作者:杨金珊审校:陈之炎
本文约4300字,建议阅读8分钟“Attention is all you need”一文在注意力机制的使用方面取得了很大的进步,对Transformer模型做出了重大改进。目前NLP任务中的最著名模型(例如GPT-2或BERT),均由几十个Transformer或它们的变体组成。
背景
减少顺序算力是扩展神经网络GPU、ByteNet和ConvS2S的基本目标,它们使用卷积神经网络作为基本构建块,并行计算所有输入和输出位置的隐含表示。在这些模型中,将来自两个任意输入或输出位置的信号关联起来,所需的操作数量随着位置距离的增加而增加,对于ConvS2S来说,二者是线性增长的;对于ByteNet来说,二者是对数增长的。这使得学习遥远位置之间的依赖关系变得更加困难。在Transformer中,将操作数量减少到一个恒定数值,这是以降低有效分辨率为代价的,因为需要对注意力权重位置做平均,多头注意力 (Multi-Head Attention)抵消了这一影响。
为什么需要transformer
在序列到序列的问题中,例如神经机器翻译,最初的建议是基于在编码器-解码器架构中使用循环神经网络(RNN)。这一架构在处理长序列时受到了很大的限制,当新元素被合并到序列中时,它们保留来自第一个元素的信息的能力就丧失了。在编码器中,每一步中的隐含状态都与输入句子中的某个单词相关联,通常是最邻近的那个单词。因此,如果解码器只访问解码器的最后一个隐含状态,它将丢失序列的第一个元素相关的信息。针对这一局限性,提出了注意力机制的概念。
与通常使用RNN时关注编码器的最后状态不同,在解码器的每一步中我们都关注编码器的所有状态,从而能够访问有关输入序列中所有元素的信息。这就是注意力所做的,它从整个序列中提取信息,即过去所有编码器状态的加权和,解码器为输出的每个元素赋予输入的某个元素更大的权重或重要性。从每一步中正确的输入元素中学习,以预测下一个输出元素。
但是这种方法仍然有一个重要的限制,每个序列必须一次处理一个元素。编码器和解码器都必须等到t-1步骤完成后才能处理第t-1步骤。因此,在处理庞大的语料库时,计算效率非常低。
什么是Transformer
Transformer是一种避免递归的模型架构,它完全依赖于注意力机制来绘制输入和输出之间的全局依赖关系。Transformer允许显著的并行化……Transformer是第一个完全依靠自注意力来计算输入和输出的表示,而不使用序列对齐的RNN或卷积的传导模型。

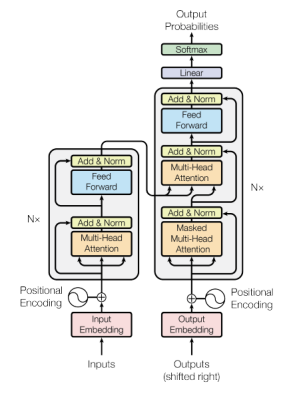
图1 Transformer 架构
从图1可以观察到,左边是一个编码器模型,右边是一个解码器模型。两者都包含一个重复N次的“一个注意力和一个前馈网络”的核心块。但为此,首先需要深入探讨一个核心概念:自注意力机制。
Self-Attention基本操作
Self-attention是一个序列到序列的操作:一个向量序列进去,一个向量序列出来。我们称它们为输入向量 ,
,  ,…,
,…, 和相应的输出向量
和相应的输出向量 ,
,  ,…,
,…, 。这些向量的维数都是k。要产生输出向量
。这些向量的维数都是k。要产生输出向量 ,Self-attention操作只需对所有输入向量取加权平均值,最简单的选择是点积。在我们的模型的Self-attention机制中,我们需要引入三个元素:查询、值和键(Queries, Values and Keys)。
,Self-attention操作只需对所有输入向量取加权平均值,最简单的选择是点积。在我们的模型的Self-attention机制中,我们需要引入三个元素:查询、值和键(Queries, Values and Keys)。
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention,self).__init__()
self.embed_size=embed_size
self.heads=heads
self.head_dim=embed_size//heads
assert(self.head_dim*heads==embed_size),"Embed size needs to be div by heads"
self.values=nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys=nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries=nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out=nn.Linear(heads*self.head_dim, embed_size)
def forward(self,values,keys,query,mask):
N=query.shape[0]
value_len,key_len,query_len=values.shape[1],keys.shape[1],query.shape[1]
#split embedding into self.heads pieces
values=values.reshape(N,value_len,self.heads,self.head_dim)
keys=keys.reshape(N,key_len,self.heads,self.head_dim)
queries=query.reshape(N,query_len,self.heads,self.head_dim)
values=self.values(values)
keys=self.keys(keys)
queries=self.queries(queries)
energy=torch.einsum("nqhd,nkhd->nhqk",[queries,keys])
#queries shape: (N,query_len, heads, heads_dim)
#keys shape: (N,key_len, heads, heads_dim)
#energy shape: (N,heads,query_len,key_len)
if mask is not None:
energy=energy.masked_fill(mask==0,float("-1e20"))#close it ,0
attention=torch.softmax(energy/(self.embed_size**(1/2)),dim=3)#softmax
out=torch.einsum("nhql,nlhd->nqhd",[attention,values]).reshape(N,query_len,self.heads*self.head_dim)
#attention shape: (N,heads, query_len,key_len)
#values shape: (N,value_len,heads,head_dim)#key_len=value_len=l
#after einsum(N,query_len,heads,head_dim) then flatten last two dim
out=self.fc_out(out)
return outQueries,Values和Keys
在自注意力机制中,通常输入向量以三种不同的方式使用:查询、键和值。在每个角色中,它将与其他向量进行比较,以获得自己的输出 (Query),获得第j个输出
(Query),获得第j个输出 (Key),并在权重建立后计算每个输出向量(Value)。为了得到这些,我们需要三个维数为k * k的权重矩阵,并为每个
(Key),并在权重建立后计算每个输出向量(Value)。为了得到这些,我们需要三个维数为k * k的权重矩阵,并为每个 计算三个线性变换:
计算三个线性变换:

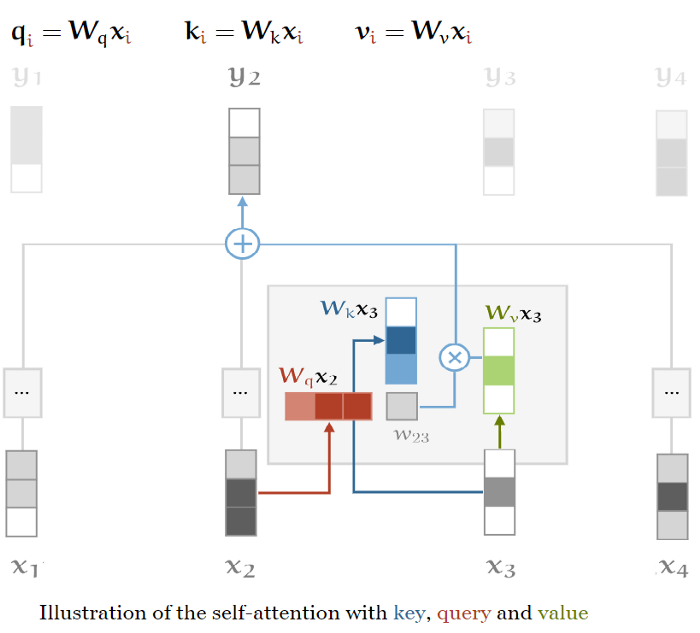
图2 查询、值和键(Queries, Values and Keys)三元素
通常称这三个矩阵为K、Q和V,这三个可学习权值层应用于相同的编码输入。因此,由于这三个矩阵都来自相同的输入,可以应用输入向量本身的注意力机制,即“Self-attention”。
TheScaledDot-ProductAttention(带缩放的点积注意力)
输入由维 的“查询”和“键”以及维
的“查询”和“键”以及维 的“值”值组成。我们用所有“键”计算“查询”的点积,每个“键”除以
的“值”值组成。我们用所有“键”计算“查询”的点积,每个“键”除以 的平方根,应用一个softmax函数来获得值的权重。
的平方根,应用一个softmax函数来获得值的权重。
使用Q, K和V矩阵来计算注意力分数。分数衡量的是对输入序列的其他位置或单词的关注程度。也就是说,查询向量与要评分的单词的键向量的点积。对于位置1,我们计算 和
和 的点积,然后是
的点积,然后是 、
、 2,
2,  、
、 等等,…
等等,…
接下来应用“缩放”因子来获得更稳定的梯度。softmax函数在大的值下无法正常工作,会导致梯度消失和减慢学习速度[1]。在“softmax”之后,我们乘以“值”矩阵,保留想要关注的单词的值,并最小化或删除无关单词的值(它在V矩阵中的值应该非常小)。
这些操作的公式为:
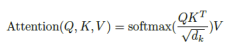
Multi-head Attention(多头注意力)
在前面的描述中,注意力分数一次集中在整个句子上,即使两个句子包含相同的单词,但顺序不同,也将产生相同的结果。相反,如果想关注单词的不同部分,”self-attention”的辨别能力则比较大,通过组合几个自注意力头,将单词向量分成固定数量(h,头的数量)的块,然后使用Q, K和V子矩阵将自注意力应用到相应的块。

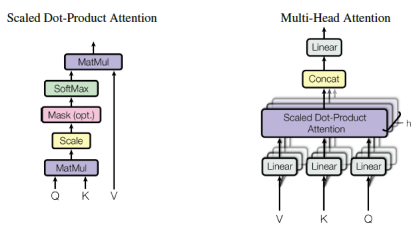
图3 多头注意力机制
由于下一层(前馈层)只需要一个矩阵,每个单词的一个向量,所以“在计算每个头部的点积之后,需要连接输出矩阵,并将它们乘以一个附加的权重矩阵Wo”[2]。最后输出的矩阵从所有的注意力头部获取信息。
PositionalEncoding(位置编码)
前文已经简单地提到,由于网络和self-attention机制是排列不变的,句子中单词的顺序是该模型中需要解决的问题。如果我们打乱输入句子中的单词,会得到相同的解。需要创建单词在句子中位置的表示,并将其添加到单词嵌入(embedding)中。
为此,我们在编码器和解码器栈底部的输入嵌入中添加了“位置编码”。位置编码与嵌入具有相同的维数,因此两者可以求和,位置编码有多种选择。
应用一个函数将句子中的位置映射为实值向量之后,网络将学习如何使用这些信息。另一种方法是使用位置嵌入,类似于单词嵌入,用向量对每个已知位置进行编码。“它需要训练循环中所有被接受的位置的句子,但位置编码允许模型外推到比训练中遇到的序列长度更长的序列”,[1]。
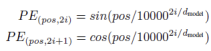
TransformerBlock(Transformer代码块)
class TransformerBlock(nn.Module):
def __init__(self, embed_size,heads,dropout,forward_expansion):
super(TransformerBlock,self).__init__()
self.attention=SelfAttention(embed_size,heads)
self.norm1=nn.LayerNorm(embed_size)
self.norm2=nn.LayerNorm(embed_size)
self.feed_forward=nn.Sequential(
nn.Linear(embed_size, forward_expansion*embed_size),
nn.ReLU(),
nn.Linear(forward_expansion*embed_size,embed_size)
)
self.dropout=nn.Dropout(dropout)
def forward(self,values,keys,query,mask):
attention=self.attention(values,keys,query,mask)
x=self.dropout(self.norm1(attention+query))
forward=self.feed_forward(x)
out=self.dropout(self.norm2(forward+x))
return outTheencoder(编码器)
位置编码:将位置编码添加到输入嵌入(将输入单词被转换为嵌入向量)。
N=6个相同的层,包含两个子层:一个多头自注意力机制,和一个全连接的前馈网络(两个线性转换与一个ReLU激活)。它按位置应用于输入,这意味着相同的神经网络会应用于属于句子序列的每一个“标记”向量。

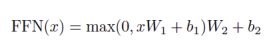
每个子层(注意和FC网络)周围都有一个残余连接,将该层的输出与其输入相加,然后进行归一化。
在每个残余连接之前,应用正则化:“对每个子层的输出应用dropout,然后将其添加到子层输入并正则化。

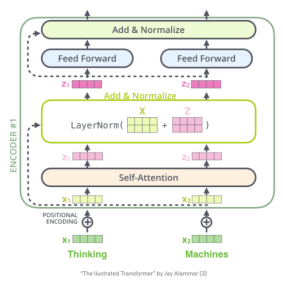
图4 编码器结构
class Encoder(nn.Module):
def __init__(
self,
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length):
super(Encoder,self).__init__()
self.embed_size=embed_size
self.device=device
self.word_embedding=nn.Embedding(src_vocab_size,embed_size)
self.position_embedding=nn.Embedding(max_length,embed_size)
self.layers=nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansion=forward_expansion
) for _ in range(num_layers)
]
)
self.dropout=nn.Dropout(dropout)
def forward(self,x,mask):
N,seq_length=x.shape
positions=torch.arange(0,seq_length).expand(N,seq_length).to(self.device)
out=self.dropout(self.word_embedding(x)+self.position_embedding(positions))
for layer in self.layers:
out=layer(out,out,out,mask) #key,query,value all the same
return outDecoderBlock(解码器代码块)
位置编码:编码器的编码相类似。
N=6个相同的层,包含3个子层。第一,屏蔽多头注意力或屏蔽因果注意力,以防止位置注意到后续位置。禁用点积注意力模块的软最大层,对应的值设置为−∞。第二个组件或“编码器-解码器注意力”对解码器的输出执行多头注意力,“键”和“值”向量来自编码器的输出,但“查询”来自前面的解码器层,使得解码器中的每个位置都能覆盖输入序列中的所有位置。,最后是完连接的网络。
每个子层周围的残差连接和层归一化,类似于编码器。
然后重复在编码器中执行的相同残差dropout。
class DecoderBlock(nn.Module):
def __init__(self, embed_size,heads,dropout,forward_expansion,device):
super(DecoderBlock,self).__init__()
self.attention=SelfAttention(embed_size,heads)
self.norm=nn.LayerNorm(embed_size)
self.transformer_block=TransformerBlock(
embed_size, heads, dropout, forward_expansion
)
self.dropout=nn.Dropout(dropout)
def forward(self,x,value,key,src_mask,trg_mask):
#source mask and target mask
attention=self.attention(x,x,x,trg_mask)#trg_mask is the mask mult-headed attention the first one in decoder block
query=self.dropout(self.norm(attention+x))
out=self.transformer_block(value,key,query,src_mask)
return out在N个堆叠的解码器的最后,线性层,一个全连接的网络,将堆叠的输出转换为一个更大的向量,logits。
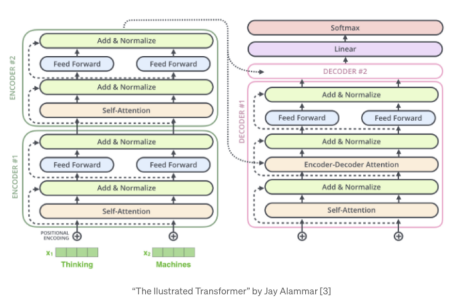
图5 解码器结构
Joining all the pieces: the Transformer(全部拼接起来构成Transformer)
定义并创建了编码器、解码器和linear-softmax最后一层等部件之后,便可以将这些部件连接起来,形成Transformer模型。
值得一提的是,创建了3个掩码,包括:
编码器掩码:它是一个填充掩码,从注意力计算中丢弃填充标记。
解码器掩码1:该掩码是填充掩码和前向掩码的结合,它将帮助因果注意力丢弃“未来”的标记,我们取填充掩码和前向掩码之间的最大值。
解码器掩码2:为填充掩码,应用于编码器-解码器注意力层。
class Transformer(nn.Module):
def __init__(
self,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
trg_pad_idx,
embed_size=256,
num_layers=6,
forward_expansion=4,
heads=8,
dropout=0,
device="cuda",
max_length=100):
super(Transformer,self).__init__()
self.encoder=Encoder(
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length
)
self.decoder=Decoder(
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length
)
self.src_pad_idx=src_pad_idx
self.trg_pad_idx=trg_pad_idx
self.device=device
def make_src_mask(self,src):
src_mask=(src!= self.src_pad_idx).unsqueeze(1).unsqueeze(2)
#(N,1,1,src_len)
return src_mask.to(self.device)
def make_trg_mask(self,trg):
N,trg_len=trg.shape
trg_mask=torch.tril(torch.ones((trg_len,trg_len))).expand(
N,1,trg_len,trg_len
)
return trg_mask.to(self.device)
def forward(self,src,trg):
src_mask=self.make_src_mask(src)
trg_mask=self.make_trg_mask(trg)
enc_src=self.encoder(src,src_mask)
out=self.decoder(trg, enc_src,src_mask, trg_mask)
return out参考文献:
[1] Peter Bloem, “Transformers from scratch” blog post, 2019.
[2] Jay Alammar, “The Ilustrated Transformer” blog post, 2018.
编辑:王菁
校对:林亦霖
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
 点击“阅读原文”加入组织~
点击“阅读原文”加入组织~