模型过拟合,对经常建模的小伙伴来说是非常熟悉的,稍不留神,模型就出现过拟合了,这让我们在解决模型过拟合问题上花费了不少功夫。同样这个也是在面试中最高频会被Q到的问题。因此,在平日里建立模型的过程中,虽然模型过拟合问题很难避免,但在处理时为了避免少走弯路,我们有必要熟悉下模型过拟合的原因,以及常见的处理方法,这对我们提高建模的工作效率是非常有帮助的。
1、模型拟合介绍
在了解模型过拟合问题之前,我们先整体熟悉下机器学习模型训练的本质,以及模型拟合结果的表现形式。机器学习的核心思路是采用相关模型算法(常见如线性回归、逻辑回归、决策树、K近邻、朴素贝叶斯等)对建模样本数据进行拟合训练,从而实现对未知新样本数据的有效预测。在这个过程中,我们可以把模型的预测数据结果与样本真实数据结果之间的差异程度称为“误差”。其中,算法模型在训练数据集上的误差称为“训练误差”,而在新的测试样本数据上的误差称为“泛化误差”。
机器学习算法模型对训练样本数据集以外样本数据(包括验证数据集、测试数据集)的预测能力,也可以称为“泛化能力”,是机器学习提高模型性能的量化目标。在模型泛化能力表现不佳的原因中,过拟合与欠拟合问题是最常见的两种现象,下面简单介绍下二者的原理与区别。
(1)模型过拟合
模型过拟合,指算法模型的学习能力太强,使模型在训练拟合过程中,将样本数据中的“个别特征”当成了“一般规律”,更形象地说,就是把训练数据特征分布的“个性”作为所有潜在样本的“共性”来处理,从而导致模型的泛化能力很弱。过拟合问题通过模型指标可以直接反映,即模型在训练数据集上表现优异,但在测试数据集上表现较差。
(2)模型欠拟合
模型欠拟合,指算法模型的学习能力较弱,使模型在训练拟合过程中,难以学习到样本数据中的“一般规律”信息,直接导致模型的泛化能力较弱。从模型指标上体现,欠拟合问题在训练数据集和测试数据集的性能表现都比较差。
从过拟合与欠拟合的原理可以了解到,二者都会导致模型的泛化能力较弱,只是在训练拟合阶段的学习能力差异较大,可理解为正好相反。无论怎样,这两类问题都是我们在实际建模过程中不愿意看到的,都需要做出相关处理,以保证模型的学习能力与泛化能力都表现较好。
对于欠拟合问题来说,是相对容易解决的,情况本身在模型训练环节表现较差,也没有必要去进行建模样本外的性能测试,只需要对模型算法提高学习器的能力就可以解决,常见的方式是直接调整模型训练参数,比如增加模型迭代的次数等。
对于过拟合问题,是我们建模过程中需要重点关注和解决的,因为这种情况需要将训练数据和测试数据的模型表现进行对比才能发现。而且,从机器学习角度来讲,模型过拟合问题是难以避免的,测试数据的模型表现总会与训练数据的模型表现存在一定差异。我们需要尽可能做到的是,在模型指标可以满足业务需求的情况下,将模型在训练数据的“学习能力”与测试数据的“泛化能力”之间的差异缩放到一定合理的范围内,这是我们最终实现模型上线使用前的目标。
通过前边内容熟悉了模型过拟合与欠拟合的原理逻辑与业务背景之后,接下来我们结合实际场景情况,重点来分析下造成模型过拟合情况的相关原因。我们先从常用模型类型的角度,来看下回归模型与分类模型的拟合情况,具体示意图分别如图1、图2所示。
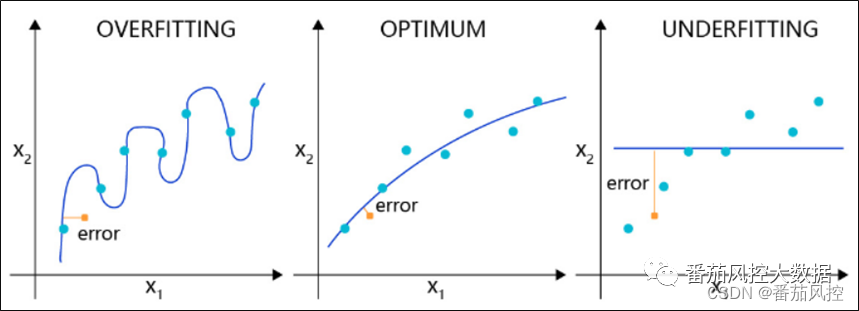
图1 回归模型的拟合情况
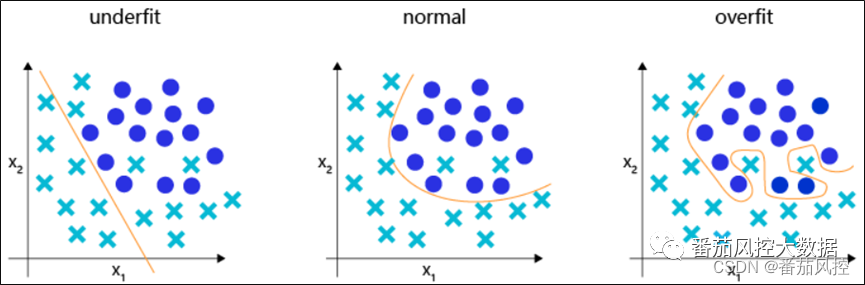
图2 分类模型的拟合情况
由以上示意图可知,可以很形象地理解模型拟合的不同情况及其特点:
(1)对于回归模型,通过可视化结果来反映(图1)。正常拟合的模型结果是一条坡度较缓的抛物线(optimum),样本点与拟合曲线存在的训练误差也是在合理范围内。过拟合的模型结果是存在很多拐点的抛物线(overfitting),虽然对样本数据特征学习很精准,但显然是对特征分布过于敏感,包括局部样本特征的个性化规律,并没有正确表达出数据分布的大众化规律。欠拟合的模型结果则是只拟合出一条直线(underfitting),显然没有真正学习到样本特征数据的真实规律。
(2)对于分类模型,通过可视化结果来反映(图2)。正常拟合的模型结果是一条半圆形曲线(normal),存在轻微的训练误差也是完全合理的。过拟合的模型结果曲线是一条非常扭曲的形状(overfit),虽然对样本点做出了较准确的分类,但其中样本点必然会存在个别特征,不能代表整体样本的普遍规律,难以表达出样本主要且真实的分布规律。欠拟合的模型结果是类似直线作为分类边界(underfit),很显然存在误差较大,没有将样本特征进行合理区分。
2、模型过拟合原因
通过前边内容熟悉了模型过拟合与欠拟合的原理特点与业务背景之后,接下来我们结合实际业务场景,来重点分析下造成模型过拟合情况的原因,主要有以下几种可能情况:
(1)模型训练数据的样本量不足
在建模前的样本准备环节,样本量是明显的特征表现,理论上讲,建模数据的样本量越多越好,有利于模型的训练学习,但是也需要适当,如果样本量超过一定范围,一方面由于样本特征类似没有过多训练的必要,另一方面也会加大服务器的承载能力也会降低建模效率。但是,模型训练数据的样本量过少,比如只有几百条样本,难以代表实际业务数据的客观规律,这样使模型训练时仅能学习到当前样本可能存在较大区分度的数据规律,而反映在测试数据上的模型性能表现会直接变差。一般情况下,建模样本的训练数据量至少可以达到几千,比如逻辑回归等算法,但最合理的情况是能满足几万条,这对常用的决策数集成学习算法(如随机森林、XGBoost、LightGBM等)也是非常合适的。
(2)建模样本的噪音数据干扰过大
在训练样本数据中,如果存在的噪音数据(异常值)数量过多或者特征明显,会直接影响模型训练的效果,因为模型在训练拟合时,会较大程度学习到噪音数据的特征分布特点,忽略样本客观数据的整体规律,也就是实际业务数据输入与输出的真实关系。
(3)模型训练拟合的迭代次数过多
在常见算法模型中,我们都可以指定模型训练的迭代次数,一般情况下可以选择默认参数,但是为了提升模型效果,我们往往会重新定义迭代次数。在这种情况下,如果模型的迭代次数太少,模型并没有得到较好的学习,会直接产生模型欠拟合的情况。如果模型的迭代次数过多,模型会将学习到很多噪音数据的分布规律,以及少量没有较好区分能力特征属性,这样虽然可以保证模型训练后的性能指标较好,但很容易造成模型过拟合现象。
(4)算法模型的参数复杂度过高
在采用某模型算法进行训练时,我们会经常通过定义多个参数来调整模型性能,比如常见的随机森林、XGBoost、LightGBM等算法,算法内置的超参数较多,例如决策树数量、树的深度、树叶子节点数、学习率等。虽然这些参数对模型性能影响较大,有助于我们优化模型效果,但是如果对模型参数组合设置的太多,会导致模型的复杂度增加,例如决策树的数量太多、树的深度太大、树叶子节点过多等。在这种情况下,最终得到决策树集成学习模型,由于在训练过程按照入参超量要求进行过度学习,使得模型出现过拟合的问题。
(5)测试样本与训练样本的特征分布差异较大
为了保证模型的效果,我们在建模过程中,必然会采用测试数据来检验模型训练的效果。对于常提到的验证数据集与测试数据集,可以理解为样本内测试与样本外测试。其中,样本内测试数据和训练样本数据来源于同一个建模宽表,数据拆分过程经常采用的是随机抽样。对于样本外测试数据,是从时间窗口角度,在训练数据时窗后的样本。但是,我们在提取测试样本时,比如针对样本内的验证数据集,如果没有采用随机抽样方法,或者在随机抽样的基础上又限定了某个前提条件,很可能导致验证样本数据集与训练样本数据集的特征分布存在较大差异。同理,针对样本外的测试数据集,如果选取的时间窗口不合理,也很可能导致测试样本数据集与训练样本数据集的特征差异较大。在这种情况下,虽然模型在训练样本数据上得到了合理的训练学习,但是反映在测试数据集上模型性能会下降很多。当然,这种过拟合现象本质上可以称为“伪过拟合”,但同样是我们建模过程中需要避免的。
3、过拟合解决方法
根据以上介绍的模型过拟合现象常见的几种原因,我们在实际的建模过程中,只要重点关注以上情况,可以很大程度的避免模型过拟合问题。在具体实施解决方面,我们针对以上场景,来简要描述下具体的解决思路与方法。
(1)增加训练数据集的样本量
训练数据样本量的选取,具体需要结合模型采用的算法,例如逻辑回归算法对样本量相对较少,随机森林、XGBoost、LightGBM等决策树集成学习相对较多,而神经网络算法需要样本量更多。
(2)减少模型拟合的特征数量
通过特征相关指标进行变量筛选,常见特征分析指标有信息值IV、相关性pearson、共线性vif、贡献度importance等,同时可以采用特征聚类、特征降维等方法缩小变量池范围。
(3)建模样本的数据清洗
在模型训练前,要对建模样本的噪音数据进行处理,包括异常值处理、缺失值处理、重复值处理等,这样可以有效避免噪音数据在模型拟合阶段的干扰。
(4)减少模型的迭代次数
在合理的范围内,适当减少模型的迭代次数,可以有效保证模型较低程度地学习区分能力弱或分布异常的特征规律。
(5)调低模型参数的复杂度
模型算法默认参数情况下,适当降低某些重要参数的取值,以决策树学习算法为例,可以降低树的深度、树的叶子节点数等。
(6)增加正则化约束条件
对于逻辑回归、线性回归等传统机器学习算法,常见的有L1正则化与L2正则化,也就是在模型训练的损失函数中加入⼀个正则化项;对于神经网络深度学习算法,增加Dropout 层约束条件,本质也是正则化约束。
以上内容便是根据建模过程中常出现的过拟合与欠拟合现象,分别描述了各种拟合情况的概念原理和分布特点。同时,围绕实际场景中需重点关注的模型过拟合问题,详细介绍了模型过拟合问题的主要原因,并具体分析了解决模型过拟合问题的思路与方法。在数据建模工作中,可以结合样本数据的实际情况,以及建模过程的分析步骤,合理选用数据处理方法,有效避免模型过拟合现象的出现,从而获得一个训练样本学习能力与测试样本泛化能力都表现较优的模型。
另外在模型调参上,之前陈老师在星球上也发过一个详细的帖子,提到过如何增加模型的鲁棒性,避免过拟合的情况,具体请参考星球上的帖子:

…
~原创文章