1.概述
维度: 对于数组和series,维度就是功能shape返回的结果,shape中返回了几个数字,就是几个维度。降维算法中的”降维“,指的是降低特征矩阵中特征的数量。降维的目的是为了让算法运算更快,效果更好,但其实还有另一种需求:数据可视化。
2. sklearn中的降维算法

3. PCA与SVD
在降维中,PCA使用的信息量衡量指标,就是样本方差,又称可解释性方
差,方差越大,特征所带的信息量越多。
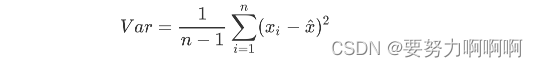
Var代表一个特征的方差,n代表样本量,xi代表一个特征中的每个样本取值,xhat代表这一列样本的均值。
无偏估计:
1.https://www.bilibili.com/video/BV1pq4y1p7nu/?spm_id_from=333.999.0.0&vd_source=50d7155404373ccb2004b778100660be
2.https://www.bilibili.com/video/BV1CT4y1j71j/?spm_id_from=333.999.0.0&vd_source=50d7155404373ccb2004b778100660be
3.1 降维是如何实现的
重要的步骤:
找出n个新特征向量,让数据能够被压缩到少数特征上并且总信息量不损失太多的技术就是矩阵分解。
PCA使用方差作为信息量的衡量指标,并且特征值分解来找出空间V。
SVD使用奇异值分解来找出空间V,其中Σ也是一个对角矩阵,不过它对角线上的元素是奇异值,这也是SVD中用来衡量特征上的信息量的指标。
通常来说,在新的特征矩阵生成之前,我们无法知晓PCA都建立了怎样的新特征向量,新特征矩阵生成之后也不具有可读性。以PCA为代表的降维算法因此是特征创造(feature creation,或feature construction)的一种。
3.1.1 重要参数
(1) n_components
n_components是我们降维后需要的维度,即降维后需要保留的特征数量。
(2)svd_solver 与 random_state
参数svd_solver是在降维过程中,用来控制矩阵分解的一些细节的参数。有四种模式可选:“auto”, “full”, “arpack”,“randomized”,默认”auto"。
参数random_state在参数svd_solver的值为"arpack" or "randomized"的时候生效,可以控制这两种SVD模式中的随机模式。
(3) 重要属性components_
特征信息数据,不可以进行可视化。
3.1.2 重要接口
(1)inverse_transform
通过让原特征矩阵X右乘新特征空间矩阵V(k,n)来生成新特征矩阵X_dr,那理论上来说,让新特征矩阵X_dr右乘V(k,n)的逆矩阵 ,就可以将新特征矩阵X_dr还原为X。
案例:


![236. 二叉树的最近公共祖先 - 力扣[LeetCode]](https://img-blog.csdnimg.cn/25bcf3890b7d4b5d974d5f927c4e5005.png)

![[JavaEE]线程的状态与安全](https://img-blog.csdnimg.cn/b3be26ed346b4687814cbbe267a6e933.png)