关于join
当需要查询两个表的交集、并集等数据时,除了嵌套子查询的方式外,还可以使用join的方式提升性能。对于MySQL的join语句,需要两个最基础的“角色”:主表即驱动表,关联表即驱动表。join描述的就是驱动表与被驱动表的关联关系。MySQL有三种关联逻辑处理策略,分别为:Index Nested-Loop Join、Simple Nested-Loop Join、Block Nested-Loop Join。在编写SQL时,需要配合explain使语句选择性能最优的策略。
Index Nested-Loop Join
索引嵌套循环连接,
MySQL选择驱动表与被驱动表关联逻辑之一。
当使用该策略时,MySQL的执行流程为:
- 从驱动表中读入一行数据 R;
- 从数据行 R 中,取出 a 字段到被驱动表里去查找;
- 取出被驱动表中满足条件的行,跟 R 组成一行,作为结果集的一部分;
- 重复执行步骤 1 到 3,直到驱动表的末尾循环结束。
什么情况下MySQL会选择Index Nested-Loop Join?
当驱动表关联被驱动表的字段上具有索引时,会使用本策略。在本策略中,驱动表在where条件筛选完毕后,会扫描全表,被驱动表走索引的树搜索。
假设被驱动表共N行数据,对于Index Nested-Loop Join来说,在查询被驱动表的数据时,会使用二分法进行查找,即时间复杂度为:O(logN),由于每次在被驱动表查一行数据,要先搜索索引再回表搜索,假设驱动表行数是N,执行整个过程复杂度近似:N+N*2*log2M。
Simple Nested-Loop Join
当被驱动表无可用索引时,在驱动表得到一行数据后,需要拿着该数据去被驱动表扫描全表逐行匹配数据,假设驱动表有N行数据,被驱动表有M行数据,那么扫描总行数则为:N*M行。如果驱动表与被驱动表均有十万行数据,则需要扫描100亿行。
当然,MySQL 也没有使用这个Simple Nested-Loop Join算法,而是使用了另一个叫作“Block Nested-Loop Join”的算法,简称 BNL。
Block Nested-Loop Join
当被驱动表无可用索引时,算法流程为:
- 把驱动表的数据读入线程内存join_buffer中
- 扫描被驱动表,把被驱动表的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回。
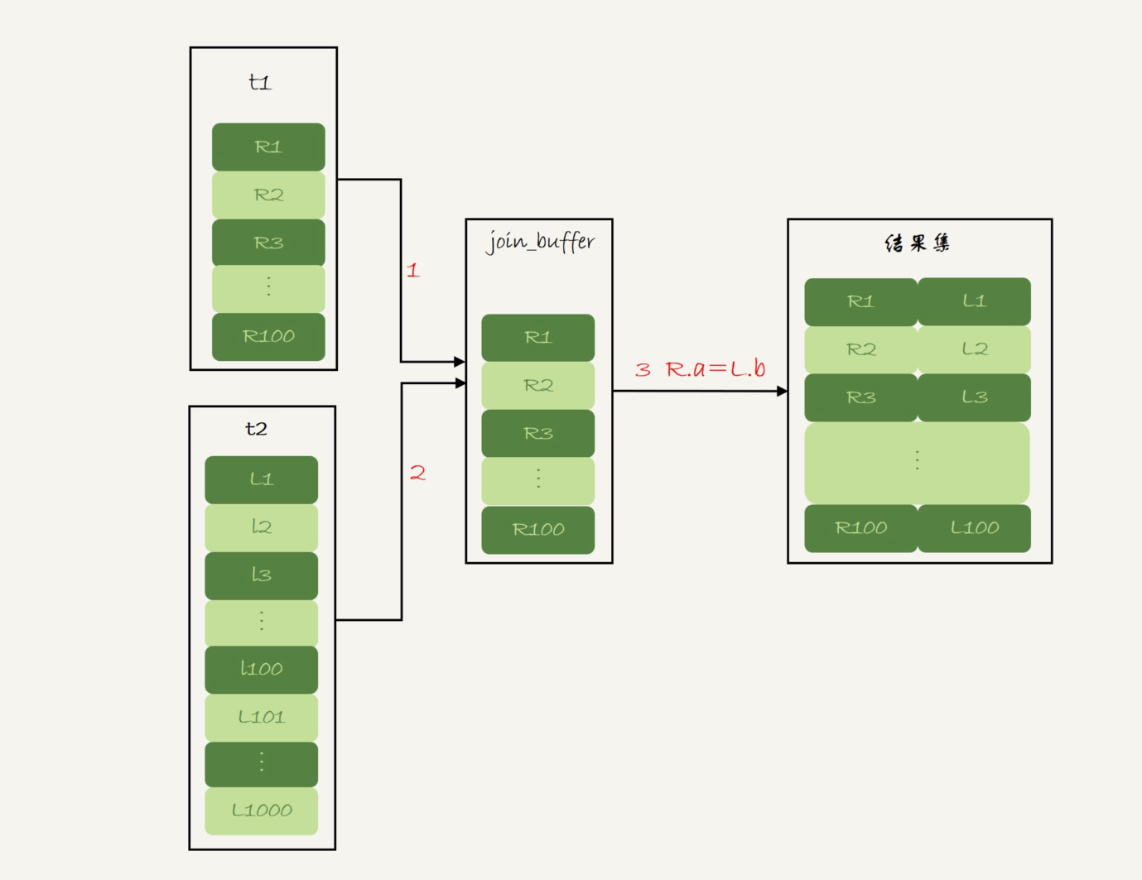

图片引用自极客时间《MySQL实战45讲》。
能不能使用join语句?
- 如果可以使用 Index Nested-Loop Join 算法,也就是说可以用上被驱动表上的索引,其实是没问题的;
- 如果使用 Block Nested-Loop Join 算法,扫描行数就会过多。尤其是在大表上的 join 操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种 join 尽量不要用。
所以你在判断要不要使用 join 语句时,就是看 explain 结果里面,Extra 字段里面有没有出现“Block Nested Loop”字样。