1 基本概念
过度拟合(overfit)
创建的模型与用于该模型的训练数据之间发生过于密切的关系,从而引起该模型无法对新数据进行准确的预测。正则化(Regularization)策略可以减少过度拟合,或者使用大数据量、多样化数据类型的数据集用于训练也可以减少过度拟合。
过度拟合问题,非常类似于学生与老师之间的学习关系,例如,一个偏科的学生仅善于自己有兴趣的科目以及只善于从该科目的老师中学习,而对其他科目不感兴趣以及不善于从其他科目的老师中学习,因而,偏科就是一个现实中过度拟合的实例。因此,一个学生需要培养对不同的科目感兴趣以及善于从不同的老师中学习,则该学生具备综合能力、具备处理问题的应变能力。
正则化(regularization)
用于在训练过程中减少过度拟合的机制,在机器学习的过程中使用正则化机制不断地校正相关的数据,常用的正则化机制的类型包括:
|
正则化也被定义成对模型复杂度的处罚措施。
正则化机制是违反直觉的,例如,增加正则化通常会增加训练的损失值,这种场景很容混淆,合理的解释是,最小化损失值的目标是提升预测的准确程度,而正则化机制的目标也是提升预测的准确度,但是最小化损失值不是正则化的目标,因此,即使正则化会增加损失值,但是正则化有利于帮助模型对现实世界的数据样本做出更准确的预测。
L1正则化(L1 regularization)
该正则化机制是处罚一个权重在所有权重的绝对值之和中的比例,也就是,将不相关或者强相关特征的权重占比设置为0,因而,一个权重占比等于0的特征可以高效地从模型中被删除。
L2正则化(L2regularization)
该正则化机制是处罚一个权重在所有权重平方之和中的比例,也就是,将离群的特征值(数值大的正值或者数值小的负值)的权重设置为接近0值但是不等于0值,因而,一个权重占比接近0值的特征在模型中依然被保留,但是不会影响模型预测的准确度。
删除正则化(dropout regularization)
该正则化机制是用于训练神经网络,在一个隐藏层固定数目的单元中为一个梯度步骤删除一个随机选择的单元,删除的单元越多,正则化的效果越强。
提早停止(early stopping)
该正则方法是用在训练过程中损失值完成最小化之前结束训练,使用提早停止训练,用户可以有目标地在验证数据集的损失值开始上升的时候停止模型训练,也就是,该正则化机制可以在模型训练的效果变差之前提早结束训练。
离群值
与大部分值都保持一定距离的值,在机器学习中,离群值分类如下所示:
|
例如,假设价格是一个模型的特征,数据集的均值是7元,标准差是1元,则12元与2元的价格是离群值,因为离均值7元的距离都是5元。出现离群值的大多数原因是数据出错,需要使用均值进行筛选。
2 过拟合与欠拟合
本章节主要是使用技术框架tf.keras从代码的角度描述机器学习中关于数据训练的过度拟合(过拟合)以及拟合不足(欠拟合)的场景。
在前面的分类模型以及燃油预测的实例分析中,模型在验证数据的准确度在经过多次的迭代训练之后达到峰值,然后准确度保持稳定的状态或者开始下降。
也就是,模型将会开始过度拟合训练数据,因此,在机器学习过程中模型应该学会如何去处理过度拟合显得非常重要。虽然经常可能获得一个有关训练数据集的高准确度,但是,模型真正需要的是从测试数据集中(新数据)获取一个高准确度的预测。
过度拟合的相反是拟合不足,当训练数据还有改善的空间,则会出现拟合不足的情况,出现拟合不足的原因有很多,例如,构建的模型不够完善,模型过于正则化,模型参与训练的时间不足,也就是,模型或者网络还没有从训练数据中学会相关的风格,不完全掌握这些受训数据之间的关系。
但是,如果训练的时间太长,则会引起过度拟合,所学到的风格不适用于测试数据集(新数据)。因此,模型需要在过度拟合与拟合不足之间寻找一种平衡的状态,也就是,模型需要在训练过程中掌握一个合适的迭代次数。
为了更有效地防止出现过度拟合,最好的方法使用更加完整的训练数据集,也就是,训练数据集必须覆盖模型期望处理的所有范围,更广泛的范围的训练数据集有利于更好的训练效果。
安装工具

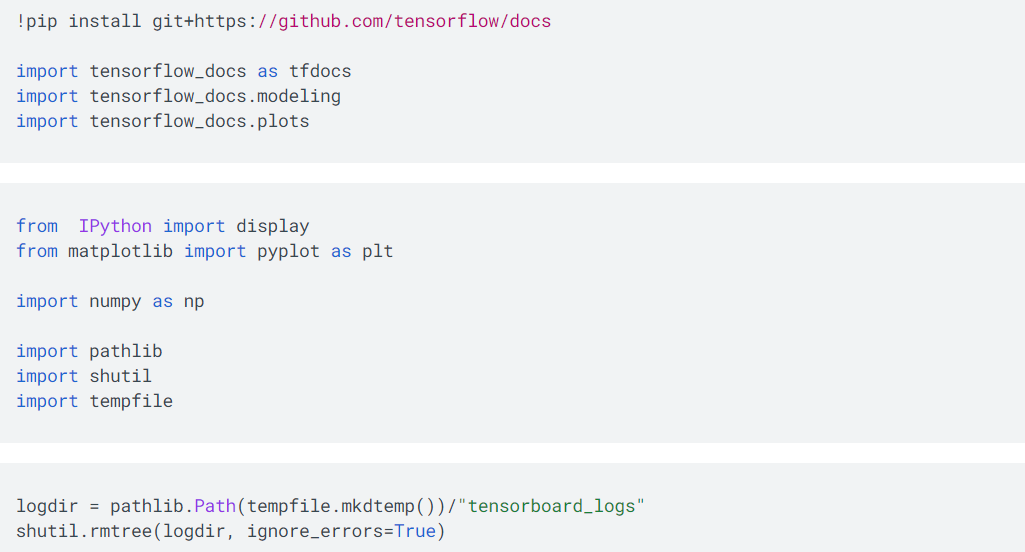
如上所示,导入keras相关的正则化工具集regularizers、以及其他基础库。
Higgs数据集
该数据集是物理学上的实验数据集,包括数据样本数是11,000,000,而每个数据样本包括28个特征,以及一个二元分类的标签。


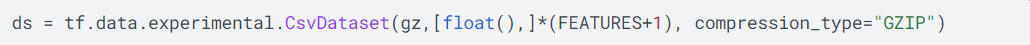
如上所示,从教育机构下载Higgs的实验数据,使用 CsvDataset工具解压以及读取Csv格式的数据集。

如上所示,定义一个函数,处理Csv格式的数据集的每行数据样本,并且返回每行数据样本的特征与标签,其中,label是标签,features是特征。
(未完待续)



![[UE笔记]延迟与延迟补偿](https://img-blog.csdnimg.cn/2420d56cf00f4ab8a6365f289187145a.png)