📖 前言:随着大数据时代的到来,大数据已经在金融、交通、物流等各个行业领域得到广泛应用。而Hadoop就是一个用于处理海量数据的框架,它既可以为海量数据提供可靠的存储;也可以为海量数据提供高效的处理。

目录
- 🕒 1. 大数据概述
- 🕒 2. Hadoop概述
- 🕘 2.1 Hadoop前世今生
- 🕘 2.2 Hadoop优缺点
- 🕘 2.3 Hadoop生态
- 🕘 2.4 Hadoop架构变迁
- 🕒 3. 部署Hadoop
- 🕘 3.1 创建hadoop用户
- 🕘 3.2 更新apt
- 🕘 3.3 安装SSH、配置SSH无密码登陆
- 🕘 3.4 安装Java环境
- 🕘 3.5 安装 Hadoop3.3.5
- 🕘 3.6 Hadoop单机配置(非分布式)
- 🕘 3.7 Hadoop伪分布式配置
- 🕘 3.8 运行Hadoop伪分布式实例
- 🕘 3.9 安装Hadoop集群
🕒 1. 大数据概述
大数据是来源于众多不同数据源的集合,通常由5个特征来描述,包括大量(Volume)、真实(Veracity)、多样(Variety)、低价值密度(Value)和高速(Velocity),这5个特征称为大数据的5V特征。
旧版教材定义(4V):
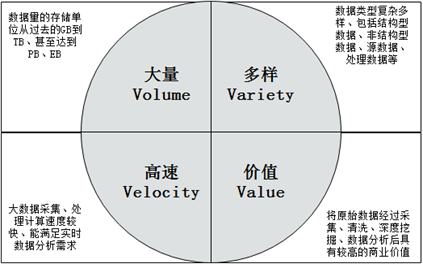
研究大数据最重要的意义是预测。
🕒 2. Hadoop概述
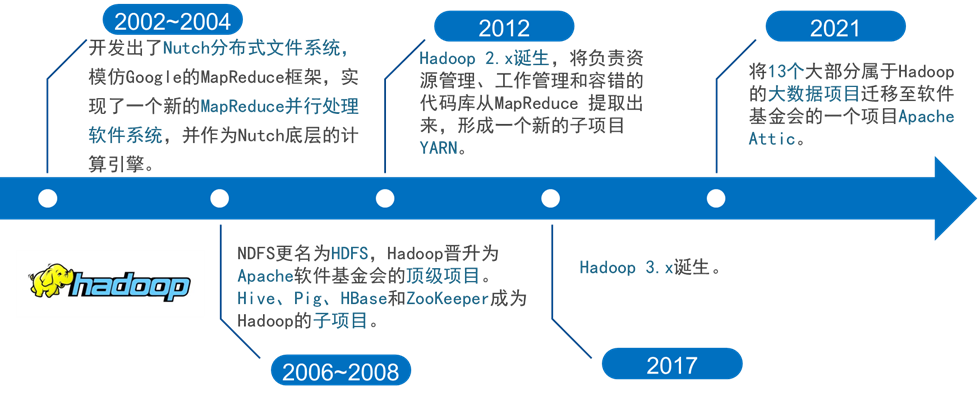
🕘 2.1 Hadoop前世今生
🕘 2.2 Hadoop优缺点
优点:低成本、高可靠性、高容错性、高效率、高扩展性
缺点:不适合处理小文件、无法实时计算、安全性较低
🕘 2.3 Hadoop生态
随着Hadoop的不断发展,Hadoop生态体系越来越完善,现如今已经发展成一个庞大的生态体系。
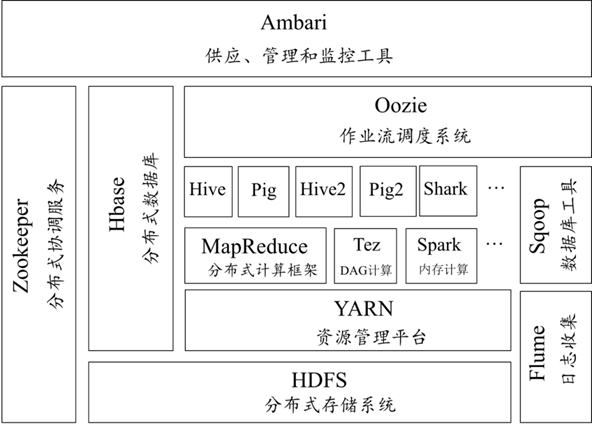
- HDFS分布式文件系统:HDFS是Hadoop的分布式文件系统,它是Hadoop生态系统中的核心项目之一,是分布式计算中数据存储管理基础。
- MapReduce分布式计算框架:MapReduce是一种计算模型,用于大规模数据集(大于1TB)的并行运算。
- Yarn资源管理框架:Yarn(Yet Another Resource Negotiator)是Hadoop 2.0中的资源管理器,它可为上层应用提供统一的资源管理和调度。
- Sqoop数据迁移工具:Sqoop是一款开源的数据导入导出工具,主要用于在Hadoop与传统的数据库间进行数据的转换。
- Mahout数据挖掘算法库:Mahout是Apache旗下的一个开源项目,它提供了一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员方便快捷地创建智能应用程序。
- HBase分布式存储系统:HBase是Google Bigtable克隆版,它是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
- Zookeeper分布式协作服务:Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和HBase的重要组件。
- Hive基于Hadoop的数据仓库:Hive是基于Hadoop的一个分布式数据仓库工具,可以将结构化的数据文件映射为一张数据库表,将SQL语句转换为MapReduce任务进行运行。
- Flume日志收集工具:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
🕘 2.4 Hadoop架构变迁
Hadoop共发行了三个版本,分别是Hadoop 1.x、Hadoop 2.x和Hadoop 3.x。
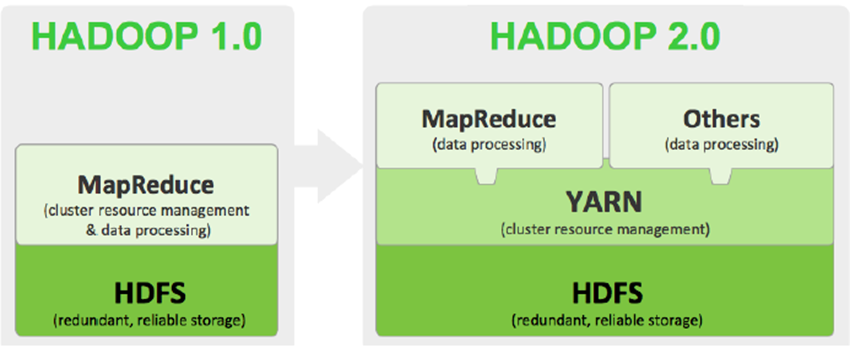
Hadoop1.0内核主要由分布式存储系统HDFS和分布式计算框架MapReduce两个系统组成,而Hadoop2.x版本主要新增了资源管理框架Yarn以及其他工作机制的改变。
Hadoop 3.x是基于JDK1.8开发的,较其他两个版本而言,在功能和优化方面发生了很大的变化,其中包括HDFS 可擦除编码、多Namenode支持、MR Native Task优化等。
🕒 3. 部署Hadoop
🔎 Hadoop3.3.5安装教程_单机/伪分布式配置_Hadoop3.3.5/Ubuntu22.04
环境:VMware 16.2.3、Ubuntu 22.04 64位、hadoop-3.3.5
🔎 Hadoop大数据课程软件 提取码: 09oy
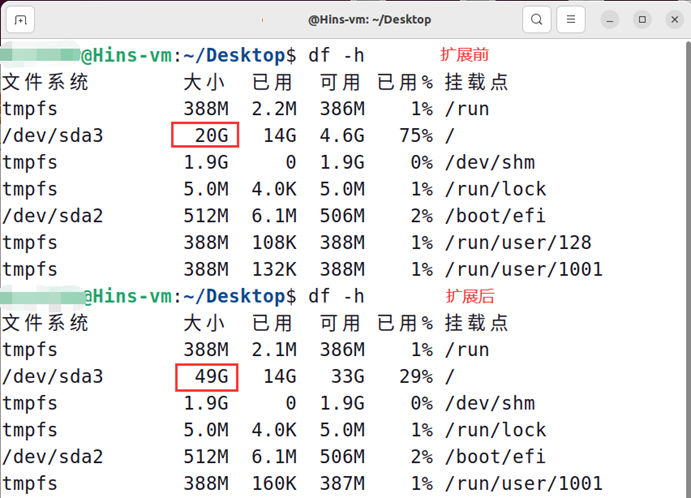
一般而言,开展大数据实验,需要在虚拟机中安装各种大数据软件,至少需要消耗40GB磁盘空间,因此,建议把磁盘空间设置为50GB~100GB,且内存为4G以上。
以下是已安装的Ubuntu扩容方法:
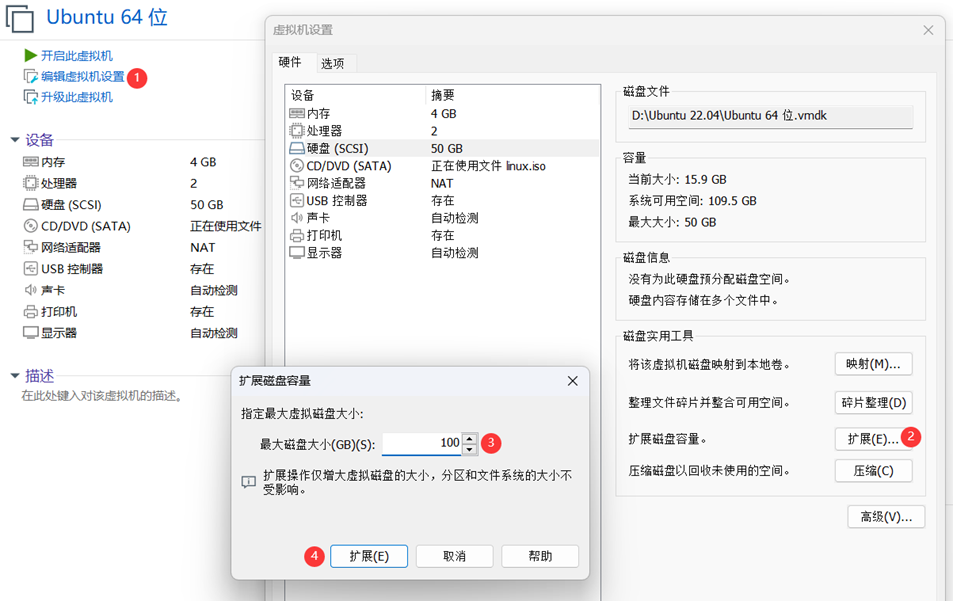
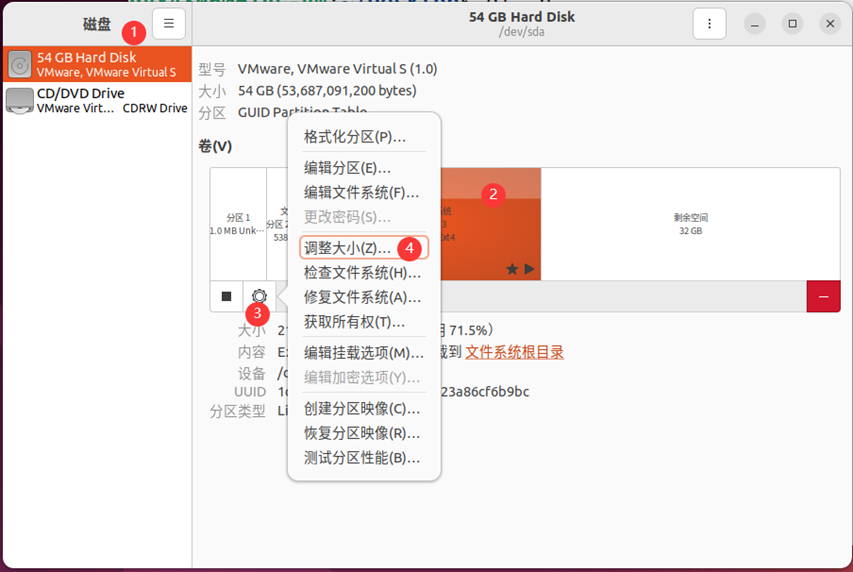
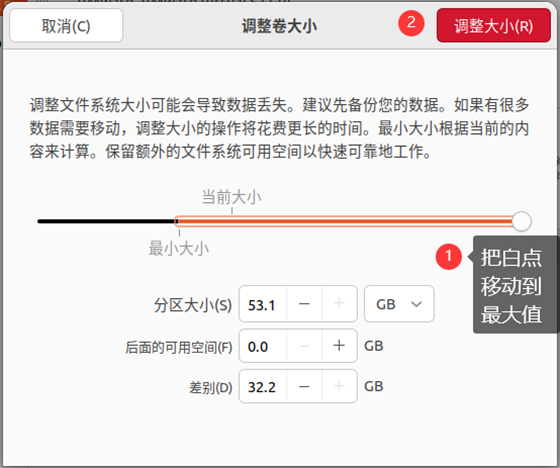
随后打开Ubuntu进行设置:
🕘 3.1 创建hadoop用户
如果你安装 Ubuntu 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
sudo useradd -m hadoop -s /bin/bash
这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
Ubuntu终端复制粘贴快捷键:在Ubuntu终端窗口中,复制粘贴的快捷键需要加上 shift,即粘贴是 ctrl+shift+v。
接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudo passwd hadoop
可为 hadoop 用户增加管理员权限,方便部署
sudo adduser hadoop sudo
最后注销当前用户,返回登陆界面。在登陆界面中选择刚创建的 hadoop 用户进行登陆。
🕘 3.2 更新apt
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:
sudo apt-get update
后续需要更改一些配置文件,建议使用 vim 。
sudo apt-get install vim
🔎 【Linux详解】——yum与vim的基本使用
🕘 3.3 安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。
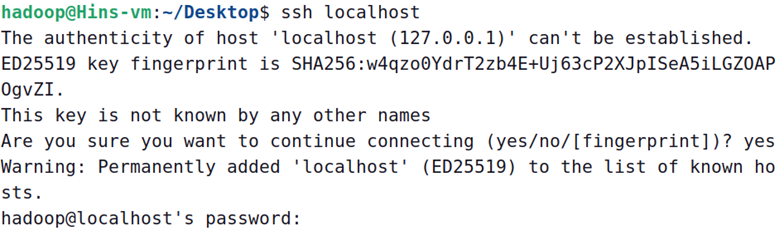
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
hadoop@Hins-vm:~$ exit # 退出刚才的 ssh localhost
注销
Connection to localhost closed.
hadoop@Hins-vm:~/Desktop$ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
hadoop@Hins-vm:~/.ssh$ ssh-keygen -t rsa # 会有提示,都按回车就可以
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:OhgJuRKQaCQF6TcJroolvsUdd4CX35H8cAOk1cS8HIU hadoop@Hins-vm
The key's randomart image is:
+---[RSA 3072]----+
|**. .+=.o. |
|*o . . . + oE |
|= + .. + . =.oo |
| + * .. o . =o. |
|o o +. .So . . |
|o.o .oo.. |
|+o o..o |
|o.. . |
| .. |
+----[SHA256]-----+
hadoop@Hins-vm:~/.ssh$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了。
🕘 3.4 安装Java环境
Hadoop3.3.5需要JDK版本在1.8及以上。需要按照下面步骤来自己手动安装JDK1.8。
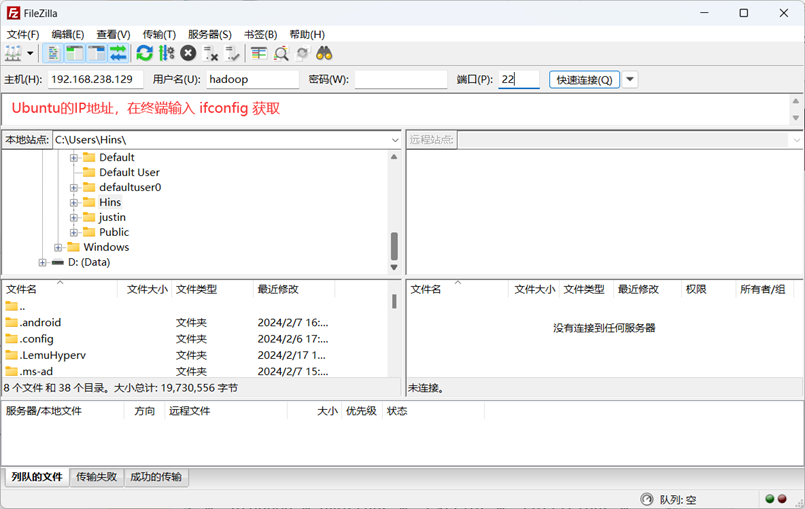
我们需要从windows向虚拟机上面安装的ubuntu进行大数据文件的传输,这时候,我们不能通过VMTools来进行传输,否则会导致VM工具的错误,所以,这时候我们需要一个第三方的软件,来进行大数据文件的传输。这里选择FileZilla。
首先在Windows端下载FileZilla,安装打开后,输入下面四个框的信息进行连接
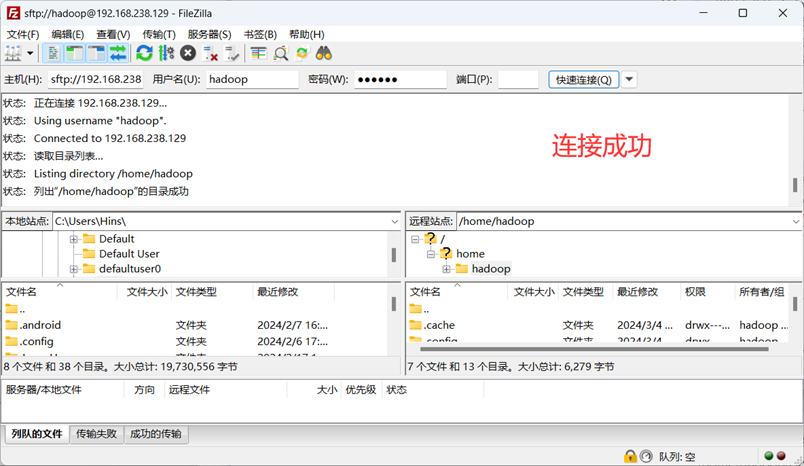
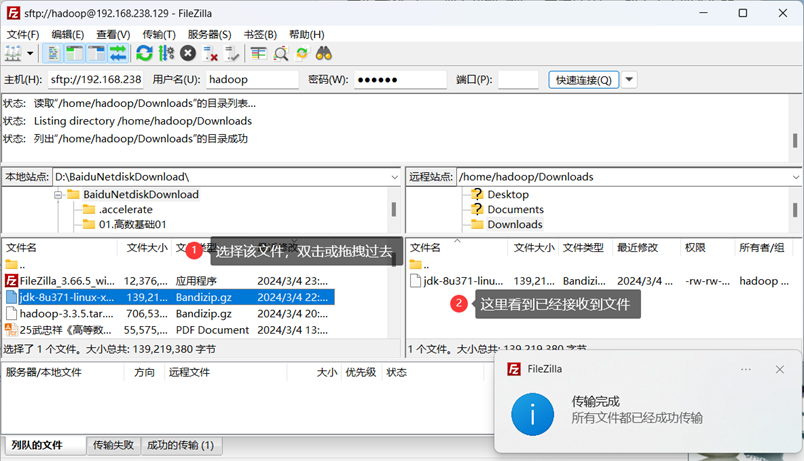
可以看到,该压缩文件已经保存在“/home/hadoop/Downloads”目录下。
在Linux命令行界面中,执行如下Shell命令(注意:当前登录用户名是hadoop):
hadoop@Hins-vm:~$ cd /usr/lib
hadoop@Hins-vm:/usr/lib$ sudo mkdir jvm # 创建/usr/lib/jvm目录用来存放JDK文件
[sudo] hadoop 的密码:
hadoop@Hins-vm:/usr/lib$ cd ~ # 进入hadoop用户的主目录
hadoop@Hins-vm:~$ cd Downloads # 注意区分大小写字母,刚才已经通过FTP软件把JDK安装包传到该目录下
hadoop@Hins-vm:~/Downloads$ ls
jdk-8u371-linux-x64.tar.gz
# 把JDK文件解压到/usr/lib/jvm目录下
hadoop@Hins-vm:~/Downloads$ sudo tar -zxvf ./jdk-8u371-linux-x64.tar.gz -C /usr/lib/jvm
JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
hadoop@Hins-vm:~/Downloads$ cd /usr/lib/jvm
hadoop@Hins-vm:/usr/lib/jvm$ ls
jdk1.8.0_371
可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_371目录。
下面继续执行如下命令,设置环境变量:
hadoop@Hins-vm:/usr/lib/jvm$ cd ~
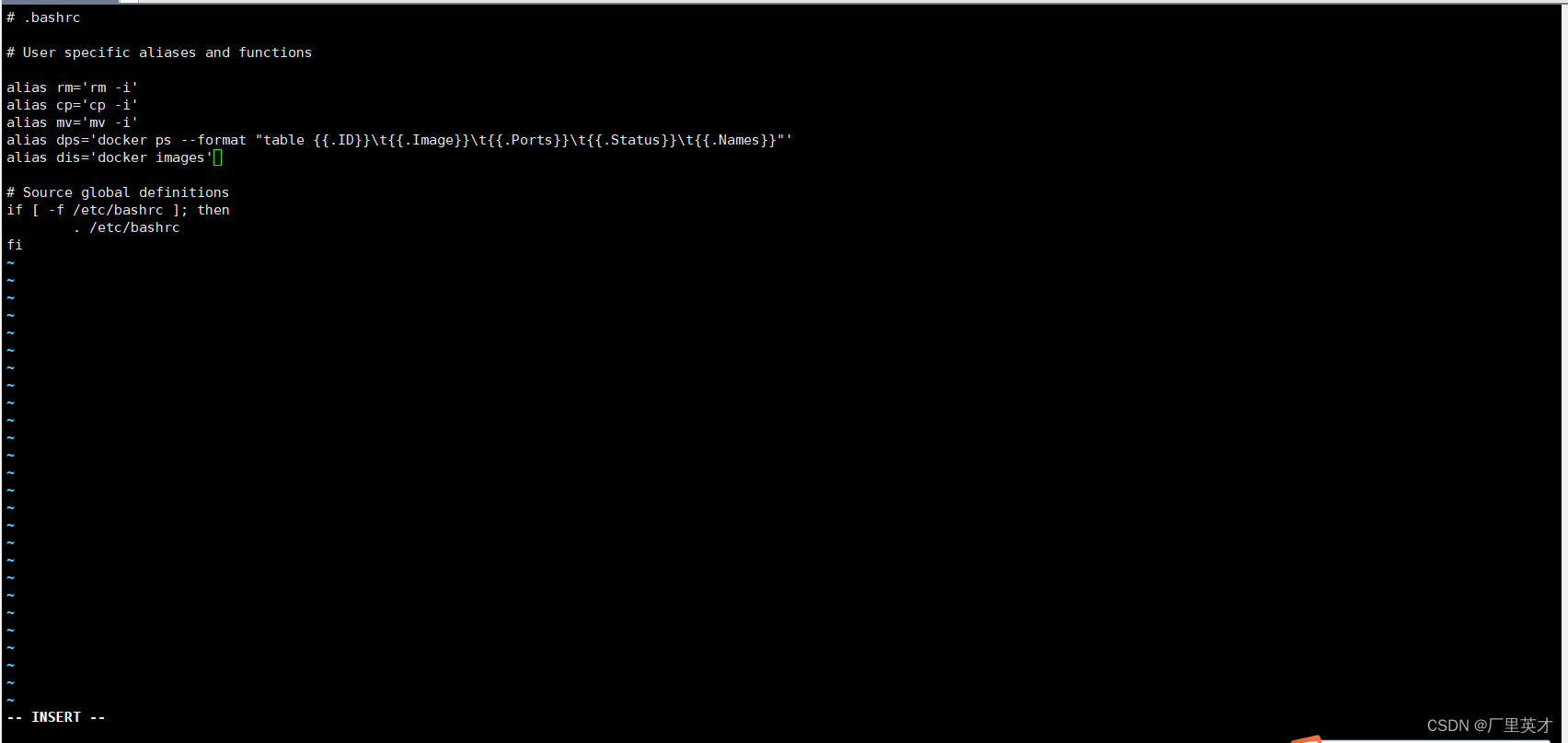
hadoop@Hins-vm:~$ vim ~/.bashrc
上面命令使用vim编辑器打开了hadoop这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_371
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
先按
i进入插入模式,后使用ctrl+shift+v粘贴,随后按ESC,输入:wq保存退出。
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
这时,可以使用如下命令查看是否安装成功:
hadoop@Hins-vm:~/Downloads$ java -version
java version "1.8.0_371"
Java(TM) SE Runtime Environment (build 1.8.0_371-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.371-b11, mixed mode)
至此,就成功安装了Java环境。下面就可以进入Hadoop的安装。
🕘 3.5 安装 Hadoop3.3.5
我们选择将 Hadoop 安装至 /usr/local/ 中:
sudo tar -zxvf ~/Downloads/hadoop-3.3.5.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.3.5/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
hadoop@Hins-vm:/usr/local$ cd /usr/local/hadoop
hadoop@Hins-vm:/usr/local/hadoop$ ./bin/hadoop version
Hadoop 3.3.5
Source code repository https://github.com/apache/hadoop.git -r 706d88266abcee09ed78fbaa0ad5f74d818ab0e9
Compiled by stevel on 2023-03-15T15:56Z
Compiled with protoc 3.7.1
From source with checksum 6bbd9afcf4838a0eb12a5f189e9bd7
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.3.5.jar
🕘 3.6 Hadoop单机配置(非分布式)
Hadoop集群三种部署模式
- 独立模式:一种在单台计算机的单个JVM进程中模拟Hadoop集群的工作模式,此模式部署的Hadoop通常用于快速安装体验Hadoop的功能,并不适用于实际生产环境。
- 伪分布式模式:一种在单台计算机的不同JVM进程中运行Hadoop集群的工作模式,此模式部署的Hadoop通常用于在开发环境中进行测试和调试,并不适用于实际生产环境。
- 完全分布式模式:一种在多台计算机的JVM进程中运行Hadoop集群的工作模式,Hadoop集群的每个守护进程都运行在不同的计算机中,此模式部署的Hadoop通常作为实际生产环境的基础。
Hadoop 默认模式为非分布式模式(独立模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
执行成功后如下所示,输出了作业的相关信息,输出的结果是符合正则的单词 dfsadmin 出现了1次
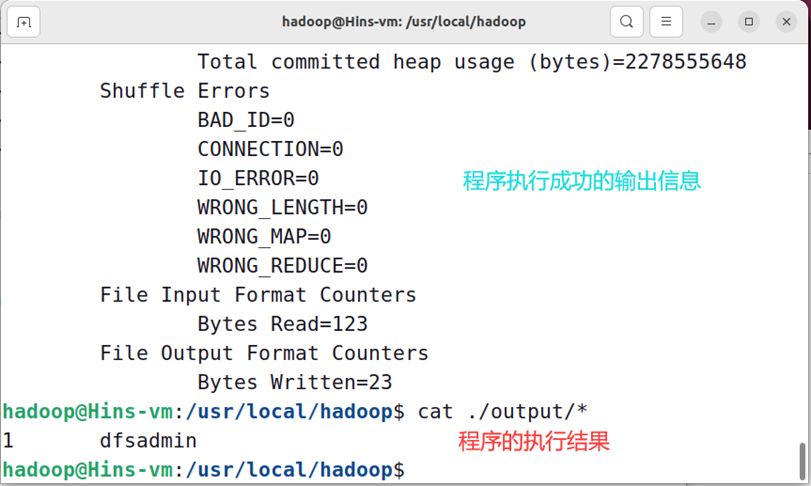
注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
rm -r ./output
🕘 3.7 Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件 core-site.xml :
gedit ./etc/hadoop/core-site.xml
将当中的
<configuration>
</configuration>
修改为下面配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同样的,修改配置文件 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
Hadoop配置文件说明:
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 的提示
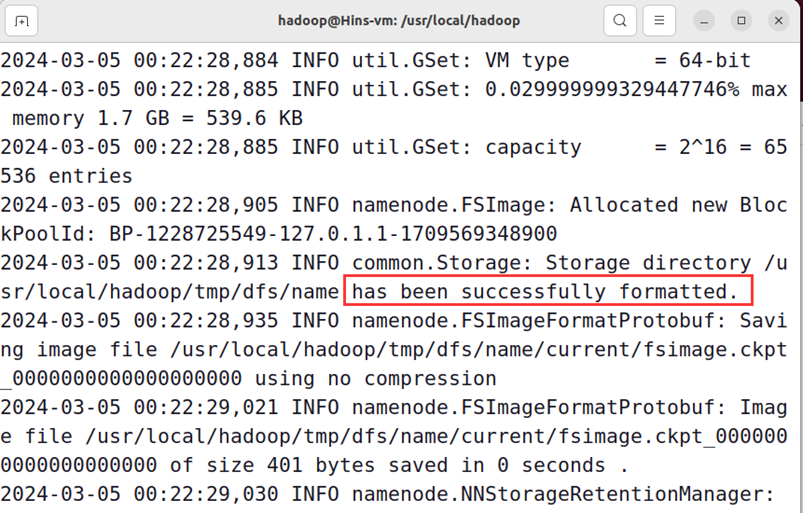
接着开启 NameNode 和 DataNode 守护进程。
cd /usr/local/hadoop
./sbin/start-dfs.sh # start-dfs.sh是个完整的可执行文件,中间没有空格
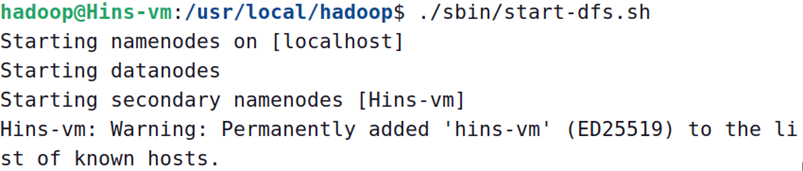
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、“DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
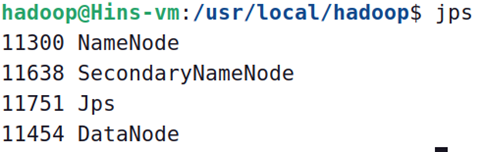
成功启动后,可以访问 Web 界面 http://localhost:9870 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
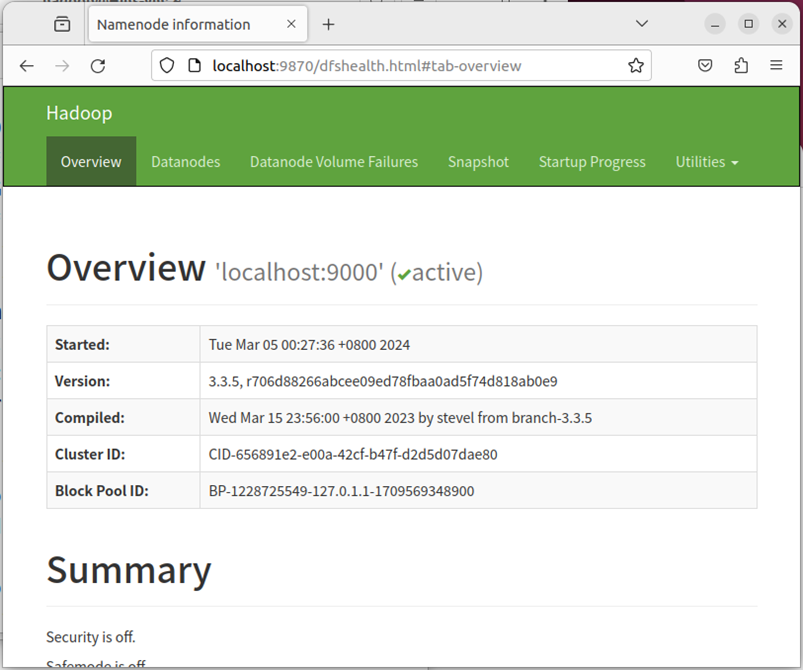
🕘 3.8 运行Hadoop伪分布式实例
上面的单机模式,grep 例子读取的是本地数据,伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录:
./bin/hdfs dfs -mkdir -p /user/hadoop
接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input:
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
复制完成后,可以通过如下命令查看文件列表:
hadoop@Hins-vm:/usr/local/hadoop$ ./bin/hdfs dfs -ls input
Found 10 items
-rw-r--r-- 1 hadoop supergroup 9213 2024-03-05 00:39 input/capacity-scheduler.xml
-rw-r--r-- 1 hadoop supergroup 1075 2024-03-05 00:39 input/core-site.xml
-rw-r--r-- 1 hadoop supergroup 11765 2024-03-05 00:39 input/hadoop-policy.xml
-rw-r--r-- 1 hadoop supergroup 683 2024-03-05 00:39 input/hdfs-rbf-site.xml
-rw-r--r-- 1 hadoop supergroup 1133 2024-03-05 00:39 input/hdfs-site.xml
-rw-r--r-- 1 hadoop supergroup 620 2024-03-05 00:39 input/httpfs-site.xml
-rw-r--r-- 1 hadoop supergroup 3518 2024-03-05 00:39 input/kms-acls.xml
-rw-r--r-- 1 hadoop supergroup 682 2024-03-05 00:39 input/kms-site.xml
-rw-r--r-- 1 hadoop supergroup 758 2024-03-05 00:39 input/mapred-site.xml
-rw-r--r-- 1 hadoop supergroup 690 2024-03-05 00:39 input/yarn-site.xml
伪分布式运行 MapReduce 作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件(可以将单机步骤中创建的本地 input 文件夹,输出结果 output 文件夹都删掉来验证这一点)。
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar grep input output 'dfs[a-z.]+'
查看运行结果的命令(查看的是位于 HDFS 中的输出结果):
./bin/hdfs dfs -cat output/*
结果如下,注意到刚才我们已经更改了配置文件,所以运行结果不同。
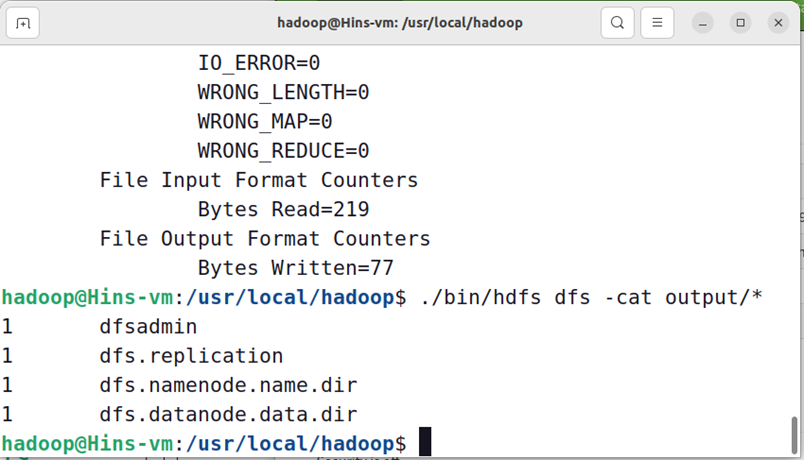
我们也可以将运行结果取回到本地:
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/*
Hadoop 运行程序时,输出目录不能存在,否则会提示错误 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次执行,需要执行如下命令删除 output 文件夹:
./bin/hdfs dfs -rm -r output # 删除 output 文件夹
在实际开发应用程序时,可考虑在程序中加上如下代码,能在每次运行时自动删除输出目录,避免繁琐的命令行操作:
Configuration conf = new Configuration();
Job job = new Job(conf);
/* 删除输出目录 */
Path outputPath = new Path(args[1]);
outputPath.getFileSystem(conf).delete(outputPath, true);
若要关闭 Hadoop,则运行
./sbin/stop-dfs.sh
注意:下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 就可以!
🕘 3.9 安装Hadoop集群
在平时的学习中,我们使用伪分布式就足够了。如果需要安装 Hadoop 集群,可查看🔎 Hadoop集群安装配置教程(Hadoop3.3.5)。
OK,以上就是本期知识点“Hadoop概述与搭建环境”的知识啦~~ ,感谢友友们的阅读。后续还会继续更新,欢迎持续关注哟📌~
💫如果有错误❌,欢迎批评指正呀👀~让我们一起相互进步🚀
🎉如果觉得收获满满,可以点点赞👍支持一下哟~
❗ 转载请注明出处
作者:HinsCoder
博客链接:🔎 作者博客主页