单表只存在于dbm中,db0中只存在数据分片的表,且肯定存在excludedTables中。对于db1、db2、db3同理。源码如下图:
通过上面分析可知,对于我这个项目的实际情况,单表只在dbm中,在加载单表时完全不用去db0~db3数据源中去加载。显然这块共四次加载所有表名及4*400=1600次循环判断是多余的。若数据源增多或者需要数据分片的表增多,在上述多余的步骤上耗时也会变多,项目启动会变的更慢。可以通过修改getAggregateDataSourceMap方法,只获取dbm数据源来优化启动时间。
具体优化方式如下:
使用HikariCP数据源连接池替换Druid数据源连接池。
在应用里建一个和SingleTableRule类相同名称且路路径相同的文件,将下面内容拷贝进去,这样不会动到原jar包。下面内容就是将getAggregateDataSourceMap方法替换为getMasterDataSourceMap方法,只获取dbm数据源。
package org.apache.shardingsphere.singletable.rule;
import lombok.Getter;
import org.apache.shardingsphere.infra.config.properties.ConfigurationProperties;
import org.apache.shardingsphere.infra.database.type.DatabaseType;
import org.apache.shardingsphere.infra.datanode.DataNode;
import org.apache.shardingsphere.infra.route.context.RouteContext;
import org.apache.shardingsphere.infra.route.context.RouteUnit;
import org.apache.shardingsphere.infra.rule.ShardingSphereRule;
import org.apache.shardingsphere.infra.rule.identifier.scope.SchemaRule;
import org.apache.shardingsphere.infra.rule.identifier.type.DataNodeContainedRule;
import org.apache.shardingsphere.infra.rule.identifier.type.DataSourceContainedRule;
import org.apache.shardingsphere.infra.rule.identifier.type.MutableDataNodeRule;
import org.apache.shardingsphere.infra.rule.identifier.type.TableContainedRule;
import javax.sql.DataSource;
import java.util.Collection;
import java.util.Collections;
import java.util.LinkedHashMap;
import java.util.LinkedList;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Objects;
import java.util.Optional;
import java.util.Set;
import java.util.stream.Collectors;
/**
* Single table rule.
*/
@Getter
public final class SingleTableRule implements SchemaRule, DataNodeContainedRule, TableContainedRule, MutableDataNodeRule {
private final Collection<String> dataSourceNames;
private final Map<String, SingleTableDataNode> singleTableDataNodes;
public SingleTableRule(final DatabaseType databaseType, final Map<String, DataSource> dataSourceMap, final Collection<ShardingSphereRule> builtRules, final ConfigurationProperties props) {
Map<String, DataSource> aggregateDataSourceMap = getMaterDataSourceMap(dataSourceMap);
dataSourceNames = aggregateDataSourceMap.keySet();
singleTableDataNodes = SingleTableDataNodeLoader.load(databaseType, aggregateDataSourceMap, getExcludedTables(builtRules), props);
}
// 只获取主数据库数据源
private Map<String, DataSource> getMasterDataSourceMap(final Map<String, DataSource> dataSourceMap) {
Map<String, DataSource> result = new LinkedHashMap<>(1);
for (Entry<String, DataSource> entry : dataSourceMap.entrySet()) {
String logicName = entry.getKey();
if (logicName != null) {
result.put(logicName,dataSourceMap.get(logicName));
}
break;
}
return result;
}
/**
* Judge whether single tables are in same data source or not.
*
* @param singleTableNames single table names
* @return whether single tables are in same data source or not
*/
public boolean isSingleTablesInSameDataSource(final Collection<String> singleTableNames) {
Set<String> dataSourceNames = singleTableNames.stream().map(singleTableDataNodes::get).filter(Objects::nonNull).map(SingleTableDataNode::getDataSourceName).collect(Collectors.toSet());
return dataSourceNames.size() <= 1;
}
/**
* Judge whether all tables are in same data source or not.
*
* @param routeContext route context
* @param singleTableNames single table names
* @return whether all tables are in same data source or not
*/
public boolean isAllTablesInSameDataSource(final RouteContext routeContext, final Collection<String> singleTableNames) {
if (!isSingleTablesInSameDataSource(singleTableNames)) {
return false;
}
SingleTableDataNode dataNode = singleTableDataNodes.get(singleTableNames.iterator().next());
for (RouteUnit each : routeContext.getRouteUnits()) {
if (!each.getDataSourceMapper().getLogicName().equals(dataNode.getDataSourceName())) {
return false;
}
}
return true;
}
/**
* Get sharding logic table names.
*
* @param logicTableNames logic table names
* @return sharding logic table names
*/
public Collection<String> getSingleTableNames(final Collection<String> logicTableNames) {
return logicTableNames.stream().filter(singleTableDataNodes::containsKey).collect(Collectors.toCollection(LinkedList::new));
}
@Override
public void addDataNode(final String tableName, final String dataSourceName) {
if (dataSourceNames.contains(dataSourceName) && !singleTableDataNodes.containsKey(tableName)) {
singleTableDataNodes.put(tableName, new SingleTableDataNode(tableName, dataSourceName));
}
}
@Override
public void dropDataNode(final String tableName) {
singleTableDataNodes.remove(tableName);
}
private Collection<String> getExcludedTables(final Collection<ShardingSphereRule> rules) {
return rules.stream().filter(each -> each instanceof DataNodeContainedRule).flatMap(each -> ((DataNodeContainedRule) each).getAllTables().stream()).collect(Collectors.toSet());
}
@Override
public Map<String, Collection<DataNode>> getAllDataNodes() {
return singleTableDataNodes.values().stream().map(each -> new DataNode(each.getDataSourceName(), each.getTableName()))
.collect(Collectors.groupingBy(DataNode::getTableName, LinkedHashMap::new, Collectors.toCollection(LinkedList::new)));
}
@Override
public Collection<String> getAllActualTables() {
return Collections.emptyList();
}
@Override
public Optional<String> findFirstActualTable(final String logicTable) {
return Optional.empty();
}
@Override
public boolean isNeedAccumulate(final Collection<String> tables) {
return false;
}
@Override
public Optional<String> findLogicTableByActualTable(final String actualTable) {
return Optional.empty();
}
@Override
public Optional<String> findActualTableByCatalog(final String catalog, final String logicTable) {
return Optional.empty();
}
@Override
public Collection<String> getAllTables() {
return singleTableDataNodes.keySet();
}
@Override
public Collection<String> getTables() {
return singleTableDataNodes.keySet();
}
@Override
public String getType() {
return SingleTableRule.class.getSimpleName();
}
}
优化后本地测试十次启动时间,启动时间如下图
启动次数 | 第一次 | 第二次 | 第三次 | 第四次 | 第五次 | 第六次 | 第七次 | 第八次 | 第九次 | 第十次 |
启动时间 | 15.231s | 17.426s | 16.395s | 16.19s | 17.029s | 15.169s | 15.025s | 15.559s | 14.975s | 14.699s |
通过优化前后本地启动时间对比可以看出应用启动明显快了些。
该方式适用于ShardingSphere版本:5.0.0和5.2.0版本,只在这两个正在使用的版本上验证了下,其他版本并未验证是否可行。