智能客服机器人的业务指标,最常见的就是解决率,解决率的高低直接关系到客户采购机器人的价值。解决率很高,客户可以省下很多成本开销,如果解决率很低,那么就没有必要采购这个客服机器人。所以,智能客服机器人解决率的高低,直接关系到客户的采购、新购、留存等。影响解决率的因素有很多,如何量化分析其中每一个关联因素,直接找出问题所在,然后给出解决方案,很困难。之前一直做不到全自动化分析,需要大量人工介入分析,耗时费力,成本巨大。但是,大模型给出了完美的解决方案,我们把大模型引入到七鱼客服机器人的业务指标波动分析中,显著提升机器人售后维护效率。
影响业务指标解决率的常见因素有哪些?
业务指标,通常来说就是解决率,主要考核的就是转人工的会话个数,越少,解决率越高,反之,解决率越低。转人工的原因五花八门,主要如下所示:
1. 知识库中没有覆盖当前 C 端客户的热门咨询点。
2. 知识库中覆盖了当前 C 端客户的热门知识点,但是由于以下具体原因导致转人工:
-
答案配置得太复杂,内容太多,没有做到简洁、直白,客户不想看或者看不明白。
-
虽然覆盖了该知识点,但是用户问题在多个知识点中都配置了,导致匹配混乱。
-
虽然覆盖了该知识点,但是匹配在了原本不该出现的知识点下面。
3. 知识库中覆盖了当前 C 端客户的热门知识点,并且答案配置也很合理,客户就是想转人工。
4. 知识库中覆盖了当前 C 端客户的热门知识点,但是算法没有匹配到,或者匹配到了不是最好的。
如果客户购买了我们的七鱼智能客服机器人,用了一段时间以后,出现解决率下降怎么处理呢?目前售后维护同学最常见的做法是:
-
看下七鱼后台业务指标统计结果,分析下最近几天变化情况,然后再分析下转人工对话(因为时间有限,可能也就分析几通对话)。
-
再进一步就是拉取一下这个机器人的诊断报告,然后看下分析结论。
-
最后一套操作下来,给客户答复就是:你们这个机器人最近业务咨询量上升了,流量比之前大很多,可能是访客问了很多问题,在知识库中没有,所以解决率低了。
这么说,客户可能不会相信(可能还会被怼无脑回答),精细化运营时代,这些词不应该出现在反馈结论中。因为没有数据支撑,都是瞎扯,一切结论要有数据支持,量化指标才行。
大模型时代我们可以做什么?

如上图所示,这个是访客咨询的 top 热门问题,每个热门问题都关联到了当前的知识库,会提示当前知识库是否有存在的匹配知识点、以及配置的答案、是否差评等信息。有一种类型的问题需要重点关注,问题本身在知识库中有精确匹配的知识点,但是还是有差评,或者还是有很多转人工存在(该知识点解决率很低)。这种情况,目前的普遍做法是拉取转人工或者差评对话,人工分析其中的原因:
-
结合转人工前后两通对话,分析访客到底为啥转人工,需要给出大概的分类,这个分类本身是动态变化的,事先不知道具体都有哪些类别(因为单独一通对话,可能看不出来具体原因)。
-
判断转人工之前访客问的问题和转人工以后是否一致,有很多转人工的,并不是机器人回答的不好,而是,访客觉得下一个问题可能比较难,需要人工才可以解决;或者他下一个问题,就想要人工来负责处理。
-
转人工以后,访客都在咨询什么问题,这些问题人工是如何回答的,知识库中是不是有答案。
以上三个核心问题,伴飞服务一期做不了,只能人工抽取部分少量对话来分析,主观性、片面性很强,耗时不说,最后的准确率也不高。
大模型可以做哪些工作?主要有以下三种。
1. 使用大模型分析转人工前和转人工后的会话信息,让大模型自己总结转人工的原因,然后找出每一通转人工对话详细原因,并对这些原因做语义聚类,找出可能的分类。
-
无具体类别的分类,无法采用传统的分类算法,可以采用聚类,把相同含义的聚在一起。
-
采用大模型,自主确定分类的类别个数,然后总结每个类别占比。
2. 使用大模型判断转人工前和转人工后,访客咨询的问题是否前后一致(完全一致、部分一致、完全不一致),计算每种占比,如果:
-
完全一致占比最高,说明机器人未能很好得回答访客问题,访客问题在机器人端没有得到有效解决。
-
完全不一致占比最高,说明机器人已经很好的解决了访客问题,访客转人工是为了询问其他问题的,转人工高和机器人没有关系。
-
部分一致占比高,说明,机器人是解决了一部分访客问题的,但是不理想,需要进一步分析转人工以后询问的问题在知识库中是否有答案。
3. 统计转人工以后,访客询问的核心问题以及客服的回答,同时确定这个核心问题在当前知识库中是否已经存在,不存在的需要优化知识库,已经存在的,需要对比人工坐席回答和当前知识库中的答案是否一致,建议参考人工坐席回答来润色知识库中的答案。
客户(某车企为例)实践
选取某车企作为种子客户,使用大模型,深入分析。会话选取时间:2023 年 9 月和 10 月,一共 8731 通关联对话(大模型的分析耗时大概需要一个晚上时间)。
找一个 C 端访客转人工的对话,如下:
转人工之前的对话详情:
访客:你好。
客服:您好,请问有什么可以帮助您?
访客:话筒有优惠吗?
访客:买麦克风带有接收器吗?
转人工之后的对话详情:
客服:您好,很高兴为您服务~我这边帮您看一下,请稍等。
客服:麦克风使用【跳转商城】。
客服:有的哈,您可以通过视频参考一下。
访客:嗯嗯!
客服:请问还有其他问题可以帮您的吗?
访客:看了。
访客:有优惠吗?
客服:没有优惠呢?
我们使用大模型进行总结:
prompt 写法
现在有 A 和 B 两通客服和访客的对话,其中 A 对话是访客与客服机器人的对话,如果服务不满意,就会转接到人工客服,从而产生 B 对话。现在 A 对话如下:XXXX,B对话如下:XXXX。
现在你是一名客服信息整理人员,你被要求做以下事情:
1. 请结合 A 和 B 对话进行分析,总结访客为什么会转人工,直接给出具体的原因,不需要做额外的分析。
2. 需要联合 A 和 B 对话,综合起来分析,给出一个判断,在 A 对话中,访客问的问题和在 B 对话中,是否相同,有三个选择,完全相同、部分相同、完全不同,只能在这三个选项中选一个。
3. 需要对 B 对话进行分析,总结访客问的最核心问题以及客服的回答。
最后的结果要以 json 格式给出,具体如下:{'转人工原因':'XXXXX','访客在 A 和 B 对话中询问问题是否一致':'YYYYY','访客核心问题':'XXXXX','客服答案':'YYYYYY'}。不需要解释,直接给出 json 结果即可。"}
大模型返回结果
{
'转人工原因':'客服机器人没有回答访客关于话筒优惠和麦克风带有接收器的问题',
'访客在 A 和 B 对话中询问问题是否一致':'部分相同',
'访客核心问题':'麦克风带有接收器吗,有优惠吗',
'客服答案':'麦克风有结收器,没有优惠'
}
使用大模型分析转人工前后原因是否一致
对这 8000 多通会话分析以后(部分解码失败,大模型返回的 json 格式不对,导致解码出错,提取不到信息)。对访客转人工前后咨询问题是否有改变,得出的结论如下:
-
转人工前后,访客询问的问题是否一致:{'完全相同': 4821, '部分相同': 2157, '完全不同': 1708, '无法判断': 45}。
-
完全相同的占比:55.5%;部分相同占比:24.8%;完全不同占比:19.6%,其他占比:0.05%。
-
说明该车企所有转人工会话中,有将近 20% 不是由于机器人导致的,而是人为导致的,他就是想转人工。55.5% 是由于对机器人的回答答案不满意,不满足访客需求,这部分建议对比知识库答案和人工坐席答案。
使用大模型分析转人工原因以及类别占比
对所有的转人工原因进行聚类操作,结果如下(至于聚类多少个类别,根据样本个数来):

使用大模型分析转人工以后的问题
如果访客在转人工前后,询问的问题都是一样的,特别是这个问题在当前知识库有精确匹配的情况下,为啥访客还要坚持转人工?理论上说精确匹配已经可以直接出答案了,访客都已经看到答案了,还要求转人工,大概率是这个答案本身他不满意。所以,我们需要对这个知识库中的答案和人工答案作对比分析。
访客转人工以后,询问的问题,在当前的知识库中是否已经有知识点了?(可以反向评估当前知识库怎么样)如果已经有精确匹配了,把答案取出来,和人工做一个语义分析,观察是否合理。如果没有精确匹配,那就需要完善知识库。
大模型使用的 prompt:
prompt:现在有两个答案 A 和 B,其中 A 和 B 答案都可能带有 HTML 格式标签,如果带有标签,你需要先把标签去掉,再进行后续操作。\n A 答案是: {answer_a}\n,B 答案是:{answer_b}\n,是一名信息归纳整理人员,需要对两种答案 A 和 B 做判断,要求如下:\n 1.如果 A 和 B 答案有 HTML 标签,先把这些标签去掉。\n 2.拿去掉网页标签以后的 A 和 B 比较,判断 A 和 B 的语义是否一致,给出判断:语义完全相同、语义部分相同、语义完全不同三种答案。\n 其中语义完全相同,指的是 A 和 B 两个答案,在语义上完全一样,讲的都是同一个意思;语义部分相同,指的是 A 和 B 两个答案,有部分含义一样的,只是相互之间有差异,可能其中一个答案还说了其他事情;语义完全不同,指的是 A 和 B 两个答案,一点关系也没有,指的完全不同的事情。请你直接给出判断,在 语义完全相同、语义部分相同、语义完全不同 三个选项中,选择一个输出结果即可,不需要解释任何理由,直接给结果。
一共参与分析的会话有:7877。
转人工前后,访客咨询了相同的问题 并且 转人工以后咨询的问题在当前知识库中有精确匹配:1156,占比:14.7%
在这1156条结果中,机器人给出的答案和人工坐席给出的答案,语义差异较大的有:1138条,占比:98.4%,典型如下:
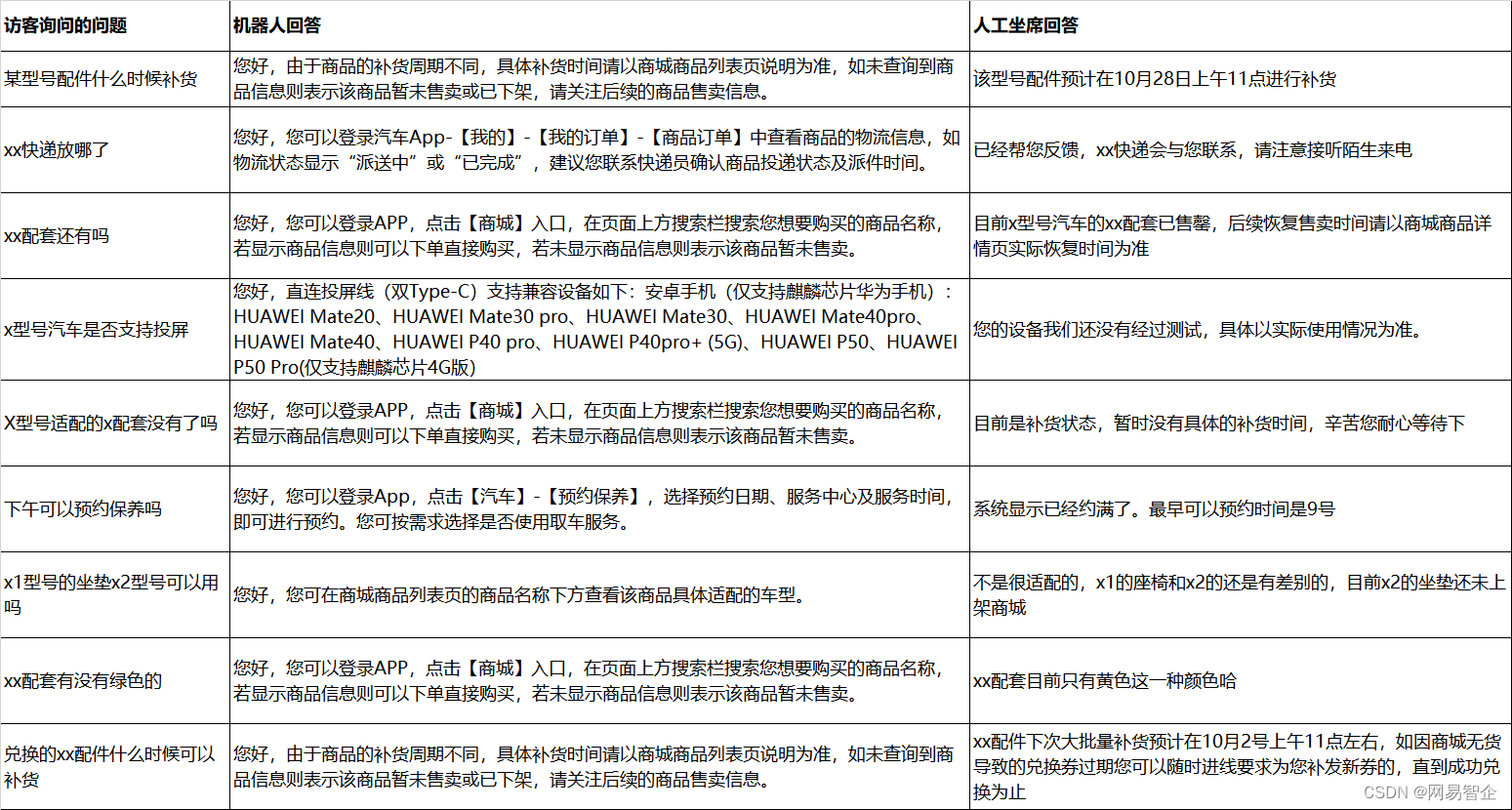
在这 1156 条结果中,机器人给出的答案和人工坐席给出的答案,语义相同的有:18 条,占比:1.6%,典型如下:
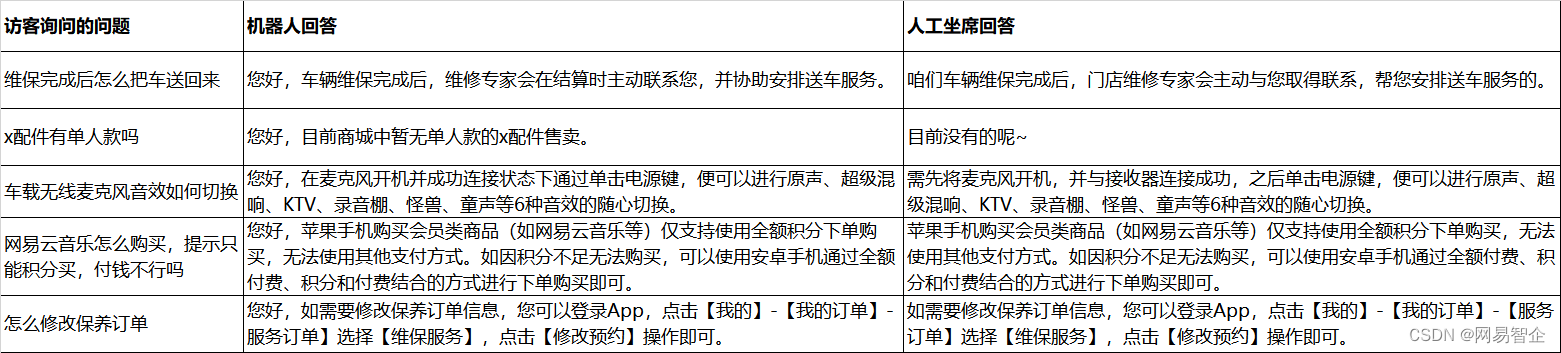
如果不管转人工前后咨询的问题是否相同,我们从整体看,在这 7000 多通已经转人工的会话中,访客咨询的问题在当前知识点有精确匹配的占比是:67.6%。

通过大模型的分析,我们可以很形象直观的把访客转人工前后的原因找出来,可以看出知识库中配置的答案和人工回答有啥不同。精细化运营时代,想提升解决率,必须要从每一个服务细节下手,当上述列出来的问题,是影响解决率的核心问题时候,就必须要及时处理。
比如该车企的这个案例,当前影响他们最主要的问题是人工客服可以通过内部的系统信息,查询到一些商品是否有货、到货时间、维修费用等信息,而不是知识库中配置的万能答案。这些万能答案本身没有问题,但是根本解决不了任何问题,相当于说了也白说,答案太过万能,没有聚焦访客问题。
总结
通过大模型分析转人工前后的对话,精确找出访客为啥要转人工。这个之前只能让人工去看,耗时费力,做一份分析报告,至少需要好几天时间,由于人工看的对话数量有限,难免以偏概全。
通过大模型总结转人工前后询问的问题是否一致,从这个切入点,就可以知道访客转人工是不是不满意当前机器人的回答,还是说 C 端访客就是想转人工,不信任机器人,这个比例大概有多少等信息。这样可以大概预估出通过优化,解决率可以提升多少。
通过大模型总结转人工以后访客的核心问题,然后通过回调线上服务的接口,就可以知道,如果访客当初没有转人工,他问的问题在当前知识库中是否有合适的知识点来解答。
如果有精确匹配,我们可以进一步把知识库中配置的答案找出来,和人工坐席的答案做语义层面的对比,看看差别是否很大,是不是可以再进一步优化。
如果没有精确匹配,我们需要进一步统计这个问题被询问的次数是否很多,如果很频繁,我们就需要整理到知识库中,以便其他访客询问类似问题,我们机器人可以做出完美回答。
总之,大模型时代,智能客服机器人无法缺席,大有可为。









![[PTQ]均匀量化和非均匀量化](https://img-blog.csdnimg.cn/1d7cb93add5d4b27b8fcc2e99b29a064.png#pic_center)


