目录
一、数据清理
二、数据变换
三、特征工程
四、总结
一、数据清理
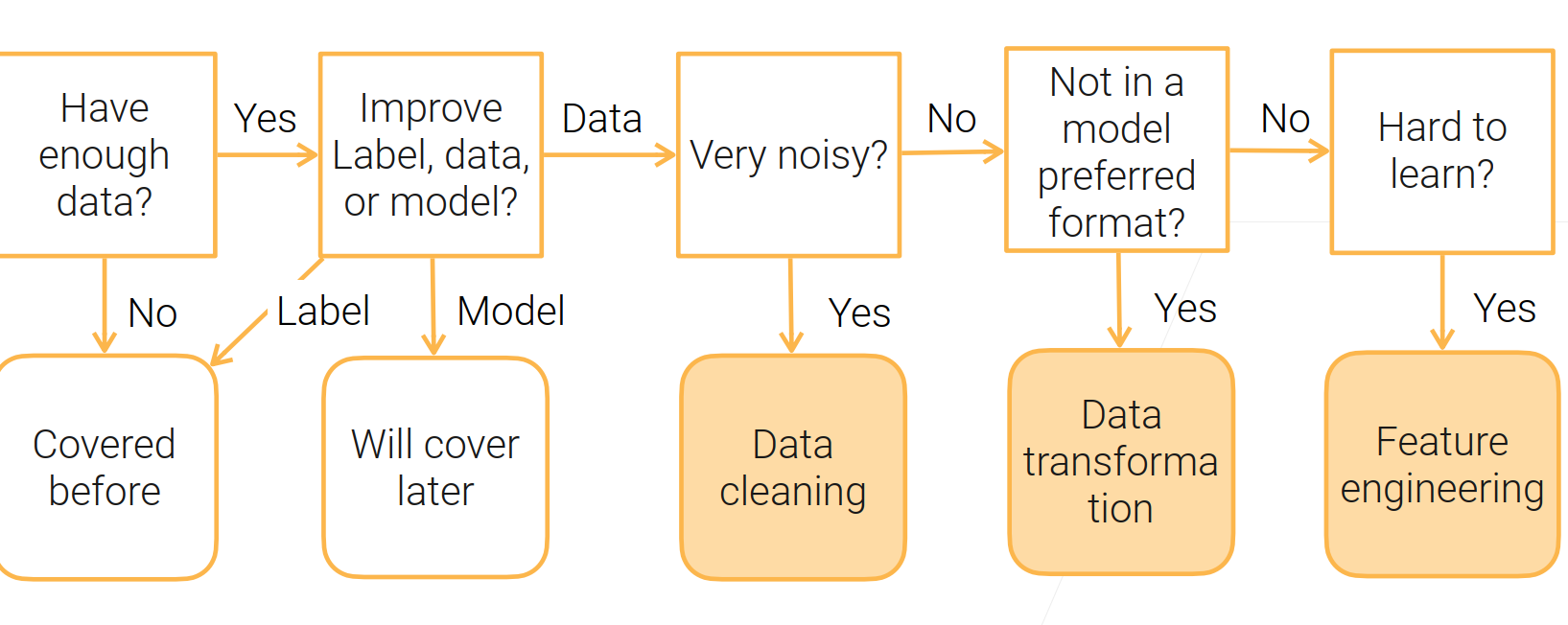
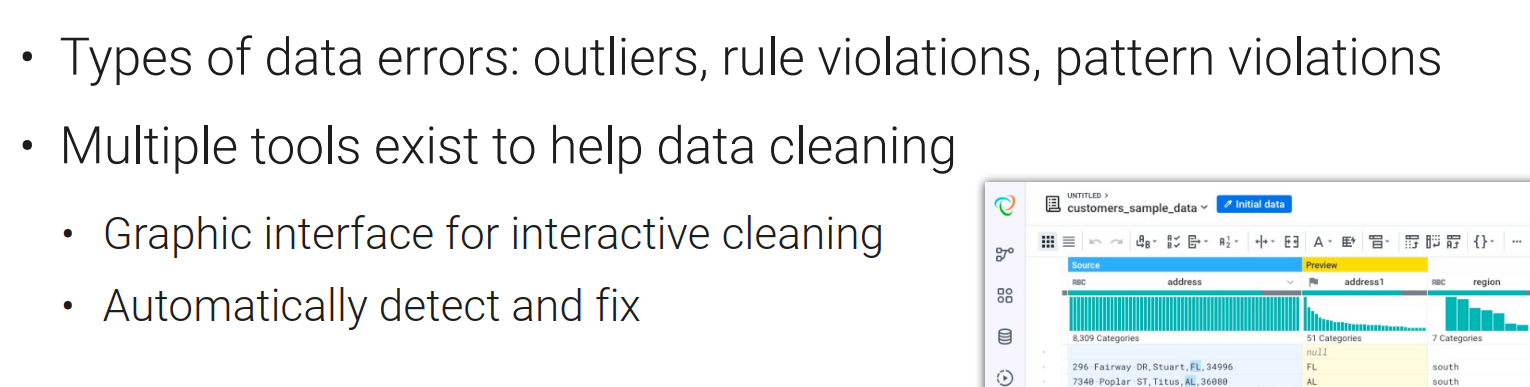
数据清理是提升数据的质量的一种方式。
- 数据不干净(噪声多)?
需要做数据的清理,将错误的信息纠正过来;
- 数据比较干净(数据不是想要的格式)?
对数据进行变换;
- 数据对模型不是很友好?
对数据的特征进行提取。
数据的错误
- 收集到的数据与真实观测值不一致【数值丢失,数值错误,极端的值】。
- 好的模型对错误是有容忍度的【给了错误的数据一样是能够收敛但是精度会比用干净的数据低一点】。
- 部署了这样的模型后可能会影响新收集来的数据结果。
数据错误的类型
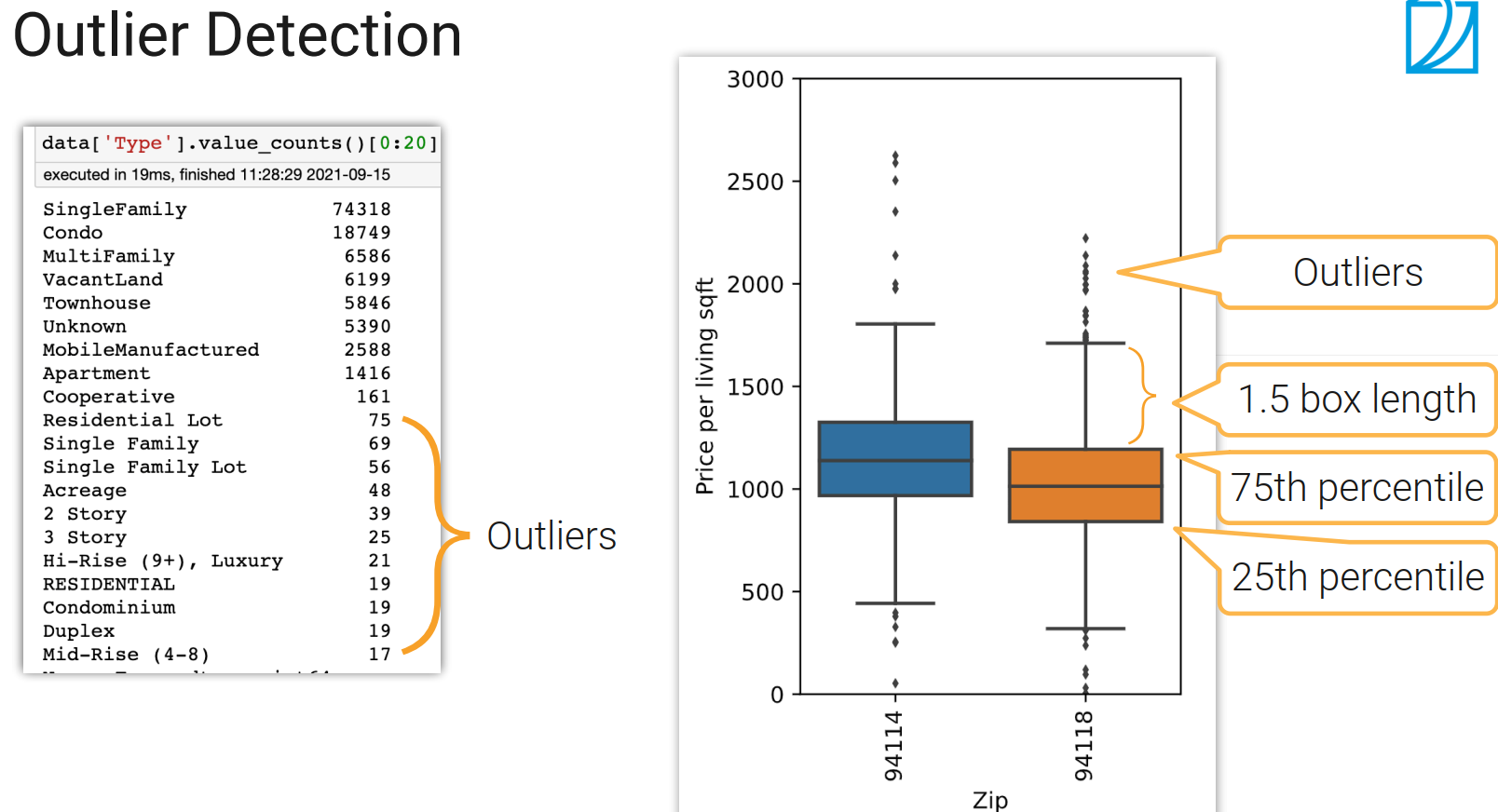
- 数据中某个样本的数值不在正常的分布区间中(Outlier)
- 违背了规则(Rule violations)
- 违反了语法上或语义上的限制(Pattern violations)
不同类型的错误要怎么做检测?
Rule-based Detection
Pattern-based Detection
总结
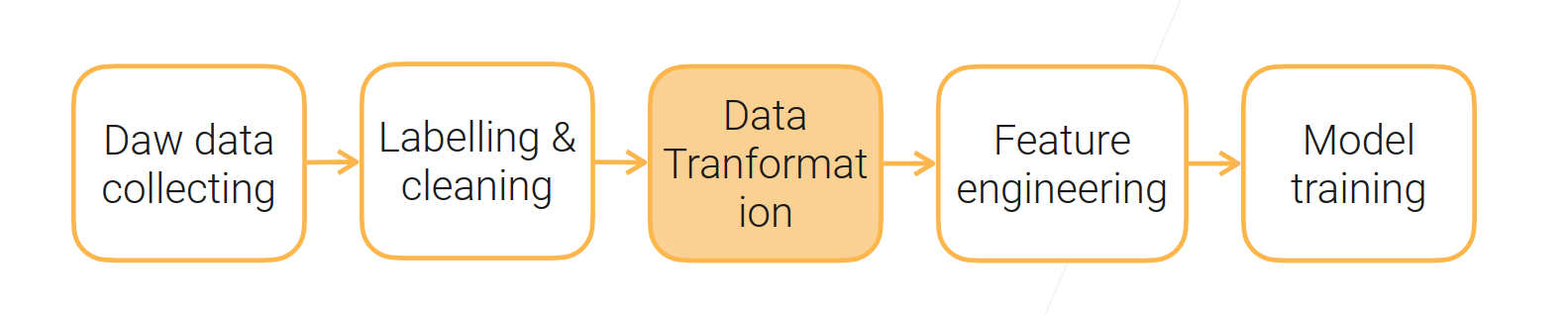
二、数据变换
数据标注、清理到特征工程之间的操作是数据变换
对数值的变换
- 把一个列里面的数值的最小值与最大值都限定到一个固定区间内,然后把所有的元素只通过线性变化出来【将数据的单位放到合理的区间】;
- Z-score 一个更常见的算法:通过算法使得均值变为0,方差变为1
- 把一列的数据换成是-1到1之间的数据
- 对数值都是大于0,且数值变换比较大可以试一下log一下【log上面的加减等于原始数据的乘除,可以将计算基于百分比的】
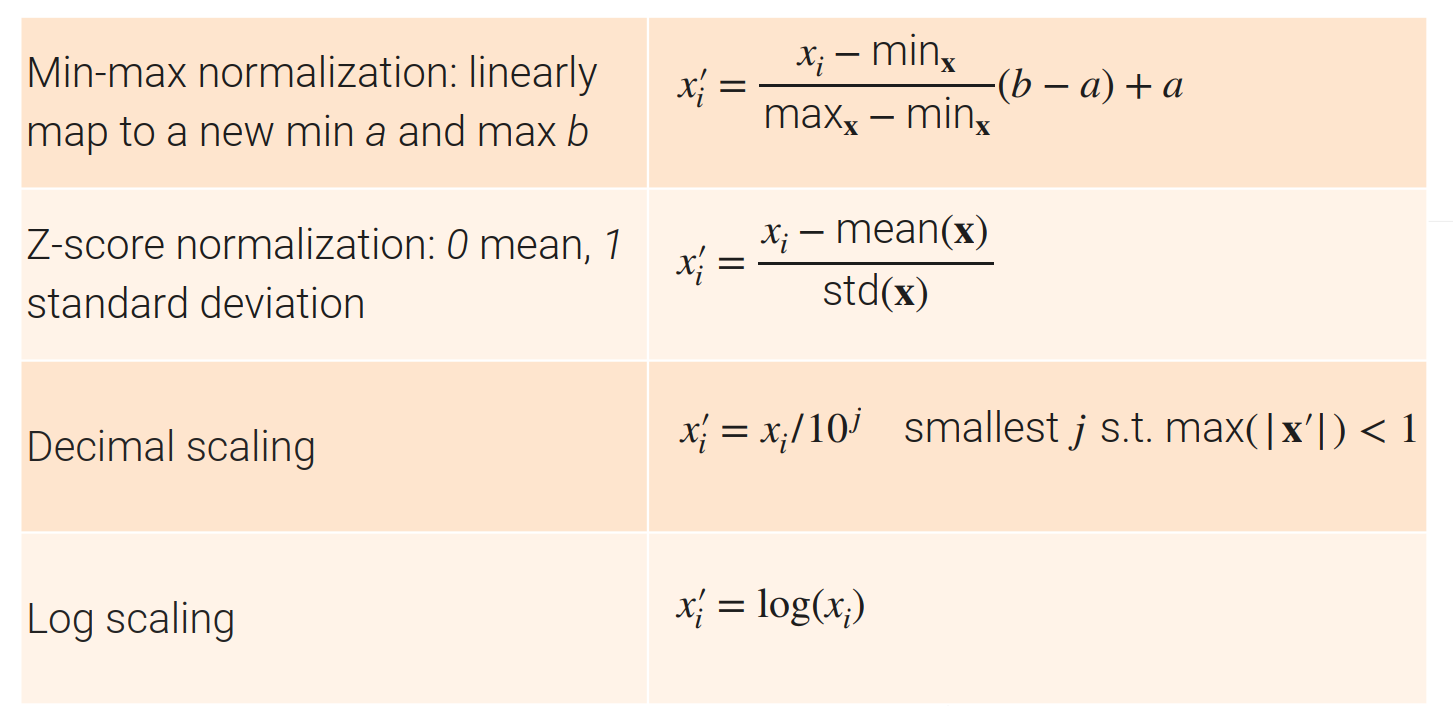
对图片的变换
- 将图片的尺寸变小【机器学习对低分辨率的图片不在意】
- 图片采样的比较小,且jpeg选用中等质量压缩,可能会导致精度有1%的下降(ImageNet)【数据的大小与质量要做权衡】
对视频的变换
- 比如:使用短视频(10s以内),将视频切到感兴趣的部分
对文本的变换
- 词根化(语法化):把一个词变成常见的形式
- 词元化(机器学习算法中最小的单元)
总结

三、特征工程
为什么需要特征工程:
因为机器学习的算法比较喜欢定义的比较好的、它能比较好的去处理的、固定长度的输入输出。
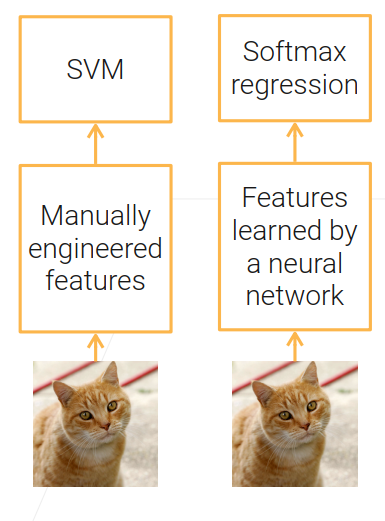
对表的数据
- 对于整型或浮点型的数据,可以直接用或者是把最大最小值拿出来,再把这个数据分成n个区间,如果值在区间中,则会给它对应区间的下标i【这样可以让机器学习算法不去纠结一个具体的值(细粒度的值)】
- 对于类别的数据,一般采用one-hot(独热)编码(虽然有n列,但是只有每一列有值)【虽然有很多的类别但是常见的只有几个类,可以将少数的类别变成不确定的类别,只保留那些比较重要的类别,这样可以把这些重要的类别放到可控的单元内】
- 对于时间的特征,将时间的数据弄成机器学习算法能知道这些天数中是有特殊意义的日子(周末、休息日、新年之类的)
- 特征组合:这样子能拿到两两特征之间相关性的东西

对文本的数据
- 可以将文本换成一些词元(token)
- Bag of woeds(BoW) model:把每一个词元(token)弄成one-hot编码,再把句子里的所有词元加起来【这里要注意的是 怎么样把词典构造出来,不能太大也不能太小;BoW model最大的问题在于原句子的信息丢失了】。
- Word Embeddings(词嵌入):将词变成一个向量,向量之间具有一定的语义性的(两个词之间对应的向量之间的内积比较近的话,说明这两个词在语义上来说是比较相近的)
- 可以使用预训练的模型(BERT,GPT-3)
对于图片与视频
- 传统是用手动的特征方式如SIFT来做
- 现在用预训练好的深度神经网络来做(ResNet,I3D)
总结

四、总结
要启动一个机器学习任务
- 有没有足够的数据?
没有的话就去收集数据【发掘在哪里找数据;数据增强;生成自己需要的数据;(以上方法都不可以可能这个任务不那么适合机器学习)】
- 对数据进行提升。 标号?数据质量?模型?
1、对模型之后会展开
2、提升标号:没有标号可以去标;标号里面有很多错误的话,要对它进行清理;【数据标注:半监督学习;有钱可以众包;看看数据长什么样子,找其他的规则,从数据中提起有弱噪音的标号,也是可以用来训练模型的】
3、数据预处理:看看数据长什么样子;通常来说数据是有很多噪音的,要对数据清洗;将数据变成我们需要的格式;特征工程;
4、上面的过程可以说是一个迭代的过程。
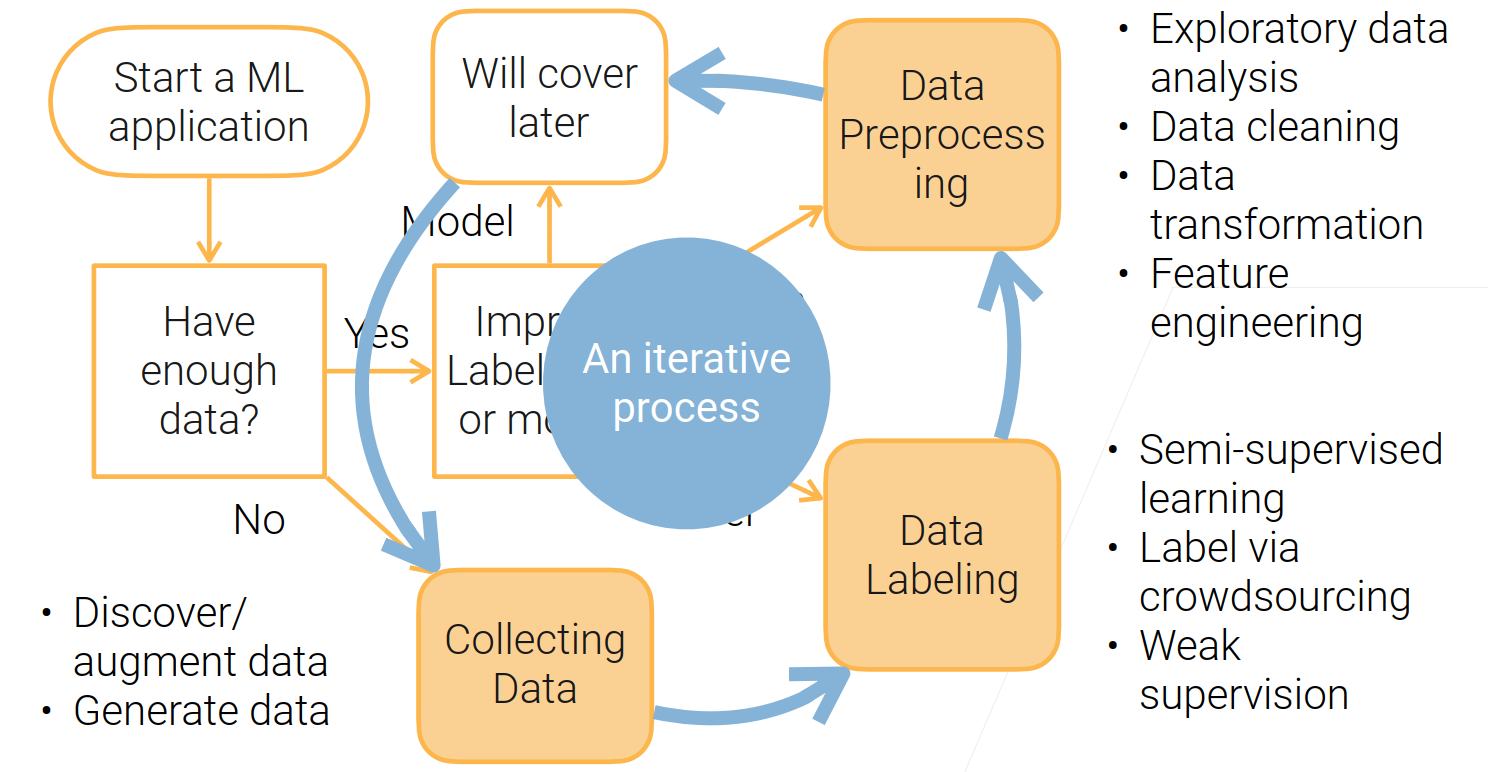
面对的挑战:
数据的质与量要做权衡;
数据质量:数据的多样性:产品所关心的方方面面都要考虑;无偏差:数据不能只是偏向于一个方面;公平性:不区别对待数据。
大数据的管理是一件很难的事情:存储;快速处理;版本控制;数据安全 。


![236. 二叉树的最近公共祖先 - 力扣[LeetCode]](https://img-blog.csdnimg.cn/25bcf3890b7d4b5d974d5f927c4e5005.png)

![[JavaEE]线程的状态与安全](https://img-blog.csdnimg.cn/b3be26ed346b4687814cbbe267a6e933.png)