博主介绍:Java领域优质创作者,博客之星城市赛道TOP20、专注于前端流行技术框架、Java后端技术领域、项目实战运维以及GIS地理信息领域。
🍅文末获取源码下载地址🍅
👇🏻 精彩专栏推荐订阅👇🏻 欢迎点赞收藏评论拍砖........
【Docker Swarm总结】《容器技术 Docker+K8S专栏》✅
【uniapp+uinicloud多用户社区博客实战项目】《完整开发文档-从零到完整项目》✅
【Springcloud Alibaba微服务分布式架构 | Spring Cloud】《系列教程-更新完毕》✅
【SpringSecurity-从入门到精通】《学习完整笔记-附(完整demo源码)》✅
【从零开始Vue项目中使用MapboxGL开发三维地图教程】《系列教程-不定时更新》✅
【Vue.js学习详细课程系列】《共32节专栏收录内容》✅
感兴趣的可以先收藏起来相关问题都可以给我留言咨询,希望帮助更多的人。
目录
8、service 操作
8.1 task 伸缩
8.2 task 容错
8.3 服务删除
8.4 滚动更新
8.5 更新回滚
9、service 全局部署模式
9.1 环境变更
9.2 创建 service
9.3 task 伸缩
10、overlay 网络
10.1 测试环境 1搭建
10.2 overlay 网络概述
10.3 docker_gwbridg 网络基础信息
10.4 ingress 网络基础信息
10.5 宿主机的 NAT 过程
10.6 ingress_sbox 的负载均衡
10.7 VXLAN
11 Raft 算法
11.1 基础
11.2 角色、任期及角色转变
11.3 leader 选举
11.4 数据同步
11.5 脑裂
11.6 Leader 宕机处理
11.7 Raft 算法动画演示
8、service 操作
8.1 task 伸缩
根据访问量的变化,需要在不停止服务的前提下对服务的 task 进行扩容/缩容,即对服
务进行伸缩变化。有两种实现方式:
(1) docker service update 方式
通过 docker service update --replicas 命令可以实现对指定服务的 task 数量进行变更。
docker service lsdocker service update --replicas 4 tomcates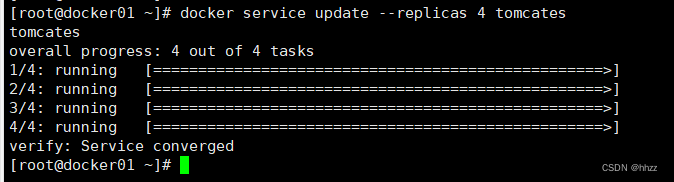
此时可以看到新增了一个 task 节点。
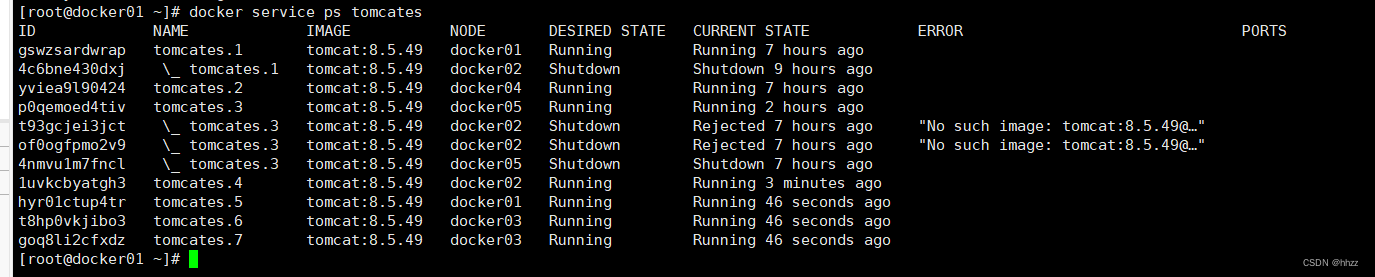
docker service ps tomcates

(2) docker service scale 方式
通过 docker service scale 命令可以为指定的服务变更 task 数量。
docker service scale tomcates=7此时可以看到新增了 3 个 task 节点。由于共有 5 台主机,现有 7 个 task,所以就出现了
一个主机上有多个 task 的情况。docker01上有两个tom服务分别为tom1和tom5.
当然,也可以使 task 数量减小。例如,下面的命令使 task 又变回了 3 个。
docker service scale tomcates=3这三个 task 分别在 docker01、docker04 与 docker05 主机。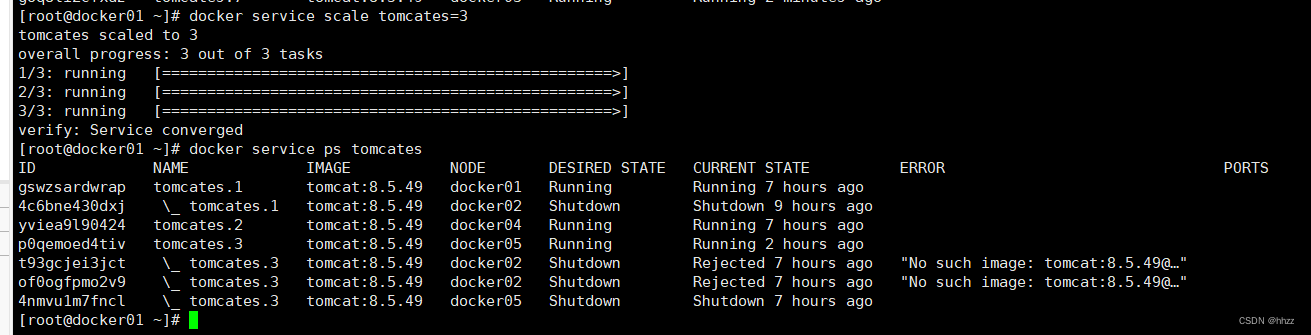
(3) 暂停节点的 task 分配
docker node update --help
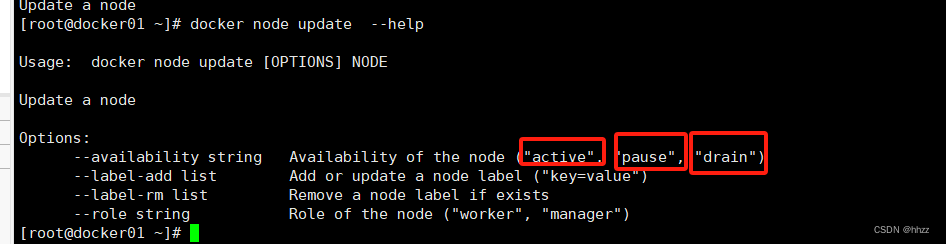
生产环境下,可能由于某主机性能不高,在进行 task 扩容时,不想再为该主机再分配更多的 task,此时可通过 pause 暂停该主机节点的可用性来达到此目的。
例如,当前 docker01、docker04 与 docker05三个主机上的tomcates 服务的 task 情况如下。

现准备将 tomcates 服务的 task 扩容为 10,但保持 docker02 节点中的 task 数量仍为 1 不变,
此时就可通过 docker node update --availability pause 命令修改 docker02 节点的可用性。
docker node update --availability pause docker02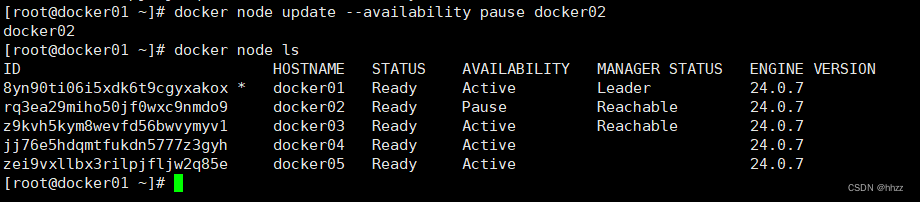
将 tomcates 服务的 task 扩容为 10。
docker service scale tomcates=10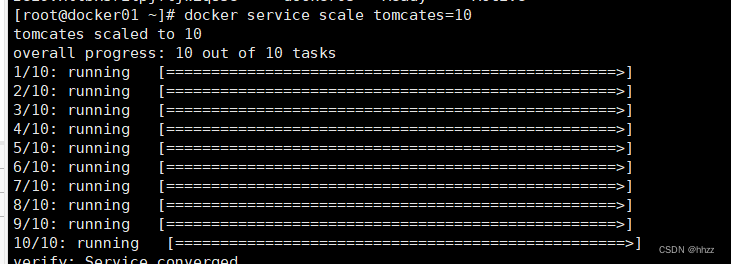
查看各节点分配的 task 情况会发现 docker02的 task 数量并未增加,其它节点主机有变化了。
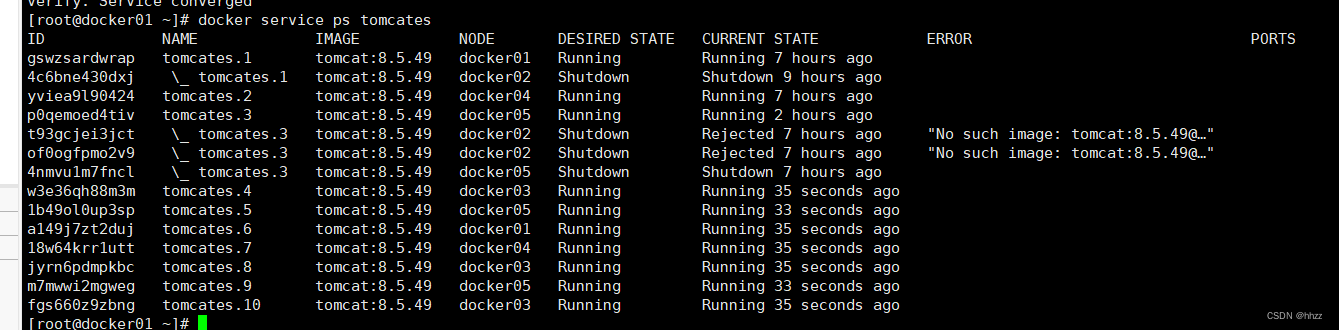
(4) 清空 task
默认情况下,manager 节点同时也具备 worker 节点的功能,可以由分发器为其分配 task。
但 manager 节点使用 raft 算法来达成 manager 间数据的一致性,对资源较敏感。因此,阻
止 manager 节点接收 task 是比较好的选择。或者,由于某节点出现了性能问题,需要停止服务进行维修,此时最好是将该节点上的task 清空,以不影响 service 的整体性能。
通过 docker node update –availability drain 命令可以清空指定节点中的所有 task。
例如,目前各个节点的对于 tomcates服务的 task 分配情况如下:
docker service ps tomcates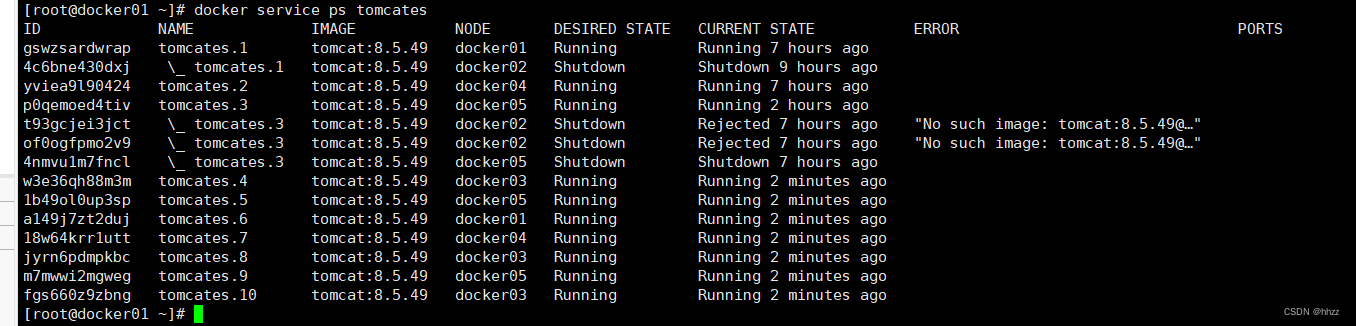
现对 docker02 与 docker05 两个节点进行 task 清空操作。
docker node update --availability drain docker02
docker node update --availability drain docker05
此时可以看到,tomcates服务的 task 总量并没有减少,只是 docker02 与 docker05 两个节点上
是没有 task 的,而全部都分配到了 docker01、docker03 与 docker04 三个节点上了。这个结果就是由编排器与分发器共同维护的。
8.2 task 容错
当某个 task 所在的主机或容器出现了问题时,manager 的编排器会自动再创建出新的
task,然后分发器会再选择出一台 available node 可用节点,并将该节点分配给新的 task。
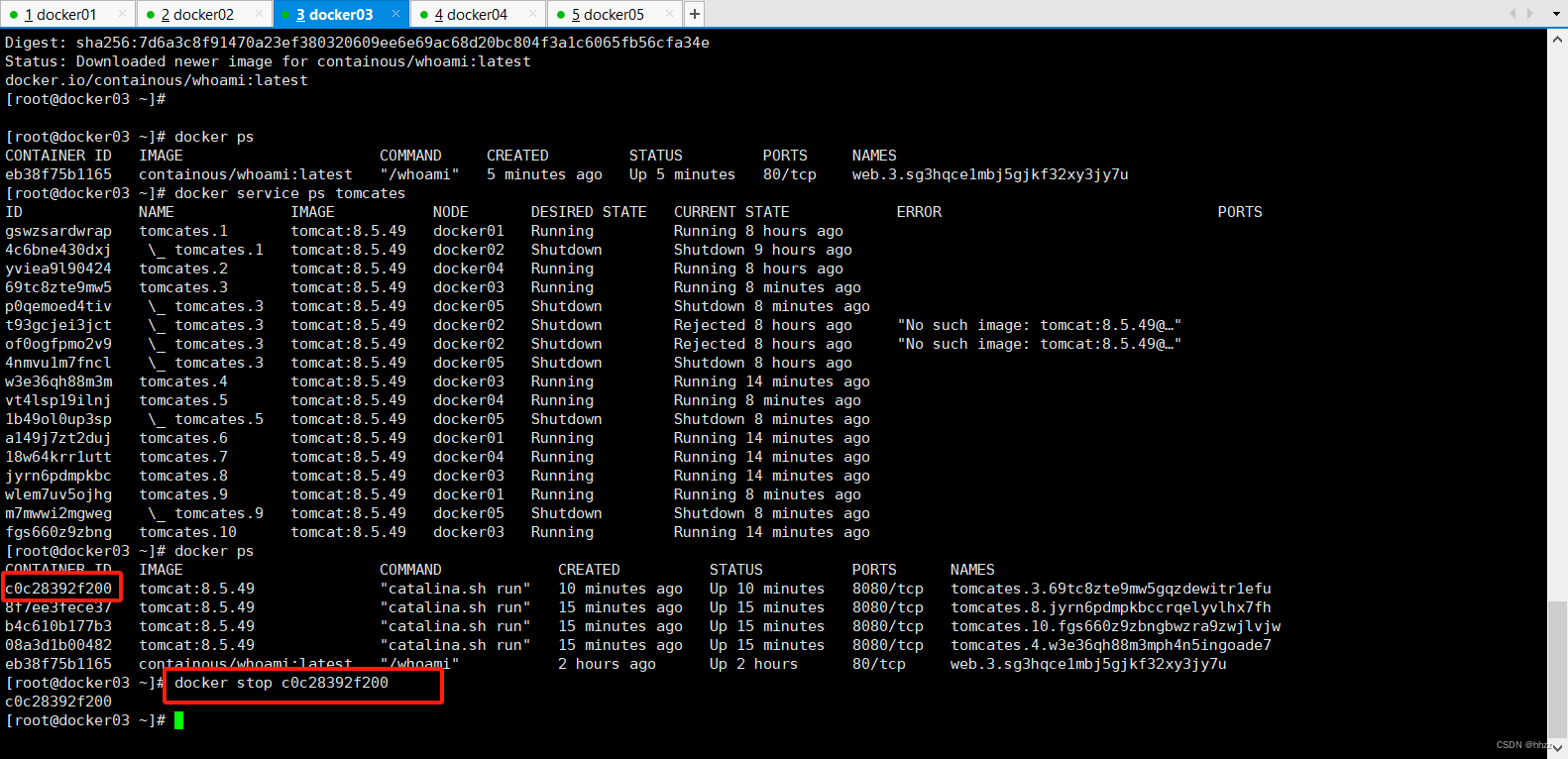
(1) 停掉容器
现在通过停掉 docker03、docker02或 docker05 中某个主机容器的方式来模拟故障情况。例
如停掉 docker03 的容器。
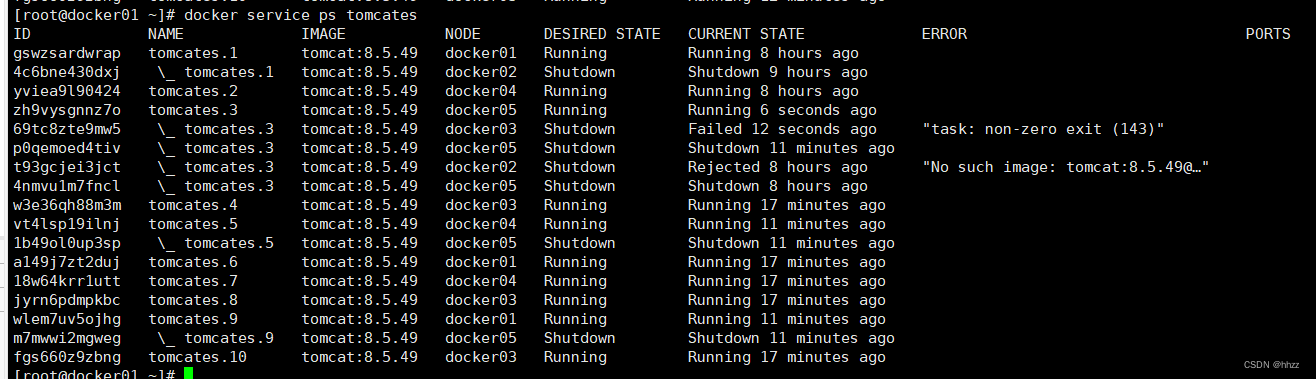
(2) 查看 task 节点
此时再查看服务的 task 节点信息可以看到 task分配到其他 主机。
8.3 服务删除
通过 docker service rm [service name|service ID]可以删除指定的一个或多个 service。
docker service rm tomcates删除后,该 service 消失,当然,该 service 的所有 task 也全部删除,task 相关的节点容器全部消失。

8.4 滚动更新
当一个 service 的 task 较多时,为了不影响对外提供的服务,在对 service 进行更新时可
采用滚动更新方式。
(1) 需求
这里要实现的更新时,将原本镜像为 tomcat:8.5.49 的 service 的镜像滚动更新为tomcat:8.5.39。
(2) 创建 service
创建一个包含 10 个副本 task 的服务,该服务使用的镜像为 tomcat:8.5.49。
docker service create \
--name toms \
--replicas 10 \
--update-parallelism 2 \
--update-delay 3s \
--update-max-failure-ratio 0.2 \
--update-failure-action rollback \
--rollback-parallelism 2 \
--rollback-delay 3s \
--rollback-max-failure-ratio 0.2 \
--rollback-failure-action continue \
-p 9000:8080 \
tomcat:8.5.39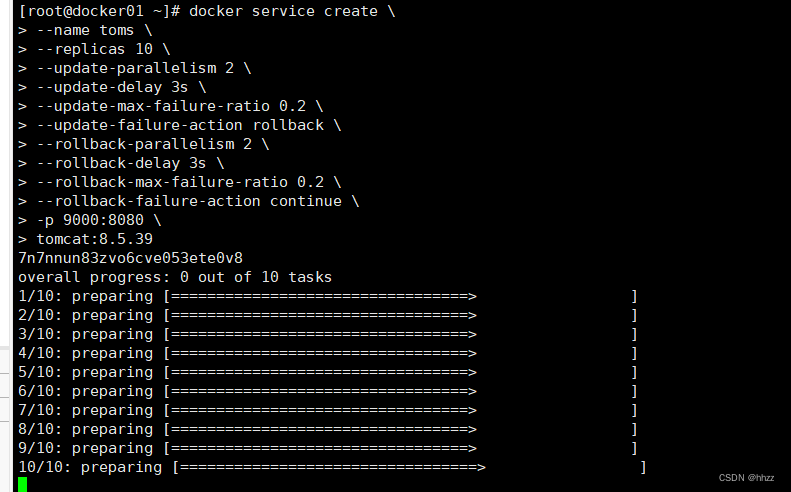
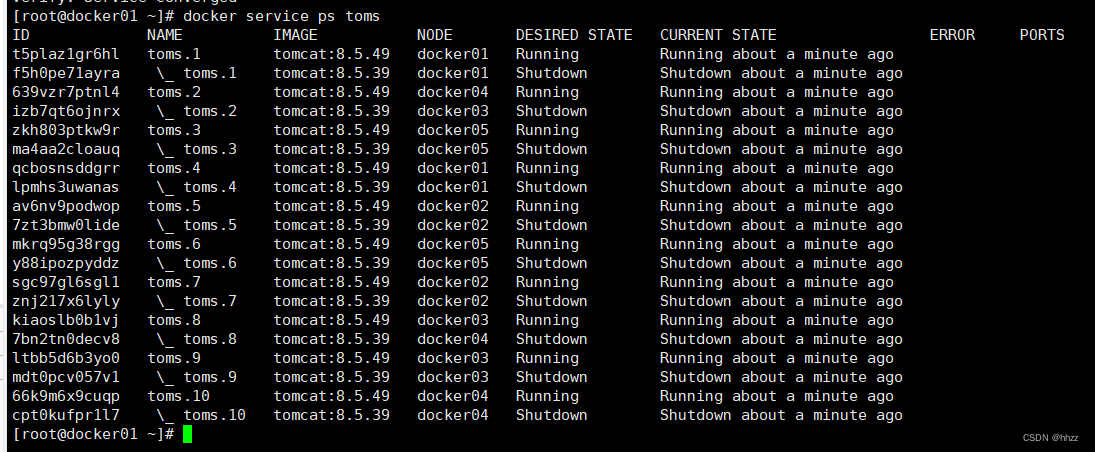
这 10 个 task 被非常平均的分配到了 5 个 swarm 节点上了。
docker service ps toms
(3) 更新 service
现要将 service 使用的镜像由 tomcat:8.5.39 更新为 tomcat:8.5.49。
docker service update --image tomcat:8.5.49 toms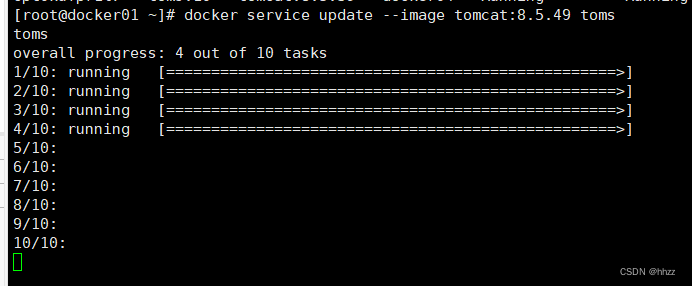
会发现这个更新的过程就是前面在创建服务时指定的那样,每次更新 2 个 task,更新间隔为 3 秒。更新完毕后再查看当前的 task 情况发现,已经将所有任务的镜像更新为了 8.5.49 版本。
8.5 更新回滚
在更新过程中如果更新失败,则会按照设置的回滚策略进行回滚,回滚到更新前的状态。
但用户也可通过命令方式手工回滚。
下面的命令会按照前面设置的每次回滚 2 个 task,每次回滚间隔 3 秒进行回滚。下面的
是回滚过程中的某个回滚瞬间。
docker service update --rollback toms

以下是回滚完毕后的结果。
回滚完毕后再查看当前的 task 情况发现,已经将所有任务的镜像恢复为了 8.5.39 版本。
但需要注意,task name 保持未变,但 task ID 与原来的 task ID 也是不同的,并不是恢复到了
更新之前的 task ID。即编排器新创建了 task,并由分发器重新为其分配了 node。
docker service ps toms
9、service 全局部署模式
根据 task 数量与节点数量的关系,常见的 service 部署模式有两种:replicated 模式与
global 模式。前面创建的 service 是 replicated 模式的,下面来创建 global 模式的 service。

9.1 环境变更
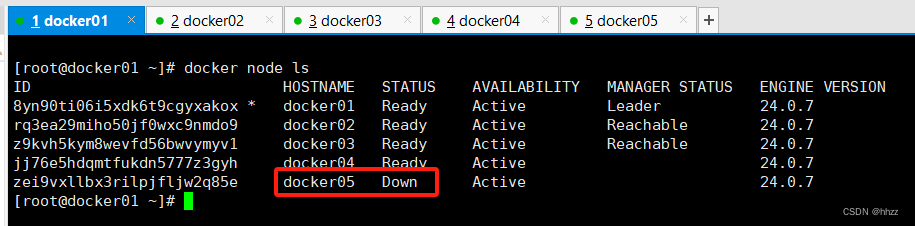
为了后面的演示效果,让 swarm 集群的节点变为 4 个。这里先使 docker5 退群。
docker swarm leave
此时 docker5 的节点状态变为了 Down。
docker node ls
将此节点再从 swarm 集群中删除。
docker node rm docker05
现在 docker5 节点才彻底被删除。

9.2 创建 service
在 docker service create 命令中通过--mode 选项可以指定要使用的 service 部署模式,默
认为 replicated 模式。
docker service create --name toms2 --mode global -p 9001:8080 tomcat:8.5.39

该模式会在每个节点上分配一个 task。
docker service ls
docker service ps toms2
9.3 task 伸缩
对于 global 模式来说,若要实现对 service 的 task 数量的变更,必须通过改变该 servicve所依附的 swarm 集群的节点数量来改变。节点增加,则 task 会自动增加;节点减少,则 task会自动减少。
下面要在这个 4 节点的 swarm 集群中增加一个节点,以使 toms 服务的 task 也增一。
首先在 manager 节点获取新增一个节点的 token。
docker swarm join-token worker

在 docker5 上运行加入命令,完成 swarm 的入群。
docker swarm join --token SWMTKN-1-4xrmirqfkb41hzrqjtqtehzjom484oi77dq8u1cqgrx9dqqw21-0y0n33l0vjxfxj4lai4r5hi80 192.168.162.201:2377此时查看 toms2 服务的 task 详情,发现已经自动增加了一个 task。
docker service ps toms2

10、overlay 网络
10.1 测试环境 1搭建
(1) 暂停分配 task

现让 docker2 主机暂停分配 task
docker node update --availability pause docker02
(2) 创建 service
现启动一个 service,包含 10 个 task。
docker service create --name toms --replicas 10 -p 9000:8080 tomcat:8.5.39
当前 swarm 集群共有 5 个节点,10 个 task 被分配到了 4 个可用节点上,其中除了被暂
停的 docker2 节点上是没有分配 task 外,其余节点都分配了多个 task。
docker service ps toms
此时,访问docker02主机http://192.168.162.202:9000/

居然能访问????问题解决请继续看下一节overlay网络。
10.2 overlay 网络概述
(1) overlay 网络简介
overlay 网络,也称为重叠网络或覆盖网络,是一种构建于 underlay 网络之上的逻辑虚拟网络。即在物理网络的基础上,通过节点间的单播隧道机制将主机两两相连形成的一种虚拟的、独立的网络。
Docker Swarm 集群中的 overlay 网络主要是通过 iptables、ipvs、vxlan 等技术实现的、基于其本身通信需求的网络模型。
(2) overlay 网络模型
这里要说的 overlay 网络模型,确切地说,是 Docker Swarm 集群的 overlay 网络模型。
Docker Swarm 集群的 overlay 网络模型在创建时,会创建出两个网络:docker_gwbidge
网络与 ingress 网络。这就是典型的 overlay 网络——在宿主机的物理网络之上又创建出新的
网络。同时还创建出了 docker_gwbidge 网关与 br0 网关,及 ingress-sbox 容器。
当请求到达后会首先经由 docker_gwbidge 网关跳转到 ingress-sbox 容器,在其中具有当
前整个service的所有容器IP,在其中通过轮询负载均衡方式选择一个容器IP作为目标地址,
然后再跳转到 br0 网关。在 br0 网关中会根据目标地址所在主机进行判断。若目标地址为本
地容器 IP,则直接将请求转发给该容器处理即可。若目标地址非本地容器 IP,则会将请求经
由 vxlan 接口,通过 vxlan 隧道技术将请求转发给目标地址容器。
10.3 docker_gwbridg 网络基础信息
在详细分析 overlay 网络模型的通信原理之前,首先来了解一下 docker swarm 的 overlay
网络的基础信息。
(1) 查看 docker_gwbridge 网络详情
docker swarm 集群的 overlay 网络模型在创建时,会自动创建两个网络:docker_gwbridge
网络与 ingress 网络。

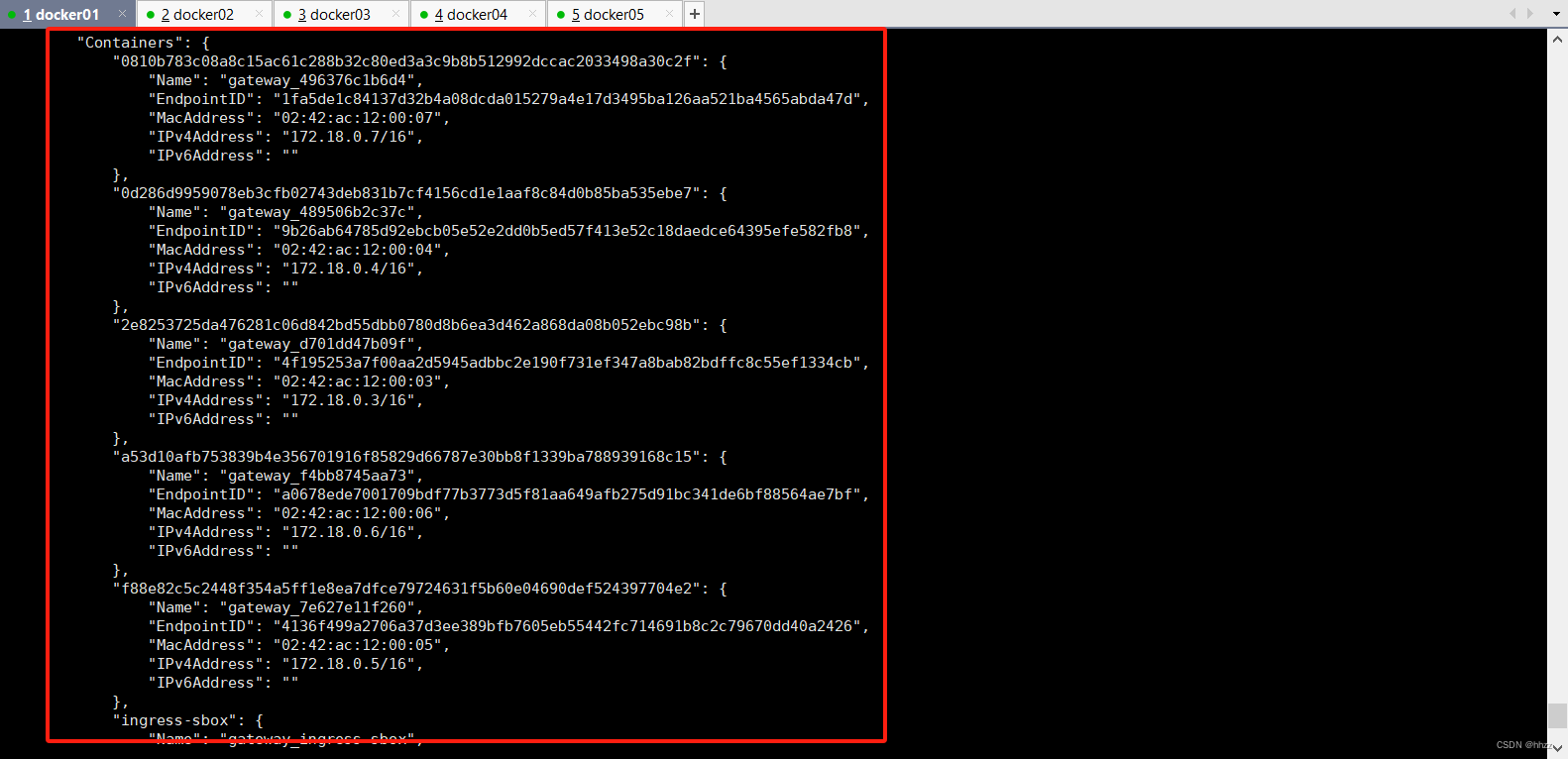
查看 docker_gwbridge 网络详情可以看到,docker_gwbridge 网络包含的子网为
172.18.0.0/16,其网关为 172.18.0.1。那么,这个网关是谁呢?

同时还看到,该网络中包含了 6 个容器。其中 5 个为 service 的 task 容器,另一个的容
器 ID 为 ingress-sbox。
(2) ingress-sbox 容器

通过 docker ps –a 命令查看当前主机中的所有容器,发现并没有 ingress-sbox 容器。为
什么?因为 docker ps 命令的本质是 docker process status,查看的是当前主机中真实存在的
容器进程的状态。而 ingress-sbox 容器是由 overlay 网络虚拟出的,并不是真实存在的进程,
所以通过 docker ps 命令是查看不到的。
从 docker_gwbridge 的网络详情中可以看到,其中 2 个为 service 的 task 容器,其 ID 由
64 位 16 进制数构成,而 ingress-sbox 容器的 ID 就是 ingress-sbox,与其它 2 个容器的 ID 构
成方式完全不同。
(3) docker_gwbridge 网关
docker_gwbridge 的网络详情中的网关 172.18.0.1 是谁呢?
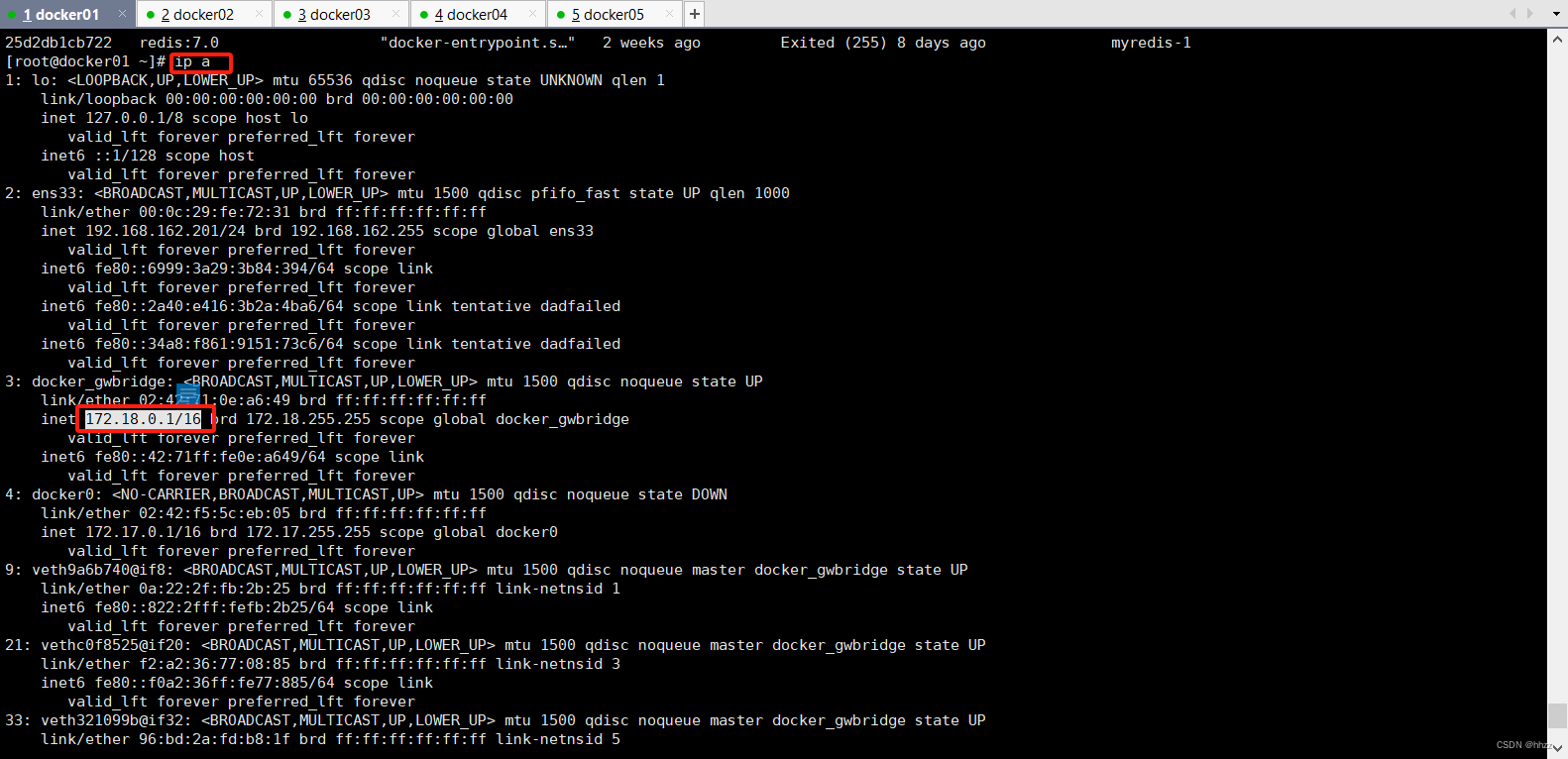
在宿主机中通过 ip a 命令查看宿主机的网络接口,可以看到 docker_gwbridge 接口的 IP
为 172.18.0.1。即 docker_gwbridge 网络中具有一个与网络名称同名的网关。同时还看到,下
面的 3 个接口全部都是连接在 docker_gwbridge 上的。
(4) 查看 task 容器的接口
查看 docker_gwbridge 网络的 task 容器的接口情况,可以看到这些容器中正好有接口与
docker_gwbridge 网关中的相应接口构成 veth paire。

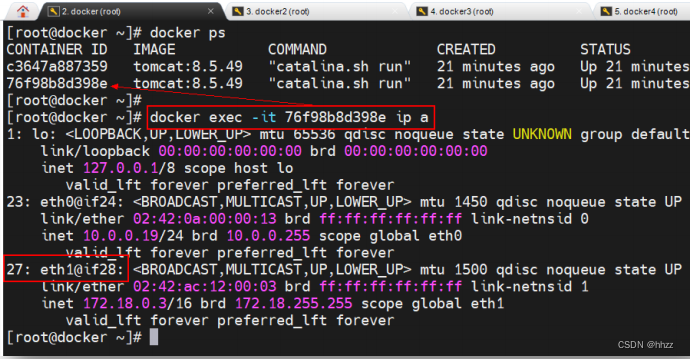
(5) 查看 ingress-sbox 容器的接口
如何查看docker_gwbridge网络的ingress-sbox容器的接口情况呢?每个容器都具有一个
独立的网络命名空间,而每个 docker 主机中的网络命名空间,都是以文件的形式保存在目
录/var/run/docker/netns 中。

其中 ingress_sbox 就是容器 ingress-sbox 的网络命名空间。通过 nsenter 命令可进入该命
名空间并查看其接口情况。可以看到该命名空间中正好也存在接口与 docker_gwbridge 网关
中的相应接口构成 veth paire。

10.4 ingress 网络基础信息
(1) 查看 ingress 网络详情
overlay 网络除了创建了 docker_gwbridge 网络外,还创建了一个 ingress 网络。
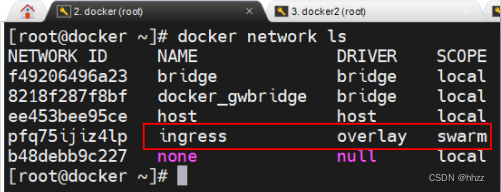
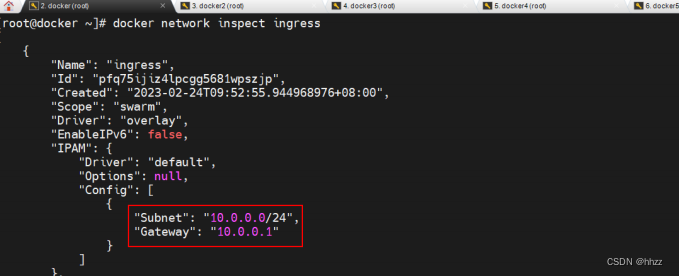
查看 ingress 网络详情可以看到,ingress 网络包含的子网为 10.0.0.0/24,其网关为 10.0.0.1。
那么,这个网关是谁呢?
同时还看到,该网络中也包含了 3 个容器,这 3 个容器与 docker_gwbridge 网络中的 3
个容器是相同的容器,虽然 Name 不同,IP 不同,但容器 ID 相同。说明这 3 个容器都同时
连接在 2 个网络中。
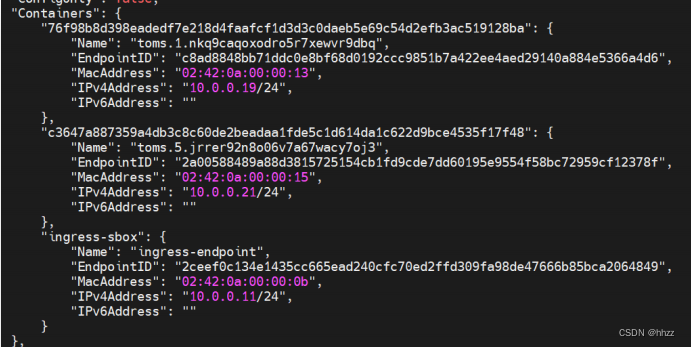
(2) br0 网关
10.0.0.1 网关是谁呢?
每个容器都具有一个独立的网络空间,而每个 docker 主机中的网络命名空间,都是以
文件的形式保存在/var/run/docker/netns 目录中。查看当前主机的网络空间:
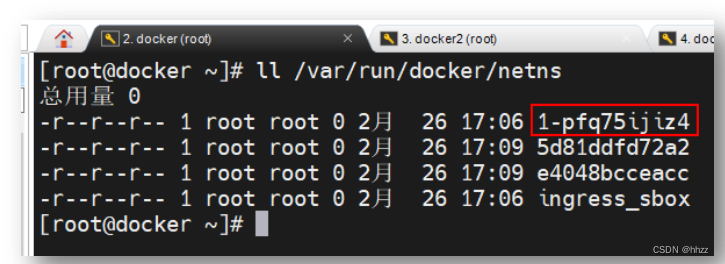
查看/var/run/docker/netns 目录中的命名空间发现,其包含的 4 个命名空间中,有 2 个
命名空间是 2 个 task 容器的,它们的名称由 12 位长度的 16 进制数构成;ingress_sbox 是
ingress-sbox 容器的命名空间。那么,1-pfq75ijiz4 命名空间是谁呢?进入该命名空间,查看
其接口信息。
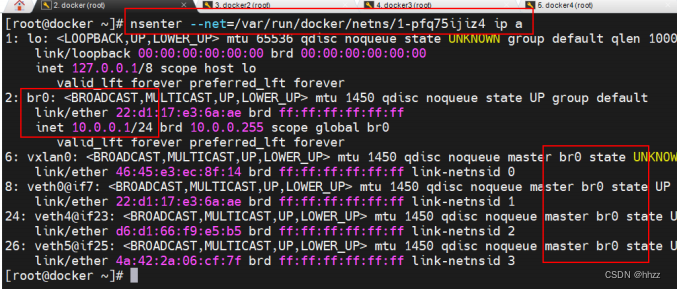
可以看到 2 号接口 br0 的 IP 为 10.0.0.1,即 ingress 网络的网关为 1-pfq75ijiz4 命名空间
中的 br0。同时还看到,br0 上还连接着 4 个接口,说明 br0 就是一个网关。那么,都是谁
连接在这 4 个接口上呢?
(3) 查看 task 容器的接口
查看 ingress 网络的 task 容器的接口情况,可以看到这些容器中正好有接口与 br0 网关
中的相应接口构成 veth paire。

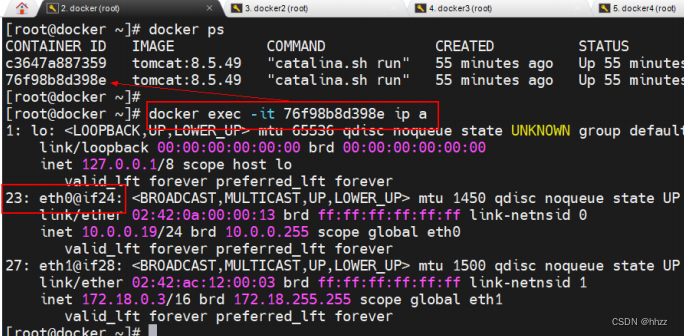
(4) 查看 ingress-sbox 容器的接口
查看 ingress-sbox 容器的命名空间 ingress_sbox 的接口情况,可以看到该命名空间中正
好也存在接口与 br0 网关中的相应接口构成 veth paire。

10.5 宿主机的 NAT 过程
(1) 查看宿主机路由
用户提交的192.168.192.101:9000请求会首先被192.168.192.101主机的哪个接口接收并
处理呢?通过命令 ip route 可以查看当前网络命名空间中的静态路由信息。

可以看出,所有对 192.168.182.0/24 网络的请求,都需要经过 ens33 接口,而该接口连
接的 IP 为 192.168.192.101。即 ens33 接口会处理该请求。当然,查看该主机的接口情况也
可以看到,ens33 接口地址为 192.168.192.101。
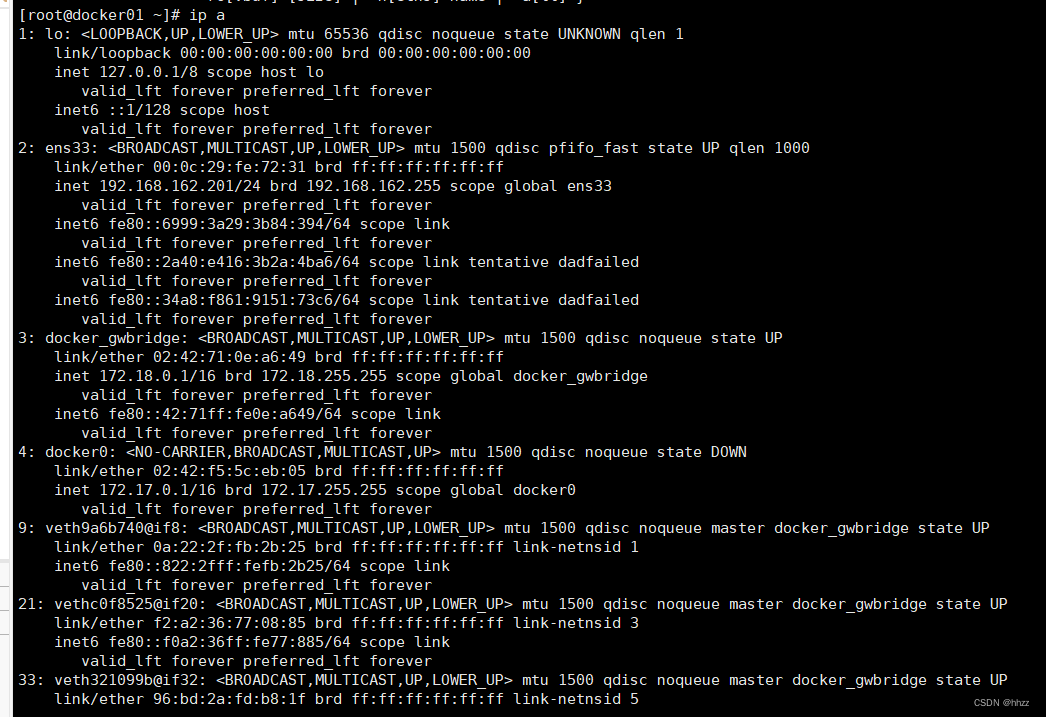
那么 ens33 接口又会将请求转发到哪里呢?这就需要查看宿主机的路由转发表 nat 中的
路由规则了。
(2) 查看 ip 转换规则
首先通过 iptables –nvL –t nat 命令来查看宿主机中网络地址转发表 nat 中的转发规则。
nat 表的主要功能是根据规则进行地址映射、端口映射,以完成地址转换。
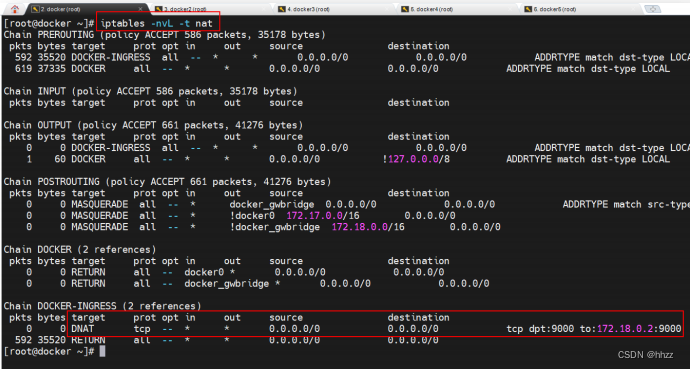
DOCKER-INGRESS 路由链路中的 DNAT 映射规则中指出,对于任何源 IP,只要其访问端
口号为 9000,就会将其转换为 172.18.0.2:9000 的请求,即将请求转发到 172.18.0.2。那么请
求是如何到达 172.18.0.2 的呢?
(3) 查看宿主机路由
通过 ip route 命令查看当前宿主机的静态路由信息。

可以看出,所有对 172.18.0.0/16 网络的请求,都需要经过 docker_gwbridge 接口,而该
接口连接的 IP 为 172.18.0.1。即 docker_gwbridge 接口会处理该请求。由一个网络去访问另
一个网络必须要经过该目标网络的网关。经前面的学习知道,docker_gwbridge 正好就是
172.18.0.0/16 网络的网关。
也就是说,客户端提交的 192.168.192.101:9000 的请求,经 docker_gwbridge 网关,被
路由到了 IP 为 172.18.0.2 的接口。那么谁的 IP 是 172.18.0.2 呢?经过前面网络基础信息查
看可知,docker_gwbridge 网络中包含 IP 为 172.18.0.2 的 ingress-sbox 容器。
10.6 ingress_sbox 的负载均衡
客户端请求经宿主机的 NAT 已经成功通过 docker_gwbridge 网关转发到了 172.18.0.2,
即转发到了 ingress-sbox 容器,或者更确切地说,是转发到了 ingress_sbox 命名空间。那么,
ingress_sbox 命名空间又会将请求转发到哪里呢?这就需要查看 ingress_sbox 命名空间的
iptables 的 mangle 表与 IPVS 功能了。
(1) 查看 ingress_sbox 的 mangle 表
mangle 表的主要功能是根据规则修改数据包的一些标志位,以便其他规则或程序可以
利用这种标志对数据包进行过滤或路由。
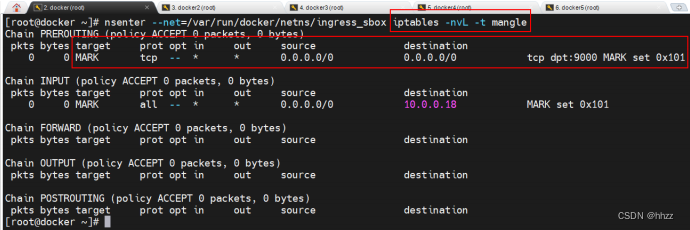
该路由链中为任意源地址端口为 9000 的请求打了一个 MARK 标记 0x101,该 MARK 标
记将被 IPVS 用于负载均衡。
(2) 安装 ipvsadm 命令
后面我们需要使用该命令查看 IPVS 实现的负载均衡规则,但由于 CentOS 系统中默认没
有安装 ipvsadm 命令,所以需要先 yum 安装。
(3) 查看 ingress_sbox 负载均衡规则

端口为 9000 的请求被打上了一个数值为 257 的 MARK 标记,该标记通过 LVS 的 IPVS 的
负载均衡,将该请求转发到了下面的 10 个 IP 接口,且这 10 个接口的权重 weight 是相同的,
都是 1。这 10 个 IP 接口具有一个共同点,全部来自于 10.0.0.0/24 网络。那么,如何能到达
10.0.0.0/24 网络呢?
(4) 查看命名空间路由
通过前面的学习可知,若要由一个网络转发到另一个网络,则必须要先到目标网络的网
关。由于目前尚在 172.18.0.0/16 网络,预转发到 10.0.0.0/24 网络,所以必须要先到 10.0.0.0/24
网络的网关 10.0.0.1,即 br0。通过查看 br0 所在命名空间 1-pfq75ijiz4 的静态路由也可看出:

但存在的问题是,请求目前尚在 ingress_sbox 命名空间中,怎样才能从 ingress_sbox 命
名空间中出去,然后跳转到 br0 呢?查看 ingress_sbox 命名空间中的静态 IP 路由:

可以看出,所有对 10.0.0.0/24 网络的请求,都需要经过 eth0 接口,而该接口连接的 IP
为 10.0.0.11。在 ingress_sbox 命名空间中 eth0 接口就是 7 号接口,其 veth pair 接口就是 br0
中的 8 号接口。所以,ingress_sbox 命名空间中请求经由 7 号接口跳转到了 br0 网关。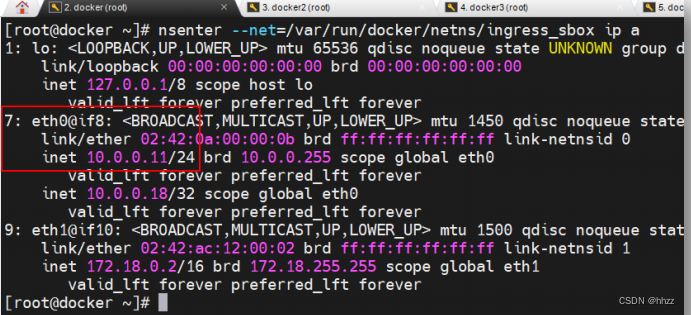
(5) br0 网关的处理
到达 br0 后,再将请求从 br0 的哪个接口转发出去,是由目标地址决定的,而目标地址
就是 IPVS 负载均衡选择出的 IP。请求到达 br0 后,首先会将目标地址与本地的 task 容器地
址进行比较,若恰好就是当前宿主机中的 task 容器的 IP,那么直接将请求通过相应的接口
将其转发;若不是当前宿主机中的 IP,则会将请求转发到 vxlan0 接口。经过 vxlan0 接口,
可经由 VXLAN 技术将请求通过“网络隧道”发送到目标地址。
10.7 VXLAN
(1) VXLAN 简介
VXLAN 是一种隧道技术,可以将不同协议的数据包重新封装后发送。新的包头提供了路由信息,从而使被封装的数据包在隧道的两个端点间通过公共互联网络进行路由。被封装的
数据包在公共互联网络上传递时所经过的逻辑路径称为隧道。一旦到达网络终点,数据将被
解包并转发到最终目的地。
(2) 测试环境 2 搭建
为了能够看清楚请求在不同主机的容器间所进行了通信,及通信过程中所使用的 VXLAN
技术,这里将原来的服务先删除,然后再创建一个新的服务。不过,该服务仅有一个副本。
首先删除原来的 service。
然后在任意主机中创建一个新的 servivce,其仅包含一个副本。这里在 docker3 主机创
建了服务。可以看到,这唯一的副本被分配到了 docker5 主机。

(3) 安装 tcpdump 命令
这里准备使用 tcpdump 命令对 VXLAN 数据进行监听,但在 centOS7 系统中默认是没有
安装 tcpdump 命令的,所以需要使用 yum 命令先在 docker5 主机安装。
yum install -y tcpdump
(4) docker5 先监听
无论对哪个主机的该服务进行访问,请求最终都会通过 docker5 主机的 ens33 接口进入,
然后再找到该 task 容器。所以这里要先监听 docker5 的 ens33 接口。

(5) docker3 访问
在浏览器可以对任意主机提交访问请求。这里是向 docker3 主机发出的访问请求。

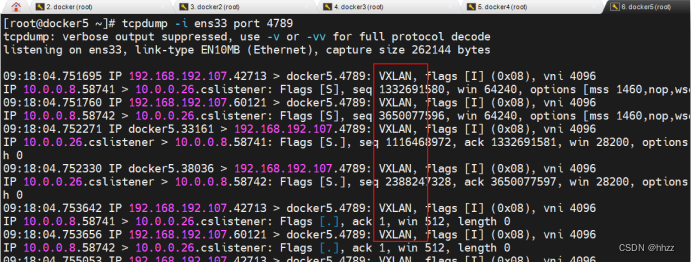
(6) docker5 查看抓包数据
当向 docker3 主机发送了访问请求后,docker5 上就会看到抓取的 VXLAN 数据包。
11 Raft 算法
11.1 基础
Raft 算法是一种通过对日志复制管理来达到集群节点一致性的算法。这个日志复制管理
发生在集群节点中的 Leader 与 Followers 之间。Raft 通过选举出的 Leader 节点负责管理日志
复制过程,以实现各个节点间数据的一致性。
11.2 角色、任期及角色转变
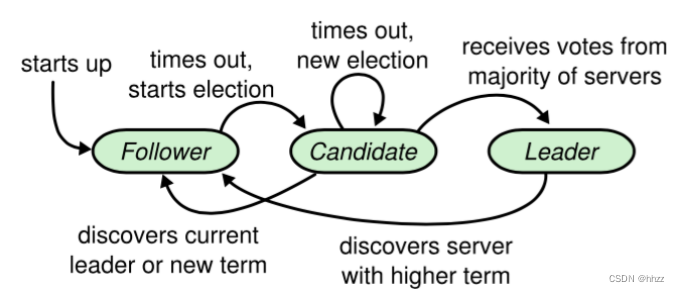
在 Raft 中,节点有三种角色:
- Leader:唯一负责处理客户端写请求的节点;也可以处理客户端读请求;同时负责日志复制工作
- Candidate:Leader 选举的候选人,其可能会成为 Leader。是一个选举中的过程角
- Follower:可以处理客户端读请求;负责同步来自于 Leader 的日志;当接收到其它Cadidate 的投票请求后可以进行投票;当发现 Leader 挂了,其会转变为 Candidate 发起Leader 选举
11.3 leader 选举
通过 Raft 算法首先要实现集群中 Leader 的选举。
(1) 我要选举
若 follower 在心跳超时范围内没有接收到来自于 leader 的心跳,则认为 leader 挂了。此
时其首先会使其本地 term 增一。然后 follower 会完成以下步骤:
- 此时若接收到了其它 candidate 的投票请求,则会将选票投给这个 candidate
- 由 follower 转变为 candidate
- 若之前尚未投票,则向自己投一票
- 向其它节点发出投票请求,然后等待响应
(2) 我要投票
follower 在接收到投票请求后,其会根据以下情况来判断是否投票:
- 发来投票请求的 candidate 的 term 不能小于我的 term
- 在我当前 term 内,我的选票还没有投出去
- 若接收到多个 candidate 的请求,我将采取 first-come-first-served 方式投票
(3) 等待响应
当一个 Candidate 发出投票请求后会等待其它节点的响应结果。这个响应结果可能有三
种情况:
- 收到过半选票,成为新的 leader。然后会将消息广播给所有其它节点,以告诉大家我是新的 Leader 了
- 接收到别的 candidate 发来的新 leader 通知,比较了新 leader 的 term 并不比自己的 term小,则自己转变为 follower
- 经过一段时间后,没有收到过半选票,也没有收到新 leader 通知,则重新发出选举
(4) 选举时机
在很多时候,当 Leader 真的挂了,Follower 几乎同时会感知到,所以它们几乎同时会变为 candidate 发起新的选举。此时就可能会出现较多 candidate 票数相同的情况,即无法选举出 Leader。
为了防止这种情况的发生,Raft 算法其采用了 randomized election timeouts 策略来解决这个问题。其会为这些 Follower 随机分配一个选举发起时间 election timeout,这个 timeout在 150-300ms 范围内。只有到达了 election timeout 时间的 Follower 才能转变为 candidate,否则等待。那么 election timeout 较小的 Follower 则会转变为 candidate 然后先发起选举,一般情况下其会优先获取到过半选票成为新的 leader。
11.4 数据同步
在 Leader 选举出来的情况下,通过日志复制管理实现集群中各节点数据的同步。
(1) 状态机
Raft 算法一致性的实现,是基于日志复制状态机的。状态机的最大特征是,不同 Server
中的状态机若当前状态相同,然后接受了相同的输入,则一定会得到相同的输出。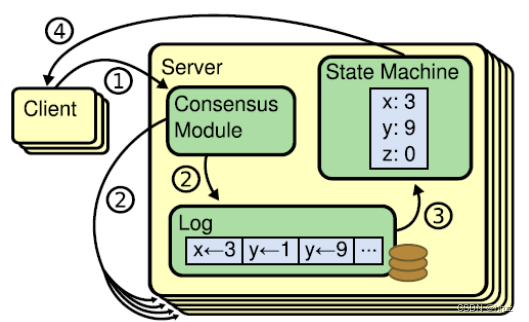
(2) 处理流程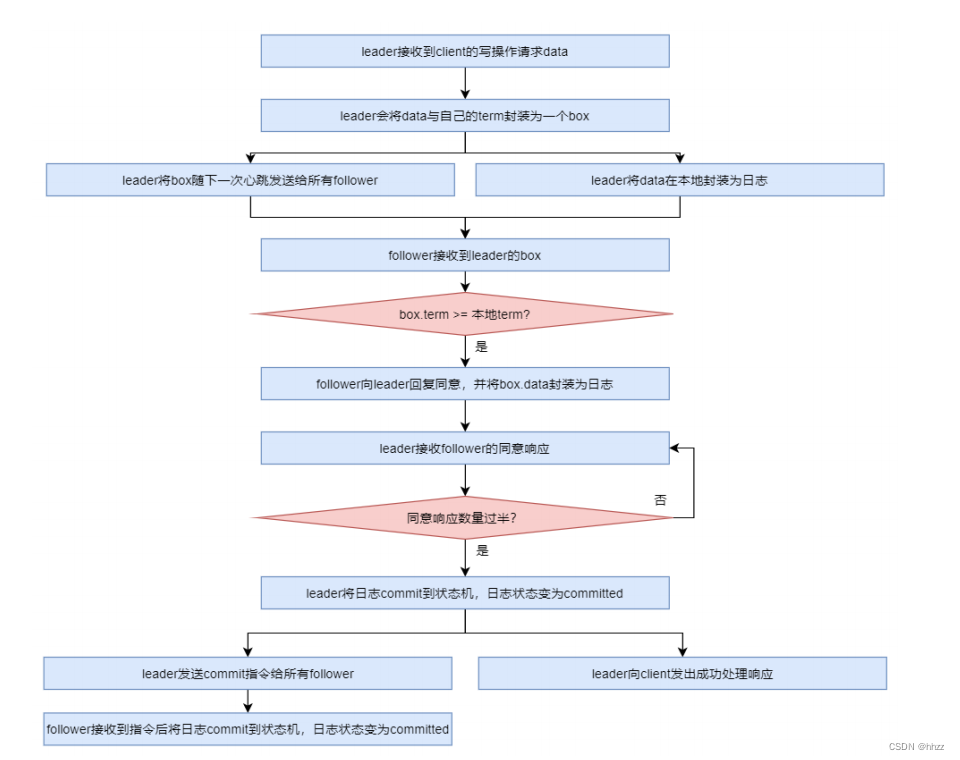
当 leader 接收到 client 的写操作请求后,大体会经历以下流程:
- leader 在接收到 client 的写操作请求后,leader 会将数据与 term 封装为一个 box,并随
着下一次心跳发送给所有 followers,以征求大家对该 box 的意见。同时在本地将数据封
装为日志
- follower 在接收到来自 leader 的 box 后首先会比较该 box 的 term 与本地记录的曾接受过
的 box 的最大 term,只要不比自己的小就接受该 box,并向 leader 回复同意。同时会将
该 box 中的数据封装为日志。
- 当 leader 接收到过半同意响应后,会将日志 commit 到自己的状态机,状态机会输出一
个结果,同时日志状态变为了 committed
- 同时 leader 还会通知所有 follower 将日志 commit 到它们本地的状态机,日志状态变为
了 committed
- 在 commit 通知发出的同时,leader 也会向 client 发出成功处理的响应。
(3) AP 支持
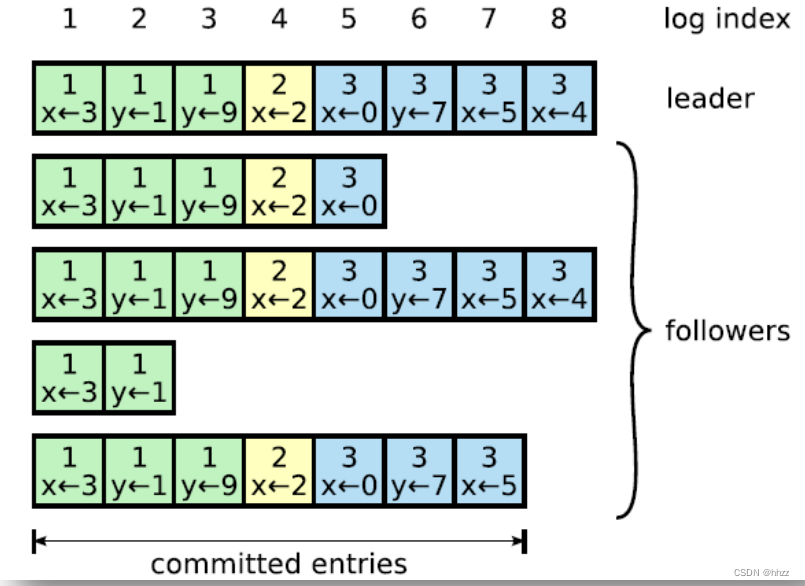
Log 由 term index、log index 及 command 构成。为了保证可用性,各个节点中的日志可
以不完全相同,但 leader 会不断给 follower 发送 box,以使各个节点的 log 最终达到相同。
即 raft 算法不是强一致性的,而是最终一致的。
11.5 脑裂
Raft 集群存在脑裂问题。在多机房部署中,由于网络连接问题,很容易形成多个分区。
而多分区的形成,很容易产生脑裂,从而导致数据不一致。
由于三机房部署的容灾能力最强,所以生产环境下,三机房部署是最为常见的。下面以
三机房部署为例进行分析,根据机房断网情况,可以分为五种情况:
(1) 情况一--不确定
这种情况下,B 机房中的主机是感知不到 Leader 的存在的,所以 B 机房中的主机会发
起新一轮的 Leader 选举。由于 B 机房与 C 机房是相连的,虽然 C 机房中的 Follower 能够感
知到 A 机房中的 Leader,但由于其接收到了更大 term 的投票请求,所以 C 机房的 Follower
也就放弃了 A 机房中的 Leader,参与了新 Leader 的选举。
若新 Leader 出现在 B 机房,A 机房是感知不到新 Leader 的诞生的,其不会自动下课,
所以会形成脑裂。但由于 A 机房 Leader 处理的写操作请求无法获取到过半响应,所以无法
完成写操作。但 B 机房 Leader 的写操作处理是可以获取到过半响应的,所以可以完成写操
作。故,A 机房与 B、C 机房中出现脑裂,且形成了数据的不一致。
若新 Leader 出现在 C 机房,A 机房中的 Leader 则会自动下课,所以不会形成脑裂。
(2) 情况二--形成脑裂
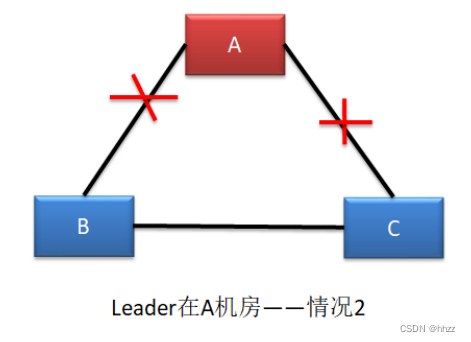
这种情况与情况一基本是一样的。不同的是,一定会形成脑裂,无论新 Leader 在 B 还
是 C 机房。
(3) 情况三--无脑裂
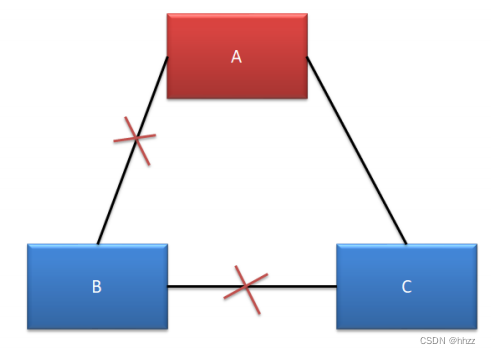
A、C 可以正常对外提供服务,但 B 无法选举出新的 Leader。由于 B 中的主机全部变为
了选举状态,所以无法提供任何服务,没有形成脑裂。
(4) 情况四--无脑裂
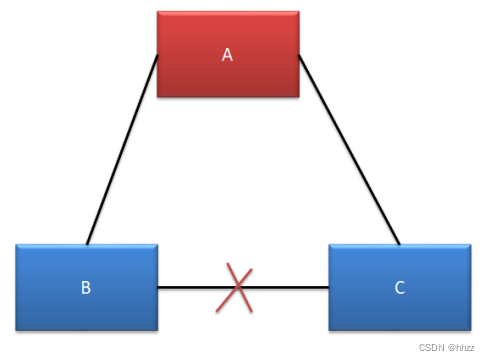
A、B、C 均可以对外提供服务,不受影响。
(5) 情况五--无脑裂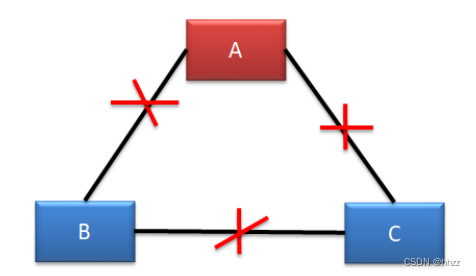
A 机房无法处理写操作请求,但可以对外提供读服务。
B、C 机房由于失去了 Leader,均会发起选举,但由于均无法获取过半支持,所以均无
法选举出新的 Leader。
11.6 Leader 宕机处理
(1) 请求到达前 Leader 挂了
client 发送写操作请求到达 Leader 之前 Leader 就挂了,因为请求还没有到达集群,所以
这个请求对于集群来说就没有存在过,对集群数据的一致性没有任何影响。Leader 挂了之
后,会选举产生新的 Leader。
由于 Stale Leader 并未向 client 发送成功处理响应,所以 client 会重新发送该写操作请求。
(2) 未开始同步数据前 Leader 挂了
client 发送写操作请求给 Leader,请求到达 Leader 后,Leader 还没有开始向 Followers
发出数据 Leader 就挂了。这时集群会选举产生新的 Leader。Stale Leader 重启后会作为
Follower 重新加入集群,并同步新 Leader 中的数据以保证数据一致性。之前接收到 client 的
数据被丢弃。
由于 Stale Leader 并未向 client 发送成功处理响应,所以 client 会重新发送该写操作请求。
(3) 同步完部分后 Leader 挂了
client 发送写操作请求给 Leader,Leader 接收完数据后向所有 Follower 发送数据。在部
分 Follower 接收到数据后 Leader 挂了。由于 Leader 挂了,就会发起新的 Leader 选举。
- 若 Leader 产生于已完成数据接收的 Follower,其会继续将前面接收到的写操作请求转换为日志,并写入到本地状态机,并向所有 Flollower 发出询问。在获取过半同意响应后会向所有 Followers 发送 commit 指令,同时向 client 进行响应。
- 若 Leader 产生于尚未完成数据接收的 Follower,那么原来已完成接收的 Follower 则会放
弃曾接收到的数据。由于 client 没有接收到响应,所以 client 会重新发送该写操作请求。
(4) commit 通知发出后 Leader 挂了
client 发送写操作请求给 Leader,Leader 也成功向所有 Followers 发出的 commit 指令,
并向 client 发出响应后,Leader 挂了。
由于 Stale Leader 已经向 client 发送成功接收响应,且 commit 通知已经发出,说明这个
写操作请求已经被 server 成功处理。
11.7 Raft 算法动画演示
在网络上有一个关于 Raft 算法的动画,其非常清晰全面地演示了 Raft 算法的工作原理。
该动画的地址为:http://thesecretlivesofdata.com/raft/



![[C++ 从入门到精通] 13.派生类、调用顺序、继承方式、函数遮蔽](https://img-blog.csdnimg.cn/b9c22863298044478ebbb0d6c076545d.png)