作者:台运鹏 (正在寻找internship...)
主页:https://yunpengtai.top
鉴于网上此类教程有不少模糊不清,对原理不得其法,代码也难跑通,故而花了几天细究了一下相关原理和实现,欢迎批评指正!
关于此部分的代码,可以去
https://github.com/sherlcok314159/dl-tools查看
「在开始前,我需要特别致谢一下一位挚友,他送了我双显卡的机器来赞助我做个人研究,否则多卡的相关实验就得付费在云平台上跑了,感谢好朋友一路以来的支持,这份恩情值得一辈子铭记!这篇文章作为礼物赠与挚友。」
Why Parallel
我们在两种情况下进行并行化训练[1]:
「模型一张卡放不下」:我们需要将模型不同的结构放置到不同的GPU上运行,这种情况叫
ModelParallel(MP)「一张卡的batch size(bs)过小」:有些时候数据的最大长度调的比较高(e.g., 512),可用的bs就很小,较小的bs会导致收敛不稳定,因而将数据分发到多个GPU上进行并行训练,这种情况叫
DataParallel(DP)。当然,DP肯定还可以加速训练,常见于大模型的训练中
这里只讲一下DP在pytorch中的原理和相关实现,即DataParallel和DistributedParallel
Data Parallel
实现原理
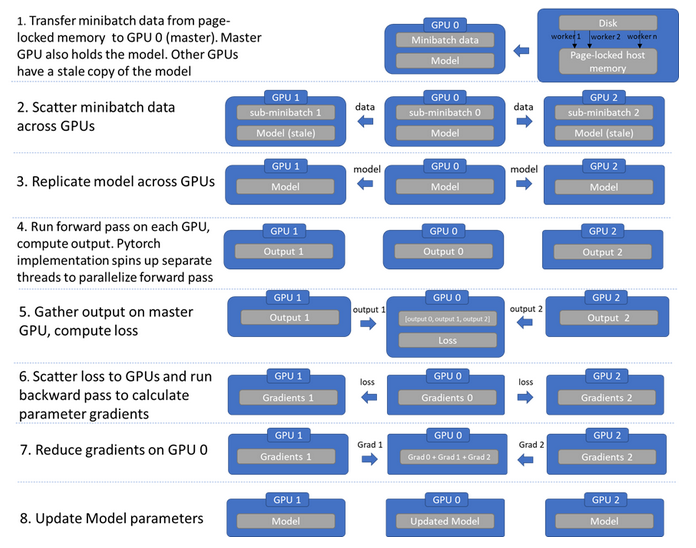
实现就是循环往复一个过程:数据分发,模型复制,各自前向传播,汇聚输出,计算损失,梯度回传,梯度汇聚更新,可以参见下图[2]:
pytorch中部分关键源码[3]截取如下:
def data_parallel(
module,
input,
device_ids,
output_device=None
):
if not device_ids:
return module(input)
if output_device is None:
output_device = device_ids[0]
# 复制模型
replicas = nn.parallel.replicate(module, device_ids)
# 拆分数据
inputs = nn.parallel.scatter(input, device_ids)
replicas = replicas[:len(inputs)]
# 各自前向传播
outputs = nn.parallel.parallel_apply(replicas, inputs)
# 汇聚输出
return nn.parallel.gather(outputs, output_device)代码使用
因为运行时会将数据平均拆分到GPU上,所以我们准备数据的时候, batch size = per_gpu_batch_size * n_gpus
同时,需要注意主GPU需要进行汇聚等操作,因而需要比单卡运行时多留出一些空间
import torch.nn as nn
# device_ids默认所有可使用的设备
# output_device默认cuda:0
net = nn.DataParallel(model, device_ids=[0, 1, 2],
output_device=None, dim=0)
# input_var can be on any device, including CPU
output = net(input_var)接下来看个更详细的例子[4],需要注意的是被DP包裹之后涉及到模型相关的,需要调用DP.module,比如加载模型
class Model(nn.Module):
# Our model
def __init__(self, input_size, output_size):
super(Model, self).__init__()
# for convenience
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
bs, input_size, output_size = 6, 8, 10
# define inputs
inputs = torch.randn((bs, input_size)).cuda()
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [6, xxx] -> [2, ...], [2, ...], [2, ...] on 3 GPUs
model = nn.DataParallel(model)
# 先DataParallel,再cuda
model = model.cuda()
outputs = model(inputs)
print("Outside: input size", inputs.size(),
"output_size", outputs.size())
# assume 2 GPUS are available
# Let's use 2 GPUs!
# In Model: input size torch.Size([3, 8]) output size torch.Size([3, 10])
# In Model: input size torch.Size([3, 8]) output size torch.Size([3, 10])
# Outside: input size torch.Size([6, 8]) output_size torch.Size([6, 10])
# save the model
torch.save(model.module.state_dict(), PATH)
# load again
model.module.load_state_dict(torch.load(PATH))
# do anything you want如果经常使用huggingface,这里有两个误区需要小心:
# data parallel object has no save_pretrained
model = xxx.from_pretrained(PATH)
model = nn.DataParallel(model).cuda()
model.save_pretrained(NEW_PATH) # error
# 因为model被DP wrap了,得先取出模型 #
model.module.save_pretrained(NEW_PATH)# HF实现貌似是返回N个loss(N为GPU数量)
# 然后对N个loss取mean
outputs = model(**inputs)
loss, logits = outputs.loss, outputs.logits
loss = loss.mean()
loss.backward()
# 返回的logits是汇聚后的
# HF实现和我们手动算loss有细微差异
# 手动算略好于HF
loss2 = loss_fct(logits, labels)
assert loss != loss2
True显存不均匀
了解前面的原理后,就会明白为什么会显存不均匀。因为GPU0比其他GPU多了汇聚的工作,得留一些显存,而其他GPU显然是不需要的。那么,解决方案就是让其他GPU的batch size开大点,GPU0维持原状,即不按照默认实现的平分数据
首先我们继承原来的DataParallel(此处参考[5])),这里我们给定第一个GPU的bs就可以,这个是实际的bs而不是乘上梯度后的。假如你想要总的bs为64,梯度累积为2,一共2张GPU,而一张最多只能18,那么保险一点GPU0设置为14,GPU1是18,也就是说你DataLoader每个batch大小是32,gpu0_bsz=14
class BalancedDataParallel(DataParallel):
def __init__(self, gpu0_bsz, *args, **kwargs):
self.gpu0_bsz = gpu0_bsz
super().__init__(*args, **kwargs)核心代码就在于我们重新分配chunk_sizes,实现思路就是将总的减去第一个GPU的再除以剩下的设备,源码的话有些死板,用的时候不妨参考我的[6]
def scatter(self, inputs, kwargs, device_ids):
# 不同于源码,获取batch size更加灵活
# 支持只有kwargs的情况,如model(**inputs)
if len(inputs) > 0:
bsz = inputs[0].size(self.dim)
elif kwargs:
bsz = list(kwargs.values())[0].size(self.dim)
else:
raise ValueError("You must pass inputs to the model!")
num_dev = len(self.device_ids)
gpu0_bsz = self.gpu0_bsz
# 除第一块之外每块GPU的bsz
bsz_unit = (bsz - gpu0_bsz) // (num_dev - 1)
if gpu0_bsz < bsz_unit:
# adapt the chunk sizes
chunk_sizes = [gpu0_bsz] + [bsz_unit] * (num_dev - 1)
delta = bsz - sum(chunk_sizes)
# 补足偏移量
# 会有显存溢出的风险,因而最好给定的bsz是可以整除的
# e.g., 总的=52 => bsz_0=16, bsz_1=bsz_2=18
# 总的=53 => bsz_0=16, bsz_1=19, bsz_2=18
for i in range(delta):
chunk_sizes[i + 1] += 1
if gpu0_bsz == 0:
chunk_sizes = chunk_sizes[1:]
else:
return super().scatter(inputs, kwargs, device_ids)
return scatter_kwargs(inputs, kwargs, device_ids, chunk_sizes, dim=self.dim)优缺点
优点:便于操作,理解简单
缺点:GPU分配不均匀;每次更新完都得销毁「线程」(运行程序后会有一个进程,一个进程可以有很多个线程)重新复制模型,因而速度慢
参考资料
[1]
Pytorch中多GPU并行计算教程: https://blog.csdn.net/qq_37541097/article/details/109736159
[2]DDP: https://www.cnblogs.com/ljwgis/p/15471530.html
[3]MULTI-GPU EXAMPLES: https://pytorch.org/tutorials/beginner/former_torchies/parallelism_tutorial.html?highlight=dataparallel
[4]OPTIONAL: DATA PARALLELISM: https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html
[5]transformer-xl: https://github.com/kimiyoung/transformer-xl
[6]Balanced Data Parallel: https://github.com/sherlcok314159/dl-tools/blob/main/balanced_data_parallel/README.md
📝论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
COLING'22 | SelfMix:针对带噪数据集的半监督学习方法
ACMMM 2022 | 首个针对跨语言跨模态检索的噪声鲁棒研究工作
ACM MM 2022 Oral | PRVR: 新的文本到视频跨模态检索子任务
统计机器学习方法 for NLP:基于CRF的词性标注
统计机器学习方法 for NLP:基于HMM的词性标注
点击这里进群—>加入NLP交流群