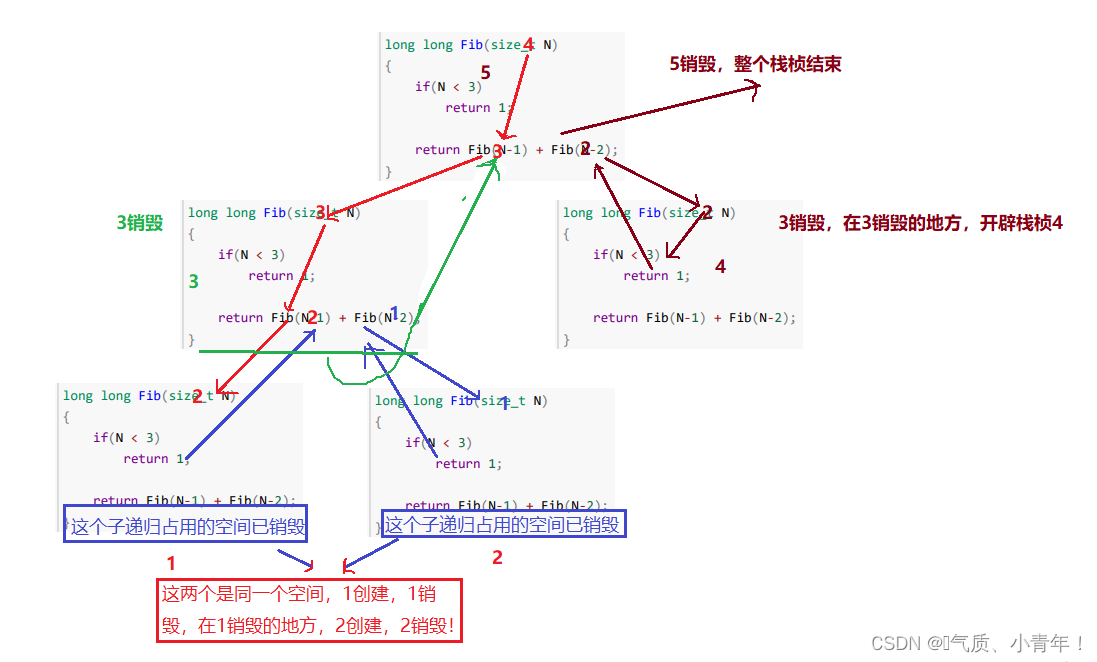
摘要
以往的Diffusion模型主要以卷积UNet作为主干网络,本文发现U-Net的归纳偏差对Diffusion模型的性能并不是至关重要的,可以用Transformer等取代。通过利用其他视觉方向成熟的Transformer方案和训练方法,Diffusion模型可以从这些架构中获益,且能保留UNet可扩展性、鲁棒性和效率等特性。
故本文提出一种基于Transformer的扩散模型,称为Diffusion Transformer(DiTs),DiT遵循ViT的技术方法。具体有:
- 用Transformer架构取代了以往在VAE的潜空间训练的Latent Diffusion Models(LDMs)框架中常用的U-Net主干
- 实验发现,增加Transformer的深度/宽度或增加输入token的数量会提高DiT的Gflops,但同时FID会降低。这证明DiTs是一个可扩展的架构,其网络复杂度(Gflops)和样本质量(FID)之间有很强的相关性
- 在基于class conditional的512×512和256×256 ImageNet基准上,最大的DiT-XL/2(118.6 Gflops)模型性能优于了先前所有的Diffusion模型,在256×256 ImageNet基准上实现了最先进的2.27的FID

上图为在512×512和256×256 ImageNet上训练的DiT-XL/2模型的生成示例。
框架
Preliminaries
Diffusion formulation
高斯扩散模型(DDPMs)假设了一个前向noise过程,该过程会将noise逐步添加真实数据 x 0 : q ( x t ∣ x 0 ) = N ( x t ; α ˜ t x 0 , ( 1 − α ˜ t ) I ) x_0:q(x_t|x_0)= N(x_t;\sqrt{\~α_t}x_0,(1−\~α_t)\Iota) x0:q(xt∣x0)=N(xt;α˜tx0,(1−α˜t)I),其中常数 α ˜ t \~α_t α˜t是超参数。通过对其应用重参化技巧,可以采样 x t = α ˜ t x 0 + 1 − α ˜ t ϵ t x_t =\sqrt{\~α_t}x_0 + \sqrt{1 − \~α_t} \epsilon_t xt=α˜tx0+1−α˜tϵt,其中 ϵ t ∼ N ( 0 , I ) \epsilon_t \sim N(0,\Iota) ϵt∼N(0,I)。
Diffusion模型被训练来学习正向加噪过程的反向过程,即 p θ ( x t − 1 ∣ x t ) = N ( μ θ ( x t ) , Σ θ ( x t ) ) p_{\theta}(x_{t-1}|x_t)=N(\mu_{\theta}(x_t),\Sigma_{\theta}(x_t)) pθ(xt−1∣xt)=N(μθ(xt),Σθ(xt)),其中神经网络用于预测 p θ p_θ pθ的统计数据。反向过程模型用 x 0 x_0 x0的对数似然的变分下界(ELBO)进行训练,Loss可简化为 L ( θ ) = − p ( x 0 ∣ x 1 ) + ∑ t D K L ( q ∗ ( x t − 1 ∣ x t , x 0 ) ∣ ∣ p θ ( x t − 1 ∣ x t ) ) L(θ) =−p(x_0|x_1)+\textstyle\sum_tD_{KL}(q^∗(x_{t−1}|x_t,x_0)||p_θ(x_{t−1}|x_t)) L(θ)=−p(x0∣x1)+∑tDKL(q∗(xt−1∣xt,x0)∣∣pθ(xt−1∣xt)),由于 q ∗ q^∗ q∗和 p θ p_θ pθ都是高斯分布,所以 D K L D_{KL} DKL可以用这两个分布的均值和协方差来计算。通过将 μ θ \mu_θ μθ重参化为noise预测网络 ϵ θ \epsilon_{\theta} ϵθ,模型可以使用预测noise ϵ θ ( x t ) \epsilon_θ(x_t) ϵθ(xt)和真实noise ϵ t \epsilon_t ϵt之间的均方误差 L s i m p l e ( θ ) = ∣ ∣ ϵ θ ( x t ) − ϵ t ∣ ∣ 2 2 L_{simple}(θ)=||\epsilon_θ(x_t)−\epsilon_t||^2_2 Lsimple(θ)=∣∣ϵθ(xt)−ϵt∣∣22进行训练。
但是,为了在训练过程中学习反向过程的协方差 Σ θ Σ_θ Σθ,需优化完整的 D K L D_{KL} DKL项。故一般用 L s i m p l e L_{simple} Lsimple训练 ϵ θ \epsilon_{\theta} ϵθ,并用完整的 L L L来训练 Σ θ Σ_θ Σθ。一旦 p θ p_θ pθ被训练,则新的图像可以通过初始化 x t m a x ∼ N ( 0 , I ) x_{t_{max}}∼N(0,I) xtmax∼N(0,I)和重参化技巧 x t − 1 ∼ p θ ( x t − 1 ∣ x t ) x_{t−1}∼p_θ(x_{t−1}|x_t) xt−1∼pθ(xt−1∣xt)来采样。
Classifier-free guidance
条件Diffusion模型可以将除 x t m a x x_{t_{max}} xtmax的额外信息作为输入,例如类类别标签 c c c。此时,反向过程转变为 p θ ( x t − 1 ∣ x t , c ) p_θ(x_{t−1}|x_t,c) pθ(xt−1∣xt,c),其中 ϵ θ \epsilon_{\theta} ϵθ和 Σ θ Σ_θ Σθ以 c c c为条件。这种情况下,可以使用classifier-free guidance来鼓励采样模型在高 log p ( c ∣ x ) \log p(c|x) logp(c∣x)的情况下找到 x x x。
根据贝叶斯公式, log p ( c ∣ x ) ∝ log p ( x ∣ c ) − log p ( x ) \log p(c|x) ∝ \log p(x|c) − \log p(x) logp(c∣x)∝logp(x∣c)−logp(x),故有 ∇ x log p ( c ∣ x ) ∝ ∇ x log p ( x ∣ c ) − ∇ x log p ( x ) ∇_x \log p(c|x) ∝ ∇_x \log p(x|c)−∇_x \log p(x) ∇xlogp(c∣x)∝∇xlogp(x∣c)−∇xlogp(x)。通过将Diffusion模型的输出解释为score函数,DDPM可通过 ϵ ^ θ ( x t , c ) = ϵ θ ( x t , ∅ ) + s ⋅ ∇ x log p ( x ∣ c ) ∝ ϵ θ ( x t , ∅ ) + s ⋅ ( ϵ θ ( x t , c ) − ϵ θ ( x t , ∅ ) ) \hat \epsilon_θ(x_t, c) = \epsilon_θ(x_t, ∅) + s \cdot ∇_x \log p(x|c) ∝ \epsilon_θ(x_t, ∅)+s \cdot (\epsilon_ θ(x_t, c)−\epsilon_θ(x_t, ∅)) ϵ^θ(xt,c)=ϵθ(xt,∅)+s⋅∇xlogp(x∣c)∝ϵθ(xt,∅)+s⋅(ϵθ(xt,c)−ϵθ(xt,∅))采样高 log p ( c ∣ x ) \log p(c|x) logp(c∣x)的 x x x,其中 s > 1 s > 1 s>1表示guidance scale( s = 1 s = 1 s=1时为标准采样)。 c = ∅ c=∅ c=∅表示Diffusion模型评估时,用一个“null”嵌入替换 c c c嵌入。
Latent diffusion models
直接在高分辨率像素空间中训练Diffusion模型的计算量非常大,而Latent diffusion models(LDMs)通过两阶段的方法解决了这个问题。首先训练一个autoencoder(VAE),并用学习到的编码器
E
E
E将图像压缩到更小的潜空间表示;然后在潜空间中用Diffusion训练表示
z
=
E
(
x
)
z = E (x)
z=E(x),并从Diffusion模型中采样一个新的表示
z
′
z'
z′,最后用学习到的解码器
x
=
D
(
z
′
)
x = D (z')
x=D(z′)将其解码为图像。

如上图所示,LDMs只需使用ADM等pixel space diffusion模型的一小部分Gflops,就可获得了良好的性能。故本文也将DiTs应用于潜空间。则本文的图像生成pipeline为一种基于混合的方法,使用卷积VAE和基于Transformer的DDPM。
Diffusion Transformer Design Space
DiT主要基于Vision Transformer(ViT)架构,该架构对patches序列进行操作,DiT保留了ViT的大部分配置。
Patchify
参考ViT,DiT的输入为空间表示
z
z
z(对于
256
×
256
×
3
256×256×3
256×256×3图像,
z
z
z的形状为
32
×
32
×
4
32×32×4
32×32×4)。DiT的第一层为“patchify”,其通过线性嵌入将输入patches转换为tokens序列
T
T
T,token维度为
d
d
d。随后将位置嵌入(position embedding)(sine-cosine版本)应用到所有tokens。patchify创建的tokens数量
T
T
T由patch size
p
p
p决定。

如上图所示,
p
p
p减半将使
T
T
T增加四倍,Transformer的Gflops也将增加四倍。本文patch size的设计空间为
p
=
2
,
4
,
8
p=2,4,8
p=2,4,8。
DiT block design

原始ViT中,在patchify之后,输入tokens会直接由一系列Transformer块处理。但DiT的输入除了noise图像外,有时还会处理额外的条件信息,如noise时间步
t
t
t,类标签
c
c
c,自然语言等。为了处理条件信息,本文探索了四种Transformer块的变体,其会对标准ViT模块进行了微小但重要的修改。如上图。
- In-context conditioning
简单地将 t t t和 c c c的embedding合并到输入tokens序列中,类似于ViT中的cls token。并在最后一个Transformer块之后,从tokens序列中删除这些条件token。这种方法给模型引入的Gflops可以忽略不计。 - Cross-attention block
将 t t t和 c c c的embedding拼接为长度为2的token序列,通过修改Transformer模块,在多头自注意力模块之后添加一个额外的多头交叉注意力层,并使用多头自注意力的输出作为query,条件embeddings作为key和value来引入条件。使用交叉注意力会为模型添加15%左右的Gflops。 - Adaptive layer norm(adaLN)block
采用自适应归一化层(adaLN)替换Transformer块中的标准归一化层(LN)。跟标准adaLN不同的是,本文不直接学习维度缩放和移位参数 γ \gamma γ和 β \beta β,而是从 t t t和 c c c的embedding的和中回归(MLP)计算 γ \gamma γ和 β \beta β,以作用于主特征。adaLN为模型添加的Gflops最少,计算效率最高。 - adaLN-Zero block
adaLN DiT块的一种修改。adaLN-Zero除了回归 γ \gamma γ和 β \beta β,还会每个DiT模块结束之前回归一个维度缩放参数 α \alpha α。并且adaLN的MLP会被初始化为零向量,这样初始化时DiT的残差模块就是一个identity函数。 与普通的adaLN块一样,adaLN-Zero给模型增加的Gflops可以忽略不计。
基于上述,将in-context、Cross-attention block、Adaptive layer norm(adaLN)block和adaLN-Zero block包括进DiT的设计空间。
Model size

如上图,本文提供了四种模型配置DiT-S、DiT-B、DiT-L和DiT-XL,涵盖了不同的模型尺寸和Gflops分配,基于此可衡量模型的缩放性能。
故将B、S、L和XL配置添加到DiT设计空间。
Transformer decoder
在最后的DiT块之后,使用layer norm(如果使用adaLN,则自适应)及线性解码器将得到的图像tokens序列解码为输出noise和输出对角线协方差,每个token会被线性解码为 p × p × 2 C p×p×2C p×p×2C的张量,其中 C C C是输入空间的通道数。最后,将解码后的tokens重新排列成原始的空间布局,得到预测的noise和协方差。输出的noise和对角线协方差的形状和原始输入的形状相同。
实验
Experimental Setup
本文实验探索了DiT设计空间并研究了不同缩放模型的特性,模型根据其配置和patch尺寸 p p p进行命名。如DiT-XL/2指XLarge配置且 p = 2 p=2 p=2。
Training
本文在 256 × 256 256×256 256×256和 512 × 512 512×512 512×512图像分辨率的ImageNet数据集上训练了class-conditional DiT模型。除了最后一层的线性层用零初始化,其余使用ViT的初始化技术。所有模型都使用学习率为 1 × 1 0 − 4 1×10^{−4} 1×10−4的AdamW来训练,没有使用weight decay和learning rate warmup,batchsize为256,使用的唯一数据增强是水平翻转。训练期间使用了decay为0.9999的指数移动平均(EMA),本文报告的所有结果都使用了EMA模型。本文继承了ADM的训练超参数,所有配置的模型都使用相同的训练超参数训练。
Diffusion
本文使用了Stable Diffusion的预训练变分自编码器(VAE)。VAE编码器的下采样因子为8,即给定 256 × 256 × 3 256×256×3 256×256×3的RGB图像 x x x, z = E ( x ) z = E (x) z=E(x)的形状为 32 × 32 × 4 32×32×4 32×32×4,DiT就在这个 z z z空间中运行。在得到DiT采样的新潜向量 z z z后,再使用VAE解码器 x = D ( z ) x = D (z) x=D(z)将其解码为像素。本文采用了ADM的Diffusion超参数。
Evaluation metrics
实验采用Frechet Inception Distance(FID)来衡量模型性能。在进行对比实验时遵循以往惯例,使用250 DDPM采样,并报告对应FID-50K。除非另有说明,否则只报告不使用classifier-free guidance的FID。实验还报告了Inception Score、sFID和Precision/Recall指标。本文报告的所有值都是通过导出样本,使用ADM的TensorFlow评估套件获得。
Compute
本文模型采用JAX实现,并在TPU-v3 pod上训练。DiT-XL/2是Gflops最大的模型,其以256的global batch size在TPU v3-256 pod上可以达到大约5.7iterations/second的速度训练。
消融实验
DiT block design
本节为DiT block的条件作用机制的选择消融实验,训练了四个Gflop最高的DiT-XL/2模型,每个模型都使用了不同的DiT block设计,包括in-context(119.4 Gflops)、cross-attention(137.6 Gflops)、adaptive layer norm(adaLN 118.6 Gflops)和adaLN-zero(118.6 Gflops),并在训练过程中测量FID。

结果如上图。观察到,adaLN-Zero块产生的FID低于cross-attention和in-context,同时是最高效的。在训练迭代了400K时,adaLN-Zero模型实现了in-context模型一半的FID,表明条件作用机制会严重影响模型质量。
其次,初始化方法也很重要,adaLN-zero将每个DiT块初始化为identity函数,其性能明显优于普通的adaLN。故对于本文的其余部分,所有模型都将使用adaLN-Zero DiT block。
Scaling model size and patch size
本节为模型大小和patch size的消融实验,训练了12个DiT模型,实验了不同的模型配置(S、B、L、XL)和patch size(8、4、2)。
Figure 2(左)给出了每个模型的Gflops及其在400K训练迭代时的FID。观察到,在所有情况下,增加模型大小和减少patch size都会显著改进DiT的性能。

上图(上)展示了在patch size不变的情况下,FID如何随着模型大小的增加而变化。在所有四种配置中,更深更广的Transformer都会显著改善所有训练阶段的FID。类似地,上图(下)显示了在模型大小保持不变的情况下,FID如何随着patch size的减小而改变,通过简单地扩展DiT处理的token数量,观察到在整个训练过程中FID有了相当大的改进。
DiT Gflops are critical to improving performance

上图中绘制了训练400K步骤时,不同配置模型的FID-50K情况及其Gflops。实验结果表明,不同配置的DiT在Gflops相近的情况下(如DiT-s/2和DiT-b/4),FID值越相近。证明模型的Gflops和FID-50K之间存在很强的负相关,表明模型的Gflops是改进DiT模型的关键因素。
Larger DiT models are more compute-efficient

上图将FID绘制为不同DiT模型的总训练Gflops的函数。训练Gflops估计方式为:模型Gflops
⋅
\cdot
⋅batch size
⋅
\cdot
⋅training steps$\cdot$3, 其中因子为3是因为反向传递的计算量约等于前向传递 的两倍。实验结果表明,更大training steps的小DiT模型比更小 training steps的较大的DiT模型计算效率低。 其次,发现在训练Gflops相同的时候,不同patch size的相同配置模型会产生不同的性能,如XL/4在大约
1
0
10
10^{10}
1010Gflops后的表现优于XL/2。
Visualizing scaling

本节验证模型大小和patch size的缩放对生成的样本质量的影响。上图可视化了使用相同的starting noise
x
t
m
a
x
x_{t_{max}}
xtmax、sampling noise和class labels从12个DiT模型中采样的结果,直观地看到了配置缩放如何影响DiT样本质量。观察到,增加模型大小和token数量(减小patch size)可以显著提高生成的视觉质量。
对比实验
256×256 ImageNet

在上述实验的
256
×
256
256×256
256×256模型之上,本节继续对DiT-XL/2训练了7M步,上表为与以往最先进模型的对比结果。观察到,当使用classifier-free guidance时,DiT-XL/2优于其他所有模型,将之前LDM获得的FID-50K从3.60降到2.27。相比潜空间的U-Net模型(如LDM-4(103.6 Gflops)),DiT-XL/2(118.6 Gflops)的计算效率更高,并大幅超越了像素空间U-Net模型(如ADM(1120 Gflops)或ADM-u(742 Gflops))。
与LDM-4和LDM-8相比,DiT-XL/2在所有测试中取得了更高的召回值。当只训练2.35M步(类似于ADM)时,XL/2仍然优于所有先前的扩散模型,FID为2.55。
512×512 ImageNet

本节在
512
×
512
512×512
512×512分辨率的ImageNet上训练了一个新的DiT-XL/2模型,并训练了3M步,其超参数与
256
×
256
256×256
256×256模型相同。上表为其与以往最先进方法的比较,观察都,在这个分辨率下XL/2再次超过了之前所有的Diffusion模型,将ADM获得的最佳FID从3.85降到3.04。XL/2仍然保持着最好的计算效率,如ADM为1983 Gflops、ADM-u为2813 Gflops,而XL/2只使用了524.6 Gflops。
Scaling Model vs. Sampling Compute

本节研究了较小的DiT模型是否在使用更多的采样计算时能胜过较大的模型。本节对所有模型training steps了400K后,计算了12个DiT模型的FID,每张图像分别使用[16、32、64、128、256、1000]个步骤采样。
结果如上图。对比使用1000步的DiT-L/2采样结果和使用128步的DiT-XL/2采样结果,此时,L/2消耗了80.7Tflops,XL/2消耗了15.2Tflops。结果表明XL/2有更好的FID-10K(23.7 vs 25.9),证明扩大采样计算量不能弥补模型的不足。
Appendix
Additional Implementation Details

上表包含了本文介绍的所有DiT模型的详细信息,包括
256
×
256
256×256
256×256和
512
×
512
512×512
512×512模型。

上表为ADM和LDM的DDPM U-Net模型的Gflop计数。
DiT model details
为了嵌入输入timesteps,使用了256维的frequency embedding及维数等于Transformer 隐藏大小和SiLU激活的两层MLP。每个adaLN层都会将timestep embedding和class embedding的和输入到SiLU非线性和MLP 层,其输出维度等于 4 × 4 \times 4×(adaLN)或 6 × 6 \times 6×(adaLN-zero)的 Transformer隐层大小。核心Transformer中使用了GELU作为激活函数。
Classifier-free guidance on a subset of channels
本文在classifier-free guidance 实验中,只对潜向量的前三个通道进行guidance,而不是对所有四个通道。经过实验调查发现,简单地调整guidance scale factor时,三通道引导和四通道引导的结果(FID)相似。
Additional Scaling Results
Impact of scaling on metrics beyond FID

上图展示了不同尺寸的DiT在FID、sFID、Inception Score、Precision和Recall指标下的表现。观察到,在所有指标中,更大的DiT模型计算效率更高,模型Gflops与性能高度相关。
Impact of scaling on training loss

上图为模型尺寸对训练损失的影响。观察到,增加DiT模型的Gflops会导致训练损失下降的更快,并在更低的值上饱和。
VAE Decoder Ablations

本文实验主要使用了LDM“f8”模型预训练VAE的微调版本(只有解码器权重被微调)。故本节消融三种不同的VAE解码器,包括LDM使用的原始解码器和Stable Diffusion使用的两个微调解码器。因为编码器在模型中是相同的,所以解码器可以直接换入,而无需重新训练整体模型。
上表显示了结果,当使用LDM解码器时,XL/2的性能继续优于以往所有prior diffusion模型。
Model Samples
本节展示在512×512和256×256分辨率下训练了3M和7M步的两个DiT-XL/2模型的生成样本。

上图为两个不同分辨率模型生成的示例。
下列图为给定输入文本class labels,在两个模型上执行一系列classifier-free guidance(由250个DDPM采样步骤和ft-EMA的VAE解码器生成)的生成样本。与之前使用guidance的工作一样,DiT下更大的guidance尺度会增加视觉保真度,并减少样本多样性。










reference
William, P. , & Saining, X. . (2023). Scalable Diffusion Models with Transformers.


![P6354 [COCI2007-2008#3] TAJNA](https://img-blog.csdnimg.cn/img_convert/fcb815275ab384982b95ad50976c9e3d.png)