基础
内存分区
栈: 存放函数的局部变量、函数参数、返回地址等,由编译器自动分配和释放。
堆: 动态申请的内存空间,就是由 malloc 分配的内存块,由程序员控制它的分配和释放,如果程序执行结束还没有释放,操作系统会自动回收。
全局区/静态存储区(.bss 段和 .data 段): 存放全局变量和静态变量,程序运行结束操作系统自动释放,在 C 语言中,未初始化的放在 .bss 段中,初始化的放在 .data 段中,C++ 中不再区分了。
常量存储区(.data 段): 存放的是常量,不允许修改,程序运行结束自动释放。
代码区(.text 段): 存放代码,不允许修改,但可以执行。编译后的二进制文件存放在这里。
程序编译四个阶段
预处理阶段
1.什么是预处理
C语言的程序中可包括各种以符号#开头的编译指令,这些指令称为预处理命令。预处理命令属于C语言编译器,而不是C语言的组成部分。通过预处理命令可扩展C语言程序设计的环境。
预处理的作用
在集成开发环境中,编译,链接是同时完成的。其实,C语言编译器在对源代码编译之前,还需要进一步的处理:预编译。预编译的主要作用如下:
●将源文件中以”include”格式包含的文件复制到编译的源文件中。
●用实际值替换用“#define”定义的字符串。
●根据“#if”后面的条件决定需要编译的代码。
预处理器(cpp)根据以字符#开头的命令,修改原始的C程序。比如hello.c中第一行的#include<stdio.h>命令告诉预处理器读取系统头文件stdio.h的内容,并把它直接插入程序文本中,结果就得到了另一个C程序,通常是以.i作为文件扩展名。
编译阶段
编译器(ccl)将文本文件hello.i翻译成文本文件hello.s,它包含一个汇编语言程序。汇编语言程序中的每条语句都以一种标准的文本格式确切的描述了一条低级机器语言指令。
汇编阶段
汇编器(as)将hello.s翻译成机器语言指令,把这些指令打包成一种可重定位目标程序的格式,并将结果保存在目标文件hello.o中。hello.o文件是一个二进制文件,它的字节编码是机器语言指令而不是字符,如果我们在文本文件中打开hello.o文件,看到的将是一堆乱码。
链接阶段
链接器(ld)负责处理合并目标代码
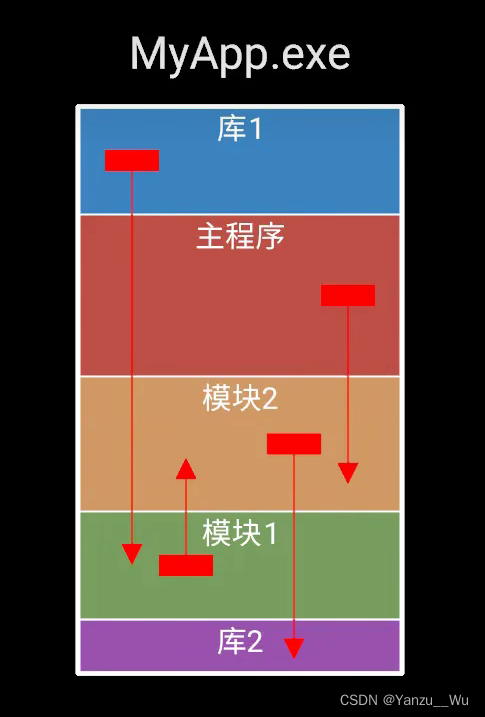
将主程序以及需要调用的库整合在一起,生成一个可执行目标文件,可以被加载到内存中,由系统执行。
其中,库分为动态库和静态库,他们的介绍和使用可以参考这篇文章:http://t.csdnimg.cn/GUdrx
原码,补码,反码
原码即十进制数的二进制形式,在最高位加上一个符号位1,0代表正数,1代表负数
若某数为正数或者0,则原码=反码=补码
若某数为负数,反码等于原码除符号位之外每位取反,补码等于反码+1
引入补码的原因为解决计算机通过原码进行2+(-2)这类运算会出错的问题,在计算机中只有设计了加法运算器,所以若需要进行减法运算入2-2,则只能利用加法2+(-2)进行运算,而利用原码进行带有负数的加法运算会出错,于是引出了补码。
总结:在计算机中,存储,运算时的数据形式都为补码,输出形式为原码
浮点数
M x 2^E M为尾数,E为阶数,2为基数,计算机领域默认基数为2
C中的float和double数据类型采用IEEE 754 规则
float,共 4个字节 32位,第1位最高位为符号位,8位指数位,23位尾数位
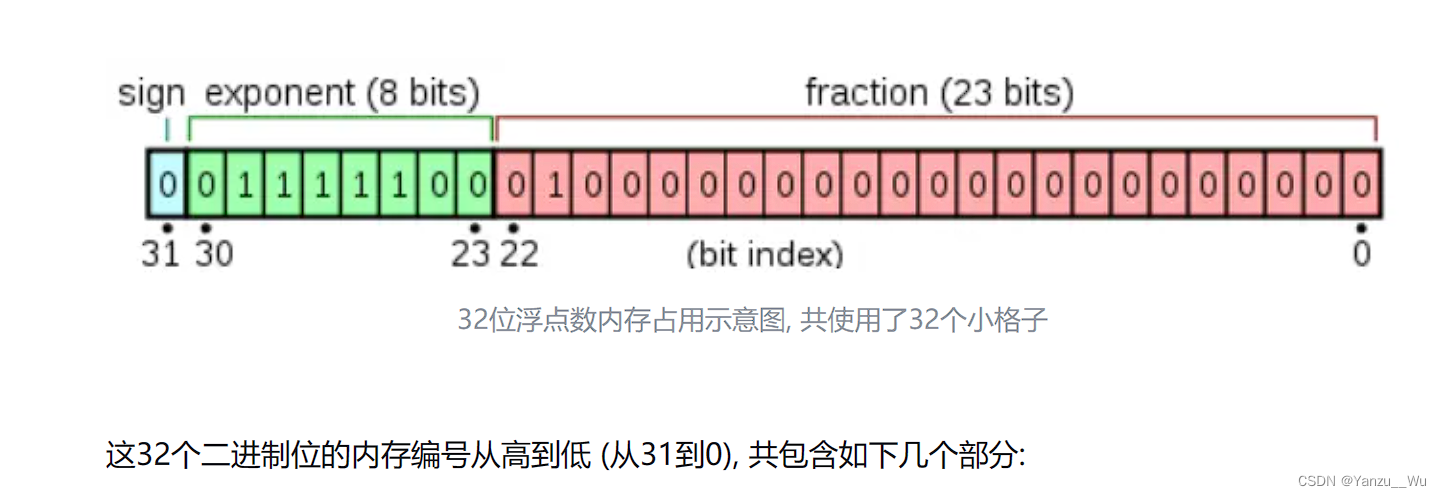
double,共 8个字节 64位,第1位最高位为符号位,11位指数位,52位尾数位

C语言中整型数据、浮点型数据在内存中的存储(超详细)_c语言 32位浮点型 整型-CSDN博客
左值和右值的区别
左值(lvalue)和右值(rvalue)最先来源于编译。在C语言中表示位于赋值运算符两侧的两个值,左边的就叫左值,右边的就叫右值。
定义:
左值指的是如果一个表达式可以引用到某一个对象,并且这个对象是一块内存空间且可以被检查和存储,那么这个表达式就可以作为一个左值。
右值指的是引用了一个存储在某个内存地址里的数据。
从上面的两个定义可以看出,左值其实要引用一个对象,而一个对象在我们的程序中又肯定有一个名字或者可以通过一个名字访问到,所以左值又可以归纳为:左值表示程序中必须有一个特定的名字引用到这个值。而右值引用的是地址里的内容,所以右值又可以归纳为:右值表示程序中没有一个特定的名字引用到这个值。
++a的话因为返回结果和运算之后的a一样,所以++a返回的是真实的a,可以被重新赋值,所以可以作为左值。而a++返回的是运算之前的a,而此时a已经+1了,返回的数据其实是过去的a,它是另外复制出来的,而不是真正的a,所以无法被赋值,所以它只能是右值。
所以a++;在执行当中的顺序是,先把a的值复制出来,进行整体运算,然后再a=a+1。
————————————————
原文链接:https://blog.csdn.net/qq_33148269/article/details/78046207
结构体字节对齐
结构体字节对齐详解【含实例】-CSDN博客
指针、引用、数组、内存
引用与指针区别
C 和 C++ 的一些区别,比如 new、delete 和 malloc、free 的区别
虚机制:虚函数、虚函数表、纯虚函数
继承、虚继承、菱形继承等
多态: 动态绑定,静态多态
1. 什么是多态?
多态就是多种形态,C++的多态分为静态多态与动态多态。静态多态就是重载,因为在编译期决议确定,所以称为静态多态。动态多态就是通过继承重写基类的虚函数实现的多态,因为是在运行时决议确定,所以称为动态多态。运行时在虚函数表中寻找调用函数的地址。
c++的多态性用一句话概括:在基类的函数前加上virtual关键字,在派生类中重写该函数,运行时将会根据对象的实际类型来调用相应的函数。如果对象类型是派生类,就调用派生类的函数;如果对象类型是基类,就调用基类的函数。
————————————————
原文链接:https://blog.csdn.net/m0_37715028/article/details/124758197
2. 多态的实现原理
1. 用virtual关键字声明的函数叫做虚函数,虚函数肯定是类的成员函数。
2. 存在虚函数的类都有一个一维的虚函数表叫做虚表。当类总声明虚函数时,编译器会在类中生成一个虚函数表。
3. 类的对象有一个指向虚表开始的虚指针,使调用虚函数时,能够找到正确函数。虚表和类是对应的,虚表指针和对象是对应的。
补充:虚函数表是一个存储类成员函数指针的数据结构,是由编译器自动生成和维护的。 当存在虚函数时,每个对象中都有一个指向虚函数的指针vptr,vptr一般作为类对象的第一个成员。
————————————————
原文链接:https://blog.csdn.net/m0_37715028/article/details/124758197
重写、重载
智能指针原理:引用计数、RAII(资源获取即初始化)思想
智能指针使用:shared_ptr、weak_ptr、unique_ptr等
1.unique_ptr是c++11版本库中提供的智能指针,它直接将拷贝构造函数和赋值重载函数给禁用掉,因此,不让其进行拷贝和赋值。
2. shared_ptr的原理
shared_ptr采用的是引用计数原理来实现多个shared_ptr对象之间共享资源:
shared_ptr在内部会维护着一份引用计数,用来记录该份资源被几个对象共享。
当一个shared_ptr对象被销毁时(调用析构函数),析构函数内就会将该计数减1。
如果引用计数减为0后,则表示自己是最后一个使用该资源的shared_ptr对象,必须释放资源。
如果引用计数不是0,就说明自己还有其他对象在使用,则不能释放该资源,否则其他对象就成为野指针。
引用计数是用来记录资源对象中有多少个指针指向该资源对象。
3.weak_ptrd的使用
shared_ptr固然好用,但是它也会有问题存在。假设我们要使用定义一个双向链表,如果我们想要让创建出来的链表的节点都定义成shared_ptr智能指针,那么也需要将节点内的_pre和_next都定义成shared_ptr的智能指针。如果定义成普通指针,那么就不能赋值给shared_ptr的智能指针。
所以在定义双向链表或者在二叉树等有多个指针的时候,如果想要将该类型定义成智能指针,那么结构体内的指针需要定义成weak_ptr类型的指针,防止循环引用的出现。————————————————
原文链接:https://blog.csdn.net/sjp11/article/details/123899141
21、野指针是什么?如何避免野指针?
野指针概念:指向内存被释放的内存或者没有访问权限的内存的指针。
如何避免野指针:
对指针进行初始化
①将指针初始化为NULL。
char * p = NULL;
②用malloc分配内存
char * p = (char * )malloc(sizeof(char));
③用已有合法的可访问的内存地址对指针初始化
char num[ 30] = {0};
char *p = num;
指针用完后释放内存,将指针赋NULL。
delete(p);
p = NULL;