Spark运行架构与核心组件
1.Spark运行梁构
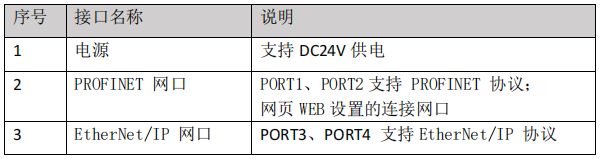
spark运行架构包括master和slave两个主要部分。master负责管理整个集群的作业任务调度,而slave则负责实际执行任务。
dirver是Spark驱动器节点,负责执行Spark任务中的main方法,将用户程序转换成作业形式,并调度executor执行任务。
2.核心组件
Driver:负责将用户程序转换成作业形式,调度executor执行任务,跟踪执行情况,并通过UI展示运行情况。
Executor:在集群中的工作节点上运行,负麦执行Spark应用的任务,任务彼此之间相互独立并将结果返回给driver,它还管理RDD的内存或存储。
Master:负责资源调度和分配,进行集群监控等职责。
Worker:运行在集群服务器上,执行具体的计算任务。
Application Master:在YARN环境中使用,负麦申请资源容器,运行用户程序任务,监控任务状态。
3.核心概念
Executor 与 Core
Spark Executor 是集群中运行在工作节点(Worker)中的一个 JVM 进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点 Executor 的内存大小和使用的虚拟 CPU 核(Core)数量。
 并行度(Parallelism)
并行度(Parallelism)
在分布式计算框架中一般都是多个任务同时执行,由于任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,记住,这里是并行,而不是并发。
RDD及其特性
1.RDD定义
RDD(弹性分布式数据集)是Spark中最基本的数据处理模型,是弹性的,不可变的、可分区,里面的元素可并行计算的集合。
2.RDD特性
弹性:存储上可以自动切换内存和磁盘,容错上可以目动恢复数据丢失,计算上有重试机制,分片上可以根据需要分片。
分布式:数据存储在大数据集群的不同节点上。
数据集:封装了计算逻辑,但不保存数据。
不可变:RDD封装了计算逻辑,不可改变,只能产生新的RDD来保存修改后的数据。
可分区井行计算:可以进行分区并行计算。
3.RDD核心属性
分区列表:用于执行任务时的并行计算,
分区计算函数:在每一个分区进行计算的函数
依赖关系:多个RDD之间的依赖关系。
RDD执行原理
1 资源申请与任务分发
Spark框架在执行时会先申请资源,将应用程序的数据处理逻辑分解成计算任务,分发到已分配资源的计算节点上进行计算。
2 任务执行流程启动YARN集群环境,Spark通过申请资源创建调度节点和计算节点,根据需求将计算逻辑划分成不同任务,调度节点将任务发送给对应的计算节点进行计算。
RDD序列化与依赖关系
1.应列化
RDD序列化包含闭包检查、房列化方法和性、房列化框架等,需要确保算子外的数据可以列化,否则无法传给
executor端执行。
2.依赖关系
血缘关系:记录RDD的转换行为,以便在分区数据丢失时重新计算恢复数据。
依赖关系:两个相邻RDD之间的关系。
窄依赖:每个上游RDD的分区最多被子RDD的一个分区便用。
宽依赖:每个上游RDD的分区可能被多个子RDD的分区使用。
RDD的阶段划分
DAG(有向无环图):由点和线组成的拓扑结构,代表RDD转换任务的过程。
阶段划分:
Application:初始化Spark Context,生成Application。
Job:由action算子生成Job。
stage:宽依赖的个数加一。
Task:每个Stage阶段里的分区个数。
RDD持久化
缓存与持久化:
缓存默认在虚拟机的堆内存中。
通过cache或persist方法缓存,需触发action算子后才实际缓存。
检查点(Checkpoint):
将RDD中间结果写入磁盘,减少容错成本。
需触发action操作后才执行。
RDD的文件读取与保存。
文件格式:包括tex、CSV、object文件等。
文件系统:本地文件系统、HDFS、HBase及数据库。
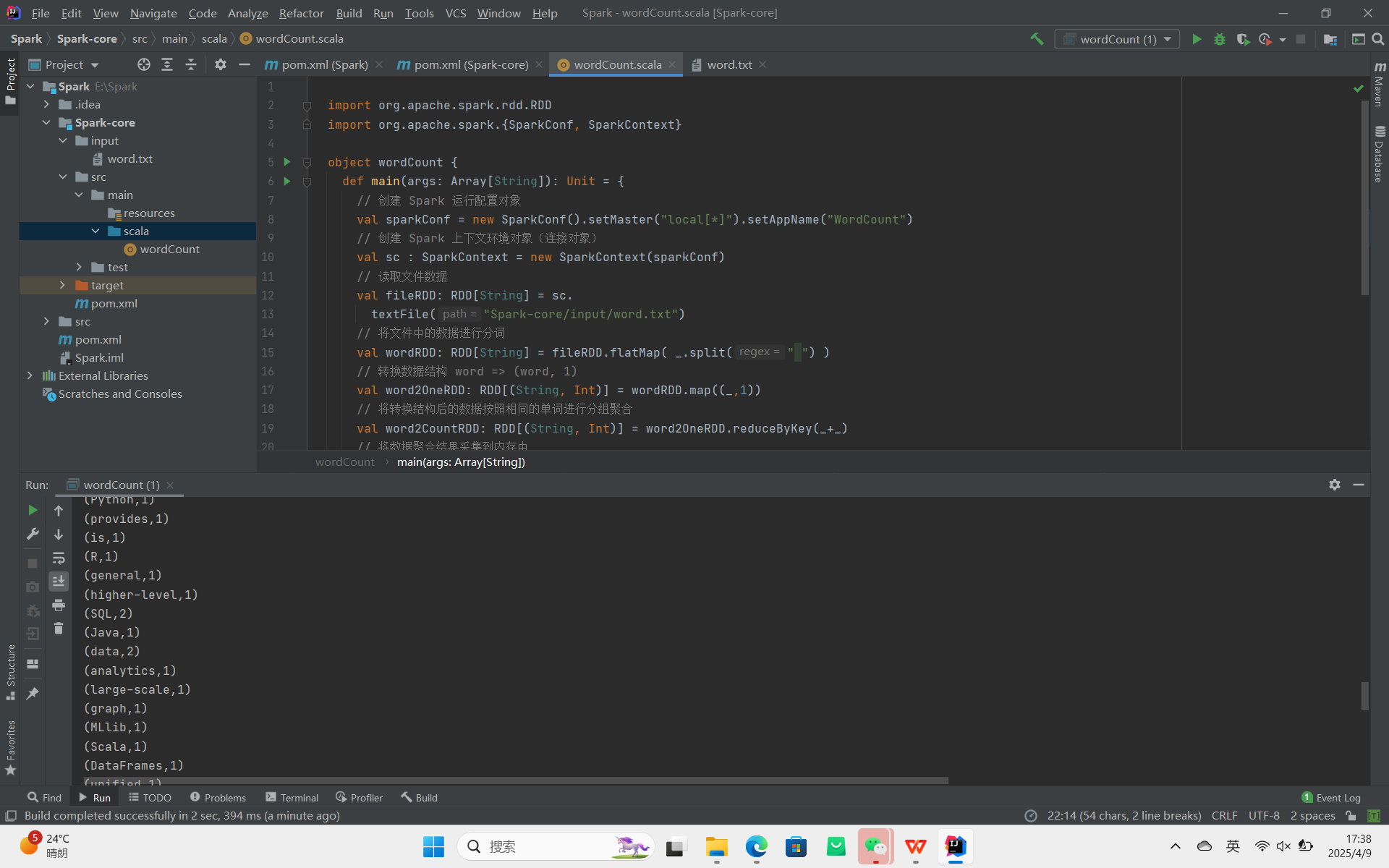
案例图片