【论文阅读】基于 NeRF 的 3D 重建的批判性分析
- Abstract
- 1. Introduction
- 2. The State of the Art
- 2.1. Photogrammetric-Based Methods
- 2.2. NeRF-Based Methods
- 3. Analysis and Evaluation Methodology
- 3.1. Proposed Methodology
- 3.2. Metrics
- 3.3. Testing Objects
- 4. Comparisons and Analyses
- 4.1. State-of-the-Art Comparison
- 4.2. Image Baseline’s Evaluation
- 4.3. Monte Carlo Simulation
- 4.4. Plane Fitting
- 4.5. Profiling
- 4.6. Cloud-to-Cloud Comparison
- 4.7. Accuracy and Completeness
- 5. Conclusions

Abstract
本文对使用神经辐射场 (NeRF) 的基于图像的 3D 重建进行了批判性分析,重点是与传统摄影测量的定量比较。因此,目的是客观评估 NeRF 的优缺点,并深入了解它们在不同现实生活场景(从小物体到遗产和工业场景)的适用性。在对摄影测量和 NeRF 方法进行全面概述后,强调了各自的优缺点,并使用具有不同尺寸和表面特征的不同物体(包括无纹理、金属、半透明和透明表面)对各种 NeRF 方法进行了比较。我们使用多个标准评估了 3D 重建结果的质量,例如噪声水平、几何精度和所需图像的数量(即图像基线)。结果表明,在具有无纹理、反射和折射表面的非协作对象上,NeRF 表现出优于摄影测量的性能。相反,在物体表面具有协作纹理的情况下,摄影测量优于 NeRF。 这种互补性应该在未来的工作中得到进一步利用。
1. Introduction
在计算机视觉和摄影测量领域,高质量3D重建是一个重要课题,具有许多应用,例如质量检测、逆向工程、结构监测、数字保存等。然而,低成本、便携且灵活的3D重建多年来,对提供高几何精度和高分辨率细节的测量技术的需求量很大。现有的 3D 重建方法可大致分为接触式或非接触式技术 [1]。为了确定物体的精确 3D 形状,基于接触的技术通常采用卡尺或坐标测量机等物理工具。虽然精确的几何 3D 测量是可行的并且非常适合许多应用,但它们确实有一些缺点,例如采集数据和执行稀疏 3D 重建所需的时间长度、测量系统的限制和/或需要昂贵的仪器,这限制了它们在具有独特计量规格的专业实验室和项目中的使用。另一方面,非接触式技术可以实现精确的 3D 重建,并且没有相关的缺点。大多数研究人员都专注于基于被动图像的方法,因为它们在广泛的应用领域具有低成本、便携性和灵活性,包括工业检测和质量控制 [2-5] 以及传统 3D 文档 [6-9]。

图 1. NeRF 场景表示的基本概念(在[16]之后)——另见第 2.2 节。
如图 1 所示,神经网络将一组由空间位置 (x, y, z) 和观察方向 (θ, φ) 组成的连续 5D 坐标作为输入,并输出每个点的每个方向上的体积密度 (σ) 和与观察方向相关的发射辐射率 (RGB)。然后从某个角度渲染 NeRF,并且可以导出 3D 几何形状,例如,通过行进相机光线以网格的形式导出[23]。
然而,尽管它们最近很受欢迎,但与更传统的摄影测量相比,仍然需要对基于 NeRF 的方法进行批判性分析,以便客观地量化生成的 3D 模型的质量并充分了解其优点和局限性。
Aims of This Research
NeRF 方法最近已成为基于图像的 3D 重建领域中摄影测量和计算机视觉的有前景的替代方案。因此,本研究旨在彻底分析用于 3D 重建的 NeRF 方法。我们评估使用基于 NeRF 的技术并通过摄影测量对各种尺寸和表面特征(纹理良好、无纹理、金属、半透明和透明)的物体生成的 3D 重建的准确性。我们从表面偏差(噪声水平)和几何精度方面检查了每种技术生成的数据。最终目标是评估 NeRF 方法在现实场景中的适用性,并提供关于基于 NeRF 的 3D 重建方法的优点和局限性的客观评估指标。
本文的结构如下:第 2 节概述了之前使用基于摄影测量和基于 NeRF 的方法进行 3D 重建的研究活动。第 3 节介绍了拟议的质量评估流程和使用的数据集,第 4 节报告了评估结果和比较结果。最后,第 5 节提供了结论和未来的研究计划。
2. The State of the Art
在本节中,对先前的 3D 重建研究进行了全面概述,结合了摄影测量和基于 NeRF 的方法,并考虑了它们在非协作表面(反射、无纹理等)中的应用。
2.1. Photogrammetric-Based Methods
摄影测量是一种广泛接受的对纹理良好的物体进行 3D 建模的方法,能够通过多视图立体 (MVS) 方法准确可靠地恢复物体的 3D 形状。基于摄影测量的方法[19,24–30]要么依赖特征匹配进行深度估计[27,28],要么使用体素来表示形状[24,29,31,32]。也可以使用基于学习的 MVS 方法,但它们通常取代经典 MVS 管道的某些部分,例如特征匹配 [33–36]、深度融合 [37,38] 或多视图图像深度推断 [39– 41]。然而,具有无纹理、反射或折射表面的物体很难重建,因为所有摄影测量方法都需要多个图像之间的匹配对应关系[14]。为了解决这个问题,人们开发了各种摄影测量方法来重建这些非协作对象。对于无纹理的物体,已经提出了诸如随机图案投影[13,42,43]或合成图案[14,44]等解决方案。然而,这些方法难以处理具有强镜面反射或互反射的高反射表面[43]。其他方法,如交叉偏振 [7,45] 和图像预处理 [46,47] 已用于反射或非协作表面,但某些技术可能会平滑表面粗糙度并影响视图之间的纹理一致性 [48,49 ]。摄影测量也用于混合方法 [50-53],其中 MVS 方法用于生成稀疏 3D 形状,该形状可以作为使用光度立体 (PS) 进行高分辨率测量的基础。传统的[52,54,55]和基于学习的[56-58] PS方法也用于理解图像辐照度方程并检索成像对象的几何形状,但镜面表面对于所有基于图像的方法仍然具有挑战性。
2.2. NeRF-Based Methods
合成逼真的图像和视频是计算机图形学的核心,也是数十年来研究的焦点[59]。神经渲染是一种基于学习的图像和视频生成方法,用于控制场景属性(例如照明、相机参数、姿势、几何形状、外观等)。神经渲染将深度学习方法与计算机图形学的物理知识相结合,以实现可控且逼真 (3D) 的场景模型。其中,NeRF,由Mildenhall等人首先提出。 2020 年,这是一种使用隐式表示渲染新视图和重建 3D 场景的方法(图 1)。在 NeRF 方法中,采用神经网络从 2D 图像中学习物体的 3D 形状。辐射场,如方程 (1) 中所定义,从每个可能的观察方向捕获场景中每个点的颜色和体积密度:

NeRF 模型采用神经网络表示,其中 X 表示图像的 3D 坐标,d 表示方位角和极坐标视角,c 表示颜色,σ 表示场景的体积密度。为了确保多视图一致性,σ的预测被设计为与观看方向无关,而颜色c可以根据观看方向和位置而变化。为了实现这一目标,分两步采用多层感知器(MLP)。第一步,MLP 将 X 作为输入并输出 σ 和高维特征向量。然后,特征向量与观察方向 d 相结合,并通过附加的 MLP,生成颜色表示 c。最初的 NeRF 实现以及后续方法采用了非确定性分层采样方法,如方程 (2)-(4) 所示。该方法涉及将光线分成 N 个等距的 bin,并从每个 bin 中均匀地抽取样本:

其中 δi 表示连续样本(i 和 i + 1)之间的距离,而 σi 和 ci 表示沿样本点 (i) 的估计密度和颜色值。采样点 (i) 处的透明度或不透明度 αi 也可使用公式 (4) 计算。
连续的方法[60-62]还结合了估计的深度,如方程(5)所示,以对密度施加限制,使它们类似于场景表面的δ函数,或强制深度的平滑度:

为了优化 MLP 参数,对每个像素使用平方误差光度损失:

其中变量 Cgt® 表示训练图像中与射线 r 对应的像素的地面真实颜色,而 R 指与要合成的图像相关的一批射线。应该注意的是,学习到的 NeRF 隐式 3D 表示被指定用于视图渲染。为了获得显式的 3D 几何形状,需要通过采用每条射线的深度分布的最大似然来提取不同视图的深度图。然后可以融合这些深度图以导出点云或将其输入到 Marching Cube [23] 算法中以导出 3D 网格。
尽管与传统摄影测量方法相比,NeRF 为 3D 重建提供了一种替代解决方案,并且可以在摄影测量可能无法提供准确结果的情况下产生有希望的结果,但正如不同作者所报告的那样,它仍然面临一些局限性 [63-68]。从 3D 计量角度来看,需要考虑的一些主要问题包括:
(1) 生成的神经渲染(随后转换为 3D 网格)的分辨率可能受到输入数据的质量和分辨率的限制。一般来说,更高分辨率的输入数据将产生更高分辨率的 3D 网格,但代价是计算要求增加。
(2) 使用 NeRF 生成神经渲染(然后生成 3D 网格)可能需要大量计算,需要大量的计算能力和内存。
(3) 一般无法对非刚性物体的 3D 形状进行精确建模。
(4) 原始 NeRF 模型是基于每像素 RGB 重建损失进行优化的,这可能会导致重建出现噪声,因为当仅使用 RGB 图像作为输入时,存在无限数量的照片一致的解释。
(5) NeRF通常需要大量具有小基线的输入图像来生成精确的3D网格,特别是对于具有复杂几何形状或遮挡的场景。在图像难以获取或计算资源有限的情况下,这可能是一个挑战。
针对上述问题,研究人员对原始 NeRF 方法提出了一些修改和扩展,以提高性能和 3D 结果。坦西克等人。 [69] 和西茨曼等人。由于NeRFs的高频表示能力不足,[70]采用了与NeRFs不同频率的位置编码操作,以提高神经渲染结果的分辨率。在此之后,其他方法专注于以不同方式提高神经渲染结果的效率和分辨率,包括模型加速[20,71]、压缩[72-74]、重新照明[75-77]和视图依赖归一化[78](Zhu et al., 2023)或高分辨率2D特征平面[68]。穆勒等人。 [20] 引入了具有多分辨率哈希编码的即时神经图形基元的概念,它允许快速高效地生成 3D 模型。巴伦等人。 [64,79]提出Mip-NeRF是原始NeRF的修改版本,允许在连续值尺度上表示场景。 Mip-NeRF 通过有效渲染抗锯齿截头圆锥体而不是射线,极大地提高了 NeRF 强调精细细节的能力。然而,该方法的局限性可能包括训练困难和计算效率问题。陈等人。 [72] 提出了一种称为 Tensorf 的新方法,用于将场景的辐射场建模和重建为 4D 张量。该方法表示具有每体素多通道特征的 3D 体素网格。除了提供卓越的渲染质量之外,与以前和当代的方法相比,该方法还实现了低得多的内存使用量。杨等人。 [80]提出了一种名为 PS-NeRF 的基于融合的方法,它将 NeRF 的优点与光度立体方法结合起来。该方法旨在通过利用 NeRF 重建场景的能力来解决传统光度立体技术的局限性,最终提高所得网格的分辨率。赖瑟等人。 [68]引入了内存高效辐射场(MERF)表示,它允许利用稀疏特征网格和高分辨率2D特征平面快速渲染大规模场景。李等人。 [21] 介绍了 Neuralangelo,这是一种创新方法,利用多分辨率 3D 哈希网格和神经表面渲染,在从多视图图像中恢复密集的 3D 表面结构方面取得了优异的结果,从而实现了从 RGB 视频捕获中进行高度详细的大规模场景重建。
一些方法 [67,81–85] 已经被提出,将 NeRF 扩展到动态域。这些方法使得重建和渲染物体的图像成为可能,同时物体正在经历来自在场景中移动的单个相机的刚性和非刚性运动。例如,Yan 等人。 [84]引入了表面感知动态 NeRF(NeRF-DS)和掩模引导变形场。通过将表面位置和方向作为神经辐射场函数中的调节因素,NeRF-DS 改进了镜面表面复杂反射特性的表示。此外,使用掩模引导变形场使 NeRF-DS 能够有效处理物体运动过程中发生的大变形和遮挡。
为了提高存在噪声时 3D 重建的准确性,特别是对于光滑和无纹理的表面,一些研究将各种先验纳入优化过程。这些先验包括语义相似性[86]、深度平滑度[60]、表面平滑度[87,88]、曼哈顿世界假设[89]和单目几何先验[90]。相比之下,Bian等人提出的NoPe-NeRF方法。 [91]使用单色图来约束帧之间的相对姿势并规范 NeRF 的几何形状。该方法可以实现更好的姿态估计,从而提高新视图合成和几何重建的质量。拉科托萨纳等人。 [92] 引入了一种用于 3D 表面重建的新颖且多功能的架构,该架构可以有效地将 NeRF 驱动方法中的体积表示提取到有符号表面近似网络中。这种方法能够提取准确的 3D 网格和外观,同时保持跨各种设备的实时渲染功能。埃尔斯纳等人。 [93]提出了自适应 Voronoi NeRFs,这是一种通过使用 Voronoi 图将场景划分为单元来提高过程效率的技术。这些单元随后被细分,以有效捕获和表示复杂的细节,从而提高性能和准确性。类似地,Kulhanek 和 Sattler [94] 引入了一种称为 tera-NeRF 的新辐射场表示,它成功地调整为以稀疏点云形式给出的 3D 几何先验,以利用更多细节。然而,值得注意的是,渲染场景的质量可能会根据不同区域点云的密度而有所不同。
一些作品旨在减少输入图像的数量[60,70,78,86,90,95]。于等人。 [95]提出了一种使用完全卷积方法在图像输入上调节 NeRF 的架构,使网络能够在对多个场景进行训练之前学习一个场景。这使得它能够从少量(甚至只有一个)视点执行前馈视图合成。同样,尼迈耶等人。 [60]介绍了一种对看不见的视图进行采样并规范从这些视图生成的补丁的外观和几何形状的方法。贾恩等人。 [86] 提出 DietNeRF 通过辅助语义一致性损失来增强小镜头质量,从而增强新位置的真实渲染。 DietNeRF 从各个场景中学习,以准确渲染同一位置的输入图像,并匹配不同随机姿势的高级语义特征。
在文化遗产领域,只有少数出版物明确调查并认识到 NeRF 在 3D 重建、数字保存和保护目的方面的潜力 [96,97]。
3. Analysis and Evaluation Methodology
主要目标是通过客观测量所得 3D 数据的质量,对传统摄影测量中基于 NeRF 的方法进行严格评估。为了实现这一点,需要考虑具有不同尺寸和表面特征的各种物体和场景,包括纹理良好、无纹理、金属、半透明和透明(第 3.3 节)。拟议的评估策略和指标(第 3.1 和 3.2 节)应帮助研究人员了解每种方法的优点和局限性,并可用于对新提出的方法进行定量评估。所有实验均基于 SDFStudio [98] 和 Nerfstudio [22] 框架。值得提醒的是,NeRF 输出是神经渲染;因此,使用行进立方体方法 [23] 从每个视图的不同深度图创建网格模型。然后使用 Open3D 库从网格顶点提取点云进行定量评估[78]。
3.1. Proposed Methodology
首先,将专用框架 [22,98] 中可用的各种 NeRF 方法应用于两个数据集,以了解它们的性能并选择性能最佳的方法(第 4.1 节)。然后,将该方法应用于其他数据集,以对传统摄影测量和可用的地面实况(GT)数据进行评估和比较(第 4.2-4.7 节)。
图 2 显示了定量评估基于 NeRF 的 3D 重建性能的拟议程序的总体概述。所有收集的图像或视频都需要相机姿势才能使用传统摄影测量或基于 NeRF 的方法生成 3D 重建。从可用图像开始,使用 Colmap 检索相机姿态。然后,应用多视图立体(MVS)或NeRF来生成3D数据。最后,我们提供独特且强大的环境和条件来提供客观的几何比较。为了实现这一目标,将摄影测量和 NeRF 生成的 3D 数据相对于 Cloud Compare 中可用的地面实况 (GT) 数据进行共同配准和重新缩放(使用迭代最近点 (ICP) 算法 [99],并执行质量评估。为了提供几何精度的公正评估,应用了不同的众所周知的标准 [13,43,100–102],包括最佳平面拟合、云与云比较、分析、准确性和完整性。使用前两个标准指标,例如标准差 (STD)、平均误差 (Mean_E)、均方根误差 (RMSE) 和平均绝对误差 (MAE)(第 3.2 节)。Remote Sens. 2023, 15, x FOR PEER REVIEW 7 of 22 优于方法(第 4.1 节)。然后,将该方法应用于其他数据集以运行评估和比较(第 4.2–4.7 节) )相对于传统摄影测量和可用的地面实况(GT)数据。图 2 显示了定量评估基于 NeRF 的 3D 重建性能的拟议程序的总体概述。所有收集的图像或视频都需要相机姿势才能使用传统摄影测量或基于 NeRF 的方法生成 3D 重建。从可用图像开始,使用 Colmap 检索相机姿态。然后,应用多视图立体(MVS)或NeRF来生成3D数据。最后,我们提供独特且强大的环境和条件来提供客观的几何比较。为了实现这一目标,使用摄影测量和 NeRF 生成的 3D 数据根据 Cloud Compare 中可用的地面实况 (GT) 数据进行共同配准和重新缩放(使用迭代最近点 (ICP) 算法 [99],并执行质量评估。为了提供几何精度的公正评估,应用了不同的众所周知的标准 [13,43,100–102],包括最佳平面拟合分析、点云比较、定性分析、准确性和完整性分析。前两个标准、指标,例如标准差 (STD)、平均误差 (Mean_E)、均方根误差 (RMSE) 和平均绝对值

图 2. 评估基于 NeRF 的 3D 重建相对于传统摄影测量的性能的拟议程序概述。
最佳平面拟合是通过使用最小二乘拟合 (LSF) 算法来完成的,该算法定义对象区域上的最佳拟合平面(假定该区域是平面)。该标准使我们能够评估摄影测量或 NeRF me 生成的 3D 数据中的噪声水平
通过从 3D 数据中提取横截面来进行分析,以突出显示重建表面的复杂几何细节。对轮廓的检查使我们能够评估保留几何细节(例如边缘和拐角)的方法的性能,并避免平滑效应。
云对云(C2C)比较是指测量两个点云中对应点之间的最近邻距离。
3.2. Metrics
尽管 NeRF 在 3D 重建目的中越来越受欢迎和广泛应用,但仍然缺乏基于指定标准或准则(例如 VDI/VDE 2643 BLATT 3)的质量评估信息。按照前面提到的共同注册流程和标准,使用以下指标(特别是对于云到云和平面拟合流程):

其中N表示观测点云的数量,Xj表示每个点到相应参考点或表面的最近距离,X表示平均观测距离。
准确性和完整性分别也称为精度和召回率[101,102],涉及测量两个模型之间的距离。评估准确性时,根据计算数据到地面实况 (GT) 计算距离。相反,为了评估完整性,计算从 GT 到计算数据的距离。这些距离可以是有符号的,也可以是无符号的,具体取决于具体的评估方法。准确度反映了重建点与地面真实情况的吻合程度,而完整性则表示所有 GT 点被覆盖的程度。通常,采用阈值距离来确定落在可接受阈值内的点的分数或百分比。阈值是根据数据密度和噪声水平等因素确定的。
3.3. Testing Objects
为了实现工作目标,使用了不同的数据集(图 3):它们具有不同尺寸和表面类型的对象,并且是在不同的照明条件、材料、相机网络、比例和分辨率下捕获的。

图 3. 具有不同表面特征的一组物体,用于评估 NeRF 方法。
Ignatius 和 Truck 数据集源自 Tanks 和 Temples 基准 [101],其中 GT 数据(通过激光扫描获取)也可用。其他数据集(Stair、Synthetic、Industrial、Bottle_1 和 Bottle_2)是在 FBK 中创建的。楼梯数据集提供平坦、反光且纹理良好且边缘锋利的表面。 GT 由理想的台阶表面平面提供。使用 Blender v3.2.2(用于几何模型、UV 纹理和材质)和 Quixel Mixer v2022(用于 PBR 纹理)创建的合成 3D 对象具有纹理良好的表面,具有复杂的几何形状,包括边缘和拐角。使用具有特定参数(焦距:50 毫米;传感器尺寸:36 毫米;图像尺寸:1920 × 1080 像素)的虚拟相机来创建沿着物体周围的螺旋曲线路径的图像序列。 Blender 中生成的 3D 模型用作 GT 进行精度评估。工业物体具有无纹理且高反射率的金属表面,这给所有被动 3D 方法带来了问题。其 GT 数据是通过标称精度为 63 μm 的 Hexagon/AICON Primescan 主动扫描仪采集的。还包括两个瓶子,具有透明和折射表面:它们的 GT 数据是在表面上粉/喷涂后使用摄影测量生成的。
作者正在准备 NeRF 方法的具体基准,并将在 https://github.com/3DOM-FBK/NeRFBK [103] 上提供,其中包含更多具有真实数据的数据集。
4. Comparisons and Analyses
本节介绍评估和比较基于 NeRF 的技术与标准摄影测量 (Colmap) 性能的实验。在比较了多种最先进的方法(第 4.1 节)后,选择 Instant-NGP 作为基于 NeRF 的方法进行全面评估,因为它比其他方法提供了更好的结果。 NeRF 训练是使用 Nvidia A40 GPU 执行的,而 3D 结果的几何比较是在标准 PC 上执行的。
4.1. State-of-the-Art Comparison
主要目标是对多种基于 NeRF 的方法进行综合分析。为了实现这一目标,Yu等人开发了SDFStudio统一框架。使用[98]是因为它将多种神经隐式表面重建方法合并到一个框架中。 SDFStudio 构建于 Nerfstudio 框架 [22] 之上。在已实现的方法中,选择了十种来比较其性能:来自 Nerfstudio 的 Nerfacto 和 Tensorf、来自 SDFStudio 的 Mono-Neus、Neus-Facto、MonoSDF、VolSDF、NeuS、MonoUnisurf 和 UniSurf 以及来自 Müller 等人的原始实现的 InstantNGP 。 [20]。
使用两个数据集:(i)合成数据集,由 200 个图像(1920 × 1080 px)组成,(ii)Ignatius 数据集 [101],其中包含 263 个图像(从分辨率为 1920 × 1080 px 的视频中提取)。
与 GT 数据的比较结果如图 4 所示。RMSE、MAE 和 STD 方面的结果表明 Instant-NGP 和 Nerfacto 方法取得了最佳结果,优于所有其他方法。就处理时间而言,Instant-NGP 两个数据集训练模型所需时间不到一分钟,Nerfacto 大约需要 15 分钟。值得注意的是,对于 Ignatius 序列(图 4b),尽管 MonoSDF、VolSDF 和 Neus-facto 的神经渲染在视觉上令人满意,但导出网格模型的行进立方体失败了;因此,无法进行评价。
因此,基于所达到的精度和处理时间,本文选择并采用 Instant-NGP 进行后续实验。

图 4. 各种基于 NeRF 的方法在 Synthetic (a) 和 Ignatius (b) 数据集上的比较结果,分别包含 200 和 263 个图像。
4.2. Image Baseline’s Evaluation
本节报告当输入图像数量减少(即基线增加)时基于 NeRF 的方法的评估。对 Instant-NGP 和 Mono-Neus(一种针对稀疏图像场景的成熟方法 [66,90])进行了比较评估,Instant-NGP 被认为是其他方法中的最佳方法(第 4.1 节)。该实验利用由四个输入图像子集组成的合成数据集,范围从 200 到 20 个图像(图 5),逐渐减少输入图像的数量(即,大约将图像基线加倍)。对于每组输入图像,两种 NeRF 方法都用于生成 3D 结果,并保持相似的历元数。对于每个子集,通过与 GT 数据进行点对点比较来估计 RMSE,如图 5 所示。研究结果表明,当有大量输入图像可用时,Instant-NGP 与 Mono-Neus 相比表现出卓越的性能。但在图像数量较少的场景下,Mono-Neus 的性能优于 Instant-NGP。然而,值得注意的是,Instant-NGP 和 Mono-Neus 都无法仅使用 10 个输入图像成功生成 3D 重建。

图 5. Instant-NGP 和 Mono-Neus 在综合数据集子集上的性能比较评估。
4.3. Monte Carlo Simulation
目的是评估当相机姿态发生变化/扰动时基于 NeRF 的 3D 结果的质量。因此,采用蒙特卡洛模拟[104]在有限范围内随机扰动相机参数的旋转和平移。扰动后,使用 Instant-NGP 生成 3D 重建并与参考数据进行比较。在两种情况下总共执行 30 次迭代(运行):(A) 旋转和平移在平移 ±20 mm 和旋转 ±2 度的范围内随机干扰,(B) 旋转和平移在范围分别为±40毫米和±4度。 Ignatius 数据集用于运行此模拟,结果如图 6 和表 1 所示。研究结果清楚地表明了拥有准确相机参数的重要性。在场景 A 中,平均估计 RMSE 为 19.72 mm,不确定性为 2.95 mm。在场景 B 中,平均估计 RMSE 几乎保持不变 (19.97 mm),而由于扰动范围较大,不确定性增加了一倍 (5.87 mm)。

图 6.扰动相机参数的蒙特卡罗模拟结果。表 1 报告了统计数据摘要。
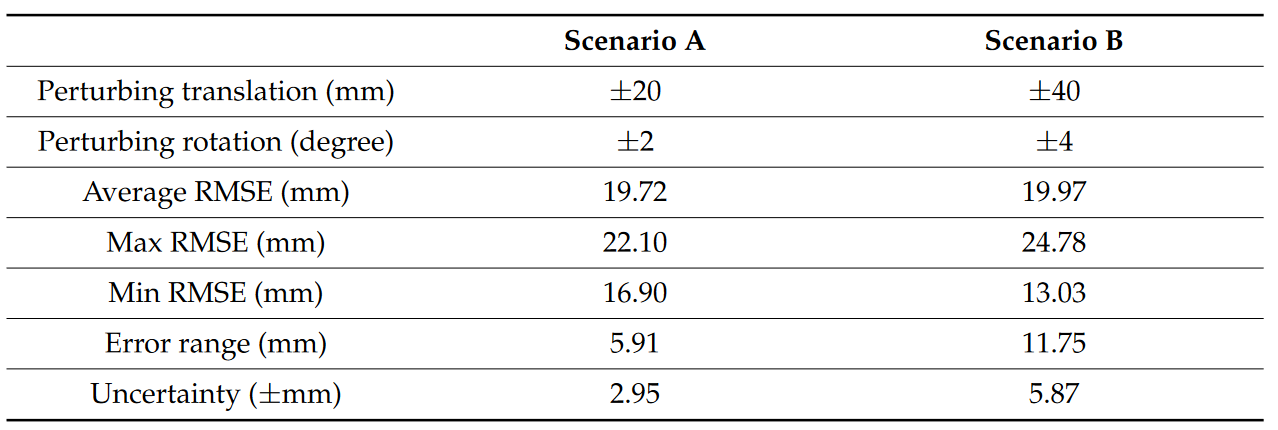
表 1. Ignatius 数据集上的蒙特卡罗模拟结果摘要。误差范围是最大和最小 RMSE 之间的差值,而不确定性则计算为误差范围的一半。
4.4. Plane Fitting
平面拟合方法可用于评估/测量重建平坦表面上的噪声水平。在使用 Stair 数据集的第一个实验中(图 7a),使用相同数量的图像和相机姿势导出了摄影测量点云和基于 NeRF 的重建。根据最佳拟合过程识别和分析两个水平面和三个垂直面(图 7b)。导出的指标如表 2 所示。

图 7. Step 数据集的图像 (a) 以及用于评估摄影测量和 NeRF 3D 重建中的噪声水平的水平和垂直平面 (b
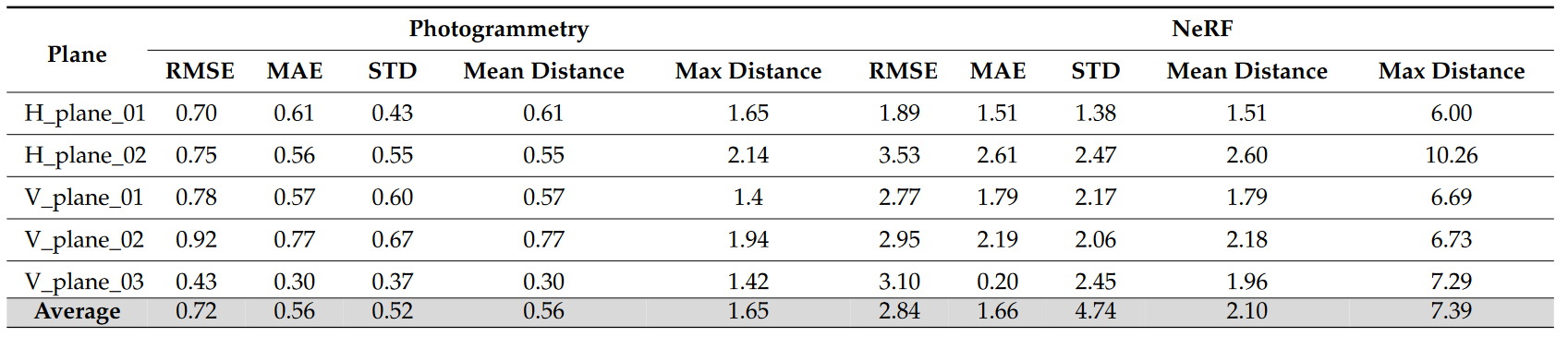
表2. 评估使用摄影测量和 Instant-NGP 处理的 Step 数据集的 3D 表面中的噪声水平 [单位:mm]
以类似的方式,使用合成数据集,其中 200 个图像用于 Instant-NGP,24 个图像用于摄影测量处理。选择五个垂直平面和五个水平平面(如图 8 所示),通过将理想平面拟合到重建的物体表面来执行表面偏差分析。表 3 报告了导出的指标。

图 8. 用于评估的具有一些水平和垂直平面的合成对象。

表 3. 合成物体的摄影测量和 NeRF 结果的评估指标 [单位:mm]。
从这两个结果(表 2 和表 3)来看,很明显,对于这两个物体,摄影测量优于 NeRF,并且可以得出噪声较小的结果。一般来说,NeRF RMSE 至少比摄影测量高 2-3 倍。
4.5. Profiling
横截面轮廓的提取有助于证明 3D 重建方法检索几何细节或将平滑效果应用于 3D 几何的能力。第 4.4 节中提供的综合数据集的结果使用 Cloud Compare 进行处理:在预定义距离处提取多个横截面(图 9),并使用不同指标与参考数据进行几何比较,如表 4 中所示。

图 9. GT (a)、摄影测量 (b) 和 NeRF © 生成的网格的近视图。合成对象 (d) 上轮廓的不同位置。参考 3D 数据(黑线)、摄影测量(红线)和 NeRF(蓝线)结果的轮廓示例

表 4. 轮廓和指标的比较[单位:mm]——见图 9a
获得的各个横截面轮廓以及所有轮廓的平均值的结果表明,摄影测量优于 NeRF,后者通常会产生更多噪声结果(图 9a-c)。例如,摄影测量的 RMSE 和 STD 估计平均值约为 0.09 mm 和 0.08 mm,而 NeRF 的该值大于 0.13 mm。
4.6. Cloud-to-Cloud Comparison
云到云比较是指评估数据集中相应 3D 样本之间相对于参考数据的相对欧几里德距离。考虑具有不同特征的不同对象(图 3):Ignatius、卡车、工业和合成。它们是小型和大型物体,具有无纹理、闪亮的金属表面。对于每个数据集,使用摄影测量 (Colmap) 和 Instant-NGP 生成 3D 数据,然后共同注册到可用的 GT(图 10)。最后,导出的指标如表 5 所示。值得注意的是,在执行的测试中使用的图像数量并不总是相同:事实上,对于 Synthetic、Ignatius 和 Truck 数据集,摄影测量已经以较低的成本提供了准确的结果。图像数量,因此添加更多图像并不会带来进一步的改进。另一方面,对于 NeRF,使用了所有可用的图像,因为较少的图像(或基线的放大)并没有带来好的结果(另见第 4.2 节)。

图 10. Instant-NGP 和摄影测量方法相对于地面真实数据的颜色编码云到云比较 [单位:毫米]

表 5. Instant-NGP 和摄影测量方法的云间比较指标[单位:mm]。对于除工业对象之外的所有对象,摄影测量都使用较少数量的图像,因为所达到的精度已经优于 NeRF。
从提供的结果可以看出,对于金属和高反射物体(工业数据集),NeRF 的表现优于摄影测量,而对于其他场景,摄影测量会产生更准确的结果。
考虑另外两个半透明和透明对象:Bottle_1 和 Bottle_2(图 3)。玻璃物体不会漫反射入射光,并且不具有用于摄影测量 3D 重建任务的自身纹理。它们的外观取决于物体的形状、周围背景和照明条件。因此,在这种情况下,摄影测量很容易失败或产生非常嘈杂的结果。另一方面,NeRF,正如 Mildenhall 等人所宣称的那样。由于 NeRF 模型的视图相关性,[16] 可以学习正确生成与透明度相关的几何图形。对于这两个对象,基于摄影测量和 NeRF 的 3D 结果共同注册到 GT 数据并计算指标(图 11 和表 6)。研究结果证明,对于透明物体,NeRF 的表现优于摄影测量。例如,Bottle_1 摄影测量的估计 RMSE、STD 和 MAE 分别为 6.5 mm、7.1 mm 和 7.5 mm。相比之下,NeRF 值分别显着降低至 1.3 mm、1.7 mm 和 2.1 mm。

图11. 两个透明物体上 Instant-NGP 和摄影测量的 o-cloud 比较[单位:mm]。

表 6 透明物体云间对比统计[单位:mm]。
4.7. Accuracy and Completeness
使用三个不同的数据集来比较摄影测量和 NeRF 的准确性和完整性:Ignatius、Industrial 和 Bottle_1。对于 NeRF(即时 NGP)和摄影测量,这两个指标都是根据可用的地面实况数据计算的。图 12 所示的结果揭示了以下见解: (i) 对于 Ignatius 数据集,摄影测量比 NeRF 表现出更高的准确性和完整性; (ii) 对于 Industrial 和 Bottle_1 数据集,NeRF 显示了稍微更好的结果。这些发现定量地证实了第 4.6 节,并且基于 NeRF 的方法在处理具有非协作表面的对象时表现出色,尤其是那些透明或有光泽的对象。相比之下,摄影测量在捕捉此类表面的复杂细节方面面临挑战,这使得 NeRF 成为更合适或互补的选择

图 12. NeRF 和摄影测量在三个不同物体上的准确性和完整性。
5. Conclusions
本文使用神经辐射场 (NeRF) 方法对基于图像的 3D 重建进行了全面分析。与传统摄影测量进行比较,报告定量和视觉结果,以了解处理多种类型的表面和场景时的优点和缺点。该研究客观地评估了 NeRF 生成的 3D 数据的优点和缺点,并深入了解它们在不同现实生活场景和应用中的适用性。该研究采用了一系列纹理良好、无纹理、金属、半透明和透明物体,并使用不同的尺度和图像集进行成像。使用各种评估方法和指标来评估生成的基于 NeRF 的 3D 数据的质量,包括噪声水平、表面偏差、几何精度和完整性。
报告的结果表明,在传统摄影测量方法失败或产生噪声结果的情况下,例如无纹理、金属、高反射和透明物体,NeRF 的性能优于摄影测量。相比之下,摄影测量对于纹理良好和部分纹理的对象仍然表现更好。这是因为,由于 NeRF 模型的视图相关性,基于 NeRF 的方法能够生成与反射率和透明度相关的几何形状。
这项研究为 NeRF 在不同现实生活场景中的适用性提供了宝贵的见解,特别是对于表面尤其具有挑战性的遗产和工业场景。更多数据集正在准备中,并将很快在 https://github.com/3DOM-FBK/NeRFBK [103] 上共享。该研究的结果强调了 NeRF 和摄影测量的潜力和局限性,为该领域即将进行的研究奠定了基础。未来的研究可以探索 NeRF 和摄影测量的结合,以提高具有挑战性的场景中 3D 重建的质量和效率。
抛转:
- instant-ngp 综合效率和效果来看,确实很有代表性。但就重建效果来说,近来已有更先进的工作发表,并且已经在sdfstudio中实现(如bakedsdf、neuralangelo),但效率不算很高,比较耗时。
- NeRFs已有相当多的变体,就本人的实验观察来看,不同方法的结果差距还是较大的。
- 没看到大场景的比较,有点遗憾。
- 整个对比流程以及评价指标很经典,值得学习。
- 由于没有对比目前最先进方法,所得结论可能仅供参考。

![[MAUI 项目实战] 手势控制音乐播放器: 动画](https://img-blog.csdnimg.cn/img_convert/a2ccb62e66267b667f935ac716ea0286.gif)
![最新[新手入门教程] JDK8u381的下载安装以及环境变量的配置](https://img-blog.csdnimg.cn/480c83f8939c4d1a990e1d2edd08e444.png)