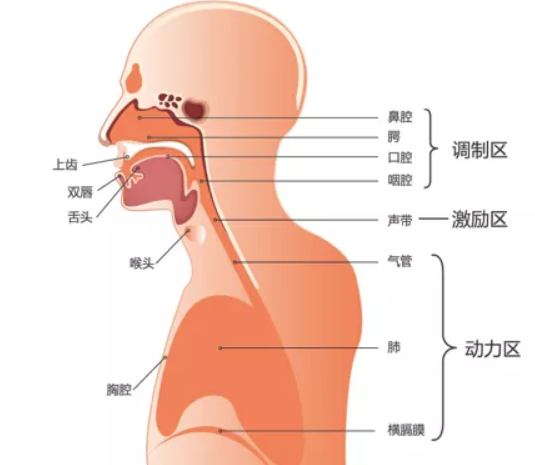
声音以波的形式传播,即声波(Sound Wave)。当我们以波的视角来理解声音时,却又大繁若简起来:仅凭频率(Frequency)、幅度(Magnitude)、相位(Phase)便构成了波及其叠加的所有,声音的不同音高(Pitch)、音量(Loudness)、音色(Timbre)也由这些基本“粒子”组合而来。
人耳对频率的接受范围大致为 20 Hz至20 kHz。


1. 语音交互优劣
1.1. 优势:
- 输入效率高。语音输入的速度是传统键盘输入方式的3倍以上。例如:语音电视选台、远场语音交互、语音支持组合指令输出(“播放周星驰电影、要免费的、4星以上的”)
- 使用门槛低。人类本就是先有语音再有文字,对于那些无法用文字交互的人来说,语音交互学习成本低,能带来极大的便利。例如:还不会打字的小孩,或者不方便打字的老人家
- 解放双手和双眼,更安全。例如:车载场景通过语音点播音乐和导航,医疗场景(医生在操作设备的时候,可能还需要记录病例)
- 传递更多的声学信息。声纹、性别、年龄、情感等。
1.2. 劣势
- 信息接收效率低。例如:文字能快速阅览概括信息,语音的话必须听完才能理解。
- 复杂的声学环境
方向性干扰环境噪声(散射噪声)远讲产生的混响声学回声
- 心理负担。交互方式不一样,例如:不太愿意通过语音来进行交互,特别是在一些公共场合
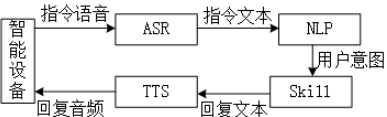
1.3. 前端处理意义
- 面对
噪声、干扰、声学回声、混响等不利因素的影响,运用信号处理、机器学习等手段,提高目标语音的信噪比或主观听觉感受,增强语音交互后续环节的稳健性。 - 让人听清:
更高的信噪比,更好的主观听觉感受和可懂度,更低的处理延时。 - 让机器听清:更好的
声学模型适配,更高的语音识别性能。
2.语言介绍
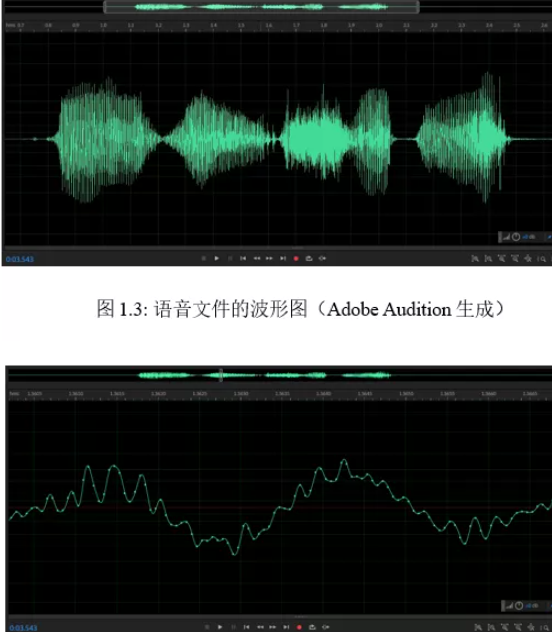
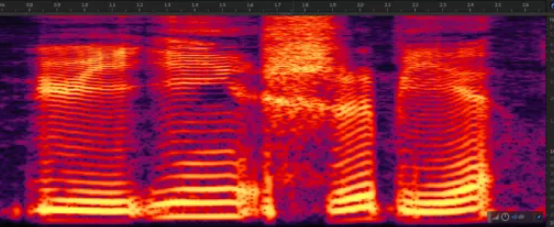
真正的语音不需要额外的注解,但对于数字化的语音来说,还需要额外的信息对文件格式进行说明,如
信道、采样率、精度、时长等,并有文件大小=格式信息+信道数采样率精度*时长。频谱图种,颜色明暗表示频带能量大小,较亮的条纹即是共振峰(Formant)。
3. 信号处理算法

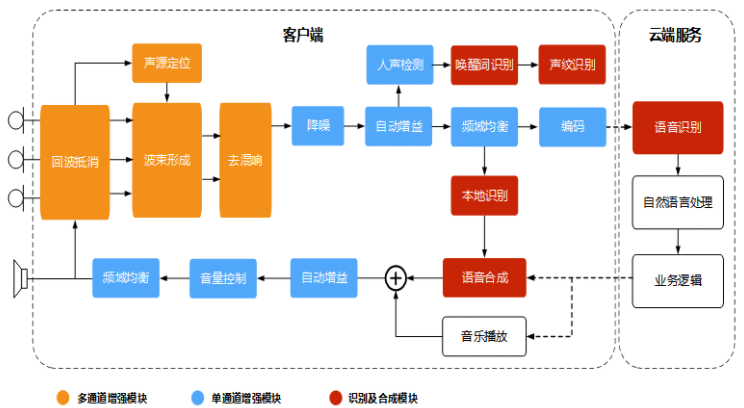
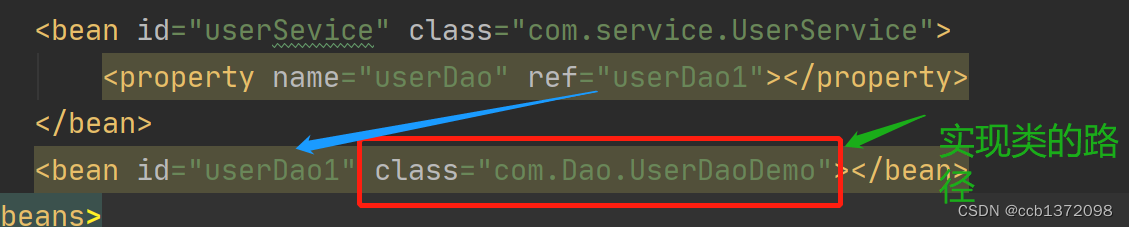
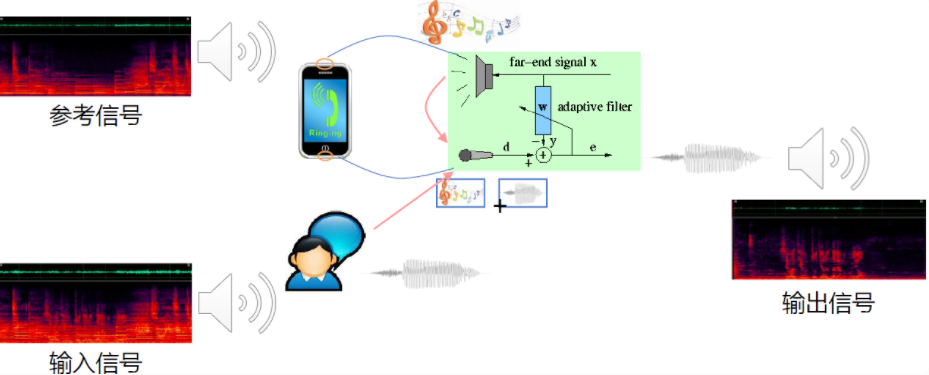
橙色部分表示多通道处理模块,蓝色部分表示单通道处理模块,红色部分表示后端识别合成等模块。麦克风阵列采集的语音首先利用参考源对各通道的信号进行回波消除,然后确定声源的方向信息,进而通过波束形成算法来增强目标方向的声音,再通过混响消除方法抑制混响;需要强调的是可以先进行多通道混响消除再进行波束形成,也可以先进行波束形成再进行单通道混响消除。经过上述处理后的单路语音进行后置滤波消除残留的音乐噪声,然后通过自动增益算法调节各个频带的能量后最为前端处理的输出,将输出的音频传递给后端进行识别和理解。
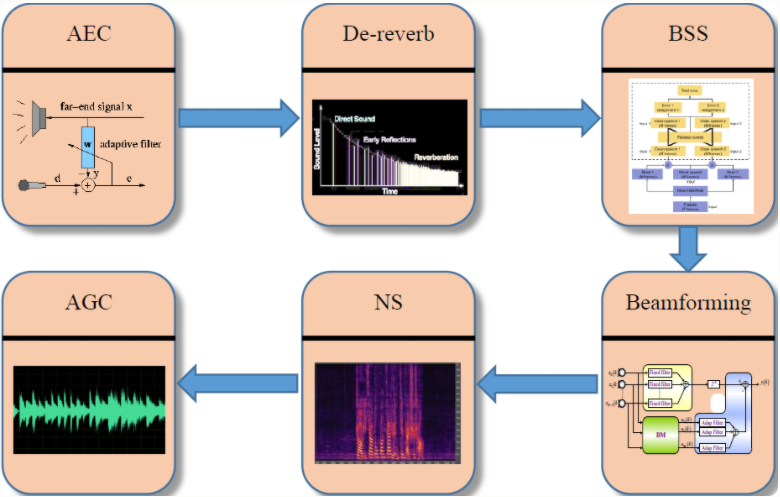
3.1. 回声消除(AEC)
- 电路回声
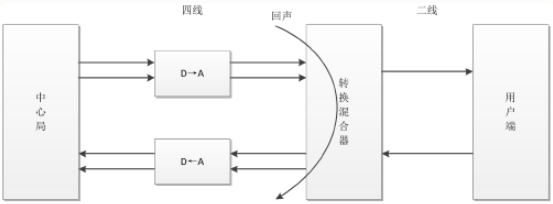
电路回声通常产生于有线通话中,为了降低电话中心局与电话用户之间电话线的价格,用户间线的连接采用两线制;而电话中心局之间连接采用四线制(上面两条线路用于发送给用户端信号,下面两条线路用于接收用户端信号)。问题就出来了,造成电路回声的根本原因是
转换混合器的二线-四线阻抗不能完全匹配(使用的不同型号的电线或者负载线圈没有被使用的原因),导致混合器 接收线路 上的语音信号流失到了 发送线路 ,产生了回声信号,使得另一端的用户在接收信号的同时听到了自己的声音。
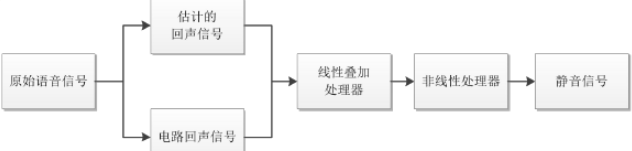
- 首先将产生的回声信号在数值上取反,线性地叠加在回声信号上,将产生的回声信号抵消,实现电路回声的初步消除。
- 添加一个非线性处理器,其实质是一个阻挡信号的开关,将残余的回声信号经过非线性处理之后,就可以实现电路回声的消除.
- 声学回声
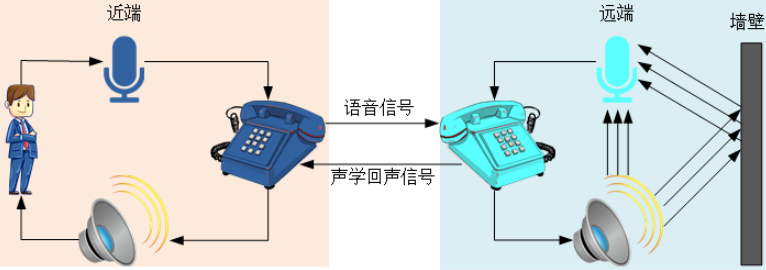
直接回声:远端扬声器将语音信号播放出来后,被远端麦克风直接采集后得到的回声;直接回声不受环境的印象,与扬声器到麦克风的距离及位置有很大的关系,因此直接回声是一种线性信号。
间接回声:远端扬声器将语音信号播放出来后,语音信号经过复杂多变的墙面反射后由远端麦克风将其拾取。间接回声的大小与房间环境、物品摆放以及墙面吸引系数等等因素有关,因此间接回声是一种非线性信号。
- 声场环境材料处理
- 墙壁、天花板换成吸音材料,有效的较少声音的反射,
- **优缺点:**可以较为直接的抑制间接噪声,但是直接噪声无法抑制;成本较高
- 回声抑制器
- 通过一个电平对比单元 轮流打开和关闭扬声器和麦克风
- **优缺点:**导致功放设备的输出信号不连续,总体效果不好
- 自适应回声抵消
- 通过自适应算法来调整滤波器的迭代更新系数,估计出一个期望信号,逼近经过实际回声路径的回声信号,也就是去模拟回声信号,然后从麦克风采集的混合信号中减去这个模拟回声,达到回声抵消的功能。
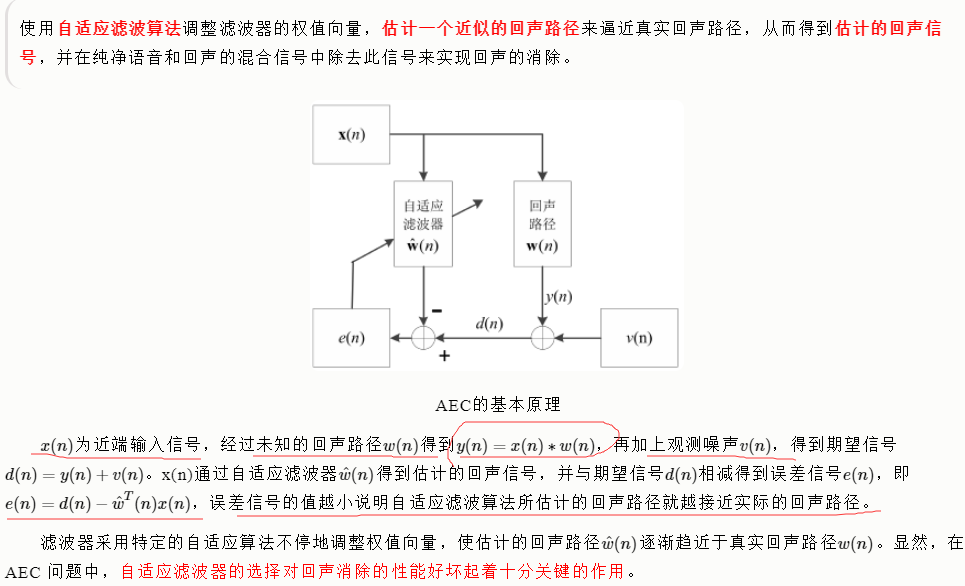
- LMS 算法介绍:
运用最小均方误差准则,对于LMS算法,其滤波器系数迭代公式为
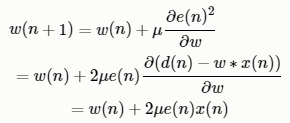

- NLMS算法
归一化最小均方(NLMS)算法是LMS算法的一个扩展,利用可变的步长因子代替固定的步长因子,就得到了NLMS算法,它通过计算最大步长值绕过了这个问题。
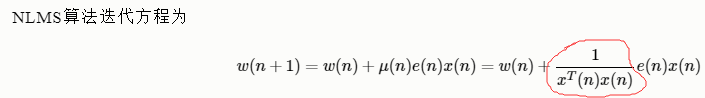
3.2. 解混响(De-reverb)
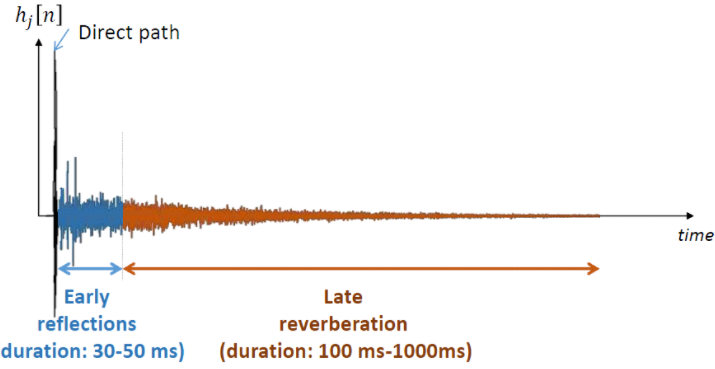
混响是由语音的多径效应所产生,在数学表达上是一个近场的纯净语音信号去卷积一个房间的冲击响应函数(RIR),这样的话能得到一个混响的语音信号。下图种蓝色部分为早期混响,橙色部分为晚期混响;在语音去混响任务中,更多的关注于对晚期混响的抑制。
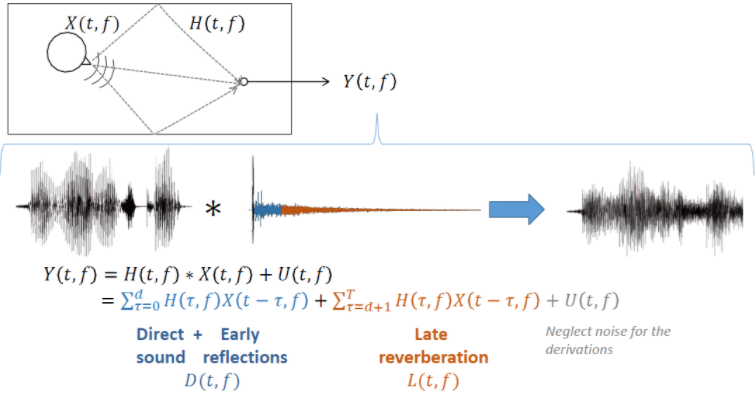
- 盲反卷积法[NeelyandAllen,1979]:直接去估计房间冲击响应函数的逆函数,如果把RIR当做是一个滤波器的话,我们直接去估计RIR的一个逆滤波器,然后把逆滤波器作用在带有混响的语音上,就得到了纯净语音信号。
只能假设完全没有噪声的场景,并且假设房间的冲击响应函数RIR是不变的,只有在这种比较严格的假设之下,才能得到相对较好的结果,但是这种假设在我们的实际情况当中是不会得到满足的,所以这种技术缺陷也是比较明显的) - 加权预测误差[WPE,Takuya,2012]:因为语音信号具有
线性预测特性(如果把语音信号当做是一系列采样点信号的话,那么下一个采样点可以用当前时刻以及当前时刻之前的若干采样点的值去预测出下一个时刻采样点的值),WPE认为混响可以分为早期混响和晚期混响,早期混响对于我们人的听觉感受系统没有负向作用,相反可能还有正面作用;晚期混响相对于房间冲击响应的拖尾的声音。那么加权预测误差则是希望估计一个最优的线性预测滤波器,这个滤波器的作用能够将房间冲击响应函数消除晚期混响的影响,多用于多通道。适用于单通道和多通道场景,多通道效果更好。www.kecl.ntt.co.jp/icl/signal/takuya/research/dereverberation.html - 麦克风阵列波束形成:混响是多路径反射到达麦克风的,所以入射方向是全向的入射,而语音是方向性的入射,所以可以设计一个波束,拾取手机语音入射方向的语音。这样其他方向的混响就会被抑制
- 深度学习用于解混响[Han,2015]:通过
DAE、DNN、LSTM或者GAN,实现频谱映射,端到端映射:带有干扰的语音信号频谱直接映射成为纯净语音信号的频谱,mask:掩膜,在当前的一个时频点上,是有效语音多还是带噪语音多,如果有效语音多则提取,如果带噪语音多则抑制。
3.3. 语音分离(BSS)
解决“鸡尾酒会”问题
- 听觉场景分析法[HuandWang,2004]:本质上是对人的听觉特性的模拟,具体手段是二分类+监督学习
- 非负矩阵分解[LeeandSeung,2001]:基于统计独立假设,语音信号的稀疏性与谐波特性,把
带有干扰的混合语音信号的频谱分解成为一个特征矩阵乘以另一个系数矩阵,那么之后属于不同声源的那些信号的特征就会很自然的聚集到一起,这样一来我们把属于干扰源的特征所对应的系数矩阵进行掩蔽, - 多通道技术:固定波束形成(fix beamforming)、自适应波束形成(adaptive beamforming)、独立成分分析(ICA),本质上都是在多通道的场景下,
通过一些空间信息和信号的统计独立假设,去估算一个最优的波束(要么提取目标说话人方向的声音,要么屏蔽干扰说话人方向的声音) - 基于深度学习的语音分离
- Deep clustering [Hershey, 2016]
- Deep attractor network [Luo and Chen, 2017]
- Permutation invariant training [Yu, 2017]
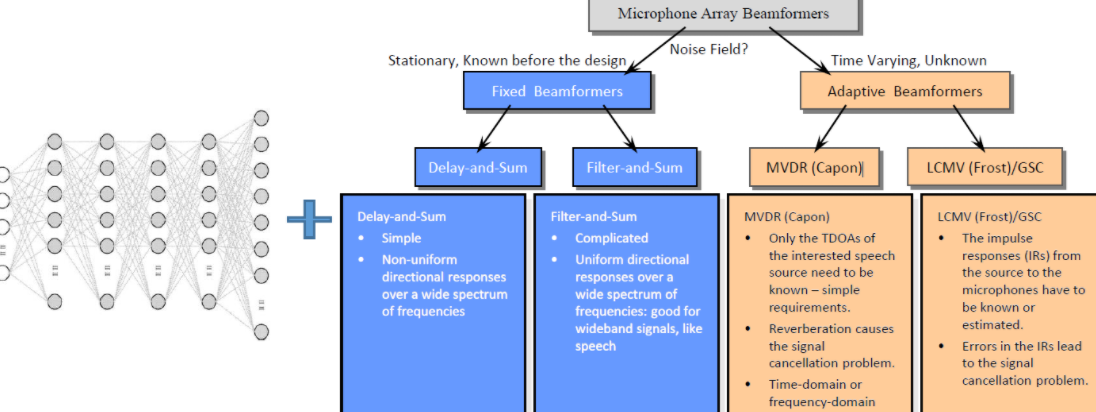
3.4. 波束成形(Beamforming)
3.5. 语音降噪(NS)
消除或抑制环境噪声,增强语音信号
- 基于统计模型的方法
- 最小均方误差MMSE、最大似然估计ML、最大后验估计MAP
- 基于子空间的方法
- 利用语音和噪声的
不相关性,借助特征值/奇异值分解手段分解到子空间处理
- 利用语音和噪声的
- 语音增强的核心在于噪声估计
- 递归平均、最小值追踪、直方图统计是比较常用的噪声估计手段
- 基于深度学习的语音增强方法
- 两大类方法:
masking&&mapping - 通过DNN、CNN、RNN或者GAN,在频域或时域实现(多为频域)
- 两大类方法:
3.6. 自动增益控制(AGC)
- 动态范围控制(Dynamic Range Control)
- 自动增益控制(Automatic Gain Control)
4. 学习链接
- 声学回声消除