利用Python实现酒店评论的情感分析
完整代码下载地址:利用Python实现酒店评论的中文情感分析
情感极性分析,即情感分类,对带有主观情感色彩的文本进行分析、归纳。情感极性分析主要有两种分类方法:基于情感知识的方法和基于机器学习的方法。基于情感知识的方法通过一些已有的情感词典计算文本的情感极性(正向或负向),其方法是统计文本中出现的正、负向情感词数目或情感词的情感值来判断文本情感类别;基于机器学习的方法利用机器学习算法训练已标注情感类别的训练数据集训练分类模型,再通过分类模型预测文本所属情感分类。本文采用机器学习方法实现对酒店评论数据的情感分类,利用Python语言实现情感分类模型的构建和预测,不包含理论部分,旨在通过实践一步步了解、实现中文情感极性分析。
1 开发环境准备
1.1 Python环境
在python官网https://www.python.org/downloads/ 下载计算机对应的python版本,本人使用的是Python2.7.13的版本。
1.2 第三方模块
本实例代码的实现使用到了多个著名的第三方模块,主要模块如下所示:
- 1)Jieba
目前使用最为广泛的中文分词组件。下载地址:https://pypi.python.org/pypi/jieba/ - 2)Gensim
用于主题模型、文档索引和大型语料相似度索引的python库,主要用于自然语言处理(NLP)和信息检索(IR)。下载地址:https://pypi.python.org/pypi/gensim
本实例中的维基中文语料处理和中文词向量模型构建需要用到该模块。 - 3)Pandas
用于高效处理大型数据集、执行数据分析任务的python库,是基于Numpy的工具包。下载地址:https://pypi.python.org/pypi/pandas/0.20.1 - 4)Numpy
用于存储和处理大型矩阵的工具包。下载地址:https://pypi.python.org/pypi/numpy - 5)Scikit-learn
用于机器学习的python工具包,python模块引用名字为sklearn,安装前还需要Numpy和Scipy两个Python库。官网地址:http://scikit-learn.org/stable/ - 6)Matplotlib
Matplotlib是一个python的图形框架,用于绘制二维图形。下载地址:https://pypi.python.org/pypi/matplotlib - 7)Tensorflow
Tensorflow是一个采用数据流图用于数值计算的开源软件库,用于人工智能领域。
官网地址:http://www.tensorfly.cn/
下载地址:https://pypi.python.org/pypi/tensorflow/1.1.0
2 数据获取
2.1 停用词词典
本文使用中科院计算所中文自然语言处理开放平台发布的中文停用词表,包含了1208个停用词。下载地址:http://www.hicode.cc/download/view-software-13784.html
2.2 正负向语料库
文本从http://www.datatang.com/data/11936 下载“有关中文情感挖掘的酒店评论语料”作为训练集与测试集,该语料包含了4种语料子集,本文选用正负各1000的平衡语料(ChnSentiCorp_htl_ba_2000)作为数据集进行分析。
3 数据预处理
3.1 正负向语料预处理
下载并解压ChnSentiCorp_htl_ba_2000.rar文件,得到的文件夹中包含neg(负向语料)和pos(正向语料)两个文件夹,而文件夹中的每一篇评论为一个txt文档,为了方便之后的操作,需要把正向和负向评论分别规整到对应的一个txt文件中,即正向语料的集合文档(命名为2000_pos.txt)和负向语料的集合文档(命名为2000_neg.txt)。
具体Python实现代码如下所示:
运行完成后得到2000_pos.txt和2000_neg.txt两个文本文件,分别存放正向评论和负向评论,每篇评论为一行。文档部分截图如下所示:
3.2 中文文本分词
本文采用结巴分词分别对正向语料和负向语料进行分词处理。特别注意,在执行代码前需要把txt源文件手动转化成UTF-8格式,否则会报中文编码的错误。在进行分词前,需要对文本进行去除数字、字母和特殊符号的处理,使用python自带的string和re模块可以实现,其中string模块用于处理字符串操作,re模块用于正则表达式处理。
具体实现代码如下所示:
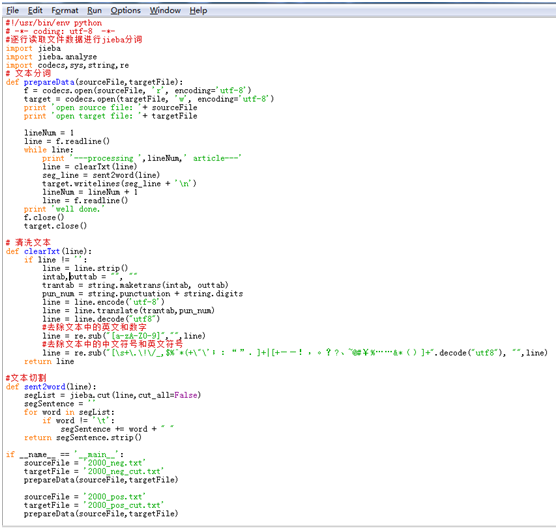
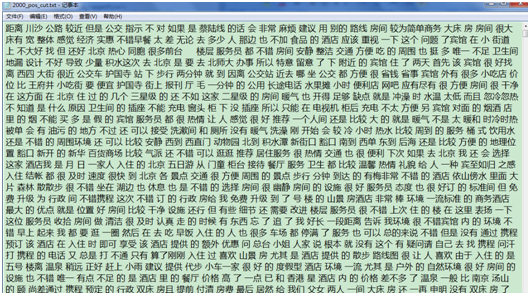
处理完成后,得到2000_pos_cut.txt和2000_neg_cut.txt两个txt文件,分别存放正负向语料分词后的结果。分词结果部分截图如下所示:
3.3 去停用词
分词完成后,即可读取停用词表中的停用词,对分词后的正负向语料进行匹配并去除停用词。去除停用词的步骤非常简单,主要有两个:
- 1)读取停用词表;
- 2)遍历分词后的句子,将每个词丢到此表中进行匹配,若停用词表存在则替换为空。
具体实现代码如下所示:
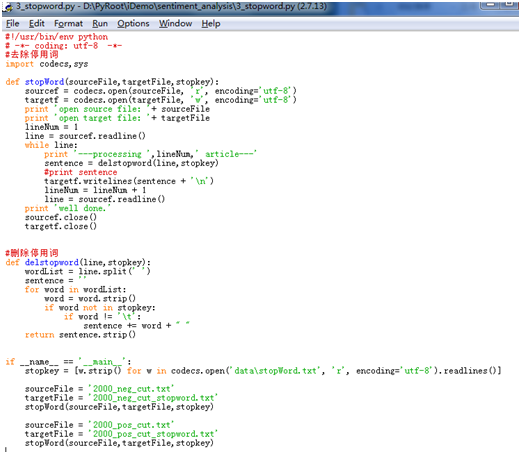
根据代码所示,停用词表的获取使用到了python特有的广播形式,一句代码即可搞定:
stopkey = [w.strip() for w in codecs.open('data\stopWord.txt', 'r', encoding='utf-8').readlines()]
读取出的每一个停用词必须要经过去符号处理即w.strip(),因为读取出的停用词还包含有换行符和制表符,如果不处理则匹配不上。代码执行完成后,得到2000_neg_cut_stopword.txt和2000_pos_cut_stopword.txt两个txt文件。
由于去停用词的步骤是在句子分词后执行的,因此通常与分词操作在同一个代码段中进行,即在句子分词操作完成后直接调用去停用词的函数,并得到去停用词后的结果,再写入结果文件中。本文是为了便于步骤的理解将两者分开为两个代码文件执行,各位可根据自己的需求进行调整。
3.4 获取特征词向量
根据以上步骤得到了正负向语料的特征词文本,而模型的输入必须是数值型数据,因此需要将每条由词语组合而成的语句转化为一个数值型向量。常见的转化算法有Bag of Words(BOW)、TF-IDF、Word2Vec。本文采用Word2Vec词向量模型将语料转换为词向量。
由于特征词向量的抽取是基于已经训练好的词向量模型,而wiki中文语料是公认的大型中文语料,本文拟从wiki中文语料生成的词向量中抽取本文语料的特征词向量。Wiki中文语料的Word2vec模型训练在之前写过的一篇文章“利用Python实现wiki中文语料的word2vec模型构建” 中做了详尽的描述,在此不赘述。即本文从文章最后得到的wiki.zh.text.vector中抽取特征词向量作为模型的输入。
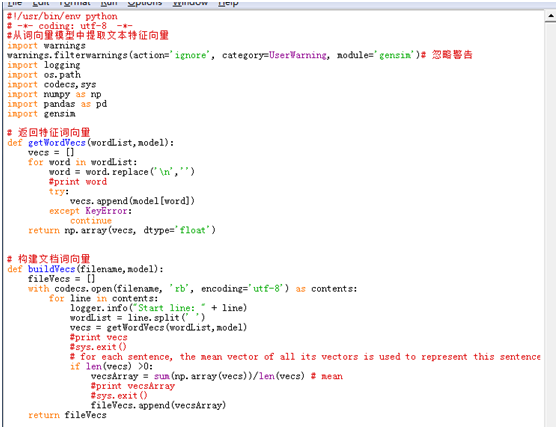
获取特征词向量的主要步骤如下:
- 1)读取模型词向量矩阵;
- 2)遍历语句中的每个词,从模型词向量矩阵中抽取当前词的数值向量,一条语句即可得到一个二维矩阵,行数为词的个数,列数为模型设定的维度;
- 3)根据得到的矩阵计算矩阵均值作为当前语句的特征词向量;
- 4)全部语句计算完成后,拼接语句类别代表的值,写入csv文件中。
主要代码如下图所示:
代码执行完成后,得到一个名为2000_data.csv的文件,第一列为类别对应的数值(1-pos, 0-neg),第二列开始为数值向量,每一行代表一条评论。结果的部分截图如下所示:

3.5 降维
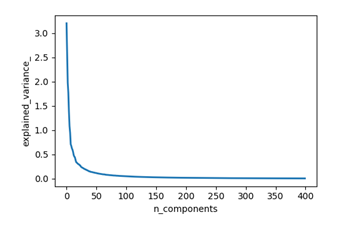
Word2vec模型设定了400的维度进行训练,得到的词向量为400维,本文采用PCA算法对结果进行降维。具体实现代码如下所示:

运行代码,根据结果图发现前100维就能够较好的包含原始数据的绝大部分内容,因此选定前100维作为模型的输入。
4 分类模型构建
本文采用支持向量机(SVM)作为本次实验的中文文本分类模型,其他分类模型采用相同的分析流程,在此不赘述。
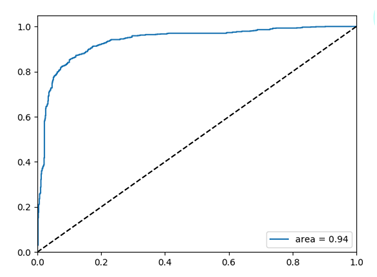
支持向量机(SVM)是一种有监督的机器学习模型。本文首先采用经典的机器学习算法SVM作为分类器算法,通过计算测试集的预测精度和ROC曲线来验证分类器的有效性,一般来说ROC曲线的面积(AUC)越大模型的表现越好。
首先使用SVM作为分类器算法,随后利用matplotlib和metric库来构建ROC曲线。具体python代码如下所示:
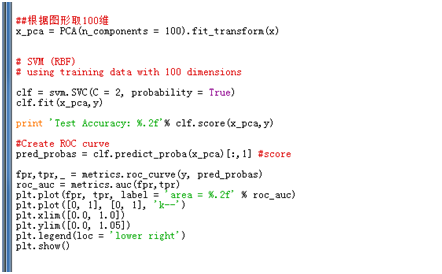
运行代码,得到Test Accuracy: 0.88,即本次实验测试集的预测准确率为88%,ROC曲线如下图所示。
完整代码下载地址:利用Python实现酒店评论的中文情感分析


![[UE笔记]延迟与延迟补偿](https://img-blog.csdnimg.cn/2420d56cf00f4ab8a6365f289187145a.png)