目录
- 引用
- 引用的特性
- 使用输出型参数
- 作返回值
- 小总结
- 引用的权限
- 引用和指针
引用
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
比如周树人,在外的笔名叫鲁迅
类型& 引用变量名(对象名) = 引用实体;
int main()
{
int a = 0;
int& b = a; // 引用
cout << &a << endl;
cout << &b << endl;
b++;
a++;
return 0;
}

引用的特性
- 引用在定义时必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
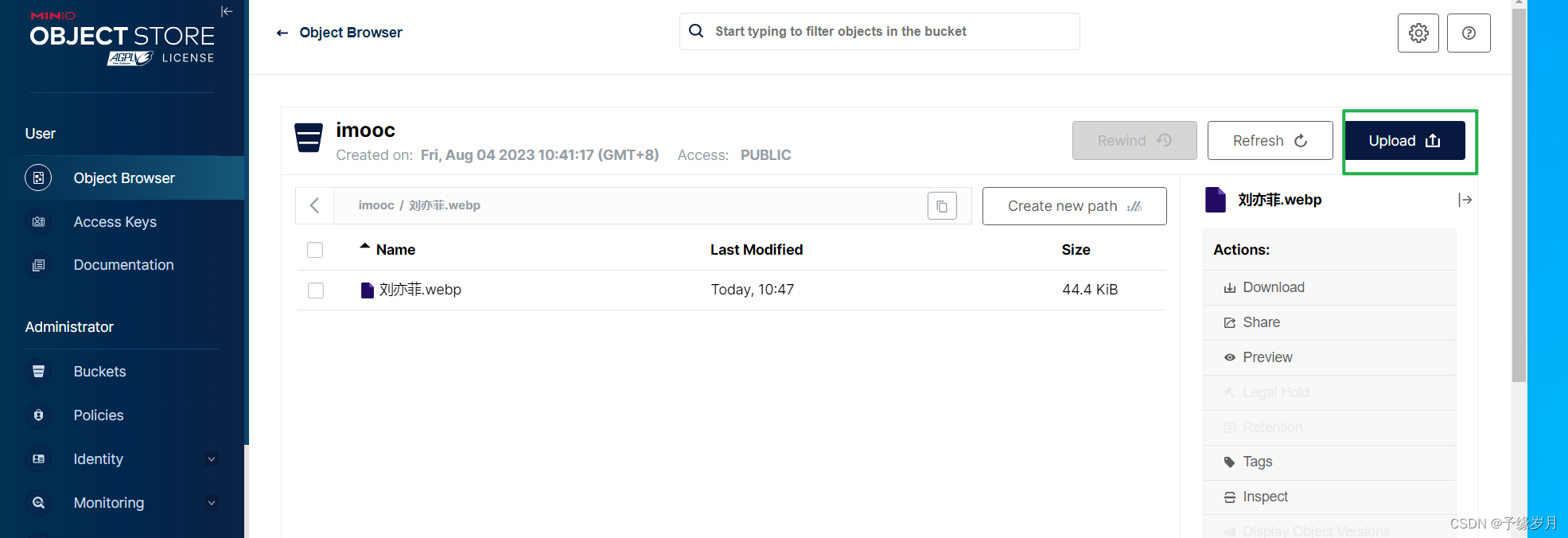
int a = 0;
int& b = a
int x = 1;
// 赋值
b = x;
b还是和a的地址是一样的
使用输出型参数
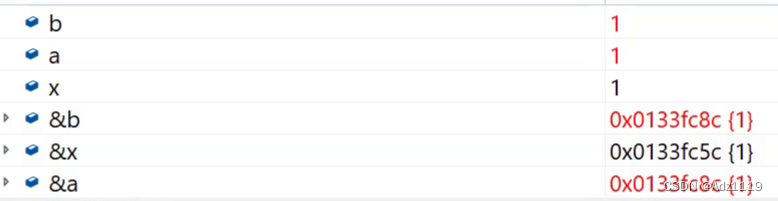
二叉树的前序遍历
本题用c语言写的话:
void _preorderTraversal(struct TreeNode* root,int* a,int* pi)
{
if(root==NULL)
return NULL;
a[(*pi)++]=root->val;
_preorderTraversal(root->left,a,pi);
_preorderTraversal(root->right,a,pi);
}
而c++用了引用后:
void _preorderTraversal(struct TreeNode* root, int* a, int& ri)
{
if (root == NULL)
return;
printf("[%d] %d ", ri, root->val);
a[ri] = root->val;
++ri;
_preorderTraversal(root->left, a, ri);
_preorderTraversal(root->right, a, ri);
}
//只放部分代码展示
int i = 0;
_preorderTraversal(root, a, i);
为什么不是直接传值(如图):
使用交换函数的使用也会方便许多
void swap(int& x1, int& x2)
{
int tmp = x1;
x1 = x2;
x2 = tmp;
}
int main()
{
int x = 0, y = 1;
swap(x, y);
return 0;
}
以前学习单链表尾插的时候
c语言二级指针的玩法
void PushBack(ListNode** pphead, int x)
{
ListNode* newnode;
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
}
}
int main()
{
ListNode* plist = NULL;
PushBack(&plist, 1);
PushBack(&plist, 2);
PushBack(&plist, 3);
return 0;
}
C++,引用的玩法
typedef struct ListNode {
int val;
struct ListNode* next;
}ListNode, *PListNode;
void PushBack(ListNode*& phead, int x)
//void PushBack(PListNode& phead, int x) 和上面代码一样的
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
// ...
if (phead == NULL)
{
phead = newnode;
}
else
{
}
}
int main()
{
ListNode* plist = NULL;
PushBack(plist, 1);
PushBack(plist, 2);
PushBack(plist, 3);
return 0;
}
plistnode是对struct Listnode*的typedef,也就是指针的typedef。plistnode代表结构体指针
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
如果传的是指针或者引用效率就会高很多,所以引用可以提高效率。
作返回值

不是把n返回给ret,因为函数调用结束的时候,n已经销毁了,所以不敢拿n去返回。所以设定是会生成临时变量,可能会用寄存器也可能是其他方式。在返回前拷贝给临时变量。把n的值拷贝到寄存器,然后寄存器充当返回值,一般值小的时候。当n比较大的时候,会在栈帧中间部分提前压一块空间作返回值。
还有一种返回方式叫传引用返回
返回的是n的引用,也就是返回的是n
可能会出现问题,n销毁了还返回n的别名,类似于野指针
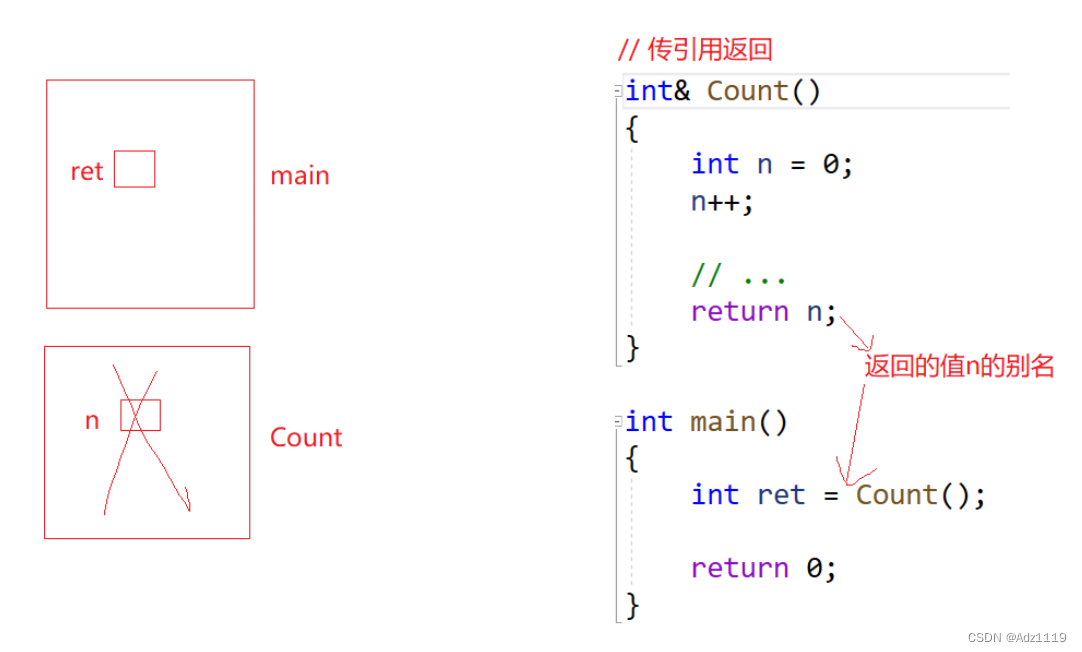
int& Count()
{
int n = 0;
n++;
// ...
return n;
}
int main()
{
int ret = Count();
cout << ret << endl;
cout << ret << endl;
return 0;
}
打印的结果可能是1,也可能是随机值,取决于这个栈帧销毁后空间会不会被置成随机值,得看环境,在vs下的结果是1 1
来看下面的代码会造成什么不一样的情况:
int& Count()
{
int n = 0;
n++;
// ...
return n;
}
int main()
{
int& ret = Count();
cout << ret << endl;
cout << ret << endl;
return 0;
}
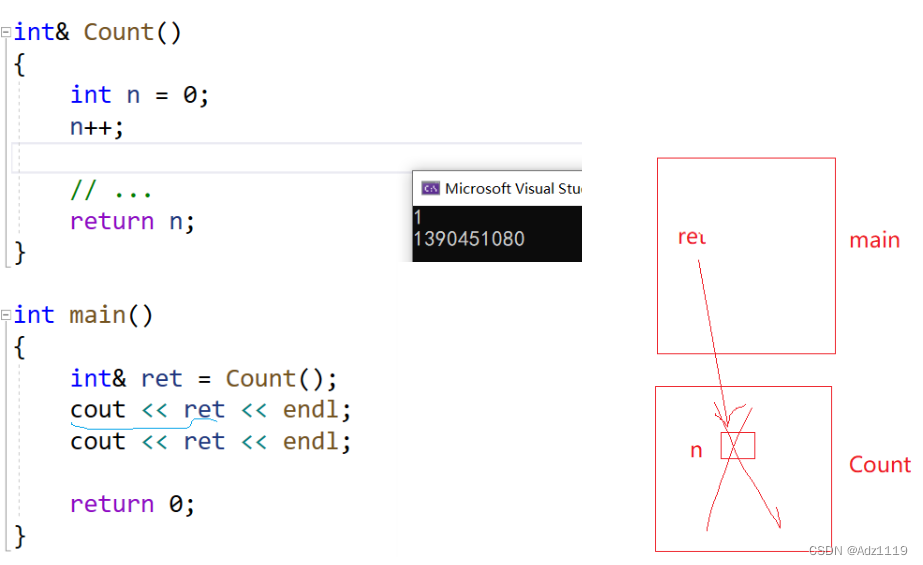
cout<<ret是一个函数调用,流插入这个函数调用还是在count空间上,只是栈帧大小可能比count大或小,函数调用时定义一些变量的时候就会对比如原来n的位置进行覆盖。
第一次调用没有覆盖因为调用函数先传参。传参过去之后函数建立栈帧但是传的值不会受到影响。第二次调用的时候想去取值,就会发现值被覆盖了。
不一定会覆盖,如果变量定义在太前一般都会被覆盖。比如在n前面定义一个大的数组就可能不被覆盖了。那么两次打印结果就都为1了(vs下)。
int& Count()
{
int a[1000];
int n = 0;
n++;
return n;
}
再看一个情况
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
Add(3, 4);
cout << "Add(1, 2) is :" << ret << endl;
}
可能是随机值可能是7,看栈帧销毁后空间会不会被置成随机值。
传引用返回让代码优化的例子:
C的接口设计
读取第i个位置的值
int SLAT(struct SeqList* ps, int i)
{
assert(i < ps->size);
// ...
return ps->a[i];
}
修改第i个位置的值
void SLModify(struct SeqList* ps, int i, int x)
{
assert(i < ps->size);
// ...
ps->a[i] = x;
}
CPP接口设计
读 or 修改第i个位置的值
int& SLAT(struct SeqList& ps, int i)
{
assert(i < ps.size);
// ...
return (ps.a[i]);
}
int main()
{
struct SeqList s;
s.size = 3;
// ...
SLAT(s, 0) = 10;
SLAT(s, 1) = 20;
SLAT(s, 2) = 30;
cout << SLAT(s, 0) << endl;
cout << SLAT(s, 1) << endl;
cout << SLAT(s, 2) << endl;
return 0;
}
小总结
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。
传引用传参(任何时候都可以用)
1、提高效率
2、输出型参数(形参的修改,影响的实参)
传引用返回(出了函数作用域对象还在才可以用)
1、提高效率
2、修改返回对象
引用的权限
在引用的过程中
权限可以平移
权限可以缩小
权限不能放大
int func()
{
int a = 0;
return a;
}
int main()
{
const int& ret = func();
const int a = 0;
// 权限的放大
// int& b = a;
//int b = a; 可以的,因为这里是赋值拷贝,b修改不影响a
// 权限的平移
const int& c = a;
// 权限的缩小
int x = 0;
const int& y = x;//x更改y也会改,y不能更改
int i = 0;
const double& d = i;
return 0;
}

在c/c++中,double d = i;发生类型转换(提升)、截断等时会产生一个临时变量,不是把 i 直接给d,是给一个double类型的临时变量,
double& d = i;是不行的原因是临时变量具有常性,这是一种权限的放大,用const引用临时变量就可以了。
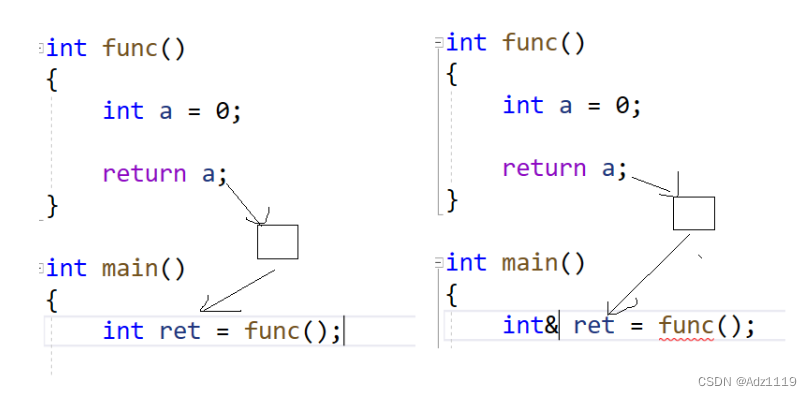
返回的不是a,是a的拷贝,右边会报错是因为临时变量具有常性
用const引用临时变量就可以了const int& ret = func();
不用担心临时变量销毁,用const引用后会延长对象的生命周期,相当于ret出了作用域临时变量才销毁
引用和指针
语法上理解引用不开空间
下层到底是怎么样的?

lea是取地址,对a取地址放到寄存器,再把寄存器放到p1
从图可以看到引用和指针在底层是一样的,引用也是存地址
再看看使用的时候:

所以底层只有指针,没有引用
像正版和盗版,内核是一样的,但是可以通过品牌区分出来
引用和指针的不同点:
- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求,没有NULL引用,但有NULL指针
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
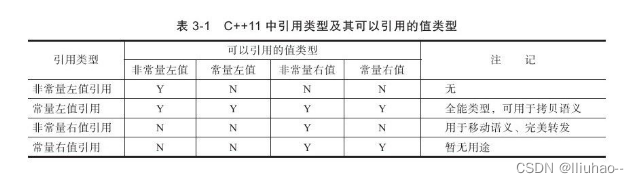
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全













![[MAUI 项目实战] 手势控制音乐播放器: 动画](https://img-blog.csdnimg.cn/img_convert/a2ccb62e66267b667f935ac716ea0286.gif)